算法在社区氛围的应用(三): 机器学习在答非所问识别上的运用
- - 知乎每日精选现在,瓦力可直接识别并处理该题中的答非所问内容. 我们鼓励认真、专业的分享,期待每一次讨论都能碰撞出更多有价值的信息,并希望每一个用心的回答都能够得到好的展示,为他人带来更多帮助. 但是,我们也发现在社区中出现了答非所问类的内容,影响知友们获取有价值内容的效率. 为了更好地识别答非所问类内容,我们采用了多种模型,包括传统的机器学习模型和比较新的深度学习模型.

跳绳的好处有哪些?可以锻炼哪些肌肉?
A:心肺功能比之前有提高。
B:有助于提高身体的乳酸阈值。
C:有助于提高身体的协调性。
D:谢谢,我去买了跳绳。
请问,以上哪个答案是答非所问?
现在,瓦力可直接识别并处理该题中的答非所问内容。
我们鼓励认真、专业的分享,期待每一次讨论都能碰撞出更多有价值的信息,并希望每一个用心的回答都能够得到好的展示,为他人带来更多帮助。但是,我们也发现在社区中出现了答非所问类的内容,影响知友们获取有价值内容的效率。
为了更好地识别答非所问类内容,我们采用了多种模型,包括传统的机器学习模型和比较新的深度学习模型。通过前期对语料的分析,我们发现语言用词、作者历史行为、知友对内容的反馈信息等都具有比较明显的区分度,因而我们尝试使用特征工程和传统机器学习方法实现了瓦力识别答非所问的第一版模型,并达到了一个相对不错的效果。
随机森林 (Random Forest) 是树模型里两个常用模型之一(另一个是 Gradient Boosting Decision Tree)。顾名思义,就是用随机的机制建立一个森林,森林由多棵分类树构成。当新样本进入时,我们需要将样本输入到每棵树中进行分类。打个形象的比喻,知乎森林召开议会,讨论 @刘看山 到底是狗还是北极狐(看山,我知道你是北极狐的,手动捂脸逃...),森林中的每棵树都独立发表了自己对这个问题的观点,做出了自己的判断。最终刘看山是狗还是北极狐,要依据投票情况来确定,获得票数最多的类别就是这片森林对其的分类结果。如同图一所示意境。
 图 1 森林会议
图 1 森林会议 有了树我们就可以分类,那么在答非所问这个场景下,怎么来建立这一个森林呢?
样本
通过训练语料和业务数据,进行特征工程,提取出了以下三类特征:
同时,通过历史积累、用户标注、策略生成产生出了训练样本集,然后用以上特征类别表示出每条样本。
分类树
使用随机有放回抽样选取每棵树的训练样本,随机选取 m 个特征 (m < 总特征数) 进行无限分裂生长,成长为能独立决策的树。
投票决策
通过建好的多棵分类树,对新的样本进行决策投票,获得最终的分类结果。
对于 Random Forest 的实现,有很多优秀开源的实现,在实际中我们封装了 Spark 中的 Random Forest 完成了模型的迭代。最终取得了 Precision 97%,Recall 58% 左右的不错结果。
细心的知友可能注意到了,我们的特征里有一类特征是与时间和回答的暴光有关的,即回答和作者的统计特征。为此我们在现有模型的基础上分析了这类特征的时间累积效果,如图二所示。从图中可以看到,经过一天的统计特征累积,Precision 达到了 90%,但 Recall 只有 40%,可以说这一天时间对于 40% 的答非所问有了比较充分的特征积累以支撑对其的准确判断。而随时间的增加,基本上 Precision 和 Recall 都有提升。但并不是时间越长,提升越多。
最终我们结合产品应用层面和算法阈值,分别选出两个时间点,一方面牺牲 Recall 快速识别处理一部分答非所问的回答,另一方面允许一定的处理延时,保证了大量的 Recall,大大净化了回答区域的无关内容。
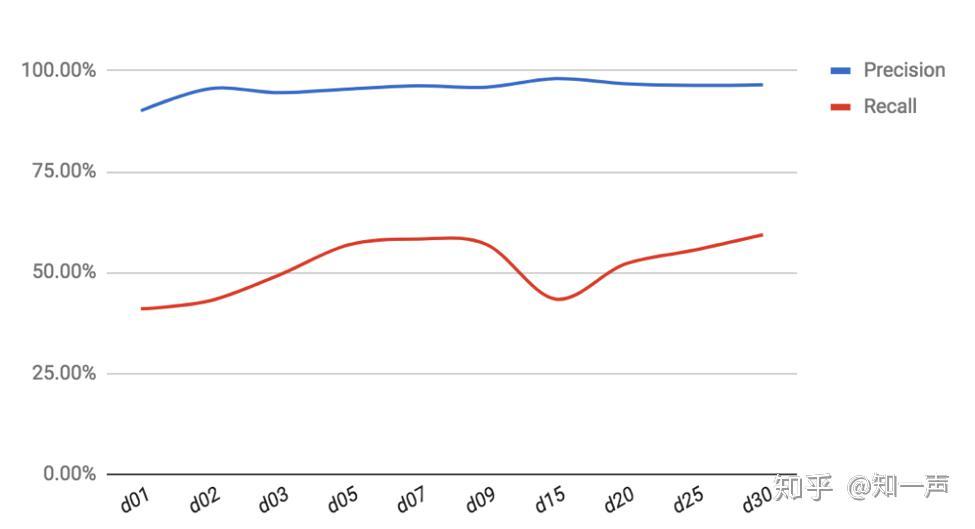 图 2 统计特征累积周期(天)对 Precision 和 Recall 的影响
图 2 统计特征累积周期(天)对 Precision 和 Recall 的影响 传统机器学习的一个核心内容就是特征工程,包括特征提取、特征选择等。
但特征工程总是会耗费比较多的时间,而且在答非所问的识别中一些时间相关的特征,还延长了处理周期,不利于快速处理。而广为流传的深度学习,能自动对输入的低阶特征进行组合、变换,映射到高阶的特征,这也促使我们转向深度学习进行答非所问的识别。
深度学习兴起于图像识别,其过程可以引用图三[1] 大致描绘,输入特征,经隐藏层逐层抽象、组合,最后经输出层得出识别结果。
 图 3 深度学习示意
图 3 深度学习示意 Word Embedding
相较于图片天然的像素表征,可以直接输入到深度神经网络里,文本需要进行向量化后方可作为网络的输入。关于「词向量化」的精彩描述可以参考[2]。此处我们抽取了知乎社区 1000 多万真实的文本信息,包括问题、回答、文章、评论等数据,利用 Facebook 开源的 FastText 训练了 256 维的词向量和字向量。对于 FastText 的原理和用法此处不作详细阐述,感兴趣的朋友可以参考[3]。
CNN 网络 (Convolutional Neural Network)
我们模型的网络结构基本上采用了 Severyn[4] 提出的网络结构,但在一些细节上做了些改动,比如图四中的 CNN-answer/question, 我们结合了 Wide & Deep[5] 的思想,以提取更为丰富的语义信息。
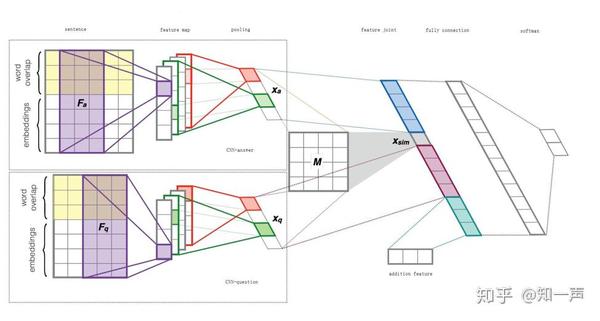 图 4 模型结构
图 4 模型结构 下面简要介绍每一层的含义:
Embedding Layer——该层利用预训练好的 FastText 词向量将原始词序列表达成词向量序列
Convolutional Layer——此层主要通过卷积操作,同时捕获类似于 N-Gram 特征(但同 N-Gram 还是有差异的)。我们的模型选取了 [2, 3, 4, 5, 6] 5 个卷积核宽度,为每个卷积核配置了 64 个 filter
Pooling Layer——池化层,对经过卷积操作提取的特征进行 Sampling。此处我们采用了 K-Max-Average pooling,对卷积层提取的特征,选择出激活程度 top-K 的特征值的平均值作为 pooling 的结果
Feature Join & Fully connected Layer——将前述几层获得的特征,以及额外信息进行融合,作为最终的特征输出,以便于最后的决策判断。实际上,我们在 Fully Connection 后面加了 3 层 Dense Layer,以提高网络的表达能力。
Softmax——将最后的特征转换成二分类决策概率。
最终训练好该模型,在验证集上达到了 Precision 78%, Recall 80% 的效果。Recall 虽有比较大的提升,但 Precision 并没有前文描述的 Random Forest 的方法好。
目前,答非所问几个模型都上线到了知乎产品的诸多场景下,如反对、举报、专项清理等。每天清理约 5000 条新产生的「答非所问」内容,以及此前现存的 115 万条「答非所问」内容。
为了维护良好的讨论氛围,我们还需不断优化和升级。我们还有很长的路要走,后续我们将建立更为精确的语义模型,辅以问题意图识别,知识库等,更加准确地识别出所有内容。瓦力的升级,离不开知友们的帮助。欢迎大家在日常使用中,继续通过「反对」和「举报」向我们提供更多反馈,与我们共同维护知乎健康的讨论氛围。
本文作者:知乎内容质量安全团队 孙先
参考文献:
[1] Breaking it down: A Q&A on machine learning
[2] 词向量和语言模型
[3] FastText
[4] Learning to rank short text pairs with convolutional deep neural networks
[5] Wide & Deep Learning for Recommender Systems