










Community Detection 社群发现算法 - CSDN博客
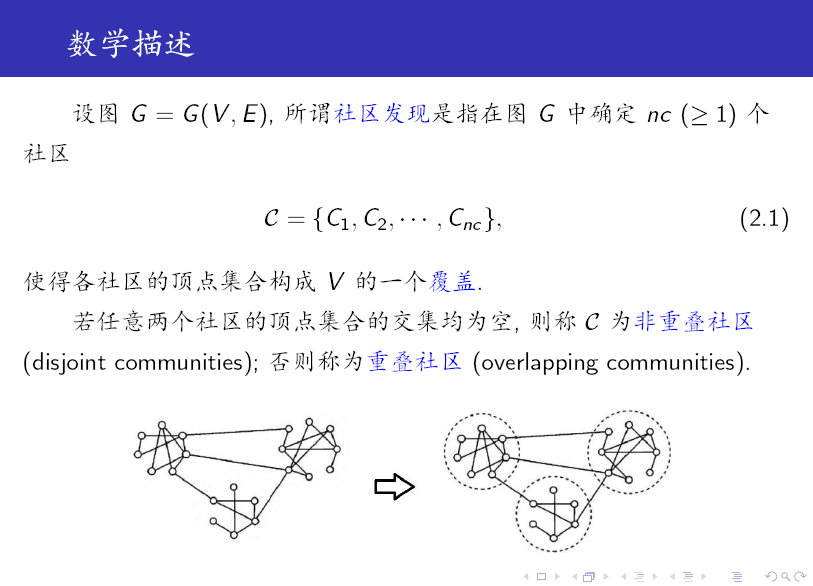
- - 社区发现(Community Detection)算法用来发现网络中的社区结构,也可以视为一种广义的. 以下是我的一个 PPT 报告,分享给大家. 从上述定义可以看出:社区是一个比较含糊的概念,只给出了一个定性的刻画. 另外需要注意的是,社区是一个子图,包含顶点和边.
社区发现(Community Detection)算法用来发现网络中的社区结构,也可以视为一种广义的 聚类算法。以下是我的一个 PPT 报告,分享给大家。

从上述定义可以看出:社区是一个比较含糊的概念,只给出了一个定性的刻画。
另外需要注意的是,社区是一个子图,包含顶点和边。
下面我们以新浪微博用户对应的网络图为例,来介绍相应的社区发现算法 。
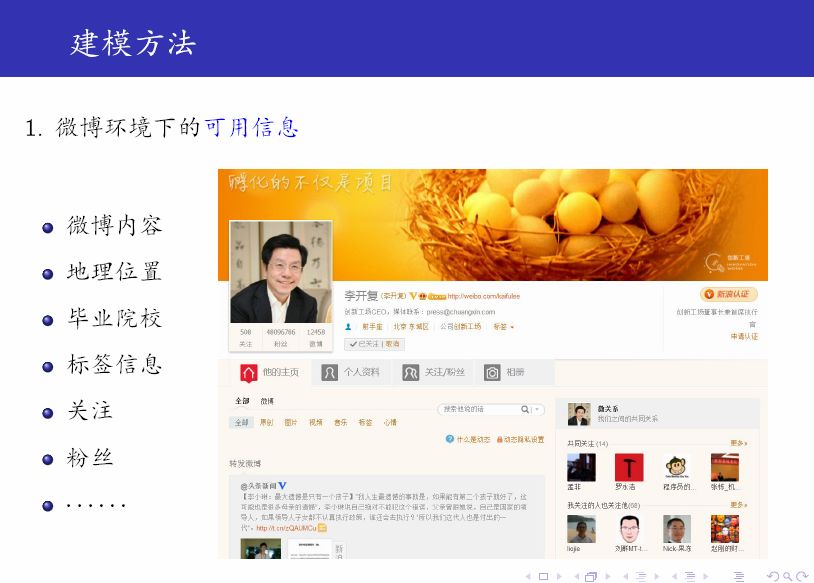
这里在相互关注的用户之间建立连接关系,主要是为了简化模型,此时对应的图为无向图。
当然,我们也可以采用单向关注来建边,此时将对应有向图。
这个定义看起来很拗口,但通过层层推导,可以得到如下 (4.2)的数学表达式。定义中的随机网络也称为 Null Model,其构造方法为:
the null model used has so far been a random graph with the same number of nodes, the same number of edges and the same degree distribution as in the original graph, but with links among nodes randomly placed.
注意,(4.2) 是针对无向图的,因此这里的 m 表示无向边的条数,即若节点 i 和节点 j 有边相连,则节点 (i, j) 对 m 只贡献一条边 。
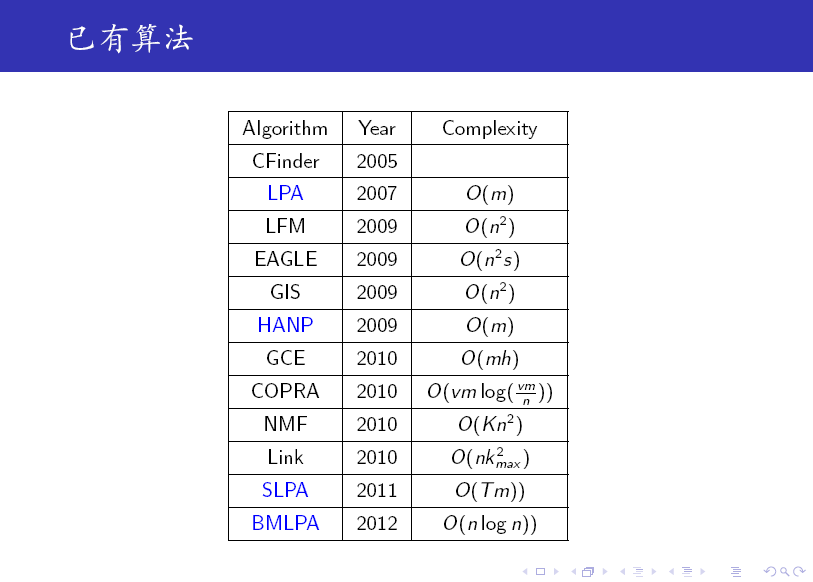
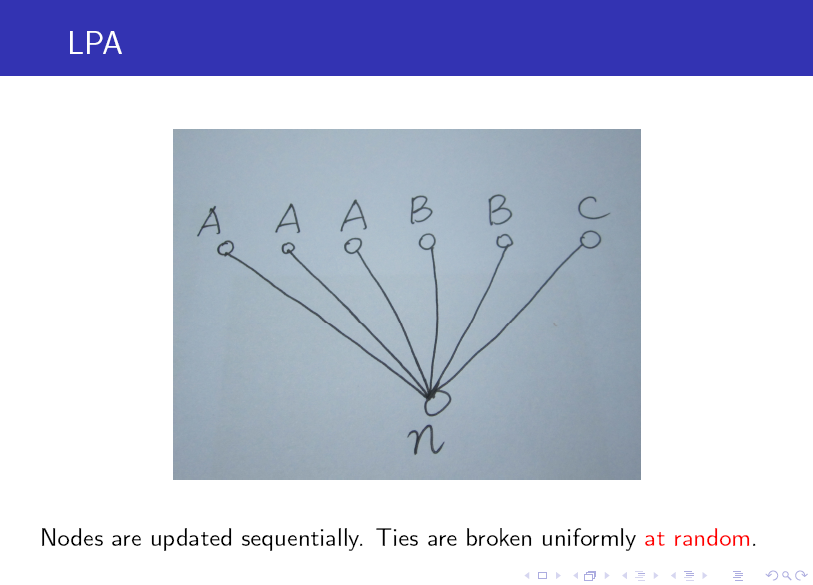
标签传播算法(LPA)的做法比较简单:
第一步: 为所有节点指定一个唯一的标签;
第二步: 逐轮刷新所有节点的标签,直到达到收敛要求为止。对于每一轮刷新,节点标签刷新的规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点。当个数最多的标签不唯一时,随机选一个。
注:算法中的记号 N_n^k 表示节点 n 的邻居中标签为 k 的所有节点构成的集合。

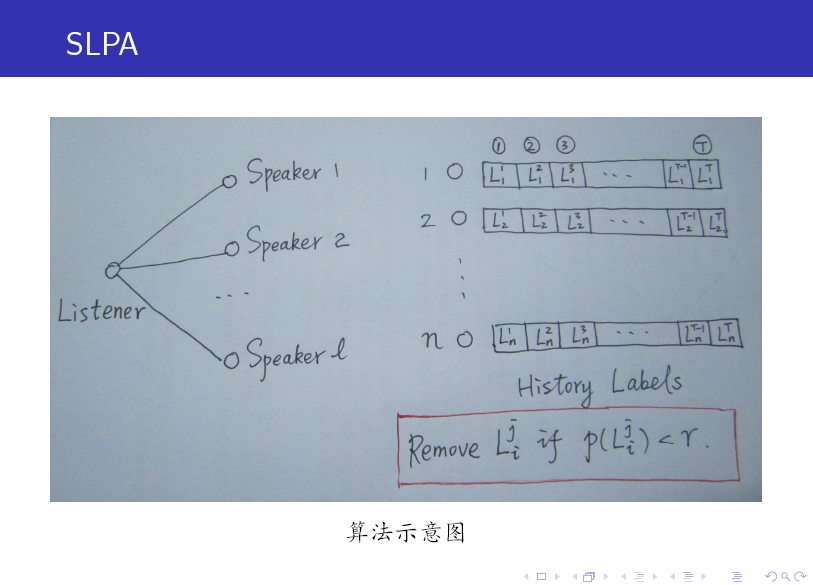
SLPA 中引入了 Listener 和 Speaker 两个比较形象的概念,你可以这么来理解:在刷新节点标签的过程中,任意选取一个节点作为 listener,则其所有邻居节点就是它的 speaker 了,speaker 通常不止一个,一大群 speaker 在七嘴八舌时,listener 到底该听谁的呢?这时我们就需要制定一个规则。
在 LPA 中,我们以出现次数最多的标签来做决断,其实这就是一种规则。只不过在 SLPA 框架里,规则的选取比较多罢了(可以由用户指定)。
当然,与 LPA 相比,SLPA 最大的特点在于:它会记录每一个节点在刷新迭代过程中的 历史标签序列(例如迭代 T 次,则每个节点将保存一个长度为 T 的序列,如上图所示),当迭代停止后,对每一个节点历史标签序列中各(互异)标签出现的频率做统计,按照某一给定的阀值过滤掉那些出现频率小的标签,剩下的即为该节点的标签(通常有多个)。
SLPA 后来被作者改名为 GANXiS,且软件包仍在不断更新中......



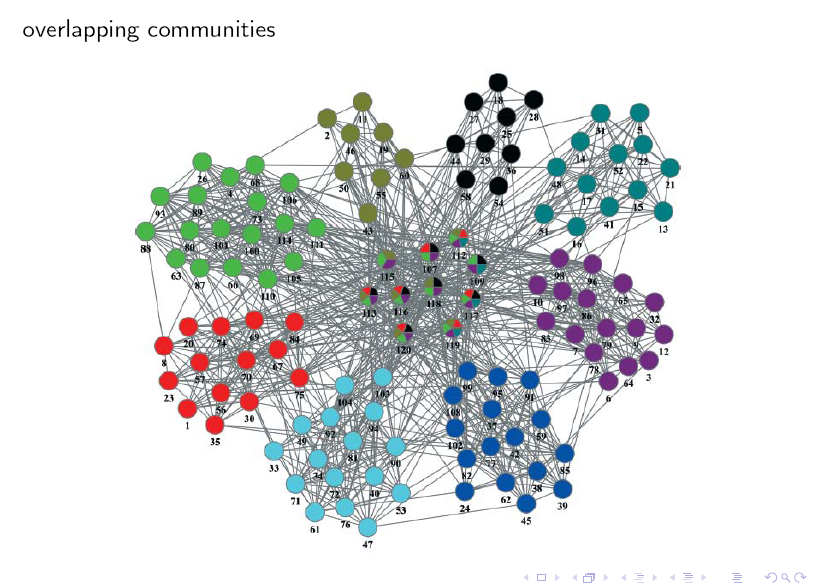
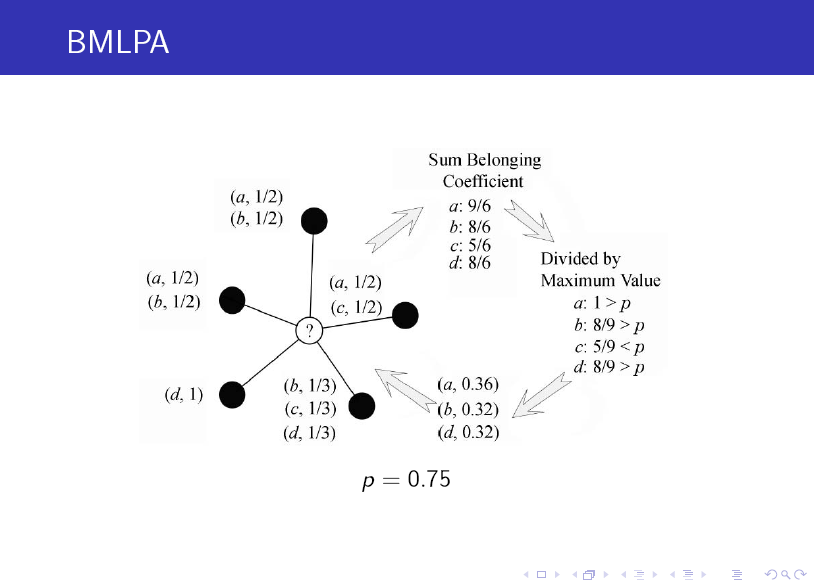
这里对上面的图做个简单介绍:带问号的节点是待确定标签的节点,黑色实心点为其邻居节点,它们的标签是已知的,注意标签均是由二元数对的序列构成的,序列中每一个元素的第一个分量表示其标签,第二个分量表示该节点属于该标签对应社区的可能性(或者说概率,叫做 belonging coefficent),因此对于每个节点,其概率之和等于 1。
我们按照以下步骤来确定带问号节点的标签:
1. 获取邻居节点中所有的互异(distinct) 标签列表,并累加相应的 belonging coefficent 值。
2. 对 belonging coefficent 值列表做归一化,即将列表中每个标签的 belonging coefficent 值除以 C1 (C1 为列表中 belonging coefficent 值的最大值)。
3. 过滤。若列表中归一化后的 belonging coefficent 值(已经介于 0,1 之间)小于某一阀值 p (事先指定的参数),则将对应的二元组从列表中删除。
4. 再一次做归一化。由于过滤后,剩余列表中的各 belonging coefficent 值之和不一定等于 1,因此,需要将每个 belonging coefficent 值除以 C2 (C2 表示各 belonging coefficent 值之和)。
经过上述四步,列表中的标签即确定为带问号节点的标签。
这里,我们对 Fast Unfolding 算法做一个简要介绍,它分为以下两个阶段:
第一个阶段:首先将每个节点指定到唯一的一个社区,然后按顺序将节点在这些社区间进行移动。怎么移动呢?以上图中的节点 i 为例,它有三个邻居节点 j1, j2, j3,我们分别尝试将节点 i 移动到 j1, j2, j3 所在的社区,并计算相应的 modularity 变化值,哪个变化值最大就将节点 i 移动到相应的社区中去(当然,这里我们要求最大的 modularity 变化值要为正,如果变化值均为负,则节点 i 保持不动)。按照这个方法反复迭代,直到网络中任何节点的移动都不能再改善总的 modularity 值为止。
第二个阶段:将第一个阶段得到的社区视为新的“节点”(一个社区对应一个),重新构造子图,两个新“节点”之间边的权值为相应两个社区之间各边的权值的总和。
我们将上述两个阶段合起来称为一个 pass,显然,这个 pass 可以继续下去。
从上述描述我们可以看出,这种算法包含了一种 hierarchy 结构,正如对一个学校的所有初中生进行聚合一样,首先我们可以将他们按照班级来聚合,进一步还可以在此基础上按照年级来聚合,两次聚合都可以看做是一个社区发现结果,就看你想要聚合到什么层次与程度。

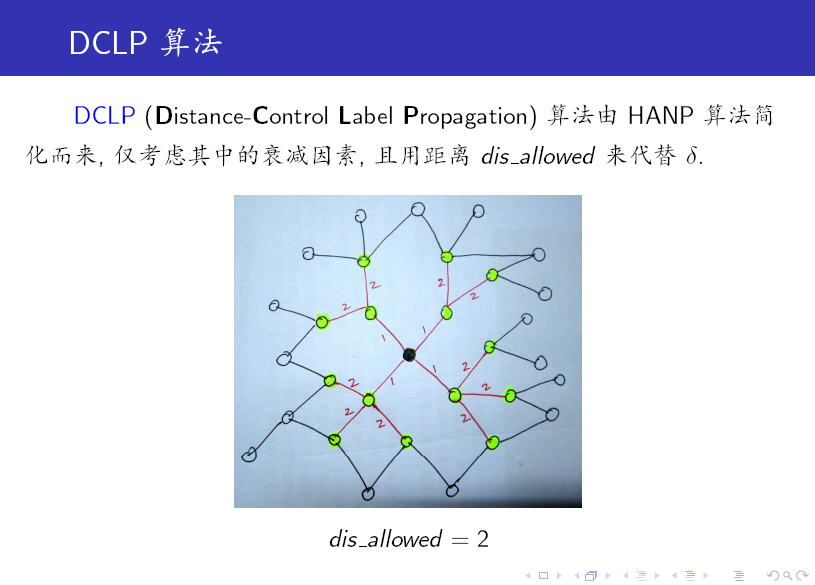
DCLP 算法是 LPA 的一个变种,它引入了一个参数来限制每一个标签的 传播范围,这样可有效控制 Monster (非常大的 community,远大于其他 community)的产生。


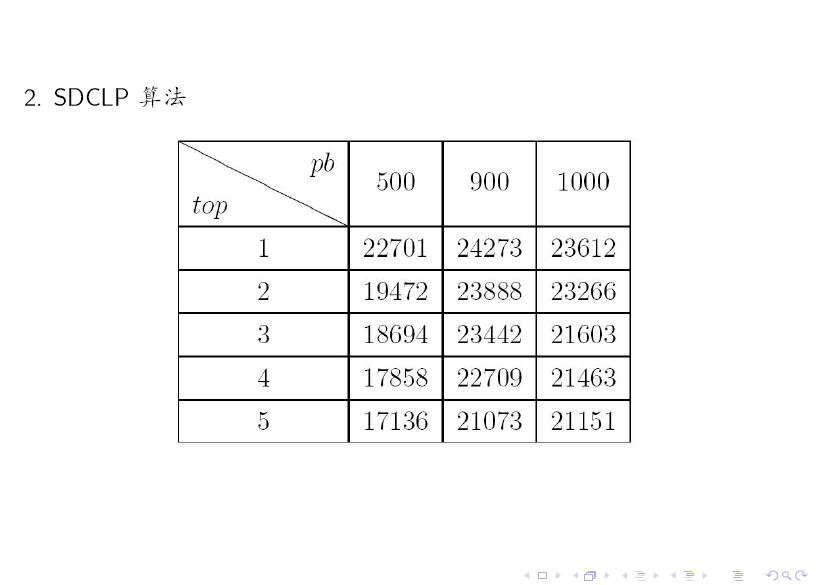
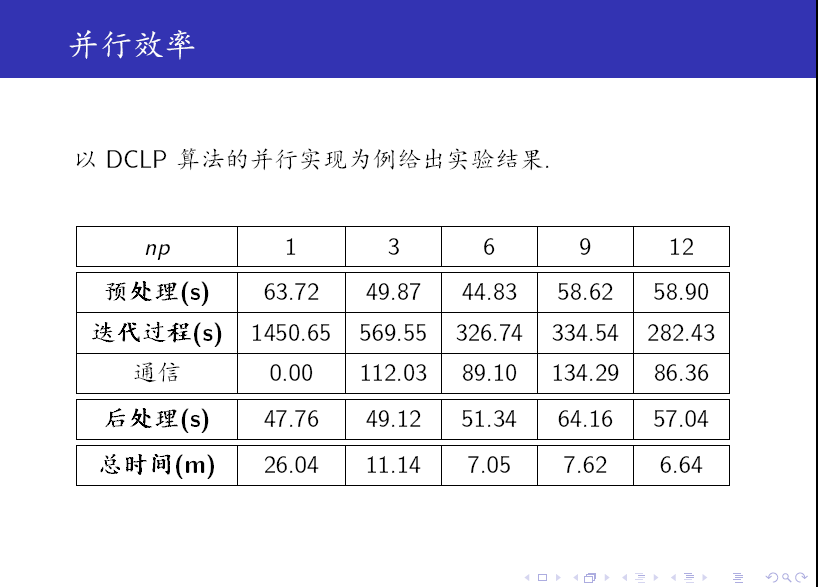
最后,我们给出一些 实验结果。

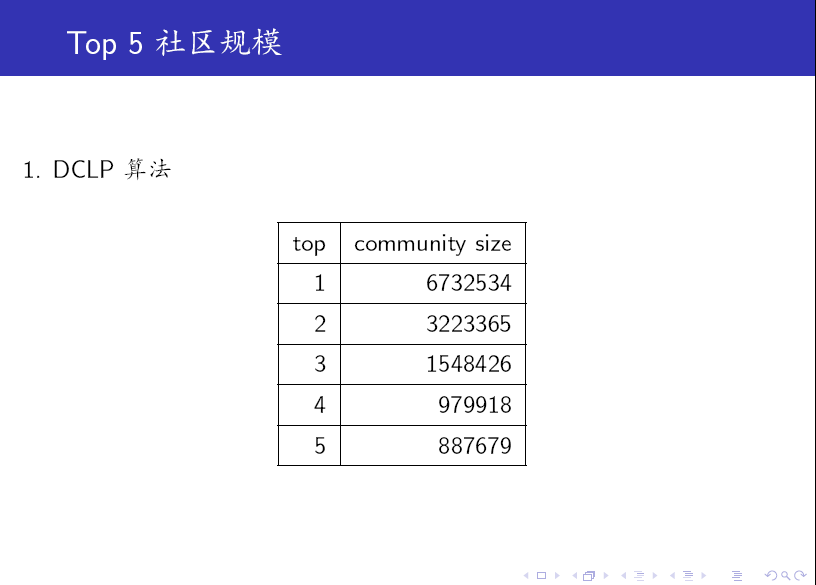
对比上述两个表格可知:SDCLP 算法得到的 top 5 社区更为均匀。
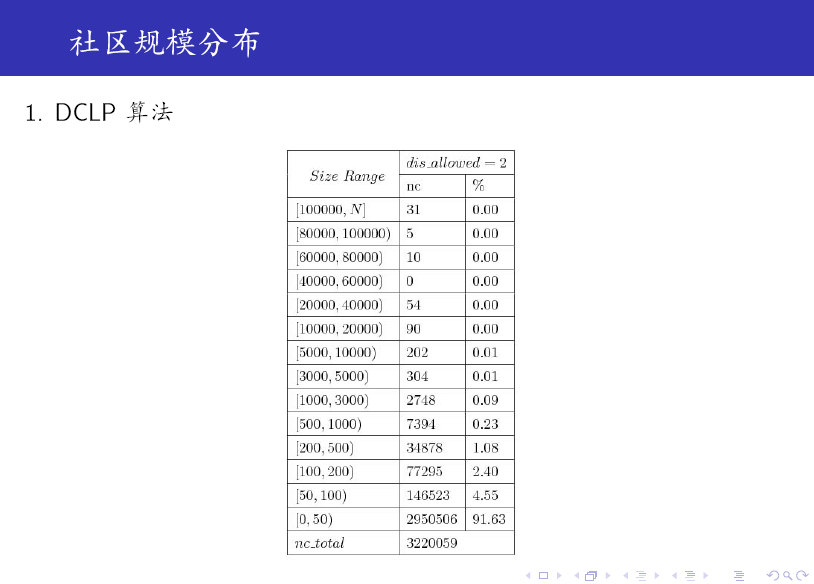
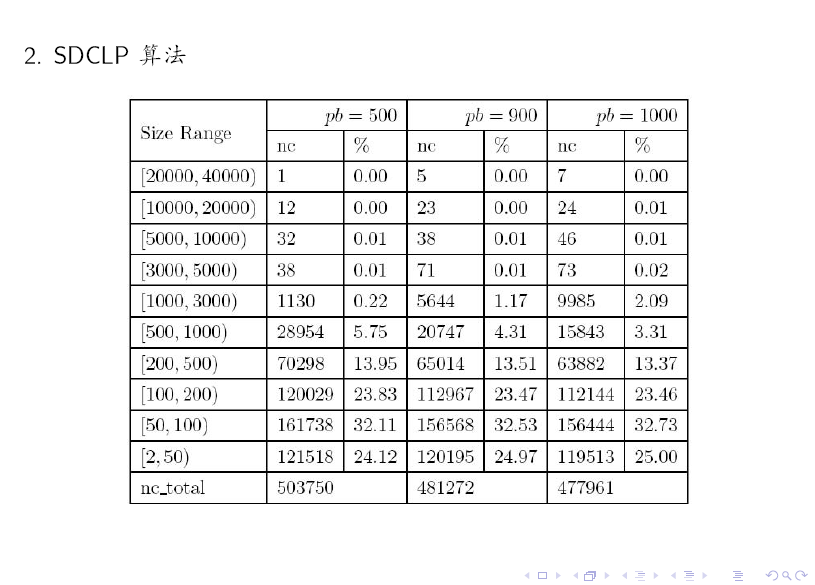
最近有很多朋友向我索要本文的 PPT,为方便大家参考,我把 本文的完整 PPT、 SPLA / GANXiS 软件包的源码以及 几篇相关算法的代表 Paper 打包了,有需要的读者请点击 社区发现算法资料自行下载。
作者: peghoty
出处: http://blog.csdn.net/peghoty/article/details/9286905
欢迎转载/分享, 但请务必声明文章出处.