kafka监控之kafka-run-class.sh
- - 开源软件 - ITeye博客kafka自带了很多工具类,在源码kafka.tools里可以看到:. 这些类该如何使用呢,kafka的设计者早就为我们考虑到了,在${KAFKA_HOME}/bin下,有很多的脚本,其中有一个kafka-run-class.sh,通过这个脚本,可以调用其中的tools的部分功能,如调用kafka.tools里的ConsumerOffsetChecker.scala,.
KafkaOffsetMonitor是一个可以用于监控Kafka的Topic及Consumer消费状况的工具,其配置和使用特别的方便。源项目Github地址为: https://github.com/quantifind/KafkaOffsetMonitor。
最简单的使用方式是从Github上下载一个最新的 KafkaOffsetMonitor-assembly-0.2.1.jar,上传到某服务器上,然后执行一句命令就可以运行起来。但是在使用过程中有可能会发现页面反应缓慢或者无法显示相应内容的情况。据说这是由于jar包中的某些js等文件需要连接到网络,或者需要翻墙导致的。网上找的一个修改版的KafkaOffsetMonitor对应jar包,可以完全在本地运行,经过测试效果不错。下载地址是: http://pan.baidu.com/s/1ntzIUPN,在此感谢一下贡献该修改版的原作者。链接失效的话,可以博客下方留言联系我。
因为完全没有安装配置的过程,所以直接从KafkaOffsetMonitor的使用开始。
将KafkaOffsetMonitor-assembly-0.2.0.jar上传到服务器后,可以新建一个脚本用于启动该应用。脚本内容如下:
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk m000:2181,m001:2181,m002:2181 \
--port 8088 \
--refresh 10.seconds \
--retain 2.days 各参数的作用可以参考一下Github上的描述:
pluginsArgs additional arguments used by extensions (see below)
启动后,访问 m000:8088端口,可以看到如下页面:

在这个页面上,可以看到当前Kafka集群中现有的Consumer Groups。
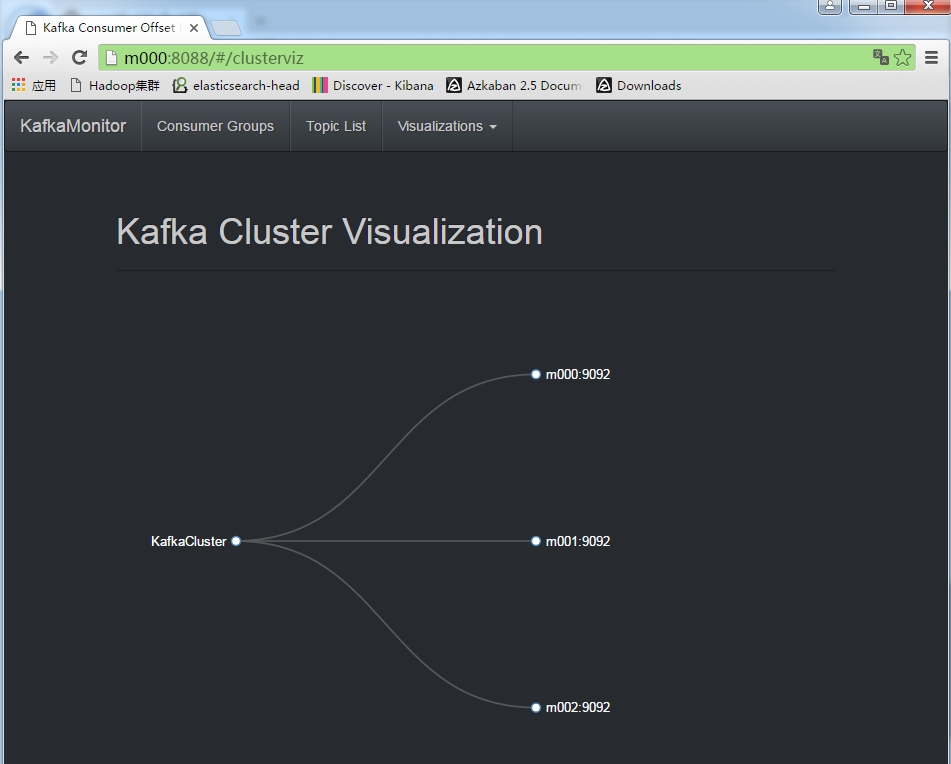
在上图中有一个Visualizations选项卡,点击其中的Cluster Overview可以查看当前Kafka集群的Broker情况
接下来将继续上一篇Kafka相关的文章 Kafka系列之-自定义Producer,在最后对Producer进行包装的基础上,分别实现一个简单的往随机Partition写messge,以及自定义Partitioner的Producer,对KafkaOffsetMonitor其他页面进行展示。
首先为本次试验新建一个Topic,命令如下:
bin/kafka-topics.sh \
--create \
--zookeeper m000:2181 \
--replication-factor 3 \
--partition 3 \
--topic kafkamonitor-simpleproducer 在上一篇文章中提到的Producer封装Github代码的基础上,写了一个往kafkamonitor-simpleproducer发送message的java代码。
import com.ckm.kafka.producer.impl.KafkaProducerToolImpl;
import com.ckm.kafka.producer.inter.KafkaProducerTool;
/**
* Created by ckm on 2016/8/30.
*/
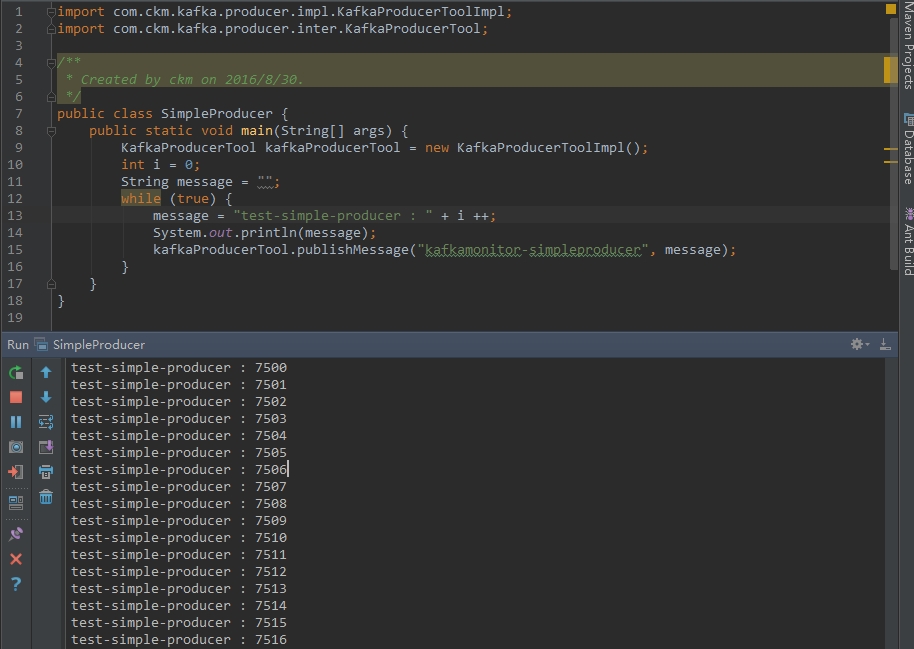
public class SimpleProducer {
public static void main(String[] args) {
KafkaProducerTool kafkaProducerTool = new KafkaProducerToolImpl();
int i = 0;
String message = "";
while (true) {
message = "test-simple-producer : " + i ++;
kafkaProducerTool.publishMessage("kafkamonitor-simpleproducer", message);
}
}
} 程序运行效果:
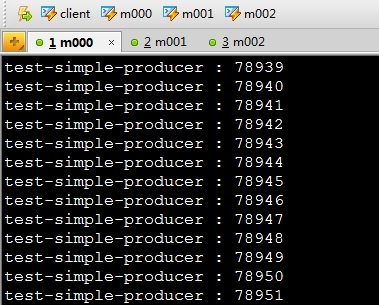
用kafka自带的ConsoleConsumer消费kafkamonitor-simpleproducer中的message。
bin/kafka-console-consumer.sh --zookeeper m000:2181 --from-beginning --topic kafkamonitor-simpleproducer 消费截图如下:
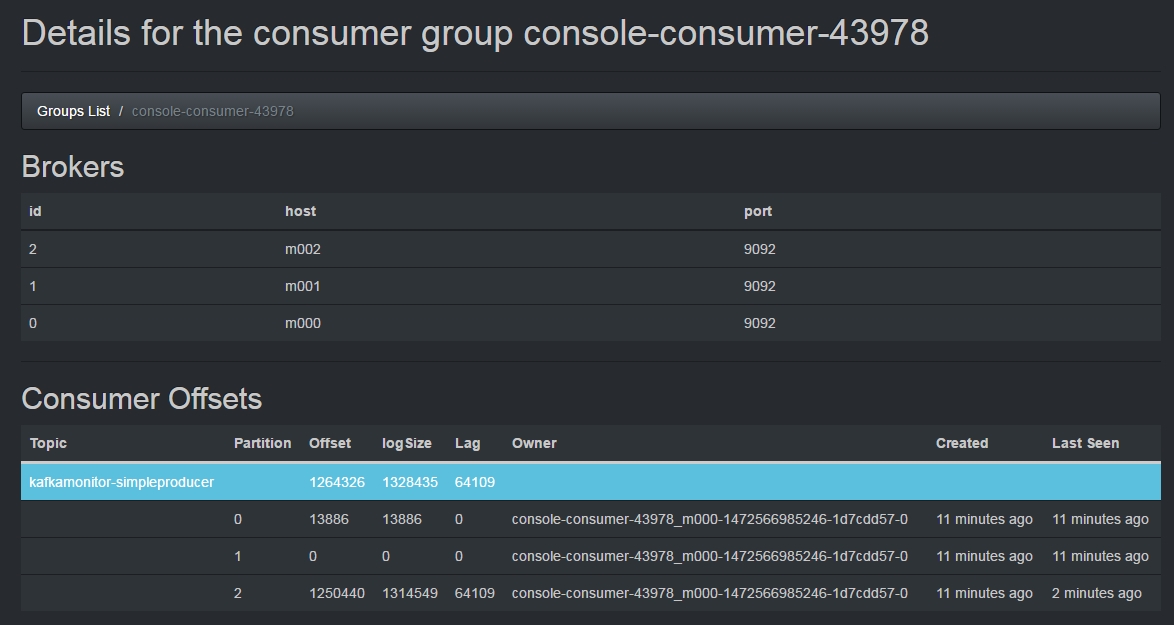
(1)在Topic List选项卡中,我们可以看到刚才新建的 kafkamonitor-simpleproducer
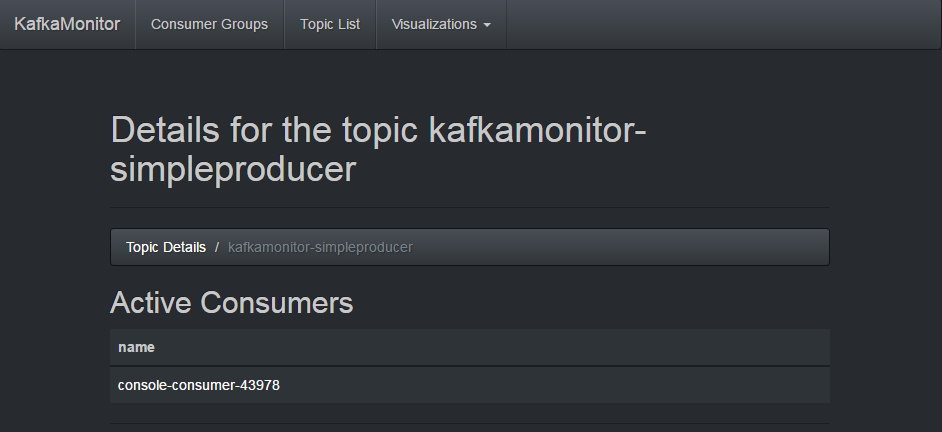
(2)点开后,能看到有一个console-consumer正在消费该topic
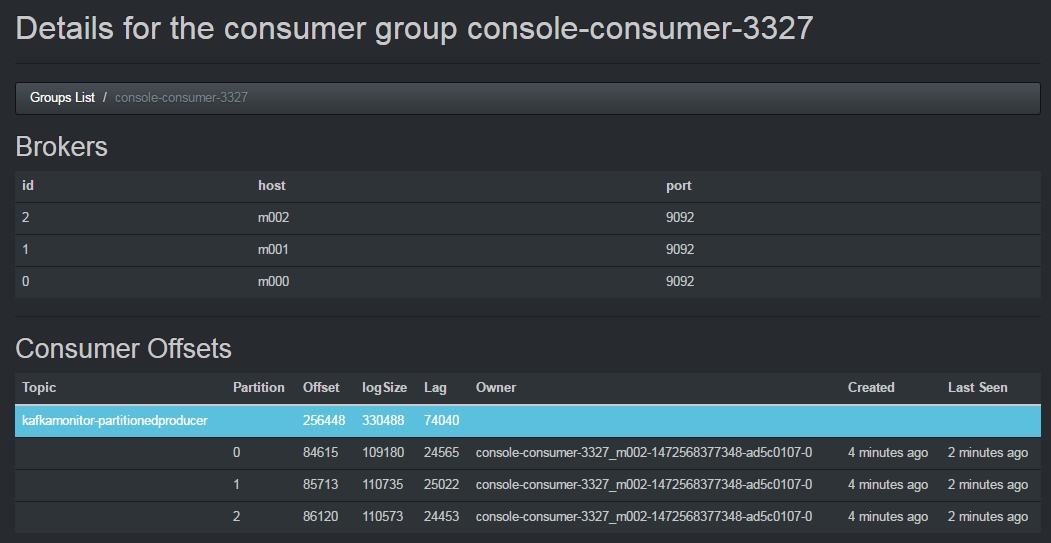
(3)继续进入该Consumer,可以查看该Consumer当前的消费状况
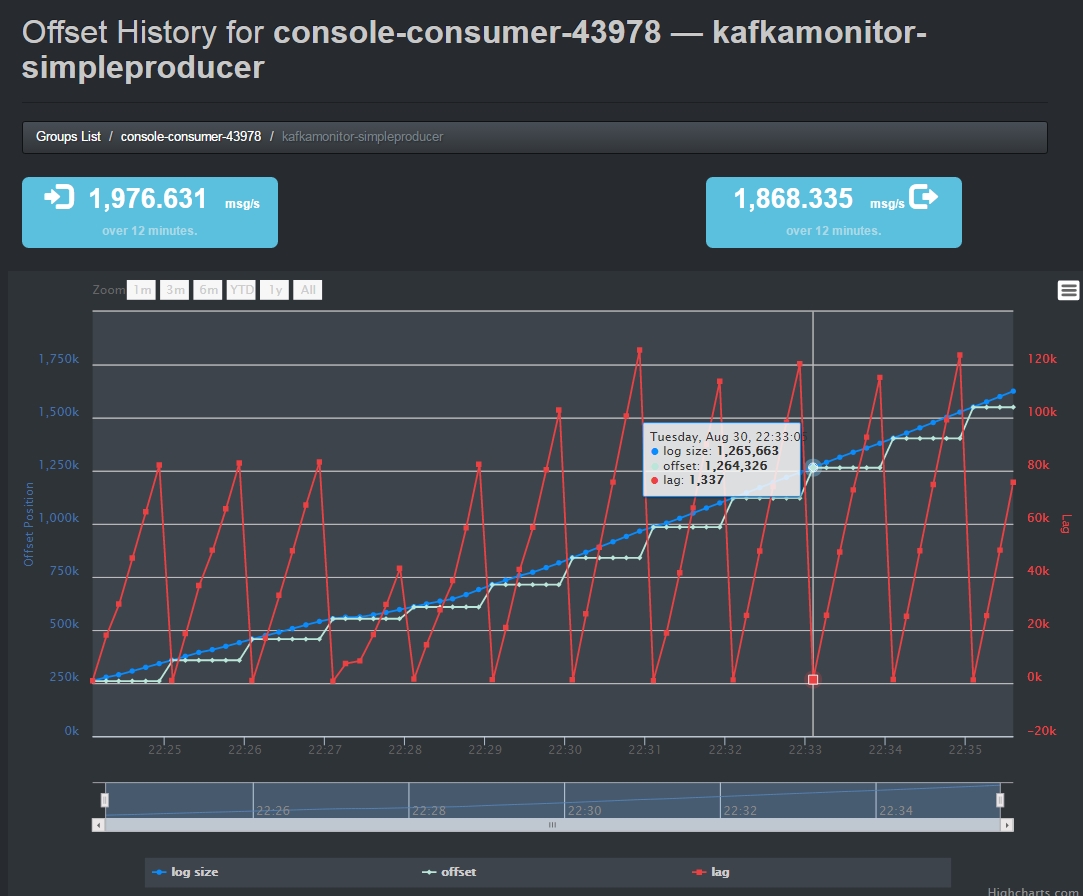
这张图片的左上角显示了当前Topic的生产速率,右上角显示了当前Consumer的消费速率。
图片中还有三种颜色的线条,蓝色的表示当前Topic中的Message数目,灰色的表示当前Consumer消费的offset位置,红色的表示蓝色灰色的差值,即当前Consumer滞后于Producer的message数目。
(4)看一眼各partition中的message消费情况
从上图可以看到,当前有3个Partition,每个Partition中的message数目分布很不均匀。这里可以与接下来的自定义Producer的情况进行一个对比。
bin/kafka-topics.sh \
--create \
--zookeeper m000:2181 \
--replication-factor 3 \
--partition 3 \
--topic kafkamonitor-partitionedproducer 逻辑很简单,循环依次往各Partition中发送message。
import kafka.producer.Partitioner;
/**
* Created by ckm on 2016/8/30.
*/
public class TestPartitioner implements Partitioner {
public TestPartitioner() {
}
@Override
public int partition(Object key, int numPartitions) {
int intKey = (int) key;
return intKey % numPartitions;
}
}
将自定义的Partitioner设置到Producer,其他调用过程和二中类似。
import com.ckm.kafka.producer.impl.KafkaProducerToolImpl;
import com.ckm.kafka.producer.inter.KafkaProducerTool;
/**
* Created by ckm on 2016/8/30.
*/
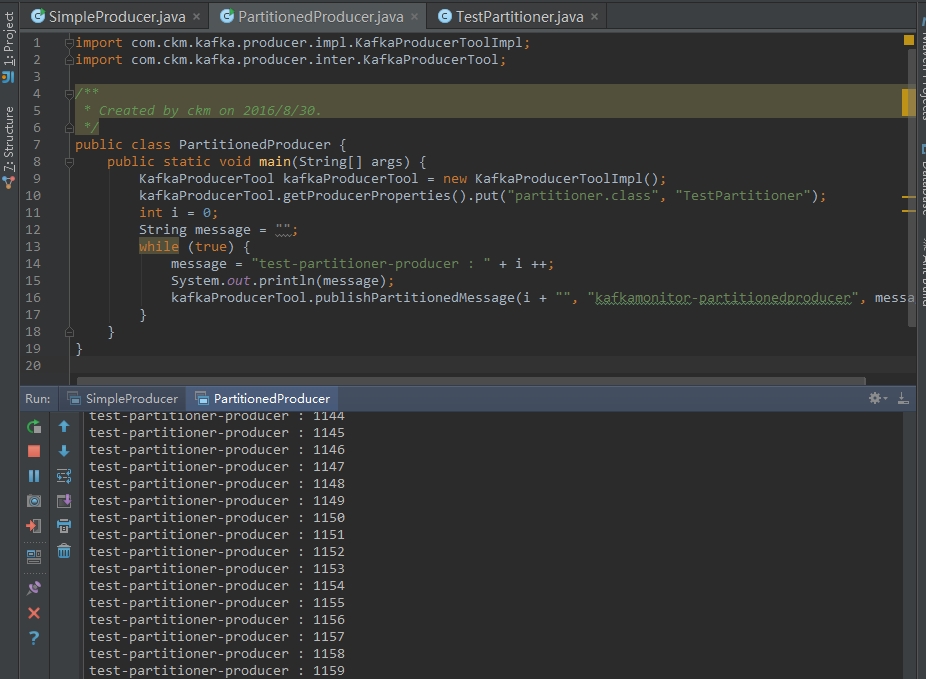
public class PartitionedProducer {
public static void main(String[] args) {
KafkaProducerTool kafkaProducerTool = new KafkaProducerToolImpl();
kafkaProducerTool.getProducerProperties().put("partitioner.class", "TestPartitioner");
int i = 0;
String message = "";
while (true) {
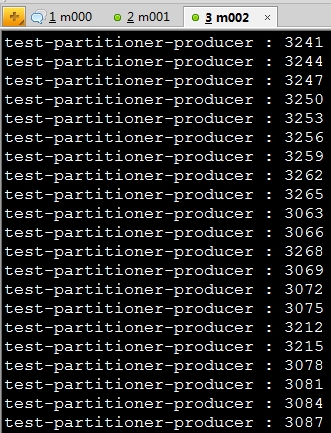
message = "test-partitioner-producer : " + i;
System.out.println(message);
kafkaProducerTool.publishPartitionedMessage("kafkamonitor-partitionedproducer", i + "", message);
i ++;
}
}
} 代码运行效果如下图:
bin/kafka-console-consumer.sh --zookeeper m000:2181 --from-beginning --topic kafkamonitor-partitionedproducer 消费效果如下图:
其他页面与上面的类似,这里只观察一下每个partition中的message数目与第二节中的对比。可以看到这里每个Partition中message分别是很均匀的。
注意事项:
注意这里有一个坑,默认情况下Producer往一个不存在的Topic发送message时会自动创建这个Topic。由于在这个封装中,有同时传递message和topic的情况,如果调用方法时传入的参数反了,将会在Kafka集群中自动创建Topic。在正常情况下,应该是先把Topic根据需要创建好,然后Producer往该Topic发送Message,最好把Kafka这个默认自动创建Topic的功能关掉。
那么,假设真的不小心创建了多余的Topic,在删除时,会出现“marked for deletion”提示,只是将该topic标记为删除,使用list命令仍然能看到。如果需要调整这两个功能的话,在server.properties中配置如下两个参数:
| 参数 | 默认值 | 作用 |
|---|---|---|
| auto.create.topics.enable | true | Enable auto creation of topic on the server |
| delete.topic.enable | false | Enables delete topic. Delete topic through the admin tool will have no effect if this config is turned off |