建立一个高可用的MQTT物联网集群How to Build an High Availability MQTT Cluster for the Internet of Things
- -建立一个高可用的MQTT物联网集群. We were searching for a secure (auth based), customisable (communicating with our REST API) and easy to use solution (we knew Node.js).
MQTT is a machine-to-machine (M2M)/“Internet of Things” connectivity protocol. It was designed as an extremely lightweight publish/subscribe messaging protocol and it is useful for connections with remote locations where a small code footprint is required and network bandwidth is at a premium.

The first time we looked for an MQTT solution was two years ago. We were searching for a secure (auth based), customisable (communicating with our REST API) and easy to use solution (we knew Node.js). We found in Moscathe right solution and, after two years, we’re happy with our choice ☺
The key metrics influencing your MQTT server choice could be different from ours. If so, check out this listof MQTT servers and their capabilities.
We’re not going to describe every single line of code, but we’ll show you two main sections, showing how simple can be setting up an MQTT server.
The code we use to run MQTT server on Lelylan is available on Github.
Setting up the MQTT server
The code below is used to start the MQTT server. First we configure the pub/sub settings using Redis, we pass the pub/sub settings object to our server and we are done.
If you ask yourself, why Redis is needed as pub/sub solution, read the Q1 on FAQ. Being short we need it to enable a communication channel between the MQTT server and other microservicescomposing Lelylan.
Authenticating the physical objects
With Mosca you can authorize a client defining three methods, each of them used to restrict the accessible topics for a specific clients.
#authenticate
#authorizePublish
#authorizeSubscribe
In Lelylan we use the authenticate methodto verify the client username and password. If the authentication is successful, the device_idis saved in the client object ,and used later on to authorize (or not) the publish and subscribe functionalities.
If you want to learn more about MQTT and Lelylan check out the dev center.
Dockeris an awesome tool to deploy production systems. It allows you to isolate your code in a clean system environment by defining a Dockerfile, an installation “recipe” used to initialize a system environment.

Container definition
To build a container around our application, we first need to create a file named Dockerfile. In here we’ll place all the needed commands Docker uses to initialize the desired environment.
In the Dockerfile used to create a container around the MQTT server we ask for a specific Node.js version ( FROM node:0.10-onbuild), add all files of the repo ( ADD ./ .), install the node packages ( RUN npm install), expose the port 1883 ( EXPOSE 1883)and finally run the node app ( ENTRYPOINT [“node”, “app.js”]).That’s all.
Run the Docker Image
Once we have a Dockerfile, we can build a docker container (if you haven’t Docker installed, do so- it supports all existing platforms, even Windows ☺). Once you have docker installed, we can build the container.
# building a container
$ docker build -t lelylan/mqtt
Which will eventually output
Successfully built lelylan/mqtt
Once we have built the container, we can run it to get a working image.
docker run -p 1883:1883 -d lelylan/mqtt
And we’re done! We now can make requests to our MQTT server.
When starting with Docker, it’s easy to make little confusion between containers and images. Read out what bothof themmeans to make your mind clearer.
# OSX
$ http://$(boot2docker ip):1883
# Linux
$ http://localhost:1883
If you’re using OS X we’re using boot2docker which is actually a Linux VM, we need to use the $DOCKER_HOST environment variable to access the VM’s localhost, otherwise, if you’re using Linux use localhost.
Other commands we were using a lot
While learning how to use Docker, we wrote down a common to use list of commands. They all are basic, but we think it’s good to have a reference to look at when needed.
Container related commands
# build and run a container without a tag
$ docker build .
$ docker run -p 80:1883 <CONTAINER_ID>
# build and run a container using a tag
$ docker build -t <USERNAME>/<PROJECT_NAME>:<V1>
$ docker run -p 80:1883 -d <USERNAME>/<PROJECT_NAME>:<V1>
Image related commands
# Run interactively into the image
$ docker run -i <IMAGE_ID> /bin/bash
# Run image with environment variables (place at the beginning)
$ docker run -e "VAR=VAL" -p 80:1883 <IMAGE_ID>
# list all running images
$ docker ps
# List all running and not running images
# (useful to see also images that exited because of an error).
$ docker ps -a
Kill images
# Kill all images
docker ps -a -q | xargs docker rm -f
Log related commands
# See logs for a specific image
docker logs <IMAGE_ID>
# See logs using the tail mode
docker logs -f <IMAGE_ID>
At this point we have a dockerized MQTT server being able to receive connections from any physical object (client). The missing thing is that it doesn’t scale, not yet ☺.
Here comes HAProxy, a popular TCP/HTTP load balancer and proxying solution used to improve the performance and the reliability of a server environment, distributing the workload across multiple servers. It is written in C and has a reputation for being fast and efficient.
Before showing how we used HAProxy, there are some concepts you need to know when using a load balancing.
If curious, you can find a lot of useful info in this articlewritten by Mitchell Anicas
Access Control List (ACL)
ACLs are used to test some condition and perform an action (e.g. select a server, or block a request) based on the test result. Use of ACLs allows flexible network traffic forwarding based on a different factors like pattern-matching or the number of connections to a backend.
# This ACL matches if the path of user’s request begins with /blog
# (this would match a request of http://example.org/blog/entry-1)
acl url_blog path_beg /blog
A backend is a set of servers that receives forwarded requests. Generally speaking, adding more servers to your backend will increase your potential load capacity and reliability by spreading the load over them. In the following example there is a backend configuration, with two web servers listening on port 80.
backend web-backend
balance roundrobin
server web1 web1.example.org:80 check
server web2 web2.example.org:80 check
A frontend defines how requests are be forwarded to backends. Frontends are defined in the frontendsection of the HAProxy configuration and they put together IP addresses, ACLs and backends. In the following example, if a user requests example.com/blog, it’s forwarded to the blogbackend, which is a set of servers that run a blog application. Other requests are forwarded to web-backend, which might be running another application.
frontend http
bind *:80
mode http
acl url_blog path_beg /blog
use_backend blog-backend if url_blog
default_backend web-backend
The code we used to run the HAProxy server on Lelylan is defined by a Dockerfile and a configuration file describing how requests are handled.
The code we use to run HAProxy is available on Github
Get your HAProxy container from Docker Hub
To get started download the HAProxy container from the public Docker Hub Registry(it contains an automated build ready to be used).
$ docker pull dockerfile/haproxy
At this point run the HAProxy container.
$ docker run -d -p 80:80 dockerfile/haproxy
The HAProxy container accepts a configuration file as data volume option (as you can see in the example below), where <override-dir>is an absolute path of a directory that contains haproxy.cfg (custom config file) and errors/ (custom error responses).
# Run HAProxy image with a custom configuration file
$ docker run -d -p 1883:1883 \
-v <override-dir>:/haproxy-override dockerfile/haproxy
This is perfect to test out a configuration file
HAProxy Configuration
Follows the configuration for our MQTT servers, where HAProxy listens for all requests coming to port 1883, forwarding them to two MQTT servers (mosca_1 and mosca_2) using the leastconnbalance mode (selects the server with the least number of connections).
2. To see the final configurations used by Lelylan checkout haproxy.cfgon Github. 1. During the HAProxy introduction we described the ACL, backend and frontend concepts. Here we used listen, a shorter but less expressive way to define all these concepts together. We used it because of some problems we had using backend and frontend. If you find out a working configuration using them, let us know.
To try out the new configuration (useful on development), override the default ones by using the data volume option. In the following example we override haproxy-overridewith the configuration file defined in /root/haproxy-override/.
$ docker run -d -p 80:80 1883:1883 \
-v /root/haproxy-override:/haproxy-override
dockerfile/haproxy
Create your HAProxy Docker Container
Once we have a working configuration, we can create a new HAProxy container using it. All we need to do is to define a Dockerfile loading the HAProxy container ( FROM dockerfile/haproxy)to which we replace the configuration file defined in /etc/haproxy/haproxy.cfg ( ADD haproxy.cfg /etc/haproxy/haproxy.cfg).We then restart the HAProxy server ( CMD [“bash”, “/haproxy-start”]) and expose the desired ports (80/443/1883/8883).
NOTE. We restart HAProxy, not simply start, because when loading the initial HAProxy container, HAProxy is already running. This means that when we change the configuration file, we need to give a fresh restart to load it.
Extra tips for HAProxy
When having troubles with HAProxy, read the logs! HAProxy uses rsyslog, a rocket-fast system for log processing, used by default in Ubuntu.
# HAProxy log configuration file
$ vi /etc/rsyslog.d/haproxy.conf
# Files where you can find the HAProxy logs
$ tail -f /var/lib/haproxy/dev/log
$ tail -f /var/log/haproxy.log
We now have a scalable MQTT infrastructure where all requests are proxied by HAProxy to two (or more) MQTT servers. The next step is to make the communication secure using SSL.
Native SSL support was implemented in HAProxy 1.5.x, which was released as a stable version in June 2014.
SSL (Secure Sockets Layer) is the accepted standard for encrypted communication between a server and a client ensuring that all data passed between the server and client remain private and integral.
First of all you need an SSL certificate. To implement SSL with HAProxy, the SSL certificate and key pair must be in the proper format: PEM.
In most cases, you simply combine your SSL certificate (.crt or .cer file provided by a certificate authority) and its respective private key (.key file, generated by you). Assuming that the certificate file is called lelylan.com.crt, and your private key file is called lelylan.com.key, here is an example of how to combine the files creating the PEM file lelylan.com.pem.
cat lelylan.com.crt lelylan.com.key > lelylan.com.pem
As always, be sure to secure any copies of your private key file, including the PEM file (which contains the private key).
Once we’ve created our SSL certificate, we can’t save it in a public repo. You know, security ☺. What we have to do is to place it in the HAProxy server, making it accessible form Docker through data volumes.
What is Docker data volumes?
A data volume is a specially-designated directory within one or more containers that provide useful features shared data. You can add a data volume to a container using the -v flag to share any file/folder, using -v multiple times to mount multiple data volumes (we already used it when loading a configuration file for the HAProxy container).
Using data volumes to share an SSL certificate.
To share our SSL certificate, we placed it in /certs(in the HAProxy server), making it accessible through the /certs folder when running the Docker Container.
$ docker run -d -p 80:80 -p 443:443 -p 1883:1883 -p 8883:8883 \
-v /certs:/certs
-v /root/haproxy-override:/haproxy-override
Don’t forget to open the port 8883 (the default one for secure MQTT connections)
Loading the SSL certificate
Once we have the SSL certificate available through Docker data volume, we can access it during through the HAProxy configuration file. All we need to do is to add one line of code to map the requests coming to the 8883 port to the SSL certificate placed in /certsand named lelylan.pem.
We’re done!
At this point we have a Secure, High Availability MQTT Cluster for the Internet of Things. Below, you can see an image representing the final result.
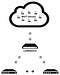
At this point, there’s one thing to make the architecture complete: we need a simple way to deploy it.
To make this possible we’ll use nscale, an open source project to configure, build and deploy a set of connected containers.
While we’ll describe some of the most important commands used by nscale, hereyou can find a guide describing step by step how nscale works.
Digital Oceanis a simple cloud hosting, built for developers. For our deployment solution , all the droplets we’ll use, are based on Ubuntu and have Docker already installed.
Do not have a Digital Ocean account? Sign up through this linkand get 10$ credit.
The first thing we had to do was to create 5 droplets, each of them dedicated to a specific app: 1 management machine (where the nscale logic will live), 1 HAProxy load balancer, 2 MQTT Mosca servers and 1 Redis server.

List of Droplets created for this tutorial on Digital Ocean.
We’re now ready to install nscale into the management machinedefined on Digital Ocean. We could also have used our local machine, but having a dedicated server for this, make it simple for all team members to deploy new changes.
Installation
Install Node.js via nvm (Node Version Manager).
curl https://raw.githubusercontent.com/creationix/nvm/v0.18.0/install.sh | bash
Logoff, login and run the following commands.
# install needed dependencies
apt-get update
apt-get install build-essential
# install node and npm
nvm install v0.10.33
nvm alias default v0.10.33
npm install npm@latest -g --unsafe-perm
# install nscale
npm install nscale -g --unsafe-perm
The installation could take a while, it’s normal ☺
Github user configuration
To use nscale you need to configure GIT.
git config --global user.name "<YOUR_NAME>"
git config --global user.email "<YOUR_EMAIL>"
Create your first nscale project
Once all the configurations are done, login into nscale.
$ nsd login
At this point we can create our first nscale project, where you’ll be asked to set a nameand a namespace (we used the same name for both of them ).
$ nsd sys create
1. Set a name for your project: <NAME>
2. Set a namespace for your project: <NAMESPACE>
This command will result into an automatically generated project folder with the following structure (don’t worry about all the files you see; the only ones we need to take care of are definition/services.jsand system.js).
|— definitions
| |— machines.js
| `— services.js *
|— deployed.json
|— map.js
|— npm-debug.log
|— README.md
|— sudc-key
|— sudc-key.pub
|— system.js *
|— timeline.json
`— workspace
...
At this point use the list command to see if the new nscale project is up and running. If everything is fine, you’ll see the project name and Id.
$ nsd sys list
Name Id
lelylan-mqtt 6b4b4e3f-f22e-4516-bffb-e1a8daafb3ea
Secure access (from nscale to other servers)
To access all servers nscale will configure, it needs a new ssh key for secure authentication solution with no passphrase.
ssh-keygen -t rsa
Type no passphrase, and save it with your project name. In our case we called it lelyan-key (remember that the new ssh key needs to live in the nscale project root, not in ~/.ssh/). Once the ssh key is created, setup the public key in all the servers nscale needs to configure: haproxy, mosca 1, mosca 2and redis.
This can be done through the Digital Ocean dashboard or by adding the nscale public key to the authorized_keyswith the following command.
cat lelylan-key.pub | \
ssh <USER>@<IP-SERVER> "cat ~/.ssh/authorized_keys"
If some problems occur, connect first to the server through SSH
ssh <USER>@<IP-SERVER>
SSH Agent Forwarding
One more thing you need to do on your management server (where the nscale project is defined), is to set the SSH Agent Forwarding. This allows you to use your local SSH keys instead of leaving keys sitting on your server.
# ~/.ssh/config
Host *
ForwardAgent yes
There is an open issueon this for nscale. If you do not set this up the deployment with nscale will not work out.
We can now start configuring nscale, starting from the nscale analyzer, which defines the authorizations settings used to access the target machines. To make this possible edit ~/.nscale/config/config.jsonby setting the specificobject from:
{
...
"modules": {
...
"analysis": {
"require": "nscale-local-analyzer",
"specific": {
}
}
...
} to:
{
...
"modules": {
...
"analysis": {
"require": "nscale-direct-analyzer",
"specific": {
"user": "root",
"identityFile": "/root/lelylan/lelylan-key"
}
}
} Adjust this config if you named your project and your key differently.
All we did was to populate the specificobject with the user(root) and the identity file(ssh key ) (this step will likely not be needed in a next release).
In nscale we can define different processes, where every process is a Docker container identified by a name, a Github repo (with the container source code) and a set of arguments Docker uses to run the image.
If you noticed that redis has not a Github repo, contgrats! At this point of the article shouldn’t be easy☺. For Redis we do not need the Github repo as we directly use the redis image defined in Docker Hub.
In this case we have 3 different type of processes: haproxy, mqttand redis.
Now that we’ve defined the processes we want to run, we can tell nscale where each of them should live on Digital Ocean through the system.jsdefinition.
As you can see, system.jsdefines every machine setup. For each of them, we define the running processes (you need to use one between the ones previously defined in services.js), the machine IP address, the user that can log in and and the ssh key name used to authorize the access.
What if I want to add a new MQTT server
Add a new machine to the nscale system.jsdefinition, the new server to the HAproxy configuration and you’re ready to go.
It’s deploying time☺
We can now compile, build and deploy our infrastructure.
# Compile the nscale project
nsd sys comp direct
# Build all containers
# (grab a cup of coffee, while nscale build everything)
nsd cont buildall
# Deploy the latest revision on Digital Ocean
nsd rev dep head
While we described the configurations needed to deploy on Digital Ocean, nscale is also good to run all services locally.
You’re done!
Once the setup is done, with the previous three commands, we’re ready to deploy an high availability MQTT cluster for the Internet of Things, adding new MQTT servers and scaling our infrastructure in a matter of minutes.
This article comes from the work I’ve made in Lelylan, an Open Source Cloud Platform for the Internet of Things. If you find this article useful, give us a star on Github(it will help to reach more developers).
In this article we showed how to build an high availability MQTT cluster for the Internet of Things. All of the code we use in production is now released as Open Source as follow.
We’ll soon release also the nscale project (right now it contains some sensible information and we need to remove them from the repo).
Many thanks to nearFormand Matteo Collina(author of Mosca and part of the nscale team) for helping us answering any question we had about nscale and the MQTT infrastructure.
Building, testing and securing such an infrastructure took several months of work. We really hope that releasing it as Open Source will help you guys on building MQTT platforms in a shorter time.
Not satisfied? If you want to learn more about some of the topics we talked about, read out the following articles!