NLP历史突破!谷歌BERT模型狂破11项纪录,全面超越人类!
- - 博客园_新闻来源:新智元(AI_era). (来源:arXiv、知乎;编辑:新智元编辑部). 今天,NLP 领域取得最重大突破. 谷歌 AI 团队新发布的 BERT 模型,在机器阅读理解顶级水平测试 SQuAD1.1 中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在 11 种不同 NLP 测试中创出最佳成绩.

来源:新智元(AI_era)
(来源:arXiv、知乎;编辑:新智元编辑部)
今天,NLP 领域取得最重大突破!谷歌 AI 团队新发布的 BERT 模型,在机器阅读理解顶级水平测试 SQuAD1.1 中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在 11 种不同 NLP 测试中创出最佳成绩。毋庸置疑,BERT 模型开启了 NLP 的新时代!
今天请记住 BERT 模型这个名字。
谷歌 AI 团队新发布的 BERT 模型,在机器阅读理解顶级水平测试 SQuAD1.1 中表现出惊人的成绩:全部两个衡量指标上全面超越人类!并且还在 11 种不同 NLP 测试中创出最佳成绩,包括将 GLUE 基准推至 80.4%(绝对改进 7.6%),MultiNLI 准确度达到 86.7%(绝对改进率 5.6%)等。

谷歌团队的 Thang Luong 直接定义:BERT 模型开启了 NLP 的新时代!
本文从论文解读、BERT 模型的成绩以及业界的评价三方面做介绍。
硬核阅读:认识 BERT 的新语言表示模型
首先来看下谷歌 AI 团队做的这篇论文(论文地址: https://arxiv.org/abs/1810.04805)。

BERT 的新语言表示模型,它代表 Transformer 的双向编码器表示。与最近的其他语言表示模型不同,BERT 旨在通过联合调节所有层中的上下文来预先训练深度双向表示。因此,预训练的 BERT 表示可以通过一个额外的输出层进行微调,适用于广泛任务的最先进模型的构建,比如问答任务和语言推理,无需针对具体任务做大幅架构修改。
论文作者认为现有的技术严重制约了预训练表示的能力。其主要局限在于标准语言模型是单向的,这使得在模型的预训练中可以使用的架构类型很有限。
在论文中,作者通过提出 BERT:即 Transformer 的双向编码表示来改进基于架构微调的方法。
BERT 提出一种新的预训练目标:遮蔽语言模型(masked language model,MLM),来克服上文提到的单向性局限。MLM 的灵感来自 Cloze 任务(Taylor, 1953)。MLM 随机遮蔽模型输入中的一些 token,目标在于仅基于遮蔽词的语境来预测其原始词汇 id。
与从左到右的语言模型预训练不同,MLM 目标允许表征融合左右两侧的语境,从而预训练一个深度双向 Transformer。除了遮蔽语言模型之外,本文作者还引入了一个“下一句预测”(next sentence prediction)任务,可以和 MLM 共同预训练文本对的表示。
论文的核心:详解 BERT 模型架构
本节介绍 BERT 模型架构和具体实现,并介绍预训练任务,这是这篇论文的核心创新。
模型架构
BERT 的模型架构是基于 Vaswani et al. (2017) 中描述的原始实现 multi-layer bidirectional Transformer 编码器,并在 tensor2tensor 库中发布。由于 Transformer 的使用最近变得无处不在,论文中的实现与原始实现完全相同,因此这里将省略对模型结构的详细描述。
在这项工作中,论文将层数(即 Transformer blocks)表示为L,将隐藏大小表示为H,将 self-attention heads 的数量表示为A。在所有情况下,将 feed-forward/filter 的大小设置为 4H,即 H = 768 时为 3072,H = 1024 时为 4096。论文主要报告了两种模型大小的结果:
- BERT BASE: L=12, H=768, A=12, Total Parameters=110M
- BERT LARGE: L=24, H=1024, A=16, Total Parameters=340M
为了进行比较,论文选择 BERT LARGE,它与 OpenAI GPT 具有相同的模型大小。然而,重要的是,BERT Transformer 使用双向 self-attention,而 GPT Transformer 使用受限制的 self-attention,其中每个 token 只能处理其左侧的上下文。研究团队注意到,在文献中,双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,因为它可以用于文本生成。BERT,OpenAI GPT 和 ELMo 之间的比较如图 1 所示。
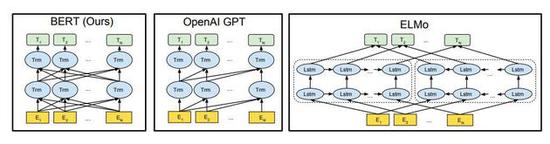
图1:预训练模型架构的差异。BERT 使用双向 Transformer。OpenAI GPT 使用从左到右的 Transformer。ELMo 使用经过独立训练的从左到右和从右到左 LSTM 的串联来生成下游任务的特征。三个模型中,只有 BERT 表示在所有层中共同依赖于左右上下文。
输入表示(input representation)
论文的输入表示(input representation)能够在一个 token 序列中明确地表示单个文本句子或一对文本句子(例如, [Question, Answer])。对于给定 token,其输入表示通过对相应的 token、segment 和 position embeddings 进行求和来构造。图 2 是输入表示的直观表示:
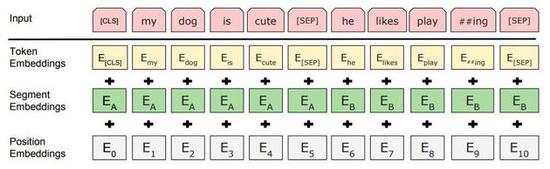
图2:BERT 输入表示。输入嵌入是 token embeddings, segmentation embeddings 和 position embeddings 的总和。
具体如下:
- 使用 WordPiece 嵌入(Wu et al., 2016)和 30,000 个 token 的词汇表。用##表示分词。
- 使用学习的 positional embeddings,支持的序列长度最多为 512 个 token。
- 每个序列的第一个 token 始终是特殊分类嵌入([CLS])。对应于该 token 的最终隐藏状态(即,Transformer 的输出)被用作分类任务的聚合序列表示。对于非分类任务,将忽略此向量。
- 句子对被打包成一个序列。以两种方式区分句子。首先,用特殊标记([SEP])将它们分开。其次,添加一个 learned sentence A 嵌入到第一个句子的每个 token 中,一个 sentence B 嵌入到第二个句子的每个 token 中。
- 对于单个句子输入,只使用 sentence A 嵌入。
关键创新:预训练任务
与 Peters et al. (2018) 和 Radford et al. (2018) 不同,论文不使用传统的从左到右或从右到左的语言模型来预训练 BERT。相反,使用两个新的无监督预测任务对 BERT 进行预训练。
任务1:Masked LM
从直觉上看,研究团队有理由相信,深度双向模型比 left-to-right 模型或 left-to-right and right-to-left 模型的浅层连接更强大。遗憾的是,标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件作用将允许每个单词在多层上下文中间接地“see itself”。
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入 token,然后只预测那些被屏蔽的 token。论文将这个过程称为“masked LM”(MLM),尽管在文献中它经常被称为 Cloze 任务(Taylor, 1953)。
在这个例子中,与 masked token 对应的最终隐藏向量被输入到词汇表上的输出 softmax 中,就像在标准 LM 中一样。在团队所有实验中,随机地屏蔽了每个序列中 15% 的 WordPiece token。与去噪的自动编码器(Vincent et al., 2008)相反,只预测 masked words 而不是重建整个输入。
虽然这确实能让团队获得双向预训练模型,但这种方法有两个缺点。首先,预训练和 finetuning 之间不匹配,因为在 finetuning 期间从未看到[MASK]token。为了解决这个问题,团队并不总是用实际的[MASK]token 替换被“masked”的词汇。相反,训练数据生成器随机选择 15% 的 token。例如在这个句子“my dog is hairy”中,它选择的 token 是“hairy”。然后,执行以下过程:
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
- 80% 的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
- 10% 的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
- 10% 的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
Transformer encoder 不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入 token 的分布式上下文表示。此外,因为随机替换只发生在所有 token 的 1.5%(即 15% 的 10%),这似乎不会损害模型的语言理解能力。
使用 MLM 的第二个缺点是每个 batch 只预测了 15% 的 token,这表明模型可能需要更多的预训练步骤才能收敛。团队证明 MLM 的收敛速度略慢于 left-to-right 的模型(预测每个 token),但 MLM 模型在实验上获得的提升远远超过增加的训练成本。
任务2:下一句预测
许多重要的下游任务,如问答(QA)和自然语言推理(NLI)都是基于理解两个句子之间的关系,这并没有通过语言建模直接获得。
在为了训练一个理解句子的模型关系,预先训练一个二进制化的下一句测任务,这一任务可以从任何单语语料库中生成。具体地说,当选择句子A和B作为预训练样本时,B有 50% 的可能是A的下一个句子,也有 50% 的可能是来自语料库的随机句子。例如:
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
团队完全随机地选择了 NotNext 语句,最终的预训练模型在此任务上实现了 97%-98% 的准确率。
实验结果
如前文所述,BERT 在 11 项 NLP 任务中刷新了性能表现记录!在这一节中,团队直观呈现 BERT 在这些任务的实验结果,具体的实验设置和比较请阅读原论文。
![图3:我们的面向特定任务的模型是将 BERT 与一个额外的输出层结合而形成的,因此需要从头开始学习最小数量的参数。在这些任务中,(a)和(b)是序列级任务,而(c)和(d)是 token 级任务。在图中,E表示输入嵌入,Ti 表示 tokeni 的上下文表示,[CLS]是用于分类输出的特殊符号,[SEP]是用于分隔非连续 token 序列的特殊符号。](http://img2018.cnblogs.com/news/66372/201810/66372-20181013173033752-871756836.jpg)
图3:我们的面向特定任务的模型是将 BERT 与一个额外的输出层结合而形成的,因此需要从头开始学习最小数量的参数。在这些任务中,(a)和(b)是序列级任务,而(c)和(d)是 token 级任务。在图中,E表示输入嵌入,Ti 表示 tokeni 的上下文表示,[CLS]是用于分类输出的特殊符号,[SEP]是用于分隔非连续 token 序列的特殊符号。
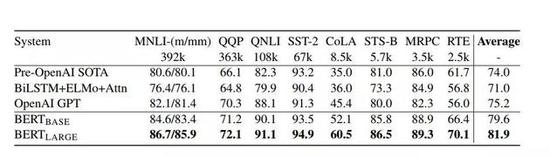
图4:GLUE 测试结果,由 GLUE 评估服务器给出。每个任务下方的数字表示训练样例的数量。“平均”一栏中的数据与 GLUE 官方评分稍有不同,因为我们排除了有问题的 WNLI 集。BERT 和 OpenAI GPT 的结果是单模型、单任务下的数据。所有结果来自 https://gluebenchmark.com/leaderboard 和 https://blog.openai.com/language-unsupervised/
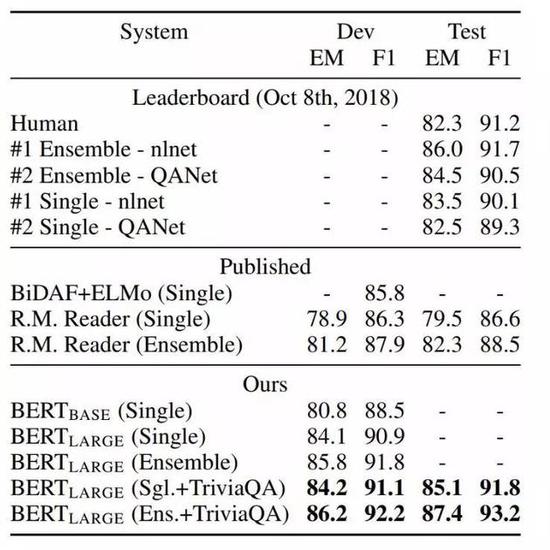
图5:SQuAD 结果。BERT 集成是使用不同预训练检查点和微调种子(fine-tuning seed)的 7x 系统。
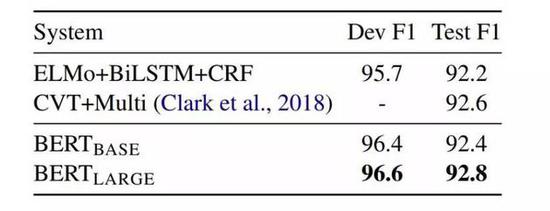
图6:CoNLL-2003 命名实体识别结果。超参数由开发集选择,得出的开发和测试分数是使用这些超参数进行五次随机重启的平均值。
超过人类表现,BERT 刷新了 11 项 NLP 任务的性能记录
论文的主要贡献在于:
- 证明了双向预训练对语言表示的重要性。与之前使用的单向语言模型进行预训练不同,BERT 使用遮蔽语言模型来实现预训练的深度双向表示。
- 论文表明,预先训练的表示免去了许多工程任务需要针对特定任务修改体系架构的需求。BERT 是第一个基于微调的表示模型,它在大量的句子级和 token 级任务上实现了最先进的性能,强于许多面向特定任务体系架构的系统。
- BERT 刷新了 11 项 NLP 任务的性能记录。本文还报告了 BERT 的模型简化研究(ablation study),表明模型的双向性是一项重要的新成果。相关代码和预先训练的模型将会公布在 goo.gl/language/bert 上。
BERT 目前已经刷新的 11 项自然语言处理任务的最新记录包括:将 GLUE 基准推至 80.4%(绝对改进 7.6%),MultiNLI 准确度达到 86.7%(绝对改进率 5.6%),将 SQuAD v1.1 问答测试 F1 得分纪录刷新为 93.2 分(绝对提升 1.5 分),超过人类表现 2.0 分。
BERT 模型重要意义:宣告 NLP 范式的改变
北京航空航天大学计算机专业博士吴俣在知乎上写道:BERT 模型的地位类似于 ResNet 在图像,这是里程碑式的工作,宣告着 NLP 范式的改变。以后研究工作估计很多都要使用他初始化,就像之前大家使用 word2vec 一样自然。
BERT 一出,那几个他论文里做实验的数据集全被轰平了,大家洗洗睡了。心疼 swag 一秒钟,出现 3 月,第一篇做这个数据集的算法,在超了 baseline 20 多点的同时也超过人了。
通过 BERT 模型,吴俣有三个认识:
1、Jacob 在细节上是一等一的高手
这个模型的双向和 Elmo 不一样,大部分人对论文作者之一 Jacob 的双向在 novelty 上的 contribution 的大小有误解,我觉得这个细节可能是他比 Elmo 显著提升的原因。Elmo 是拼一个左到右和一个右到左,他这个是训练中直接开一个窗口,用了个有顺序的 cbow。
2、Reddit 对跑一次 BERT 的价格讨论
For TPU pods:
4 TPUs * ~$2/h (preemptible) * 24 h/day * 4 days = $768 (base model)
16 TPUs = ~$3k (large model)
For TPU:
16 tpus * $8/hr * 24 h/day * 4 days = 12k
64 tpus * $8/hr * 24 h/day * 4 days = 50k
For GPU:
"BERT-Large is 24-layer, 1024-hidden and was trained for 40 epochs over a 3.3 billion word corpus. So maybe 1 year to train on 8 P100s? "
3、不幸的是,基本无法复现,所以模型和数据谁更有用也不好说。
BERT 的成功也说明,好的深度学习研究工作的三大条件:数据,计算资源,工程技能点很高的研究员(Jacob 在微软时候,就以单枪匹马搭大系统,而中外闻名)。