谈Elasticsearch下分布式存储的数据分布
- - IT瘾-geek 对于一个分布式存储系统来说,数据是分散存储在多个节点上的. 如何让数据均衡的分布在不同节点上,来保证其高可用性. 所谓均衡,是指系统中每个节点的负载是均匀的,并且在发现有不均匀的情况或者有节点增加/删除时,能及时进行调整,保持均匀状态. 本文将探讨Elasticsearch的数据分布方法,文中所述的背景是Elasticsearch 5.5.
对于一个分布式存储系统来说,数据是分散存储在多个节点上的。如何让数据均衡的分布在不同节点上,来保证其高可用性?所谓均衡,是指系统中每个节点的负载是均匀的,并且在发现有不均匀的情况或者有节点增加/删除时,能及时进行调整,保持均匀状态。本文将探讨Elasticsearch的数据分布方法,文中所述的背景是Elasticsearch 5.5。
在Elasticsearch中,以Shard为最小的数据分配/迁移单位。数据到节点的映射分离为两层:一层是数据到Shard的映射( Route),另一层是Shard到节点的映射( Allocate)。
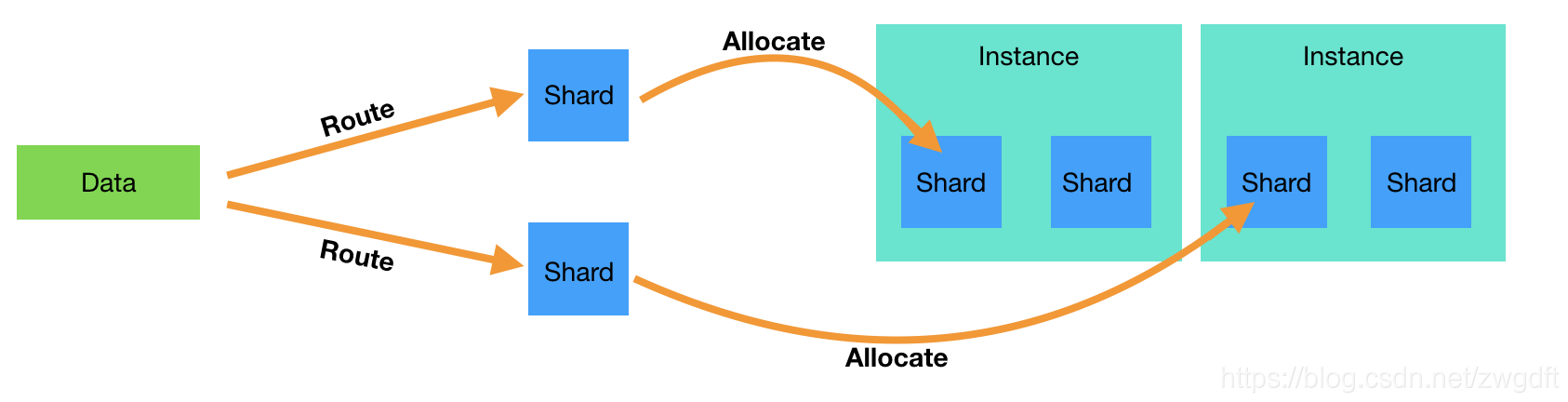
一方面,插入一条数据时,ES会根据指定的Key来计算应该落到哪个Shard上。默认Key是自动分配的id,可以自定义,比如在我们的业务中采用CompanyID作为Key。因为Primary Shard的个数是不允许改变的,所以同一个Key每次算出来的Shard是一样的,从而保证了准确定位。
shard_num = hash(_routing) % num_primary_shards 另一方面,Master会为每个Shard分配相应的Data节点进行存储,并维护相关元信息。通过Route计算出来的Shard序号,在元信息中找到对应的存储节点,便可完成数据分布。Shard Allocate的映射关系并不是完全不变的,当检测到数据分布不均匀、有新节点加入或者有节点挂掉等情况时就会进行调整,称为 Relocate。那么,Elasticsearch是根据什么规则来为Shard选取节点,从而保证数据均衡分布的?概括来看,主要有三方面的影响: 节点位置、 磁盘空间、 单个节点上的Index和Shard个数。
对于一个ES节点来说,它可能是某台物理机器上的一个VM,而这个物理机器位于某个Zone的某个机架(Rack)上。通过将Primary Shard和Replica Shard分散在不同的物理机器、Rack、Zone,可以尽可能的降低数据丢失和系统不可用的风险,这一点几乎在所有的分布式系统中都会考量。
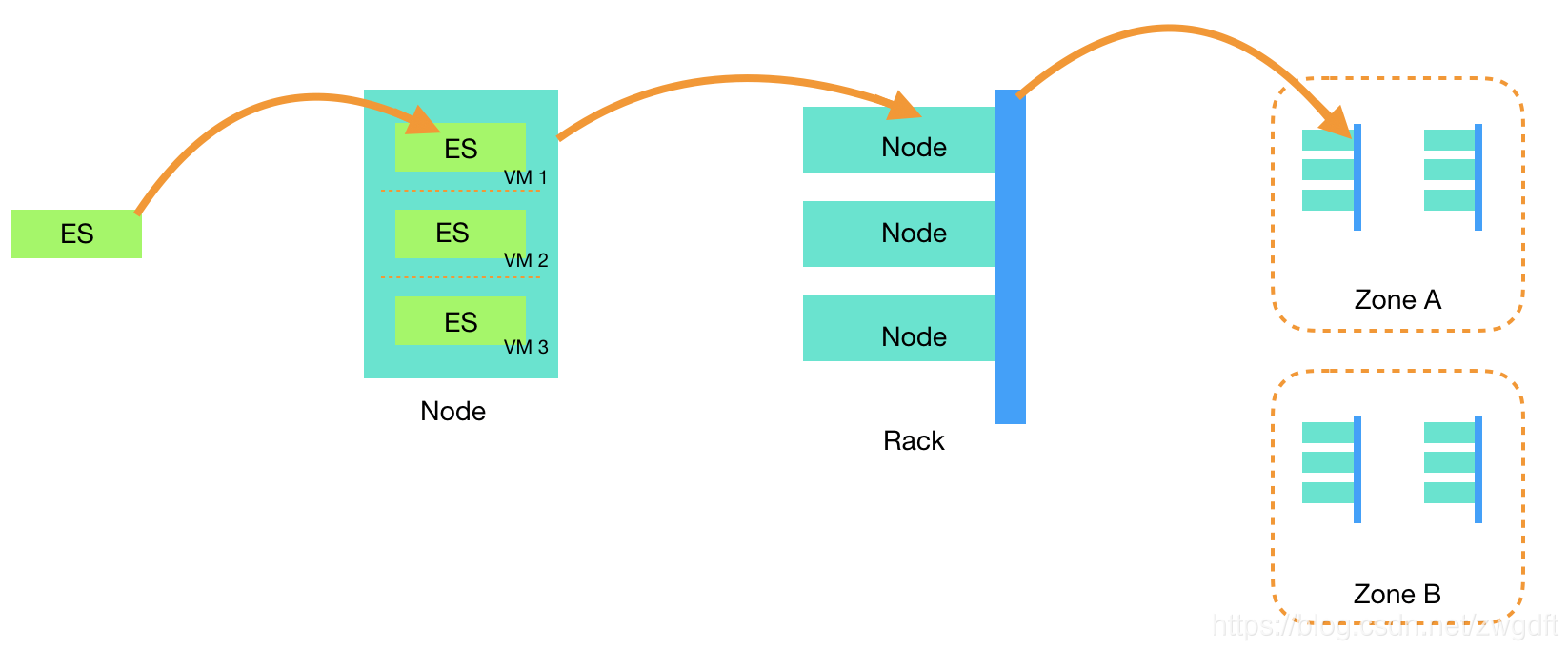
Elasticsearch是通过设置awareness.attribute对集群中的节点进行分组,从而实现Rack和Zone的发现。比如按照下列方式对elasticsearch.yml进行配置,再启动相应的节点,即可实现Zone的区分。
// elasticsearch.yml
cluster.routing.allocation.awareness.attributes: zone
// 启动ES
./bin/elasticsearch -Enode.attr.zone=zone_one
./bin/elasticsearch -Enode.attr.zone=zone_two 实践中,如果使用了这样的Awareness机制,应该保证不同分组类的机器个数一致,不会发生倾斜。比如,在Zone Awareness下,如果集群有10台机器,应该保证每个Zone各有5台机器(2个Zone)。
磁盘空间是制约存储的硬性条件,单机的可用磁盘空间决定了能否继续往这个节点写入新数据、分配新Shard以及是否需要迁移数据等。在ES中,有三个参数用来控制与此相关的特性,默认每30秒检查一次。

在满足节点位置和磁盘空间的条件后,单个节点上的Index和Shard个数是否均匀,决定了Shard可以分配/迁移到哪个节点。ES通过计算权值来量化这样的分配方式。
以检测某个Shard是否需要迁移到其他节点为例,ES会先计算该Shard所在节点(A)的权值,然后依次跟其他节点的权值比较,如果与节点B的差值(Delta-A)超过了阈值,再进一步计算节点A去掉该Shard后的权值与节点B增加该Shard后的权值之间的差值(Delta-B),如果Delta-A大于Delta-B,则表明Shard可以迁移到节点B。
这里的权值计算简化如下,其中indexBalance与shardBalance分别由参数控制,而阈值由cluster.routing.allocation.balance.threshold设置,默认为1.0f。当然,这里只描述了核心思想,详细逻辑请阅读 BalancedShardsAllocator.java中的源码。通过调整三个参数,可以控制策略的松紧。
// indexBalance = cluster.routing.allocation.balance.index, default is 0.55f
// shardBalance = cluster.routing.allocation.balance.shard, default is 0.45f
float sum = indexBalance + shardBalance;
float theta0 = shardBalance / sum;
float theta1 = indexBalance / sum;
private float weight(Balancer balancer, ModelNode node, String index, int numAdditionalShards) {
final float weightShard = node.numShards() + numAdditionalShards - balancer.avgShardsPerNode();
final float weightIndex = node.numShards(index) + numAdditionalShards - balancer.avgShardsPerNode(index);
return theta0 * weightShard + theta1 * weightIndex;
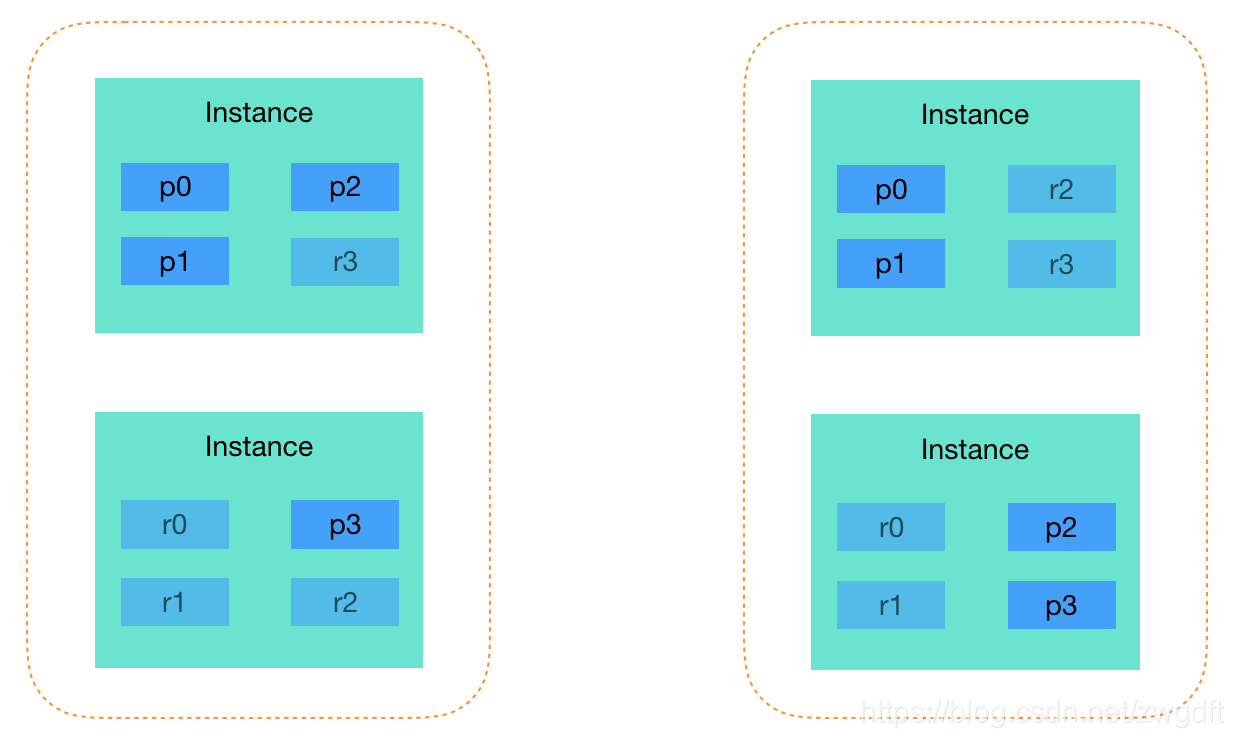
} 最初关注Elasticsearch的数据分布,是因为在性能调优时遇到了一个与Primary/Replica分布有关的问题。背景是这样的,为了能够复用单个节点上的Disk Cache,我们对查询请求进行了限制,只允许其访问Primary Shard。然而总是有那么一两台机器的查询会被Queue住,通过调研发现,这些机器上面的Primary Shard比其他机器多(对某一个Index而言),即下图中左边所示,而我们希望的是右图所示的均匀分布。
引起这个问题的根源是,Elasticsearch中的Shard均匀分布是针对Primary+Replica整体而言的,也就是说没法做到只针对Primary Shard单方面做均匀分布,所以才会出现下图左边所示,某个节点上有3个Primary Shard,而另一个节点只有1个。目前尚未发现可以调节的地方。
本文探讨了Elasticsearch的数据分布方法,其思想对很多其他分布式存储系统是通用的,而了解相关原理是做很多调优工作的前提。
(全文完,本文地址: https://blog.csdn.net/zwgdft/article/details/83478241)
(版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!)
Bruce
2018/10/30 晚