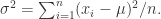
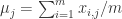


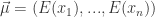
![\Sigma=[Cov(x_{i},x_{j})], i,j \in \{1,...,n\}](https://s0.wp.com/latex.php?latex=%5CSigma%3D%5BCov%28x_%7Bi%7D%2Cx_%7Bj%7D%29%5D%2C+i%2Cj+%5Cin+%5C%7B1%2C...%2Cn%5C%7D&bg=ffffff&fg=2b2b2b&s=0)










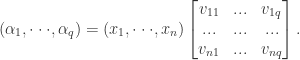
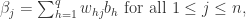










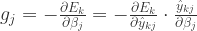



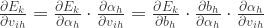






[原]异常检测--综述
- - 工作笔记异常点检测,有时也叫离群点检测,英文一般叫做Novelty Detection或者Outlier Detection,这里就对异常点检测算法做一个总结. 1. 异常点检测算法使用场景. 什么时候我们需要异常点检测算法呢. 一是在做特征工程的时候需要对异常的数据做过滤,防止对归一化等处理的结果产生影响.
异常点检测,有时也叫离群点检测,英文一般叫做Novelty Detection或者Outlier Detection,这里就对异常点检测算法做一个总结。
什么时候我们需要异常点检测算法呢?常见的有三种情况。一是在做特征工程的时候需要对异常的数据做过滤,防止对归一化等处理的结果产生影响。二是对没有标记输出的特征数据做筛选,找出异常的数据。三是对有标记输出的特征数据做二分类时,由于某些类别的训练样本非常少,类别严重不平衡,此时也可以考虑用非监督的异常点检测算法来做。
具体应用场景有,欺诈检测,入侵检测,生态系统失调,公共卫生,医疗等。
异常点检测的目的是找出数据集中和大多数数据不同的数据,常用的异常点检测算法一般分为三类。
第一类是基于统计学的方法来处理异常数据,这种方法一般会构建一个概率分布模型,并计算对象符合该模型的概率,把具有低概率的对象视为异常点。比如特征工程中的 RobustScaler方法,在做数据特征值缩放的时候,它会利用数据特征的分位数分布,将数据根据分位数划分为多段,只取中间段来做缩放,比如只取25%分位数到75%分位数的数据做缩放。这样减小了异常数据的影响。
第二类是基于聚类的方法来做异常点检测。这个很好理解,由于大部分聚类算法是基于数据特征的分布来做的,通常如果我们聚类后发现某些聚类簇的数据样本量比其他簇少很多,而且这个簇里数据的特征均值分布之类的值和其他簇也差异很大,这些簇里的样本点大部分时候都是异常点。比如 BIRCH聚类算法原理和 DBSCAN密度聚类算法都可以在聚类的同时做异常点的检测。
第三类是基于专门的异常点检测算法来做。这些算法不像聚类算法,检测异常点只是一个赠品,它们的目的就是专门检测异常点的,这类算法的代表是One Class SVM和Isolation Forest.
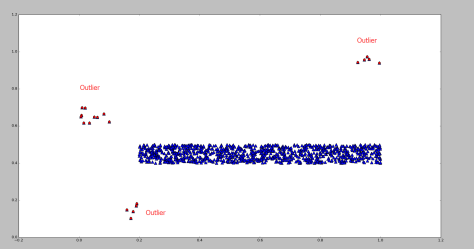
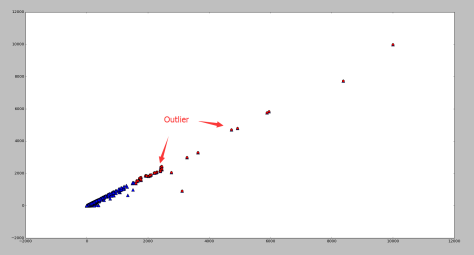
异常点(outlier)是一个数据对象,它明显不同于其他的数据对象,就好像它是被不同的机制产生的一样。例如下图红色的点,就明显区别于蓝色的点。相对于蓝色的点而言,红色的点就是异常点。

假设有 n 个点 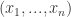

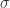
在正态分布的假设下,区域 
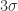
涉及两个或者两个以上变量的数据称为多元数据,很多一元离群点的检测方法都可以扩展到高维空间中,从而处理多元数据。
(1)基于一元正态分布的离群点检测方法
假设 n 维的数据集合形如 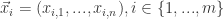
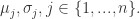

在正态分布的假设下,如果有一个新的数据 

根据概率值的大小就可以判断 x 是否属于异常值。运用该方法检测到的异常点如图,红色标记为异常点,蓝色表示原始的数据点。
(2)多元高斯分布的异常点检测
假设 n 维的数据集合 
和 
如果有一个新的数据
根据概率值的大小就可以判断
(3)使用 Mahalanobis 距离检测多元离群点
对于一个多维的数据集合 D,假设 

其中 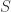
在这里, 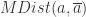

运用 Mahalanobis 距离方法检测到的异常点如图,红色标记为异常点,蓝色表示原始的数据点。

(4)使用 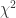
在正态分布的假设下, 
其中, 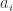
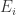
运用
在介绍这种方法之前,先回顾一下主成分分析(Principle Component Analysis)这一基本的降维方法。
对高维数据集合的简化有各种各样的原因,例如:
(1)使得数据集合更容易使用;
(2)降低很多算法的计算开销;
(3)去除噪声;
(4)更加容易的描述结果。
在主成分分析(PCA)这种降维方法中,数据从原来的坐标系转换到新的坐标系,新坐标系的选择是由数据集本身所决定的。第一个新坐标轴的方向选择的是原始数据集中方差最大的方向,第二个新坐标轴的选择是和第一个坐标轴正交并且具有最大方差的方向。该过程一直重复,重复的次数就是原始数据中特征的数目。如此操作下去,将会发现,大部分方差都包含在最前面的几个新坐标轴之中。因此,我们可以忽略余下的坐标轴,也就是对数据进行了降维的处理。
为了提取到第一个主成分(数据差异性最大)的方向,进而提取到第二个主成分(数据差异性次大)的方向,并且该方向需要和第一个主成分方向正交,那么我们就需要对数据集的协方差矩阵进行特征值的分析,从而获得这些主成分的方向。一旦我们计算出了协方差矩阵的特征向量,我们就可以保留最大的 N 个值。正是这 N 个值反映了 N 个最重要特征的真实信息,可以把原始数据集合映射到 N 维的低维空间。
提取 N 个主成分的伪代码如下:
去除平均值 计算协方差矩阵 计算协方差矩阵的特征值和特征向量 将特征值从大到小排序 保留最大的N个特征值以及它们的特征向量 将数据映射到上述N个特征向量构造的新空间中
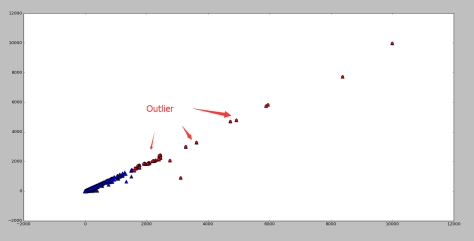
通过 Python 的 numpy 库和 matplotlib 库可以计算出某个二维数据集合的第一主成分如下:原始数据集使用蓝色的三角形表示,第一主成分使用黄色的圆点表示。
Principle Component Analysis 的基本性质:
Principle component analysis provides a set of eigenvectors satisfying the following properties:
(1)If the top-k eigenvectors are picked (by largest eigenvalue), then the k-dimensional hyperplane defined by these eigenvectors, and passing through the mean of the data, is a plane for which the mean square distance of all data points to it is as small as possible among all hyperplanes of dimensionality k.
(2)If the data is transformed to the axis-system corresponding to the orthogonal eigenvectors, the variance of the transformed data along each eigenvector dimension is equal to the corresponding eigenvalue. The covariances of the transformed data in this new representation are 0.
(3)Since the variances of the transformed data along the eigenvectors with small eigenvalues are low, significant deviations of the transformed data from the mean values along these directions may representoutliers.
基于矩阵分解的异常点检测方法的关键思想是利用主成分分析去寻找那些违背了数据之间相关性的异常点。为了发现这些异常点,基于主成分分析(PCA)的算法会把原始数据从原始的空间投影到主成分空间,然后再把投影拉回到原始的空间。如果只使用第一主成分来进行投影和重构,对于大多数的数据而言,重构之后的误差是小的;但是对于异常点而言,重构之后的误差依然相对大。这是因为第一主成分反映了正常值的方差,最后一个主成分反映了异常点的方差。
假设 dataMat 是一个 p 维的数据集合,有 N 个样本,它的协方差矩阵是 X。那么协方差矩阵就通过奇异值分解写成:
其中 P 是一个 (p,p) 维的正交矩阵,它的每一列都是 X 的特征向量。D 是一个 (p,p) 维的对角矩阵,包含了特征值 
这个数据集 dataMat 在主成分空间的投影可以写成
需要注意的是做投影可以只在部分的维度上进行,如果使用 top-j 的主成分的话,那么投影之后的数据集是
其中 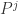

其中 
下面可以定义数据 
注意到 
整个算法的结构如图所示:

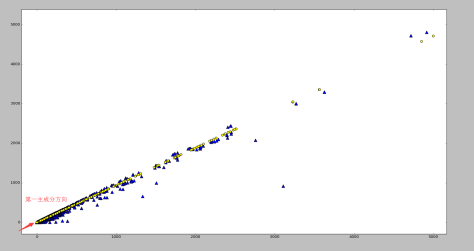
下面两幅图使用了同一批数据集,分别采用了基于矩阵分解的异常点检测算法和基于高斯分布的概率模型的异常点算法。

基于矩阵分解的异常点检测
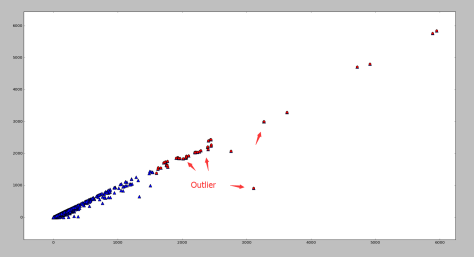
基于高斯分布的概率模型的异常点检测
根据图像可以看出,如果使用基于矩阵分解的异常点检测算法的话,偏离第一主成分较多的点都被标记为异常点,其中包括部分左下角的点。需要注意的是如果使用基于高斯分布的概率模型的话,是不太可能标记出左下角的点的,两者形成鲜明对比。
RNN 算法的主要思想
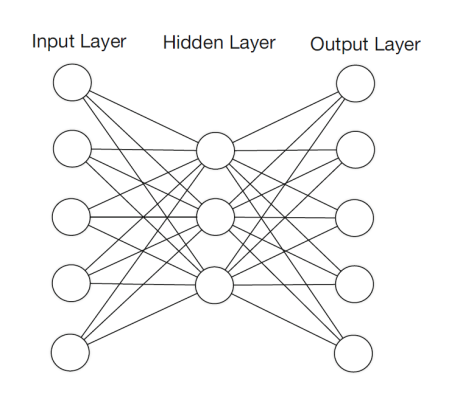
在这篇文章中,我们将会介绍一个多层的前馈神经网络,该神经网络可以用来进行异常值的检测。这个神经网络模拟的是一个恒等映射,输入层的神经元个数和输出层的神经元个数是一样的。这类的神经网络被称为 Replicator Neural Networks (RNNs),请注意这里的 RNN 算法指的并不是 Recurrent Neural Networks(RNNs),而是 Replicator Neural Networks,尽管它们拥有着同样的缩写名字 RNNs。具体来说, Replicator Neural Networks (RNNs),或者说自编码器,是一个多层前馈的神经网络 (multi-layer feed-forward neural networks)。在 Replicator Neural Networks 中,输入的变量也是输出的变量,模型中间层节点的个数少于输入层和输出层节点的个数。这样的话,模型就起到了压缩数据和恢复数据的作用。

如图所示,这里的 RNNs 有三个隐藏层,输入层和输出层的节点个数都是6,第一个隐藏层和第三个隐藏层的节点个数(图中是4个节点)少于输入层,第二个隐藏层的节点个数是最少的(图中是2个节点)。在神经网络传输的时候,中间使用了 tanh 函数和 sigmoid 函数。这个神经网络是训练一个从输入层到输出层的恒等函数(identity mapping),传输的时候从输入层开始压缩数据,然后到了第二个隐藏层的时候开始解压数据。训练的目标就是使得整体的输出误差足够小,整体的误差是由所有的样本误差之和除以样本的个数得到的。由于图中只画出了6个特征,因此第 i 个样本的误差是
如果使用已经训练好的 RNN 模型,异常值的分数就可以定义为重构误差(reconstruction error)。
下面简要介绍一下 RNN 模型是如何构建的:

根据上图所示,左边的是输入层,右边的输出层。假设第 k 层中第 i 个神经元的输出是 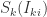
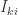
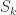
其中 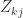

这里的 
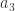


在这里可以假设 
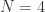
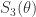
第三层的激活函数的输出就变成了 N 个离散的变量:0, 1/(N-1), 2/(N-1),…,1。这个阶梯型的激活函数是把第三层的连续输入值变成了一批离散的值。也就意味着把样本映射到了 N 个簇,那么 RNN 就可以计算出单个的异常点和一小簇的异常点。
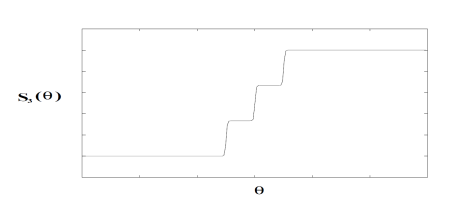
根据上面的分析,可以看出如果按照以上算法,则不能使用反向传播算法来训练模型,原因是 

一般来说,为了训练神经网络模型,需要使用后向传播算法(back propagation),也简称为 BP 算法,或者误差逆传播算法(error back propagation)。在本文中,仅针对最简单的 RNN 模型介绍如何使用 BP 算法进行模型训练,至于多层的神经网络模型或者其他的神经网络模型,方法则是完全类似的。
给定训练集合 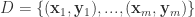
换句话说,输入样例是由 n 个属性描述,输出的结果也是 n 个属性。隐藏层只有一个,隐藏层的神经元个数是 ![q=[(n+1)/2]](https://s0.wp.com/latex.php?latex=q%3D%5B%28n%2B1%29%2F2%5D&bg=ffffff&fg=2b2b2b&s=0)
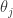



记隐藏层第 h 个神经元接收到的输入为
写成矩阵形式就是:
记输出层第 j 个神经元接收到的输入为
其中 
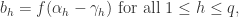

输出层第 j 个神经元的输出是 
下面可以假定激活函数都使用 
对于训练集 

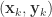
其中 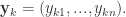
网络中有 个参数需要确定:输入层到隐藏层的 n*q 个权重值,隐藏层到输出层的 n*q 个权重值,q个隐层神经元的阈值,n 个输出层神经元的阈值。BP 算法是一个迭代学习算法,在迭代的每一轮采用了梯度下降法来进行参数的更新。任意参数的更新规则是

标准 BP 算法是根据每一个 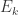

注意到 

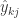
根据定义 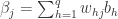

根据定义 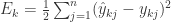
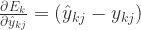
根据定义 
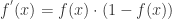
所以可以计算出对于
如果假设
那么可以得到
因此对于
根据类似的想法,有

逐个计算:
由于
所以,

整理之后,任意参数 v 的更新式子是 

其中学习率 
标准 BP 算法的训练流程:
输入:训练集合 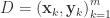

过程:
1. 在 (0,1) 范围内随机神经网络中的所有连接权重和阈值
2. repeat
for all
根据当前参数,计算出当前的样本输出 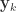
计算输出层神经元的梯度项 
计算隐藏层神经元的梯度项 
更新连接权重 

end for
3. 达到停止条件
输出:链接权与阈值都确定的神经网络模型
BP 算法的目的是最小化训练集上的累计误差 
(1)把数据集合的每一列都进行归一化;
(2)选择 70% 的数据集合作为训练集合,30% 的数据集合作为验证集合。或者 训练集合 : 验证集合 = 8 : 2,这个需要根据情况而定。
(3)随机生成一个三层的神经网络结构,里面的权重都是随机生成,范围在 [0,1] 内。输入层的数据和输出层的数据保持一致,并且神经网络中间层的节点个数是输入层的一半。
(4)使用后向传播算法(back-propagation)来训练模型。为了防止神经网络的过拟合,通常有两种策略来防止这个问题。(i)第一种策略是“早停”(early stopping):当训练集合的误差降低,但是验证集合的误差增加时,则停止训练,同时返回具有最小验证集合误差的神经网络;(ii)第二种策略是“正则化”(regularization):基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分,例如链接权和阀值的平方和。
其中蓝色的点表示正常点,红色的点表示被 RNN 算法标记的异常点。