个性化阅读的过去、现在和未来(一)·概述
- 蓝皮 - 博客园-旁观者个性化阅读的过去、现在和未来(一)·概述. 以前曾经撰文讲过Topic Engine的过去、现在和未来. Topic
Engine是一个生生不息的应用方向,因为从News Group、邮件列表、聊天室、论坛、Google
News、博客圈子、群组. ,人们一直因话题(有人也叫主题,英文为Topic)而聚集而交友,话题一直在生生不息层出不穷,组织形式在不断变异.
郑昀 20110414
前一篇:《个性化阅读的过去、现在和未来(一)·概论》,今日继续此话题。
前面说到Topic Engine/个性化阅读/Meme Tracker这几个方向所需要的研发团队大致是12个人起。下面着重说一下在现如今如何做个性化阅读。
Zite 的战略就是直接从Social Graph+Interest Graph切入,通过将Google Reader、Twitter、Facebook等拥有Interest Graph图谱的社会化数据导入,从而获得用户初始的兴趣爱好及社会化关系,由此引发阅读推荐,有效避免了推荐引擎的“冷启动”问题。如果用户不提供这些账号,Zite 需要你选择一些话题,然后就开始给你呈现相关的内容,这就和郑昀上一篇文章所介绍的2005~2007年活跃的个性化推荐没什么区别了。据说,国内已经有一家公司在做类似的产品,最近就会推出。
一、基于链接检测的聚合模式
这个模式非常好理解。只不过,我定义之所以叫链接“检测”,是因为链接并不显著,或在正文中隐藏,或在 Tweets 中隐藏,需要你特地提取出来。
2005年9月上线的 Techmeme 作为本模式的最优秀代表,就深刻地教育了 mashup 开发者,原来 链接检测 混搭 适当的A-List 有如此高的信息过滤效率。
Techmeme 在 Blog 时代称雄一时。到了 Twitter 时代,后起之秀是 TweetMeme ,上线之初,它并没有像 Techmeme 一样大放光彩,但随着 Twitter 的如日中天,它终于爆发了,它的 Alexa全球排名已经抵达在500名左右。
二、基于重复文字检测的聚合模式
Google News和百度新闻的新闻聚合,都属于本模式。它们可以通过检测近期发布的资讯之间的内容重合度,能将同一个主题的资讯合并在一起,也就是以文本相似性为技术基础的。
本模式一般是广泛收集新闻媒体信源,标记不同的权重度,做成扫描列表;然后通过爬虫抓取最新的新闻。通过对最近一段时间内的新闻计算文本相似性,可以获知哪些文章的相似度高于预设阈值,那么就说明这些文章是近似一个话题,可以合并。
三、Reddit模式
让新鲜且投票数还不足够多的文章能快速突破进入热门榜单,是很重要的。所以郑昀曾经在《榜单类应用我所喜欢的算法》中写道:“Reddit算法是我最喜欢用的算法。这个算法的解释参见我的文章:《Hacker News与Reddit的算法比较》”。
在郑昀撰写的《从Social Media海量数据中寻找专家的五大手法》中,SPEAR模式认为:“专家应该是发现者,而不是趋势的跟随者。experts应该是第一批收藏和标记高质量文章的人,从而召唤起社区内其他用户的围观。用户发现优质内容越早,表明该用户专业程度越高。所以,要区分“Discoverers”和“Followers”。”Reddit 正是通过log10 的使用,使得早期的投票(即Discoverers)获得更大的权重。比如,前10票获得的权重,与11到101票所获得的权重是一样的。
以Reddit算法为依托,针对资讯或社会化媒体数据做出不同分类的榜单,即热文列表。
四、Seeds模式
这是一种第三方应用深入某个 Social Media的常见刺探式统计方法。事先选定一个key users集合(比如创始人以及其他核心用户,被称之为“seeds”),然后从这批用户开始扫描建立Social Graph,通过统计inbound links和好友关系,得出被扫描的social media的不同指标的排行榜,这就是Spinn3r rank所用到的手法。这种模式并不限于计算Top Users。
它所用到的两个技巧倒是经常看到:
资讯聚合之后,要做到自动分类。此处用到了NLP的东西。
收集用户初始数据。此时有两种方式。
第一种,授权式:
让用户以自己的新浪微博、豆瓣、Google(Reader)等Social帐号登录;
获得用户OAuth授权后,获得用户(以及他的好友的)timeline,实时分析其潜在阅读喜好,构建Interest Graph。
第二种,预先计算式:
拿到Twitter、GR、新浪微博的类似Firehose(Streaming API)接口,提前存储大多数用户的社会化数据;
用户一旦输入(或叫“绑定”)自己的社会化帐号,后台根据已收集好的数据,立刻开始计算Interest Graph。
如何计算Interest Graph?
郑昀认为,可以把计算一个(微博/twitter)的Interest Graph视为短文本分类问题。
那么可以采用改进后的LDA算法,区分并且去除了容易造成主题混淆的关键词,只考虑主题明晰化的关键词。
什么是LDA?
即Latent Dirichlet allocation(硬翻译为 潜在狄利克雷分布或隐含狄利克雷分配)。关联关键词:Topic Modeling。
参考《基于LDA的Topic Model变形》或《LDA模型理解》。比较通俗的解释可以看这篇SEO的:《Latent Dirichlet Allocation (LDA)与Google排名有着相当显著的相关性》。
具体如何做?
去年曾经有一位rickjin在新浪微博上如是说,颇有参考价值:
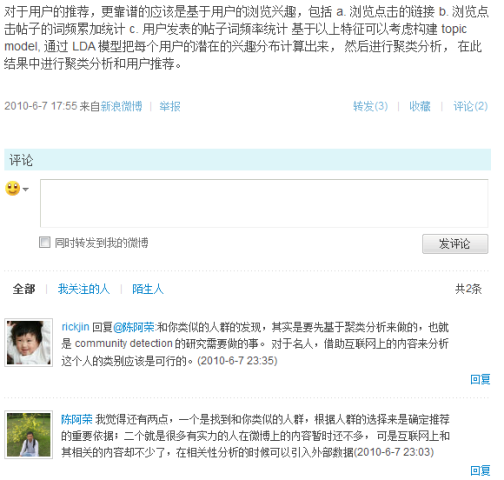
从代码层次上如何具体做,我就不说了。(注:你要是手头没工具包,也没做过NLP,也可以参考这么一个工具ROST CM。)
开源的推荐引擎,一个是easyrec.org。
背景1:http://en.wikipedia.org/wiki/Easyrec
easyrec is an open source Web application that provides personalized recommendations using RESTful Web services to be integrated into Web enabled applications. It is distributed under the GNU General Public License by the Studio Smart Agent Technologies and hosted at SourceForge.
It is written in Java, uses a MySQL database and comes with an administration tool.
另一个是Apache Mahout 。
背景2:http://www.ibm.com/developerworks/cn/java/j-lo-mahout/
Apache Mahout 是 Apache Software Foundation(ASF)
旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。经典算法包括聚类、分类、协同过滤、进化编程等。
Taste
是 Apache Mahout 提供的一个协同过滤算法的高效实现,它是一个基于 Java 实现的可扩展的,高效的推荐引擎。Taste
既实现了最基本的基于用户的和基于内容的推荐算法,同时也提供了扩展接口,使用户可以方便的定义和实现自己的推荐算法。同时,Taste 不仅仅只适用于 Java
应用程序,它可以作为内部服务器的一个组件以 HTTP 和 Web Service 的形式向外界提供推荐的逻辑。
此处的难点是,如何根据前面计算的Interest Graph,给用户推荐资讯。最简单的做法是,把Interest Graph映射到不同分类,这样只需要先期计算好每一个分类下的热门资讯,那么知道用户喜欢哪些分类,就直接推送对应的热文即可;然后根据用户点击流和分享收藏等动作做个性化推荐,调整资讯内容。
不能让传播链在这里断掉,所以必须鼓励用户再次分享、推荐、共享、收藏到其他社会化媒体渠道。
郑昀 北京报道
待续。
第一篇:《个性化阅读的过去、现在和未来(一)·概述》;
第二篇:《个性化阅读的过去、现在和未来(二)·实作》。
例行赠图一枚:

我的最新推特流:
1、
这个故事发生在距离中国不远的某俄罗斯边陲小镇硬盘维修中心。某天一位顾客带来了一块损坏的500Gb移动硬盘,这块硬盘来自河对岸的中国店铺,价格低廉的不可思议。这块移动硬盘竟然是由一个128MB的U盘和两个大螺帽组成。http://t.cn/hBgycH
2、
RT @shifeike: 这大半年来,没有一件让人开心的事儿,总是坏消息连着坏消息。我总在想,等到解放以后,罄竹难书和倒行逆施这两个成语,该拿出来用多少次啊!
3、
当《风声传奇》最后顾晓梦的父亲意欲杀死老潘,节奏越来越急促的背景音乐响起,两岁半的宝宝突然说:好像要死人了。。。
4、
下午百分点周涛教授给我们讲了个性化推荐如何与电商实际结合,非常精彩,信息量极大,深入浅出,全是干货,很久没听过这么酣畅淋漓的讲座了。
作者: 旁观者 发表于 2011-04-17 23:47 原文链接
最新新闻:
· 最后的武士:诺基亚 E6(2011-04-19 08:08)
· 传Facebook虚拟币7月推出 比肩腾讯Q币(2011-04-19 08:07)
· Chrome 开始要求对 Java 和 QuickTime 的运行进行授权(2011-04-19 08:06)
· 人人网赴美IPO拟募5亿美元或创融资之最(2011-04-19 08:05)
· 为什么我的工资最低!(2011-04-19 07:32)
编辑推荐:上周热点回顾(4.11-4.17)