Item 1: Attribute Lazy Loading Via Bytecode Enhancement
By default, the attributes of an entity are loaded eager (all at once). Are you sure that you want that?
Description:If not, then is important to know that attributes can be loaded lazily, as well via Hibernate bytecode instrumentation (another approach is via subentities). This is useful for column types that store large amounts of data: CLOB, BLOB, VARBINARY, etc.
Key points:
- For Maven, in
pom.xml, activate Hibernate bytecode instrumentation (e.g. use Maven bytecode enhancement plugin as follows) - Mark the columns that should be loaded lazily with
@Basic(fetch = FetchType.LAZY) - disable Open Session in View
Source code can be found here.
Item 2: View Binding Params Via Log4J 2
Without seeing and inspecting the SQL fired behind the scenes and the corresponding binding parameters, we are prone to introduce performance penalties that may remain there for a long time (e.g. N+1).
Update (please read):The solution described below is useful if you alreadyhave Log4J 2 in your project. If not, is better to rely on TRACE(thank you Peter Wippermann for your suggestion) or log4jdbc(thank you Sergei Poznanski for your suggestion and SOanswer). Both approaches doesn't require the exclusion of Spring Boot's Default Logging. An example of TRACEcan be found here, and an example of log4jdbc here.
Description based on Log4J 2:While the application is under development, maintenance is useful to view and inspect the prepared statement binding parameters values instead of assuming them. One way to do this is via Log4J 2 logger setting.
Key points:
- For Maven, in
pom.xml, exclude Spring Boot's Default Logging (read update above) - For Maven, in
pom.xml, add the Log4j 2 dependency - In
log4j2.xml, add the following:
<Logger name="org.hibernate.type.descriptor.sql" level="trace"/>
Output sample:

Source code can be found here.
Item 3: How To View Query Details Via "datasource-proxy"
Without ensuring that batching is actually working, we are prone to serious performance penalties. There are different cases when batching is disabled, even if we have it set up and think that it is working behind the scene. For checking, we can use hibernate.generate_statisticsto display details (including batching details), but we can go with the datasource-proxy, as well.
Description:View the query details (query type, binding parameters, batch size, etc.) via datasource-proxy.
Key points:
- For Maven, add in the
pom.xmlthe datasource-proxydependency - Create a bean post processor to intercept the
DataSource bean - Wrap the
DataSourcebean via the ProxyFactoryand an implementation of the MethodInterceptor
Output sample:

Source code can be found here.
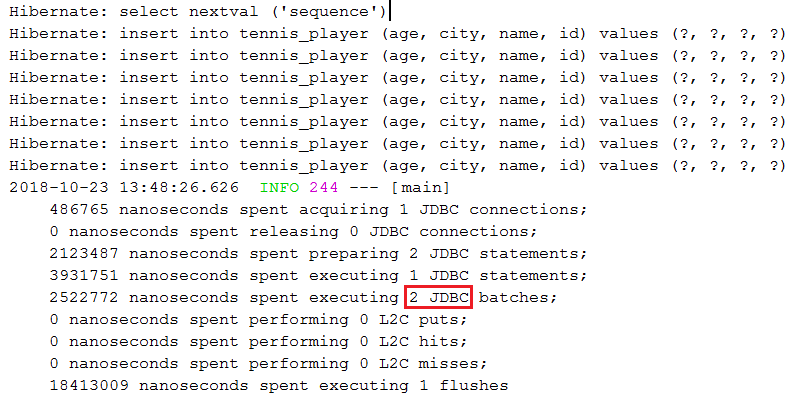
Item 4: Batch Inserts Via saveAll(Iterable<S> entities) in MySQL (or other RDBMS)
By default, 100 inserts will result in 100 SQL INSERTstatements, and this is bad since it results in 100 database round trips.
Description:Batching is a mechanism capable of grouping INSERTs, UPDATEs,and DELETEs,and as a consequence, it significantly reduces the number of database round trips. One way to achieve batch inserts consists in using the SimpleJpaRepository#saveAll(Iterable< S> entities)method. Here, we do this with MySQL.
Key points:
- In
application.properties,set spring.jpa.properties.hibernate.jdbc.batch_size - In
application.properties,set spring.jpa.properties.hibernate.generate_statistics(just to check that batching is working) - In
application.properties,set JDBC URL with rewriteBatchedStatements=true (optimization specific for MySQL) - In
application.propertiesset JDBC URL with cachePrepStmts=true(enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled) - In
application.propertiesset JDBC URL with useServerPrepStmts=true(this way you switch to server-side prepared statements (may lead to significant performance boost)) - In the entity, use the assigned generatorsince MySQL
IDENTITYwill cause batching to be disabled - In the entity, add the
@Versionproperty of type Longto avoid extra- SELECTfired before batching (also prevent lost updates in multi-request transactions). Extra- SELECTsare the effect of using merge()instead of persist(). Behind the scenes, saveAll()uses save(),which in case of non-new entities (having IDs), will call merge(), which instructs Hibernate to fire to a SELECTstatement to ensure that there is no record in the database having the same identifier. - Pay attention to the number of inserts passed to
saveAll()to not "overwhelm" the persistence context. Normally, the EntityManagershould be flushed and cleared from time to time, but during the saveAll()execution, you simply cannot do that, so if in saveAll()there is a list with a high amount of data, all that data will hit the persistence context (1st level cache) and will be in-memory until flush time. Using a relatively small amount of data should be OK. For a large amount of data, please check the next example (item 5).
Output sample:
 output")
Source code can be found here.
Item 5: Batch Inserts Via EntityManager in MySQL (or other RDBMS)
Using batching should result in a boost in performance, but pay attention to the amount of data stored in the persistence context before flushing it. Storing a large amount of data in memory can lead again to performance penalties. Item 4 fits well for a relatively small amount of data.
Description:Batch inserts via EntityManagerin MySQL (or other RDBMS). This way you can easily control the flush()and clear()of the persistence context (1st level cache). This is not possible via Spring Boot, saveAll(Iterable< S> entities). Another advantage is that you can call persist()instead of merge()— this is used behind the scene by the Spring Boot methods, saveAll(Iterable< S> entities)and save(S entity).
Key points:
- In
application.properties,set spring.jpa.properties.hibernate.jdbc.batch_size - In
application.properties,set spring.jpa.properties.hibernate.generate_statistics(just to check that batching is working) - In
application.properties,set JDBC URL with rewriteBatchedStatements=true (optimization specific for MySQL - In
application.propertiesset JDBC URL with cachePrepStmts=true(enable caching and is useful if you decide to set prepStmtCacheSize, prepStmtCacheSqlLimit, etc as well; without this setting the cache is disabled) - In
application.propertiesset JDBC URL with useServerPrepStmts=true(this way you switch to server-side prepared statements (may lead to significant performance boost)) - In the entity, use the assigned generator since MySQL
IDENTITYwill cause batching to be disabled - In DAO, flush and clear the persistence context from time to time. This way, you avoid to "overwhelm" the persistence context.
Output sample:

Source code can be found here.
You may also like the following:
Item 8: Direct Fetching Via Spring Data/EntityManager/Session
The way, we fetch data from the database that determines how an application will perform. In order to build the optimal fetching plan, we need to be aware of each fetching type. Direct fetchingis the simplest (since we don't write any explicit query) and very useful when we know the entity Primary Key.
Description:Direct fetching via Spring Data, EntityManager, and Hibernate Sessionexamples.
Key points:
- Direct fetching via Spring Data,
findById() - Direct fetching via
EntityManager#find() - Direct fetching via Hibernate
Session#get()
Source code can be found here.
Item 9: DTOs Via Spring Data Projections
Fetching more data than needed is one of the most common issue causing performance penalties. Fetching entities without the intention of modifying them is also a bad idea.
Description:Fetch only the needed data from the database via Spring Data Projections (DTOs). See also items 25-32.
Key points:
- Write an interface (projection) containing getters only for the columns that should be fetched from the database
- Write the proper query returning a
List <projection> - If possible, limit the number of returned rows (e.g., via
LIMIT). Here, we can use the query builder mechanism built into the Spring Data repository infrastructure
Output example (select first 2 rows; select only "name" and "age"):

Source code can be found here.
Item 10: How To Store UTC Timezone In MySQL
Storing date, time and timestamps in the database in different/specific formats can cause real issues when dealing with conversions.
Description:This recipe shows you how to store date, time, and timestamps in UTC time zone in MySQL. For other RDBMSs (e.g. PostgreSQL), just remove " useLegacyDatetimeCode=false" and adapt the JDBC URL.
Key points:
-
spring.jpa.properties.hibernate.jdbc.time_zone=UTC -
spring.datasource.url=jdbc:mysql://localhost:3306/db_screenshot?useLegacyDatetimeCode=false
Source code can be found here.
Item 11: Populating a Child-Side Parent Association Via Proxy
Executing more SQLs than needed is always a performance penalty. It is important to strive to reduce their number as much as possible, and relying on references is one of the easy to use optimization.
Description:A Proxycan be useful when a child entity can be persisted with a reference to its parent. In such cases, fetching the parent entity from the database (execute the SELECTstatement) is a performance penalty and a pointless action. Hibernate can set the underlying foreign key value for an uninitialized Proxy.
Key points:
- Rely on
EntityManager#getReference() - In Spring, use
JpaRepository#getOne() - Used in this example, in Hibernate, use
load() - Here, we have two entities,
Tournamentand TennisPlayer, and a tournament can have multiple players ( @OneToMany). - We fetch the tournament via a
Proxy(this will not trigger a SELECT), and we create a new tennis player and set the Proxyas the tournament for this player and we save the player (this will trigger an INSERTin the tennis players table, tennis_player)
Output sample:
- The console output will reveal that only an
INSERTis triggered, and no SELECT
Source code can be found here.
Item 12: Reproducing N+1 Performance Issue
N+1 is another issue that may cause serious performance penalties. In order to eliminate it, you have to find/recognize it. Is not always easy, but here is one of the most common scenarios that lead to N+1.
Description:N+1 is an issue of lazy fetching (but, eager is not exempt). Just in case that you didn't have the chance to see it in action, this application reproduces the N+1 behavior. In order to avoid N+1 is better to rely on JOIN+DTO (there are examples of JOIN+DTOs in items 36-42).
Key points:
- Define two entities,
Categoryand Product,having a @OneToManyrelationship - Fetch all
Productlazy, so without Category(results in 1 query) - Loop the fetched
Productcollection, and for each entry, fetch the corresponding Category(results N queries)
Output sample:

Source code can be found here.
Item 13: Optimize Distinct SELECTs Via HINT_PASS_DISTINCT_THROUGH Hint
Passing SELECT DISTINCTto an RDBMS has a negative impact on performance.
Description:Starting with Hibernate 5.2.2, we can optimize SELECT DISTINCTvia the HINT_PASS_DISTINCT_THROUGHhint. Mainly, the DISTINCTkeyword will not hit the RDBMS, and Hibernate will take care of the de-duplication task.
Key points:
- Use
@QueryHints(value = @QueryHint(name = HINT_PASS_DISTINCT_THROUGH, value = "false"))
Output sample:

Source code can be found here.
Item 14: Enable Dirty Tracking
Java Reflection is considered slow and, therefore, a performance penalty.
Description:Prior to Hibernate version 5, the dirty checkingmechanism relies on Java Reflection API. Starting with Hibernate version 5, the dirty checkingmechanism relies on bytecode enhancement. This approach sustain a better performance, especially when you have a relatively large number of entities.
Key points:
- Add the corresponding plugin in
pom.xml(e.g. use Maven bytecode enhancement plugin)
Output sample:

- The bytecode enhancement effect can be seen on
User.class, here.
Source code can be found here.
Item 15: Use Java 8 Optional in Entities and Queries
Treating Java 8 Optionalas a "silver bullet" for dealing with nulls can cause more harm than good. Using things for what they were designed is the best approach.
Description:This application is a proof of concept of how is correct to use the Java 8 Optionalin entities and queries.
Key points:
- Use the Spring Data built-in query-methods that return
Optional(e.g. findById()) - Write your own queries that return
Optional - Use
Optionalin entities getters - In order to run different scenarios check the file,
data-mysql.sql
Source code can be found here.
Item 16: How to Correctly Shape an @OneToMany Bidirectional Relationship
There are a few ways to screw up your @OneToManybi-directional relationship implementation. And, I am sure that this is a thing that you want to do it correctly right from the start.
Description:This application is a proof of concept of how is correct to implement the bidirectional @OneToManyassociation.
Key points:
- Alwayscascade from parent to child
- Use
mappedByon the parent - Use
orphanRemovalon the parent in order to remove children without references - Use helper methods on the parent to keep both sides of the association in sync
- Alwaysuse lazy fetch
- Use a natural/business key or use entity identifier and override
equals()and hashCode()as here
Source code can be found here.
Item 17: JPQL/HQL Query Fetching
When direct fetching is not an option, we can think of JPQL/HQL query fetching.
Description:This application is a proof of concept of how to write a query via JpaRepository, EntityManagerand Session.
Key points:
- For
JpaRepository, use @Queryor Spring Data Query Creation - For
EntityManagerand Session, use the createQuery()method
Source code can be found here.
Item 18: MySQL and Hibernate 5 Avoid AUTO Generator Type
In MySQL, the TABLEgenerator is something that you will always want to avoid. Neveruse it!
Description:In MySQL and Hibernate 5, the GenerationType.AUTOgenerator type will result in using the TABLEgenerator. This adds a significant performance penalty. Turning this behavior to IDENTITYgenerator can be obtained by using GenerationType.IDENTITYor the native generator.
Key points:
- Use GenerationType.IDENTITYinstead of GenerationType.AUTO
- Use the native generator exemplified in this source code
Output sample:

Source code can be found here.
Item 19: Redundant save() Call
We love to call this method, don't we? But, calling it for managed entities is a bad idea since Hibernate uses dirty checking mechanism to help us to avoid such redundant calls.
Description:This application is an example when calling save()for a managed entity is redundant.
Key points:
- Hibernate triggers
UPDATEstatements for managed entities without the need to explicitly call the save()method - Behind the scenes, this redundancy implies a performance penalty as well (see here)
Source code can be found here.
Item 20: PostgreSQL (BIG)SERIAL and Batching Inserts
In PostgreSQL, using GenerationType.IDENTITYwill disable insert batching.
Description:The ( BIG) SERIALis acting "almost" like MySQL, AUTO_INCREMENT. In this example, we use the GenerationType.SEQUENCE, which enables insert batching, and we optimize it via the hi/looptimization algorithm.
Key points:
- Use
GenerationType.SEQUENCEinstead of GenerationType.IDENTITY - Rely on the
hi/loalgorithm to fetch multiple identifiers in a single database roundtrip (you can go even further and use the Hibernate pooledand pooled-loidentifier generators (these are optimizations of hi/lo)).
Output sample:
Source code can be found here.
Item 21: JPA Inheritance — Single Table
JPA supports SINGLE_TABLE, JOINED, TABLE_PER_CLASSinheritance strategies. Each of them have their pros and cons. For example, in the case of SINGLE_TABLE, reads and writes are fast, but as the main drawback, NOT NULL constraints are not allowed for columns from subclasses.
Description:This application is a sample of JPA Single Table inheritance strategy ( SINGLE_TABLE)
Key points:
- This is the default inheritance strategy (
@Inheritance(strategy=InheritanceType.SINGLE_TABLE)) - All the classes in a hierarchy are mapped to a single table in the database
Output example (below is a single table obtained from four entities):

Source code can be found here.
Item 22: How to Count and Assert SQL Statements
Without counting and asserting SQL statements, it is very easy to lose control of the SQL executed behind the scene and, therefore, introduce performance penalties.
Description:This application is a sample of counting and asserting SQL statements triggered "behind the scenes." Is very useful to count the SQL statements in order to ensure that your code is not generating more SQLs that you may think (e.g., N+1 can be easily detected by asserting the number of expected statements).
Key points:
- For Maven, in
pom.xml, add dependencies for datasource-proxyand Vlad Mihalcea's db-util - Create the
ProxyDataSourceBuilderwith countQuery() - Reset the counter via
SQLStatementCountValidator.reset() - Assert
INSERT, UPDATE, DELETE,and SELECTvia assertInsert{Update/ Delete/ Select}Count(long expectedNumberOfSql
Output example (when the number of expected SQLs is not equal with the reality an exception is thrown):
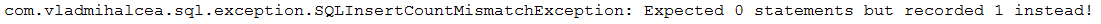
Source code can be found here.
Item 23: How To Use JPA Callbacks
Don't reinvent the wheel when you need to tie up specific actions to a particular entity lifecycle event. Simply rely on built-in JPA callbacks.
Description:This application is a sample of enabling the JPA callbacks ( Pre/ PostPersist, Pre/ PostUpdate, Pre/ PostRemove,and PostLoad).
Key points:
- In the entity, write callback methods and use the proper annotations
- Callback methods annotated on the bean class must return
voidand take no arguments
Output sample:

Source code can be found here.
Item 24: @OneToOne and @MapsId
A bidirectional @OneToOneis less efficient than a unidirectional @OneToOnethat shares the Primary Key with the parent table.
Description:Instead of a bidirectional @OneToOne, it is better rely on a unidirectional @OneToOneand @MapsId. This application is a proof of concept.
Key points:
- Use
@MapsIdon the child side - Basically, for a
@OneToOneassociation, this will share the Primary Keywith the parent table
Source code can be found here.
Item 25: DTOs Via SqlResultSetMapping
Fetching more data than needed is bad. Moreover, fetching entities (add them in the persistence context) when you don't plan to modify them is one of the most common mistakes that draws implicitly performance penalties. Items 25-32 show different ways of extracting DTOs.
Description:Using DTOs allows us to extract only the needed data. In this application, we rely on SqlResultSetMappingand EntityManager.
Key points:
- Use
SqlResultSetMappingand EntityManager - For using Spring Data Projections, check issue number 9 above.
Source code can be found here.
Stay tuned for out next installment where we explore the remaining top 25 best performance practices for Spring Boot 2 and Hibernate 5!
If you liked the article, you might also like the book.
See you in part 2!