深入理解MySQL索引
- - InfoQ推荐当提到MySQL数据库的时候,我们的脑海里会想起几个关键字:索引、事务、数据库锁等等, 索引是MySQL的灵魂,是平时进行查询时的利器,也是面试中的重中之重. 可能你了解索引的底层是b+树,会加快查询,也会在表中建立索引,但这是远远不够的,这里列举几个索引常见的面试题:. 1、索引为什么要用b+树这种数据结构.
当提到MySQL数据库的时候,我们的脑海里会想起几个关键字:索引、事务、数据库锁等等, 索引是MySQL的灵魂,是平时进行查询时的利器,也是面试中的重中之重。
可能你了解索引的底层是b+树,会加快查询,也会在表中建立索引,但这是远远不够的,这里列举几个索引常见的面试题:
1、索引为什么要用b+树这种数据结构?
2、聚集索引和非聚集索引的区别?
3、索引什么时候会失效,最左匹配原则是什么?
当遇到这些问题的时候,可能会发现自己对索引还是一知半解,今天我们一起学习MySQL的索引。
首先来看 在MySQL数据库中,一条查询语句是如何执行的,索引出现在哪个环节,起到了什么作用。
当执行SQL语句时,应用程序会连接到相应的数据库服务器,然后服务器对SQL进行处理。
接着数据库服务器会先去查询是否有该SQL语句的缓存,key是查询的语句,value是查询的结果。如果你的查询能够直接命中,就会直接从缓存中拿出value来返回客户端。
注:查询不会被解析、不会生成执行计划、不会被执行。
如果没有命中缓存,则开始第三步。
最后,数据库服务器将查询结果返回给客户端。(如果查询可以缓存,MySQL也会将结果放到查询缓存中)
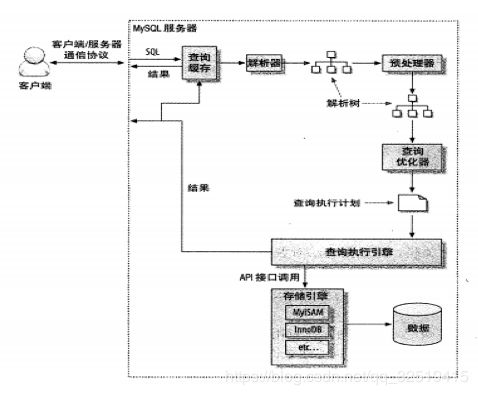
这就是一条查询语句的执行流程,可以看到索引出现在优化SQL的流程步骤中,接下来了解索引到底是什么?
先简单地了解一下索引的基本概念。
索引是帮助数据库高效获取数据的数据结构。
聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,因为只要找到第一个索引值记录,其余的连续性的记录在物理表中也会连续存放,一起就可以查询到。
缺点:新增比较慢,因为为了保证表中记录的物理顺序和索引顺序一致,在记录插入的时候,会对数据页重新排序。
索引的逻辑顺序与磁盘上行的物理存储顺序不同,非聚集索引在叶子节点存储的是主键和索引列,当我们使用非聚集索引查询数据时,需要拿到叶子上的主键再去表中查到想要查找的数据。这个过程就是我们所说的回表。
举个例子
比如汉语字典,想要查「阿」字,只需要翻到字典前几页,a开头的位置,接着「啊」「爱」都会出来。也就是说, 字典的正文部分本身就是一个目录,不需要再去查其他目录来找到需要找的内容。我们 把这种正文内容本身就是一种按照一定规则排列的目录称为==聚集索引==。
如果遇到不认识的字,只能根据“偏旁部首”进行查找,然后根据这个字后的页码直接翻到某页来找到要找的字。但结合 部首目录 和 检字表 而查到的字的排序并不是真正的正文的排序方法。
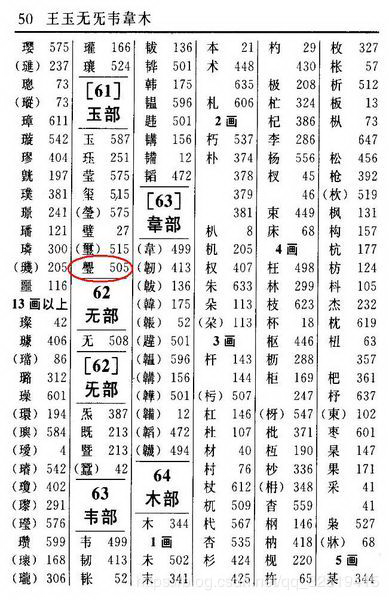
比如要查“玉”字,我们可以看到在查部首之后的检字表中“玉”的页码是587页,然后是珏,是251页。很显然,在字典中这两个字并没有挨着,现在看到的连续的“玉、珏、莹”三字实际上就是他们 在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到结果所对应的页码。我们 把这种目录纯粹是目录,正文纯粹是正文的排序方式称为==非聚集索引==。
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
ALTER TABLE `table_name` ADD UNIQUE (`column`)
ALTER TABLE `table_name` ADD INDEX index_name (`column` )
ALTER TABLE `table_name` ADD FULLTEXT (`column`)
ALTER TABLE `table_name` ADD INDEX index_name (`column1`,`column2`,`column3`)
了解了索引的基本概念后,可能最好奇的就是 索引的底层是怎么实现的呢?为什么索引可以如此高效地进行数据的查找?如何设计数据结构可以满足我们的要求? 下文通过一般程序员的思维来想一下如果是我们来设计索引,要如何设计来达到索引的效果。
可能直接想到的就是用哈希表来实现快速查找,就像我们平时用的hashmap一样,value = get(key) O(1)时间复杂度一步到位,确实, 哈希索引 是一种方式。
哈希索引就是采用一定的哈希算法,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。 本质上就是把键值换算成新的哈希值,根据这个哈希值来定位。
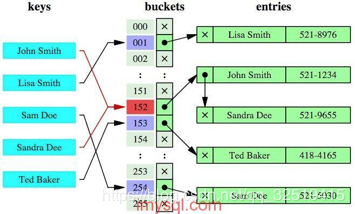
在MySQL常用的InnoDB引擎中,还是使用B+树索引比较多。InnoDB是自适应哈希索引的(hash索引的创建由 ==InnoDB存储引擎自动优化创建==,我们干预不了)。
假设要查询某个区间的数据,我们只需要拿到区间的起始值,然后在树中进行查找。
如数据为:
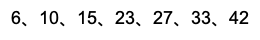
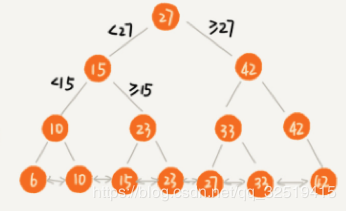
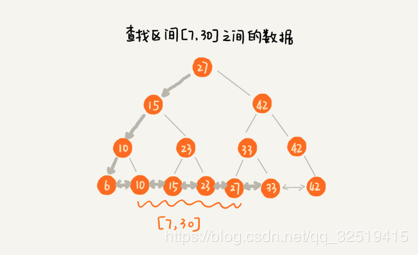
当查找到起点节点10后,再顺着链表进行遍历,直到链表中的节点数据大于区间的终止值为止。 所有遍历到的数据,就是符合区间值的所有数据。
利用二叉查找树,区间查询的功能已经实现了。但是,为了节省内存,我们只能把树存储在硬盘中。
那么, 每个节点的读取或者访问,都对应一次硬盘IO操作。每次查询数据时磁盘IO操作的次数,也叫做==IO渐进复杂度==,也就是==树的高度==。
所以,我们要减少磁盘IO操作的次数,也就是 要==降低树的高度==。
结构优化过程如下图所示:
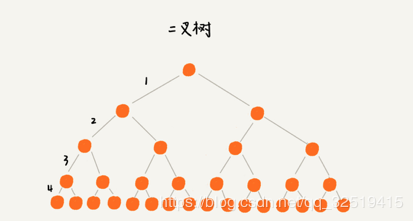
这里将二叉树变为了M叉树,降低了树的高度,那么这个M应该选择多少才合适呢?
问题:对于相同个数的数据构建m叉树索引,m叉树中的m越大,那树的高度就越小,那m叉树中的m是不是越大越好呢?到底多大才合适呢?
不管是内存中的数据还是磁盘中的数据,操作系统都是按页(一页的大小通常是4kb,这个值可以通过 getconfig(PAGE_SIZE)命令查看)来读取的,一次只会读取一页的数据。
如果要读取的数据量超过了一页的大小,就会触发多次IO操作。所以在选择m大小的时候,要尽量让每个节点的大小等于一个页的大小。
一般实际应用中,出度d(树的分叉数)是非常大的数字,通常超过100; ==树的高度(h)非常小,通常不超过3==。
顺着解决问题的思路知道了我们想要的数据结构是什么。目前索引常用的数据结构是B+树,先介绍一下什么是B树(也就是B-树)。
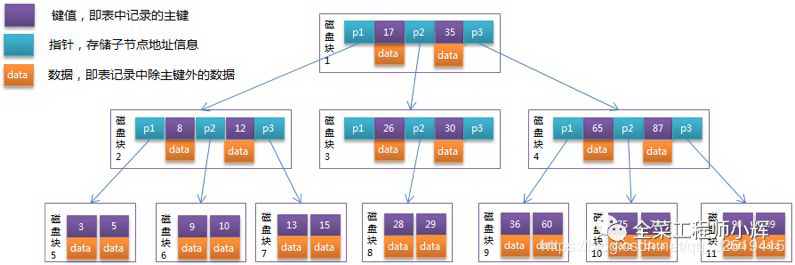
了解了B树,再来看一下B+树,也是MySQL索引大部分情况所使用的数据结构。
下图是一个M=3阶的B+树
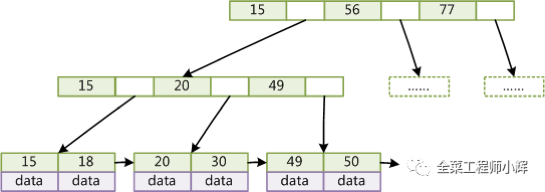
这些基本特点是为了满足以下的特性。
因为MongoDB不是传统的关系型数据库,而是以Json格式作为存储的NoSQL非关系型数据库,目的就是高性能、高可用、易扩展。摆脱了关系模型,所以 范围查询和遍历查询的需求就没那么强烈了。
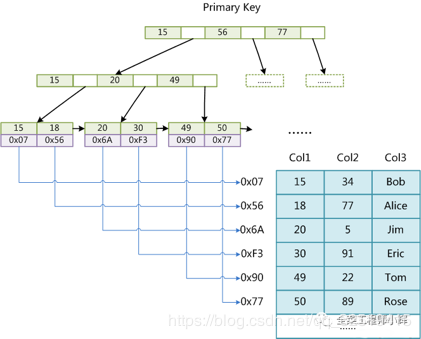
MyISAM的索引文件(.MYI)和数据文件(.MYD)文件是分离的,索引文件仅保存记录所在页的指针(物理位置),通过这些指针来读取页,进而读取被索引的行。
树中的叶子节点保存的是对应行的物理位置。通过该值, ==存储引擎能顺利地进行回表查询,得到一行完整记录==。
同时,每个叶子也保存了指向下一个叶子的指针,从而 方便叶子节点的范围遍历。
在MyISAM中,主键索引和辅助索引在结构上没有任何区别, ==只是主键索引要求key是唯一的,而辅助索引的key可以重复==。
Innodb的主键索引和辅助索引之前提到过,再回顾一次。
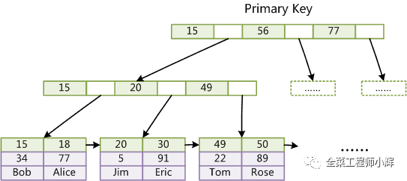
InnoDB主键索引中既存储了主健值,又存储了行数据。
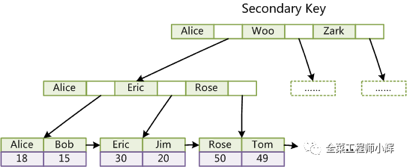
对于辅助索引,InnoDB采用的方式是在叶子节点中保存主键值,通过这个主键值来回表查询到一条完整记录,因此 按辅助索引检索其实进行了二次查询,效率是没有主键索引高的。
在上一节中了解了索引的多种数据结构,以及B树和B+树的对比等,大家应该对索引的底层实现有了初步的了解。这一节从应用层的角度出发,看一下如何建索引更能满足我们的需求,以及MySQL索引什么时候会失效的问题。
先来思考一个小问题。
问题:当查询条件为2个及2个以上时,是创建多个单列索引还是创建一个联合索引好呢?它们之间的区别是什么?哪个效率高呢?
先来建立一些单列索引进行测试:
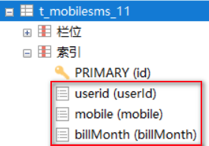
这里建立了一张表,里面建立了三个单列索引userId,mobile,billMonth。
然后进行多列查询。
explain select * from `t_mobilesms_11` where userid = '1' and mobile = '13504679876' and billMonth = '1998-03'

我们发现查询时只用到了userid这一个单列索引,这是为什么呢?因为这取决于 MySQL优化器的优化策略。
当多条件联合查询时,优化器会评估哪个条件的索引效率高,它会选择最佳的索引去使用。也就是说,此处三个索引列都可能被用到,只不过优化器判断只需要使用userid这一个索引就能完成本次查询,故最终explain展示的key为userid。
多个单列索引在多条件查询时优化器会选择最优索引策略,可能 只用一个索引,也可能将多个索引都用上。
但是多个单列索引底层会建立多个B+索引树,比较占用空间,也会浪费搜索效率 所以 多条件联合查询时最好建联合索引。
那联合索引就可以三个条件都用到了吗?会出现索引失效的问题吗?
该部分参考并引用文章:一张图搞懂MySQL的索引失效( https://segmentfault.com/a/1190000021464570)
创建user表,然后建立 name, age, pos, phone 四个字段的联合索引 全值匹配(索引最佳)。

索引生效,这是最佳的查询。
那么时候会失效呢?
最左匹配原则:最左优先,以最左边的为起点任何连续的索引都能匹配上,如不连续,则匹配不上。
如:建立索引为(a,b)的联合索引,那么只查 where b = 2 则不生效。换句话说:如果建立的索引是(a,b,c),也只有(a),(a,b),(a,b,c)三种查询可以生效。

这里跳过了最左的name字段进行查询,发现索引失效了。
遇到范围查询(>、<、between、like)就会停止匹配。
比如:a= 1 and b = 2 and c>3 and d =4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为 c字段是一个范围查询,它之后的字段会停止匹配。
如计算、函数、(手动或自动)类型转换等操作,会导致索引失效而进行全表扫描。
explain select * from user where left(name,3) = 'zhangsan' and age =20

这里对name字段进行了left函数操作,导致索引失效。
explain select * from user where age != 20;

explain select * from user where age <> 20;

索引失效
explain select * from user where name like ‘%zhangsan’;

索引生效
explain select * from user where name like ‘zhangsan%’;

explain select * from user where name = 2000;

explain select * from user where name = ‘2000’ or age = 20 or pos =‘cxy’;

正常(索引参与了排序),没有违反最左匹配原则。
explain select * from user where name = 'zhangsan' and age = 20 order by age,pos;

违反最左前缀法则,导致额外的文件排序(会降低性能)。
explain select name,age from user where name = 'zhangsan' order by pos;

正常(索引参与了排序)。
explain select name,age from user where name = 'zhangsan' group by age;
违反最左前缀法则,导致产生临时表(会降低性能)。
explain select name,age from user where name = 'zhangsan' group by pos,age;

希望大家能够多去使用索引进行SQL优化,有问题欢迎指出。
文章配图来源于网络
本文转载自公众号宜信技术学院(ID:CE_TECH)。
原文链接: