金融行业 IT 运维监控体系的建设内幕
- - IT瘾-dev多年运维经验的积累,往往己沉淀下来不少监控工具,同时也有不同专业线条的工具,在基础架构、系统网络、数据库、中间件、应用层面等采用不同的监控工具. 对于这些工具,通常采用以下方式处理:. 1)建立集中监控平台:在一体化运维体系中,监控平台贯穿所有环节,可以对生产系统涉及的各种环境的实时运行状况监控,监控平台事件驱动的特性也为一体化运维体系起到驱动的作用.
一、前言
从电商转金融 2 年多了,由于两者商业模式、流量的不同,期间踩了很多坑,尤其是在监控这一块,我们吃过不少苦头。
前期由于监控缺失,造成了多起线上事故,经过一番摸索,我们实现了一些相对可行的监控方法,有效地保证了大盘及业务的稳定,在此总结出来分享给大家,希望能为大家提供一些金融场景下的监控思路,如果大家如有更好的思路,也欢迎共同探讨。
本文主要从以下几个方面来阐述:
电商场景下的常用监控方式。
金融监控的难点。
金融场景下监控的几种可靠手段。
二、电商场景下的常用监控方式
电商场景下的监控主要有两种,一种是流量监控(接口请求),一种是关键节点(如注册,下单)的监控。
对于这两者监控来说,我们常用的手法就是打点,接口每请求一次或关键节点每生成一次打个点,这样我们就可以通过比较今天和昨天的打点数据来监控,以下为我们针对某一关键事件的打点数据:
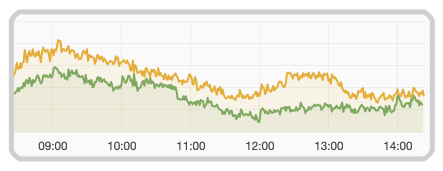
如图示:绿色代表今天打点数据,黄色代表昨天。
有了昨天和今天的打点数据我们要做监控就很简单了,可以对比同一时间段两者的打点数据,如果今天的打点数据相对于昨天下跌超过比如 50%,那么这个关键节点的路径可能是有问题的,就可以触发告警,如下图示:

这两种监控之所以在电商场景下可行主要有两个原因:
一是因为电商场景下的流量比较大,流量大,那么每分钟的打点数据就比较大, 这样通过下跌百分比来触发告警误差相对较小,所以可行,另外流量大所以意味着有任何的风吹草动,比如因为页面不可用造成的投诉短时间内会暴增,或打点数据短时间的急剧下降,都能在较短的时候内提早预警,让我们及时发现问题所在。
二是因为电商下的关键节点相对比较少,主要无非就是「添加购物车」与「下单」等关键节点,关键节点少意味着只要关键节点出了问题了,通过上文所述的下跌百分比告警排查关键节点的路径是否出问题即可,由于关键节点少,整个需要关注的核心链路相对比较短,所以排查起来相对比较容易一些。
三、金融监控的难点
上节介绍的电商场景下的两种方案在金融场景上都不适用,原因主要是因为金融是一个低频操作,且电商场景下的日活通常能达到几十上百万,但金融场景下的日活要少个几十倍,这就意味着每个关键节点的打点每小时可能只有几十不到,可能在长达几十分钟内关键节点对应的打点都为 0,所以也就无法用这种下跌百分比的形式进行告警。
为了更好地向大家介绍金融业务监控的痛点,还是先简单介绍一下金融业务。
四、金融业务简介
目前我们主要从事的是现金贷业务,属于助贷业务,所谓助贷,即平台方并不直接发放贷款,只是平台方利用自身的获客,贷后管理等优势为借款人撮合匹配资金方,以实现资金的融通,平台方收取相当的手续费。主要业务流程如下:
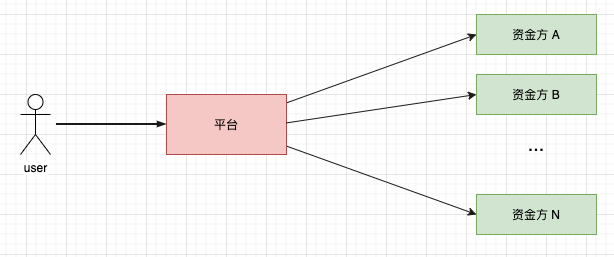
我们平台会为每一个用户挑选其中与之匹配的资金方进行授信,这些资金方的风控策略不同,所以授信通过率,借款通过率这些核心指标自然有较大的差异,像一些头部资金方如马上消金或 360 借钱等通过率比较高,我们会给予更多的流量,而一些不太知名的资金方这些关键指标表现不太如人意,给之分配的流量自然较少。
为每一个用户匹配申请资金方后,通常都要经历以下周期:
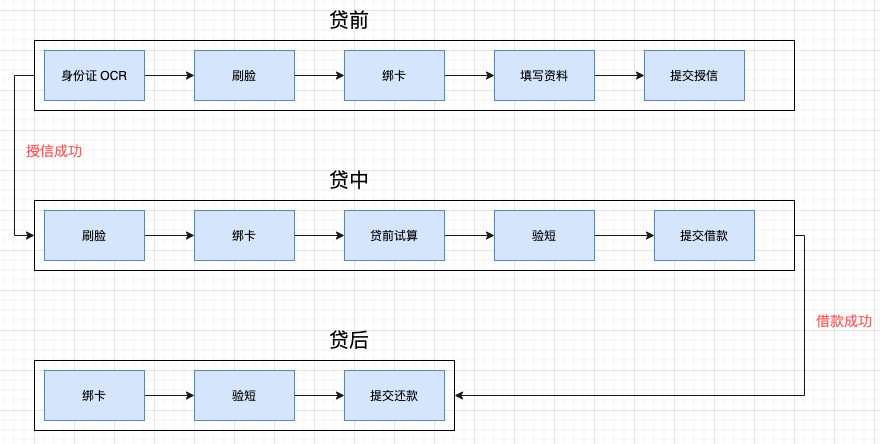
贷前:授信环节,资金方要给你额度,你总要提供身份证以及相关的学历等个人信息吧,这样资金方通过这些信息就可以评估你的信用,决定是否给你额度。
贷中 :即借款环节,授信通过之后,用户就可以借款了。
贷后 :即还款环节。
可以看到对于每一步,尤其是贷前和贷中,核心流程的关键节点都非常多,关键节点多就意味着漏斗大,用户的转化就越低,关键节点的打点(如提交授信,提交借款)可能一天只有几千,平均到每分钟也就几次甚至没有,而且由于金融本身是个非常低频的操作,用户的行为具有很大的不确定性,可能今天 8~9 点提交授信人数有 50,但第二天 8~9 点提交授信人数又降到个位数了,这些在电商里肯定会触发告警的现象在金融里却再正常不过。
所以初期常常出现这样一种现象:我们在监控图表上发现两天同一时间段某些资金方关键节点的打点(如提交授信,放款成功单数)相差巨大,但排查后发现链路却没有问题,搞得我们焦头烂额。
通过以上简介,相信大家不难理解电商场景下的监控不能照搬到金融场景中,我们必须要结合金融场景 低频的特点来设计一套相应的监控体系。
五、金融场景下监控的几种可靠手段
针对以上所述金融低频的特点,我们设计了一套相对有效的监控系统,思路如下:虽然贷前,贷中,贷后每个流程的关键节点都很多,但其实我们没必要对所有的关键节点都进行监控,我们只需要对 每个资金方的关键流程的成功结果(授信成功,借款成功,授信通过率,借款通过率)进行打点监控,因为如果授信或借款成功了,说明贷前和贷中的流程都没有问题了。
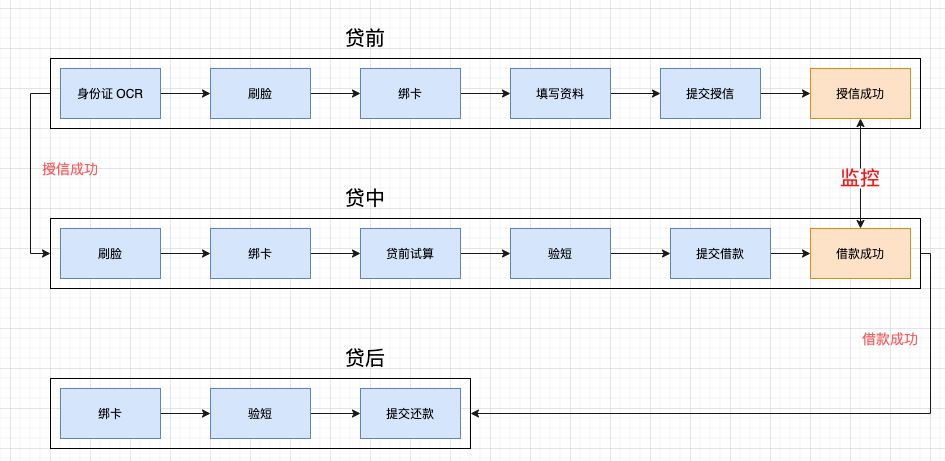
注意我们需要分别对 每个资金方的授信成功和借款成功都进行打点监控,因为统计总数成功没有意义,每个资金的风控策略和流量分配是不一样的,以成功总数来判断流程是否正常很可能导致一些资金方某天风控策略调整(或其他 bug)导致授信或借款全部失败而未被发现。
当然上文也说了,每个资金方授信成功或借款成功的总数很可能在几十分钟内都为 0,那我们可以以小时的成功总数来告警。
我们记录下每天每小时的成功总数,每半小时比较今天和过去一周同一时间段(平均值)近 X 小时内的成功数,如果低于过去一周平均成功数的一半,说明可能链路出问题了,就告警。
这个 X 怎么选择呢,如果最近一小时成功总数小于 20(这个阈值需要根据实际情况选取),那我们就选今天和过去一周同一时间段最近两小时的成功总数进行比较,如果还是小于 20 ,那就选最近三小时的成功总数进行比较,直到最近 X 小时的成功总数达到 20,这样误差就比较小了。
通过这种方式的告警有效率目前为止 100%! 也发现了线上多起问题,钉钉告警展示如下:

优质资金方由于通过率高,分配的流量大,所以对应的每小时的成功数相对来说比较多,用这种与过去一周同一时间段平均值比较的方式来进行告警确实可行,但对于那些通过率较差的资金方呢,这些资金方可能一天总共才有几个成功数,用上面的告警方式误差较大,那我们就拉长一下时间线,统计近 8 个小时此资金方的成功数,如果为 0 ,说明可能有问题:
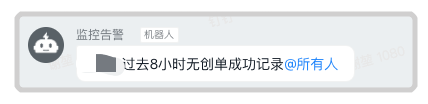
通过这种方式我们也发现了多起因为资金方风控调整导致授信/放款成功数降低导致的问题,及时通知资金方解决了问题。
迄今为止,我们总共接入了二十几家资金方,每个资金方都有自己的一套接口规范,每个资金方的接口都不一样,总共可能接入了几百上千个接口,这就带来了一些隐患,如果由于我们代码的 bug 或资金方内部问题导致接口请求失败(通常是接口返回的状态码为失败的状态码),我们很难发现,有人说这不简单吗,如果接口返回的是失败的状态码,针对此时的请求错误告警不就行了。
这里有两个问题:
一是这种告警代码应该写在哪里,有人说就写在每个资金方的请求底层啊,如果是这样的话,监控代码与业务代码紧藕合,而且我们接入了二十几家资金方,每一家的底层请求对应的文件里都要一个个的写告警代码,工作量巨大,且之后如果新接资金方很容易忘记把告警代码给加上。
二是并不是所有返回失败状态码的接口我们都要告警,有些是正常的请求失败,如「账户永久冻结」,「放款日当天不允许还款」,这些失败的请求并不是 bug 导致的失败,所以我们并不关心,就算给我们告警也没有意义,我们只对「姓名不能为空」这种会明显是 bug 导致的请求失败感兴趣,我们需要过滤过正常失败的告警。
先看第一个问题,每个资金方的底层接口请求伪代码如下:
// 接口调用String result = httpPost();
Response response = JSON.parseObject(result, Response.class);// 如果请求的状态码是失败的状态码 if (!response.getCode().equals(SUCCESS_CODE)) {
// 抛出异常,异常里带有为资金方返回的失败信息 throw new Exception(ErrorCodeEnum.ERROR_REQUEST_EXCEPTION, response.getMessage());
}
很显然如果能用切面拦截所有这些资金方抛出的异常,那我们就能把针对这些异常的告警统一写在切面里,不会对现有代码有任何入侵,且方便统一管理所有资金方的告警,也就完美解决了问题一。
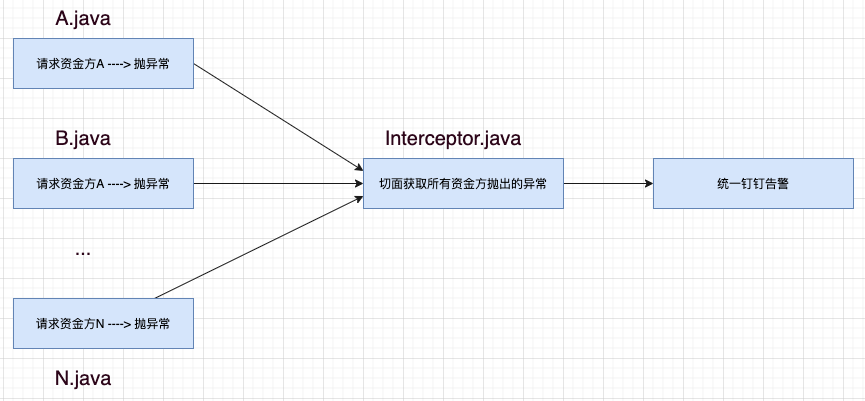
切面实现的伪代码如下:
@Aspectpublic class LoggingAspect {
//只捕获所有资金方请求文件所在的包 @AfterThrowing ("execution(* com.howtodoinjava.app.service.impl.*(..))", throwing = "ex")
public void logAfterThrowingAllMethods(CustomException ex) throws Throwable {
//发送抛出的错误信息至钉钉告警 sendDingWarning(ex.getMessage());
}
}
再来看第二个问题,如何过滤过我们不关心的正常失败请求抛出的异常呢。思路也很简单,设置一个白名单机制,如果我们发现失败的请求是正常的失败,把这个失败的信息加入白名单里即可。
这样如果某个资金方请求失败抛出异常了,我们只要看一下这个这个失败信息是否在白名单里即可,如果在,说明是正常的失败,不需要触发告警,如果不在白名单里,则触发告警。经过改造, 我们的告警流程变成了如下这样:
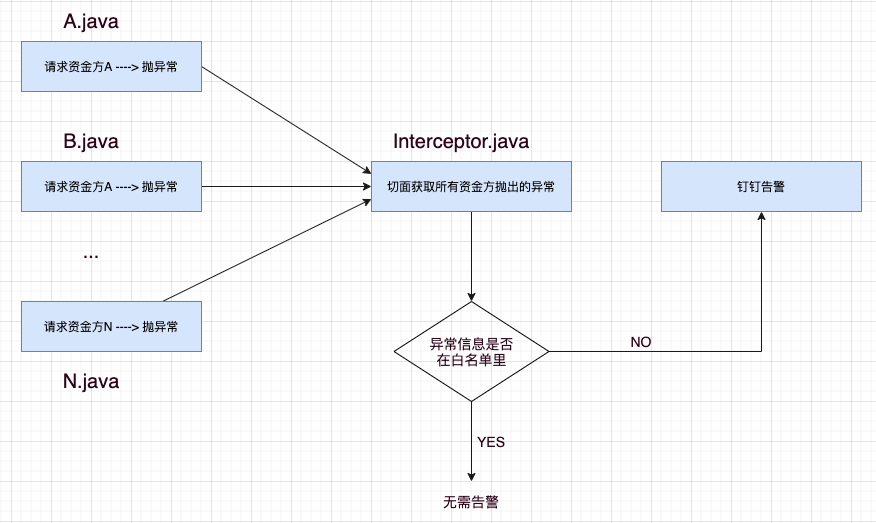
这里有一个小问题需要注意一下,这个白名单该怎么配置呢,一开始我们并不知道哪些失败的请求是正常的失败请求,所以一开始只能把所有失败的请求都告警,每发现一个正常的失败请求,就把此失败信息加到白名单里,所以这个白名单是不断动态变化的,而且也是需要实时生效的,我们选择了 360 开源的 QConf 来配置我们的白名单。
QConf 是一种基于 Zookeeper 的分布式管理服务,致力于将配置内容从代码中完全分离出来,及时可靠高效地提供配置访问和更新服务,使用 QConf 进行配置后,白名单的管理问题也解决了。
在我们的业务场景中,一个用户请求很可能会请求多个资金方的接口,如果某个资金方的服务出现问题,依赖于这个资金方接口的用户请求也就挂了,实际上在我们的业务场景中几乎每个请求都要请求资金方的接口,这也意味着只要某个资金方的服务不可用,我们业务也就不可用了,显然这是不能接受的。
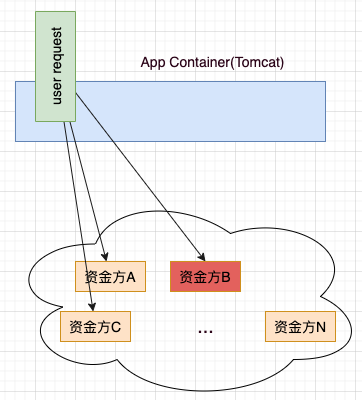
如图示:某次用户请求要请求多个资金方,如果资金方 B 的接口服务挂了,很可能导致此次用户请求也挂!甚至导致整个业务不可用!
所以我们必须引入熔断降级机制,当某个资金方服务出现异常时(如调用超时或其他异常比例升高),接下来的降级时间窗口内,对该资源的调用都自动熔断,快速失败,这样就避免了业务不可用的巨大隐患。
我们使用阿里的 Sentinel 来实现熔断降级,Sentinel 提供了几种方式来实现熔断,我们使用了 1 分钟内异常数超过阈值后进行熔断的这种方式,一旦触发了熔断,请求资金方接口就会抛出「DegradeException」,同样的也是在切面中捕获此异常,然后告警。
六、总结
本文总结分享了在金融这种低频业务场景下设计监控的几种方式,通过以上几种方式基本保证了大盘的稳定,不过其实第一种监控(针对成功数、成功率)如果换成机器学习中的行为预测效率应该会更高,也会更及时一些。
不过团队里面没有这方面经验的人才,所以暂时用针对成功数/成功率的监控来替代,后续如果有机会引入机器学习的尝试,相信会有不错的效果。如果你有更好的监控方法可以分享,欢迎评论区走起哦。
作者丨码海来源丨码海(ID:seaofcode)