BIGO技术:实时计算平台建设
- - InfoQ推荐BIGO全球音视频业务对数据的实时能力要求越来越高,数据分析师希望多维度实时看到新增用户、活跃用户等业务数据以便尽快掌握市场动向,机器学习工程师希望实时拿到用户的浏览、点击等数据然后通过在线学习将用户偏好快速加入到模型中,以便给用户推送当前最感兴趣的内容,APP开发工程师希望能够实时监控APP打开的成功率、崩溃率.
一、业务背景
BIGO全球音视频业务对数据的实时能力要求越来越高,数据分析师希望多维度实时看到新增用户、活跃用户等业务数据以便尽快掌握市场动向,机器学习工程师希望实时拿到用户的浏览、点击等数据然后通过在线学习将用户偏好快速加入到模型中,以便给用户推送当前最感兴趣的内容,APP开发工程师希望能够实时监控APP打开的成功率、崩溃率。这些实时数据的能力都要依靠实时计算平台来提供。从业界来看,实时化的趋势正在加速,本文将介绍BIGO基于flink的实时计算平台的建设经验和成果。
二、平台介绍
BIGO实时计算的发展大概分为两个阶段,在2018年之前,实时场景还比较少,实时的作业数量也不多,当时主要采用Spark Streaming来支持。从2018年开始,在综合考虑了Flink相对于Spark Streaming的优势之后,BIGO技术决定将实时计算平台切换到基于flink的技术路线上来。经过近两年的发展,BIGO实时计算平台日趋完善,基本支持了公司内主流的实时计算场景,下图是BIGO实时计算平台的架构图:
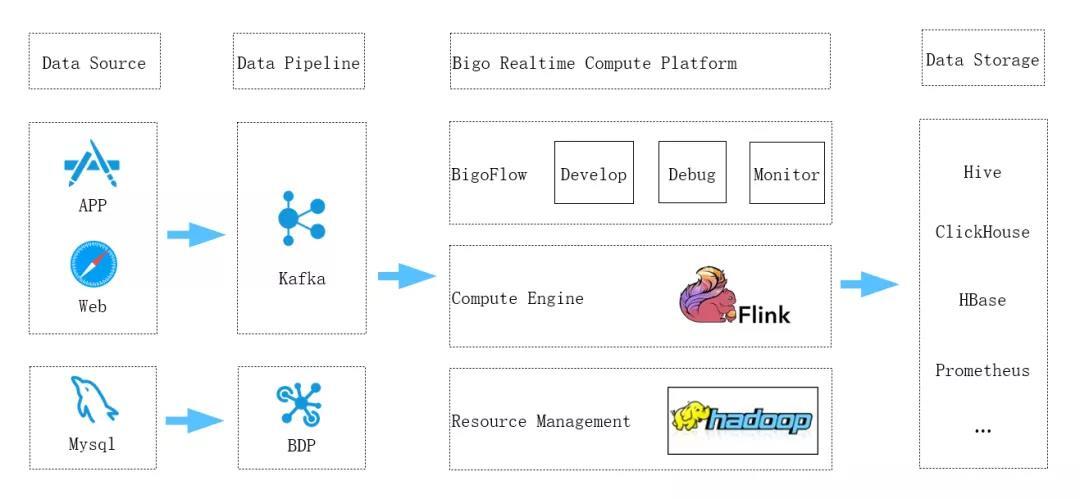
实时计算的数据来源可分为两大类,一类是用户在APP或者浏览器里的浏览、点击等行为日志,通过kafka收集进入实时计算;另一类是用户的行为产生的关系型数据库里记录的改变,这些改动产生的biglog被BDP抽取进入实时计算。
从图中可以看出,BIGO实时计算平台底层基于yarn来做集群资源管理,借助于Yarn的分布式调度能力,实现大规模集群下的调度。实时平台的计算引擎在开源Flink的基础上,为适配BIGO的场景进行了特殊的定制及开发。实时平台的上层是BIGO自研的一站式开发平台BigoFlow,在这里,用户可以方便的进行作业的开发、调试以及监控运维。BigoFlow提供了完善的SQL开发能力、自动化监控配置能力以及日志自动收集、查询能力,让用户仅需要一条SQL,就可以完成一个业务作业。它具有以下功能:
1. 提供了强大的SQL编辑器,可以进行语法检查及自动提示。
2. 可以对接公司所有的数据源及数据存储,省去了业务方自定义的工作。
3. 日志自动收集到ES里,用户可以方便的检索和查询,可以快速的定位错误。
4. 作业关键指标自动对接到公司的监控告警平台,用户不用再自己配置。
5. 收集所有作业的资源使用情况,自动进行分析,帮助识别、治理不合理作业。
实时计算出来的结果根据业务的需求,会存放到不同的存储中。ETL类作业的结果通常会入库到hive中,需要进行adhoc查询的数据通常会放到clickhouse里面。监控告警等类型的作业可以直接把结果输出到告警平台的Prometheus数据库里,供告警平台直接使用。
三、业务应用
随着实时计算平台的发展,越来越多的场景都搬到了BigoFlow平台上,实时计算也给这些场景带了很多好处,下面BIGO技术以几个典型场景为例来说明实时计算为它们带来的能力或者性能的增强。
数据ETL
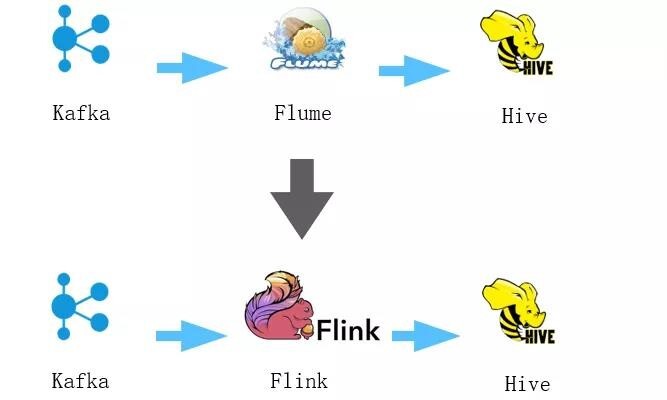
数据的抽取、转换是一个典型的实时场景,用户在APP、浏览器里的行为日志是实时不间断产生的,要实时的去采集并经过抽取转换,最后入到数据库里。BIGO之前的ETL场景数据路径通常是Kafka->flume->Hive。经过flume入库的路径存在着一下几方面的问题:
1. Flume的容错能力差,遇到已成可能会导致丢数据或者数据重复。
2. Flume的动态扩展能力差,流量突然到来时候很难立刻扩展。
3. 一旦数据字段或者格式发生变化,flume比较难于灵活调整。
而Flink提供了基于state的强大的容错能力,可以端到端exactly once,并发度可以灵活的调整,Flink SQL可以灵活的去调整逻辑。因此,绝大部分的ETL场景目前都已经迁移到了Flink架构上。
实时统计
作为一家有多个APP产品的公司,BIGO需要有大量的统计指标来反应产品的日活、营收等指标。传统这些指标一般都是通过离线Spark作业来每天或者每小时计算一次。离线计算很难保证数据的产生的及时性。经常会出现重要指标延迟产生的问题。因此我们慢慢的将重要指标通过实时计算来产生,极大的保证了数据产生的及时性。最显著的是之前一个重要指标经常延迟导致它的下游在下午才能产出,给数据分析师带来了很多困扰,改造为实时链路后,最终指标在早上7点就能产出,数据分析师上班就可以使用了。
机器学习
随着信息的爆炸发展,用户的兴趣转移的越来越快,这就要求机器学习能够尽快根据用户当时的行为推荐他感兴趣的视频。传统机器学习基于批处理的方式,通常要到最快小时级别才能更新模型。今天基于实时计算的样本训练可以不间断的将样本训练成实时模型并应用于线上,真正做到了在线学习,将根据用户行为产生的推荐做到分钟级别更新。目前,机器学习的作业已经占到了实时计算集群的50%以上。
实时监控

实时监控也是一个很重要的实时场景,app的开发者需要实时监控app打开的成功率等指标,如果出现异常,就要及时告警通知出来。之前的做法通常是原始数据存放于Hive或者ClickHouse,在基于Grafana的监控平台配置规则,每个一定时间用Presto或者ClickHouse去查询一下,根据计算出来结果进行判断是否需要告警。这种方式存在几个问题:
1. Presto或者ClickHouse本身虽然是OLAP的引擎,性能很好,但并不保证集群的高可用及实时性。而监控对实时性和高可用要求比较高。
2. 这种方式的每次计算指标都要把当天的全部数据计算一遍,存在着极大的计算浪费。
而通过实时计算的监控方案可以实时计算出来指标,直接输出到Grafana的数据库里,不仅保证了实时性,更是可以将计算的数据量减少上千倍。
四、BIGO实时平台特色
BIGO实时计算平台在发展过程中,逐步根据BIGO内部业务的使用特点,形成了自己的特色和优势。主要体现在以下几个方面:
元数据打通
一个常见的情况是数据的产生者和使用者不是同一批人。打点的同事将数据上报到kafka或者hive里,数据分析师要用这些数据去计算。他们不知道kafka的具体信息,只知道要使用的hive表名。为了减少用户使用实时计算的麻烦,BigoFlow将元数据和Kafka、hive、ClickHouse等存储都进行了打通,用户可以在作业里直接使用hive、ClickHouse的表,不需要写DDL,BigoFlow自动去解析,根据元数据的信息自动转换成Flink里的DDL语句,极大的减少了用户的开发工作。这得益于BIGO计算平台的统一规划,是很多离线、实时系统分开的公司所做不到的。
端到端的产品化方案
BigoFlow不仅仅是实时计算的平台,为了方便用户使用或者迁移,也会根据业务场景,提供端到端的整个解决方案。像前面介绍的监控场景,用户有很多监控业务需要迁移,为了尽量减少的工作,BigoFlow专门提供了监控场景的解决方案,用户只需要将计算监控指标的sql迁移到flink sql,其他包括Flink作业的DDL,数据sink到监控平台等工作完全不用做,都由BigoFlow自动实现,用户原先配置的规则也都不用变。这使得用户可以用最少的工作量完成迁移。
另外前面也提到了,BigoFlow自动将用户作业的关键指标添加了告警,这基本满足了绝大多数用户的需求,让他们专心于业务逻辑,而不用操心其他事情。用户的日志也会自动收集到ES里,方便用户查看。ES里有沉淀了一些总结出来的调查问题的搜索query,用户可以根据现象直接点击查询。
强大的hive能力
由于BIGO内的绝大部分数据都是存在Hive里的,实时作业也经常需要将结果写入hive,不少场景也需要能够从hive里读数据。所以BigoFlow跟hive的集成一直走在业界的前列。在社区1.11之前,BIGO技术就自己实现了向hive写数据,并可以动态更新meta的能力。1.11还未正式发布,我们就在1.11的基础上,自研开发了流式读取hive表支持EventTime、支持动态过滤分区、支持txt格式压缩等功能,这些功能都领先于开源社区。
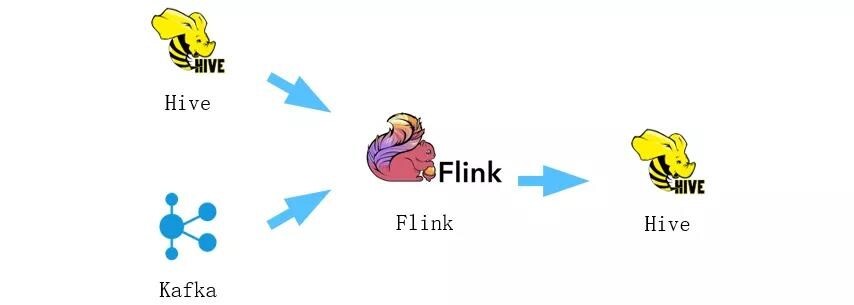
这是我们在ABTest上通过Flink实现的一个批流统一的场景。正常情况下,flink消费kafka的实时数据,实时计算结果存入到hive。但作业经常会遇到业务逻辑调整,需要重新追数据进行对数。由于数据量很大,如果追数据还从kafka消费,就会对kafka带来很大的压力,影响线上的稳定。由于数据在hive里也存了一份,我们追数据的时候,选择从hive里读取,这样用同一份代码,可以走离线和在线两条路,最大限度减少了追数据对在线的影响。
自动化ETL作业生成
Flink目前承接了大部分的ETL场景。ETL作业的逻辑一般比较简单,但作业众多,而且用户上报的数据格式会经常变化,或者字段进行了增减。为了减少用户开发、维护ETL作业的成本,我们开发ETL作业自动生成的功能,用户只需要提供上报数据的topic和格式,就可以自动生成ETL作业,将结果写入到hive中。上报数据格式或者字段发生了变化之后,也可以自动将作业进行更新。目前支持json、pb等多种数据格式。
五、展望
随着BIGO业务的快速发展,BigoFlow实时计算平台也在不断的壮大和完善,但也还有很多需要改进以及提高的地方,BIGO技术未来将会在平台完善和业务支持两个方面重点建设:
平台完善:重点提升平台的产品化水平。主要包括几个方面:开发自动化资源配置、自动调优等功能,可以根据作业的实时数据量,自动配置作业需要的资源,在流量高峰进行自动扩展,在流量低谷自动缩容;支持表血缘关系展示,方便用户分析作业之间依赖关系;支持异地多集群,flink上面支持了众多关键业务,需要极高的SLA保证,我们会通过异地多机房来保证关键业务的可靠性。探索流批统一、数据湖等场景。
支持更多业务场景:开拓更多机器学习、实时数仓的场景,进一步推广Flink SQL的使用。
六、团队简介
BIGO大数据团队专注于在PB级别数据上实现快速迭代,用大数据分析技术赋能上层业务。具体负责面向公司所有业务建设EB级别的分布式文件存储、日均万亿消息队列和50PB规模的大数据计算,包括批、流、MPP等多种计算架构,涵盖从数据定义、通道、存储与计算、数据仓库和BI等全链路技术栈。团队技术氛围浓厚,有众多开源软件的开发者,期待优秀的人才加入我们!
稿件来源来自于BIGO技术自媒体