[原]Java应用日志如何与Jaeger的trace关联
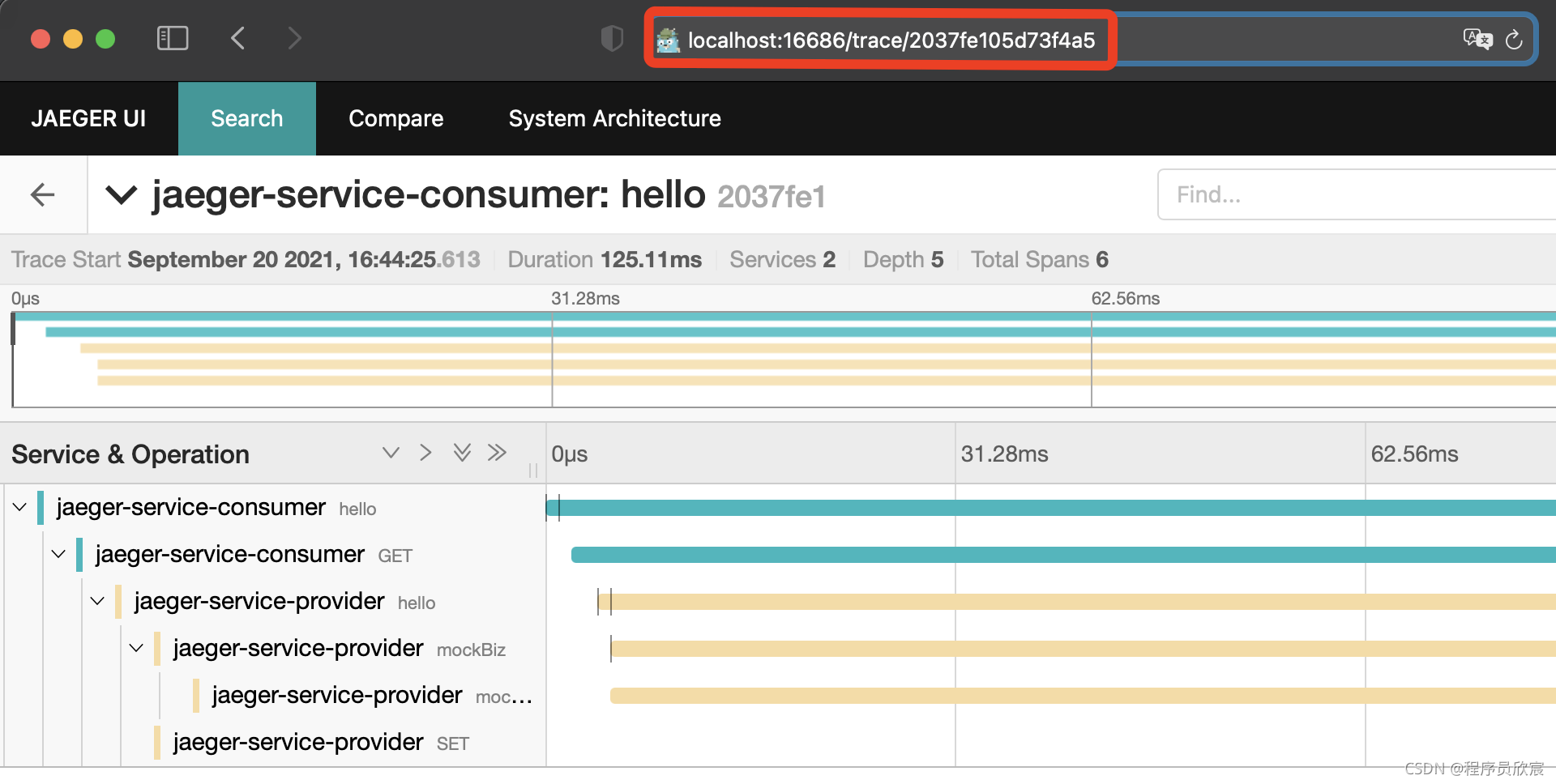
- - 程序员欣宸的博客这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos. 经过 《Jaeger开发入门(java版)》的实战,相信您已经能将自己的应用接入Jaeger,并用来跟踪定位问题了,本文将介绍Jaeger一个小巧而强大的辅助功能,用少量改动大幅度提升定位问题的便利性:将业务日志与Jaeger的trace关联.
这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<!--%logger{10}表示类名过长时会自动缩写-->
<pattern>%d{HH:mm:ss} [%thread] %-5level %logger{10} [user-id=%X{user-id}] %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
</appender>
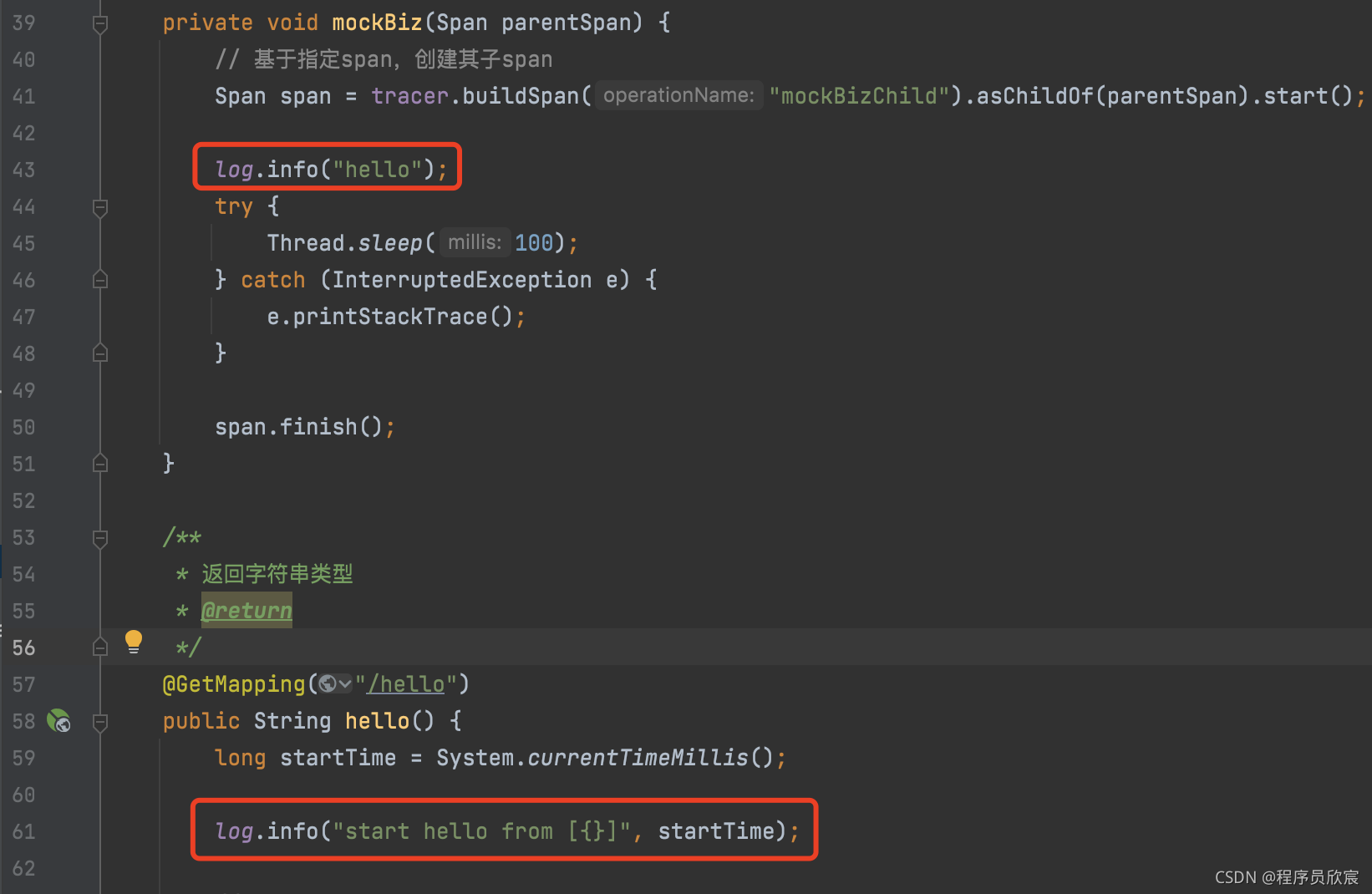
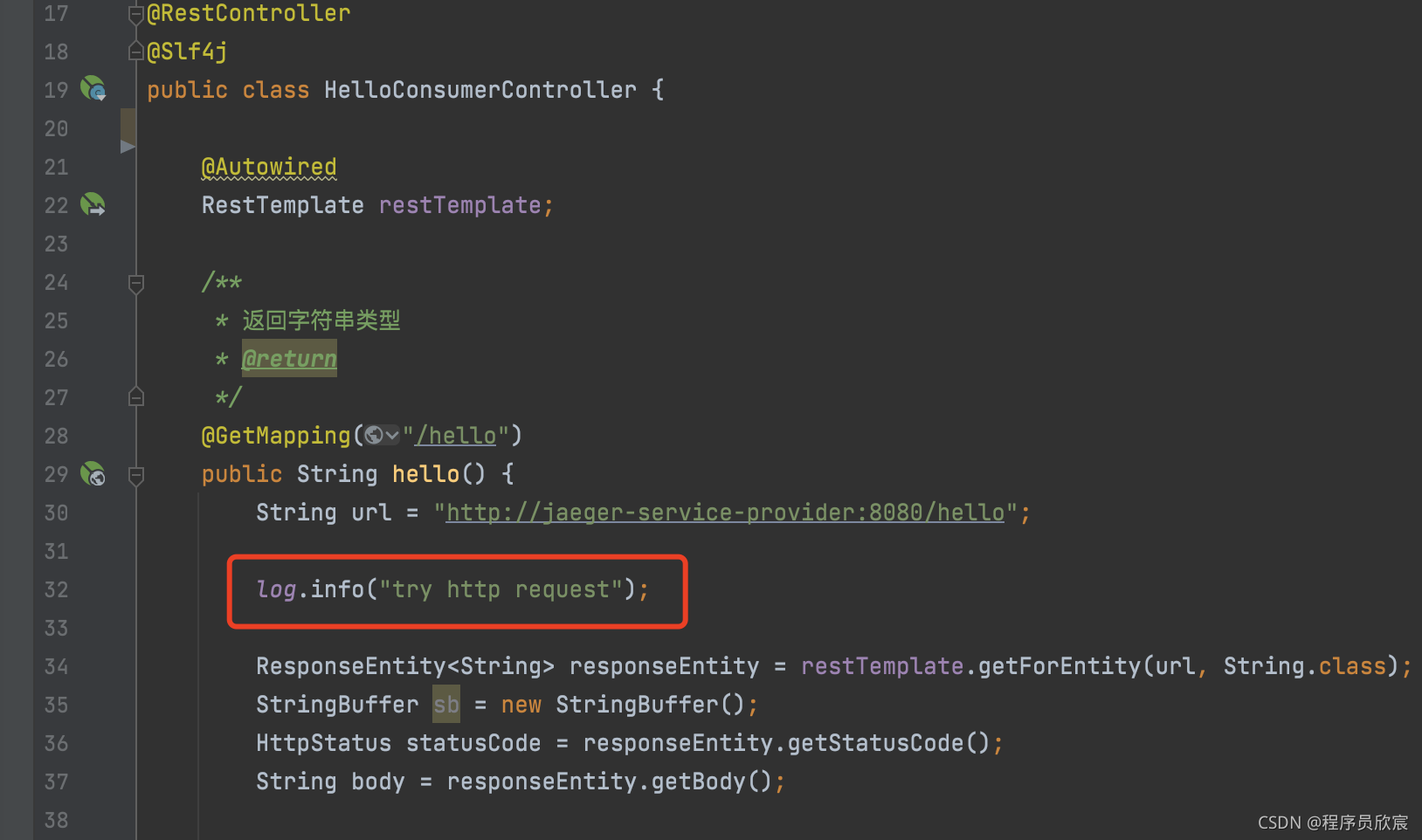
@GetMapping("/test")
public void test() {
MDC.put("user-id", "user-" + System.currentTimeMillis());
log.info("this is test request");
}
15:17:47 [http-nio-18081-exec-6] INFO c.b.j.c.c.HelloConsumerController [user-id=user-1632122267618] this is test request
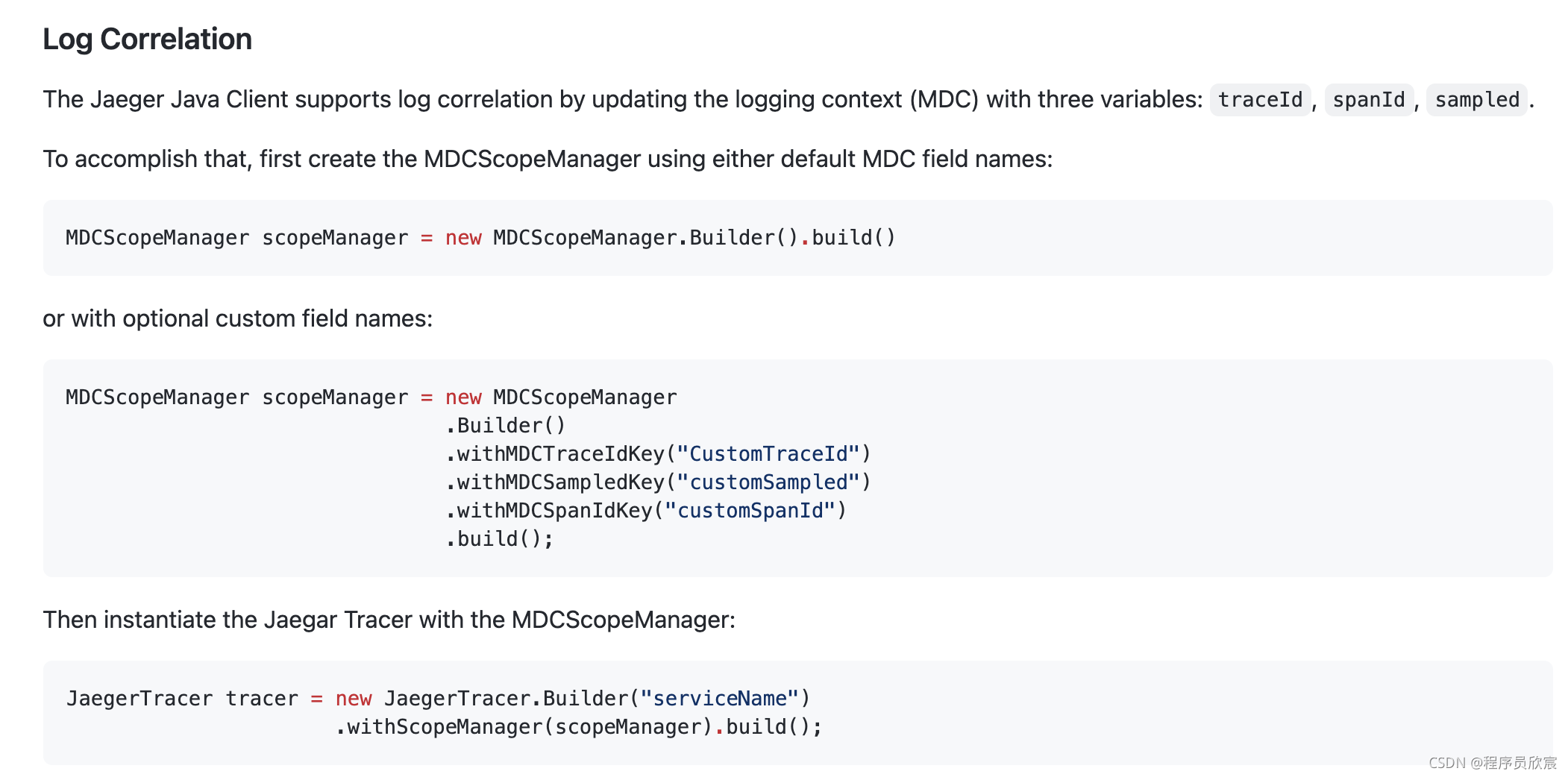
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<contextName>logback</contextName>
<!--输出到控制台-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<!--%logger{10}表示类名过长时会自动缩写-->
<pattern>%d{HH:mm:ss} [%thread] %-5level %logger{10} [traceId=%X{traceId} spanId=%X{spanId} sampled=%X{sampled}] %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
</appender>
<root level="info">
<appender-ref ref="console" />
</root>
</configuration>
package com.bolingcavalry.jaeger.provider.config;
import io.jaegertracing.internal.MDCScopeManager;
import io.opentracing.contrib.java.spring.jaeger.starter.TracerBuilderCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class JaegerConfig {
@Bean
public TracerBuilderCustomizer mdcBuilderCustomizer() {
// 1.8新特性,函数式接口
return builder -> builder.withScopeManager(new MDCScopeManager.Builder().build());
}
}