软件架构设计
- - 企业架构 - ITeye博客软件架构设计尚没有万灵的方法论支持,还是个非常新兴的行业,给出个人理解的行业软件架构设计过程,受个人水平有限,仅供参考:. 1.业务分析:针对目标行业的业务战略、蓝图、业务功能及流程进行分析,提出其中部分功能可以使用信息化进行处理,通过分析可以得出信息化要解决的问题. 2.解决方案设计:根据业务战略,形成行业信息化解决方案.
全链路改造的目的在于使我们的系统适应从单地部署到多地域部署的转变,改造涉及到的点非常多,主要包括:
1)应用代码改造
导购链路所有的依赖是否都能做多地部署,如果没法多地部署跨地域时延是否会被放大。
2)服务之间的流量路由策略
导购链路涉及到很多异构的子系统,这些异构系统之间的流量是否遵循同地域优先,当某个地域服务挂了之后流量是否允许自动切到其余地域。
3)流量强纠偏
导购的请求链路较为复杂,会依赖众多异构的子系统。虽然域名解析时流量会路由至对应的区域,但是在后续链路仍然有可能发生流量窜到其余地域的情况,这种情况下理论上会对用户体验造成影响,所以在导购链路的每一跳节点都应该有纠偏策略。
4)外部流量纠偏
外部流量由于分发策略我们没法管控,会导致预期之外的流量流入。为了避免这种情况,我们也需要有一个流量纠偏的策略。
改造点3在数据强一致场景是必不可少的,但是对本次导购链路,由于改造成本和时间的关系,最终我们放弃了改造点3。因为改造点2保证了正常情况下流量路径是符合预期的,只有异常情况才有可能发生流量窜到其他区域,但是这种情况我们认为:
低频且持续时间不长。
短时间的不一致对业务影响可控。
应用代码改造主要包括:
对于那些没法做多地部署的依赖,评估其对数据一致性的约束,如果是弱一致性,则考虑使用富客户端模式,在富客户端模式中优先读缓存,不命中再走一次RPC,通过缓存降低跨地域请求的频率。
没法做多地部署且要求数据强一致性的依赖,需要避免跨地域访问时延被放大。不存在跨地域延时的时候串行并行的区别并不明显,但是引入跨地域时延之后串行和并行的区别就会非常明显,因此对这部分依赖需要做并发改造。另一方面在改造过程中梳理出核心依赖&非核心依赖,核心依赖强制要求单元化,对于非核心依赖做到并发&可观测&可降级。
缓存改造。由于以前对缓存的使用不够严谨,会导致单地域部署下被掩盖的问题在多地域部署之下暴露出来。比如下面这种场景,在某个场景写入某个key,然后在另一个场景下读取这个key。在单地域部署下不会有问题,但是一旦多地域部署之后就有可能出现读写不同地域的情况导致数据不一致。
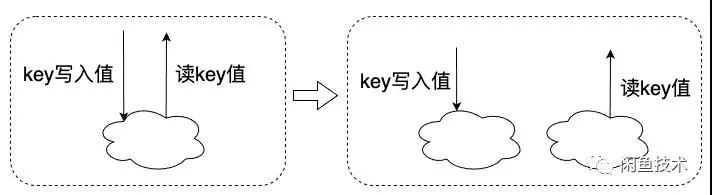
这种情况下我们需要:
强制写中心主节点。
开通主节点到其他地域的数据同步。
总的来说缓存改造两大原则:
如果是非持久化缓存,则不用做任何改造。因为这种场景缓存不命中会有数据加载过程。但是很多非持久化缓存场景滥用了持久化缓存,针对这类case需要规范使用,改造成非持久化缓存。
如果是持久化缓存,分为两种情况:
强一致性,如分布式锁,这种情况强制读写中心主集群。
非强一致性,则强制写中心主节点,就近读。
导购链路涉及到很多异构系统,包括各个子领域应用构成的微服务集群,以及众多搜索&推荐服务。异构主要体现在:
编写语言以及部署&运维平台的差异。
服务注册发现机制不一样,主要包括configserver/vipserver/zookeeper。
因此主要改造内容在于规范对这些组件的使用,调整流量路由策略保证流量区域内自闭环。
为了防止外部流量对闲鱼导购流量的影响,我们在统一接入层加了一条流量纠偏策略:对于外部非导购链路的流量,强制切回中心区域。这一点非常重要,因为对于部署范围之外的服务,如果因为这个原因导致流量到了其他可用区域,其返回数据的正确性我们没法做保证。
3、服务集群部署方案
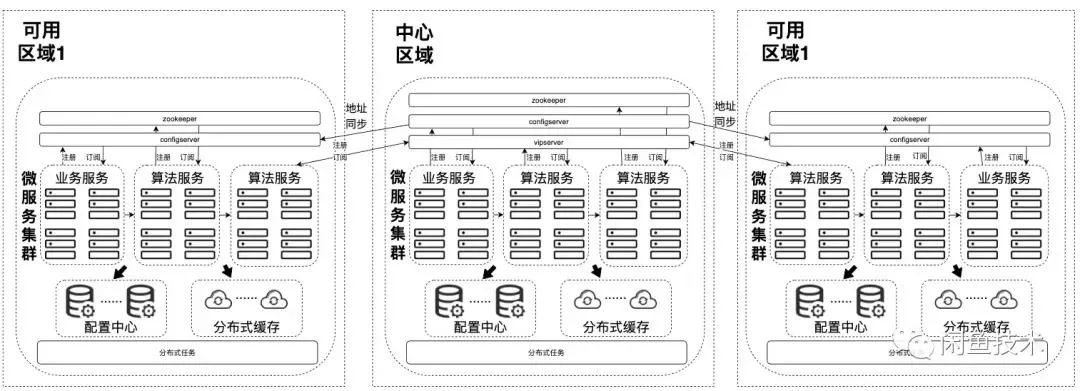
微服务集群整体采用对等部署。微服务集群按照服务发现&注册机制的不同划分成三类:
采用HSF作为RPC框架的业务服务,采用configserver做服务发现,configserver同时在多地域部署,彼此之间互相隔离,各地域部署的服务只拉取本地域内的configserver数据,通过这种方式实现地域之间的流量隔离。但是中心区域的数据会同步至其他区域(区域挂了流量可以路由到中心区域,保证服务可用)。
采用HTTP调用的算法服务集群由于历史&异构原因,采用了两种服务注册&发现方式
Zookeeper。Zookeeper在中心和区域都做单独部署,客户端请求的时候按照地域拉取对应的Zookeeper。通过这种方式实现流量的同机房访问,地域彼此间数据隔离,当单个地域服务出现问题时,只能通过将其他区域的服务数据挂载到故障地域对应的Zookeeper下面来进行恢复。
vipserver(阿里自研的一套集群路由软件负载均衡系统)。由于vipserver本身是分布式的负载均衡系统,且支持多种路由方式,故只部署一套。
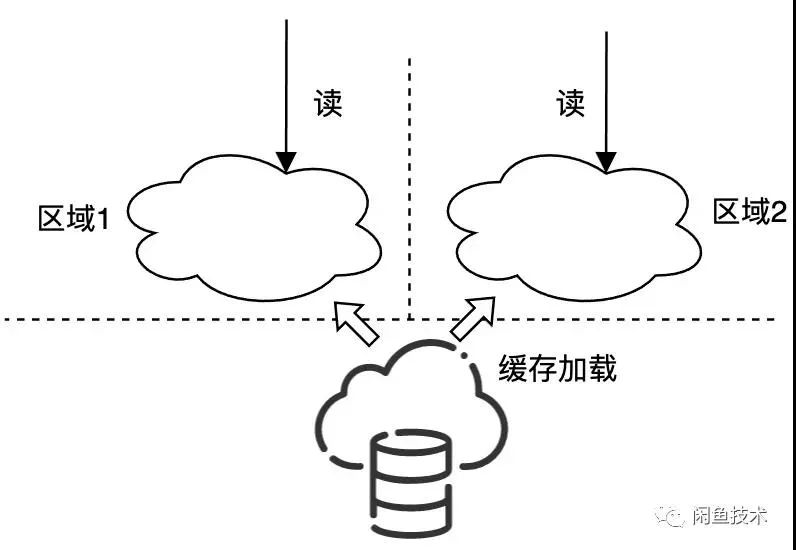
导购链路使用缓存的地方很多,大致分成两种用法:
缓解持久层的访问压力。先访问缓存,缓存如果没有数据则请求持久化层并把数据加载至缓存中,缓存本身不做数据一致性保证。这种情况比较好处理,因为不涉及到多区域之间的同步,只需要简单做多地域部署即可。
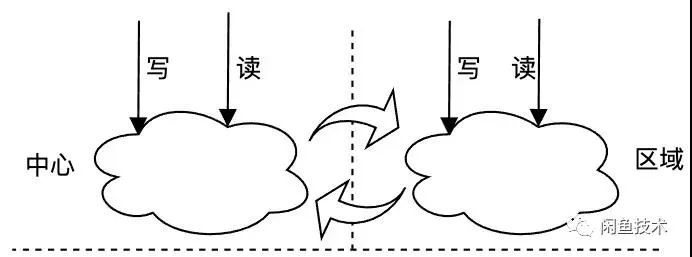
用作数据持久化。典型的如分布式锁,计数器等。这种场景会有中心和区域的概念,彼此间双向同步,这种场景在单区域部署的时候和上面的用法没有太大区别,但是在多地域部署架构下,就会因为双写导致数据出现不一致,因此需要保证同一个key同一时间不能在多区域同时写。
区域同步至中心。因为数据需要做持久化,所以会在中心有一份完整的数据集,区域保证数据的最终一致性即可。
中心同步至区域。保证区域的数据和中心的数据一致。
4、数据库部署
按照分布式系统的CAP定理:Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。所以严格意义上来说,数据库的异地部署只能三选二。但是在分布式系统中必然是分区的,而且分区之间的网络我们没法控制,也就是说P是一个事实,我们只能从C和A中二选一,这分别对应着数据库的两种数据复制方式。
主从复制模式的MySQL:中心写成功即返回,从节点依赖主从之间的数据同步。这种模式下保证了A和P,牺牲了C。
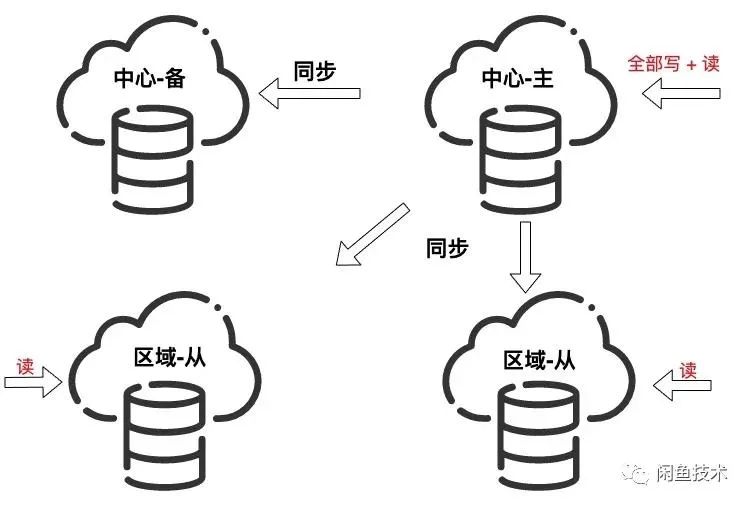
双向复制模式的MySQL:没有主从节点之分,节点与节点之间实现数据最终一致性。这种模式下同样保证了A和P,牺牲了C。

采用Paxos协议的分布式数据库如Google的Spanner等,采用Paxos协议来保证数据的强一致性,但是在Master节点挂了之后在新的Master选举出来之前不可用,即保证了C和P,牺牲了A。
一方面根据导购链路的特点(绝大部分都是数据读取操作,可以容忍短时间内的不一致)。另一方面原有的数据存储采用MySQL,考虑到成本,最终选择主从复制模式MySQL。
总结
异地部署给系统带来的最大挑战是物理距离带来的网络延时,整个系统设计都围绕着这个展开。总的来说在解决跨地域延时过程中我们遵循两个大的原则:
流量地域内自闭环。
坚持可用性优先。在这两个大原则之下从接入层,服务层以及数据存储层做了相应的改造&部署。
目前闲鱼部分链路已经实现了两地三机房部署,并且已经承接线上流量,具备了异地容灾的能力。同时经过本次改造,导购链路具备了较好的扩展性,能够以极低的成本快速部署至更多机房。
但是一方面由于导购链路大部分都是只读场景,对数据要求弱一致性即可。对于数据强一致性场景带给系统的挑战会更大。另一方面业务是一个不停演进的过程,如何保证在演进过程中仍然能保证异地多活的部署架构,这是急需解决的问题。
作者丨吴白来源丨公众号:闲鱼技术(ID:XYtech_Alibaba)dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]