Weblogic10.3部署问题的解决方法
今日,将我编写的S2SH DWR项目移植到weblogic11上,遇到一大堆的问题,但都被我一一解决。现将碰到的问题,汇总如下。
首先在oracle网站上下载weblogic11R1,然后安装上。注意,安装时带上eclipse插件。这个插件可以单独运行,是个集成了weblogic server配置的eclipse.运行eclipse,新建server 并配好。
建好Weblogic域后,就可以运行了,注意建域的时候,要选择开发模式。如果选择生产模式,在最后封装成自启动系统服务时,会失败。为了兼顾稳定,JDK可以选择生产模式的JDK。然后就可以用eclipse打包发布了。
1、首先碰到的是打包后不能运行的问题,解决方法如下,将打包后的文件解压,成为一个目录。然后以目录的形式在Admin Server Console中安装。就能解决这个问题。另外,如果发布后想以更改上下文根,可以在部署后,更改,如改为 / ,之后,会出现上下文 (未指定值),这样就是以网站根发布了。
2、字符集问题。在Jsp中pageEncoding选择GBK,但是content中的charset一定是utf-8。然后原有的工程的WEB-INF下建立weblogic.xml文件。文件头可以到安装目录的例子里去找。然后加上
<wls:charset-params>
<wls:input-charset>
<wls:resource-path>/*</wls:resource-path>
<wls:java-charset-name>utf-8</wls:java-charset-name>
</wls:input-charset>
</wls:charset-params>
并且将web.xml中spring的转码设为GBK
<filter-name>encodingFilter</filter-name>
<filter-class>
org.springframework.web.filter.CharacterEncodingFilter
</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>utf-8</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>encodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
如果这样,可能出现一些js文件失效的情况,可以将js文件用记事本打开,然后另存为utf-8编码,就能解决了。
3、加载HIbernate文件时,出现错误。HqlToken的错误。原因是antlr-2.7.6.jar与weblogic的自带的冲突引起的。解决办法在weblogic.xml里加入
<wls:container-descriptor>
<wls:prefer-web-inf-classes>true</wls:prefer-web-inf-classes>
</wls:container-descriptor>
让weblogic优先使用工程自带的包,这个方法要加在字符集之前。
注意此处网上还有一种解决办法,即在用户自定义域环境变量里添加pre classpath.这种方法虽然以控制台启动不报错。但是制作成自启动系统服务后,仍然会出现Hibernate的错误。
4、系统集成了DWR,会在使用时报CSRF错误。需要在web.xml文件里关于dwr的配置修改为如下
<servlet>
<servlet-name>dwr-invoker</servlet-name>
<servlet-class>org.directwebremoting.servlet.DwrServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<param-name>crossDomainSessionSecurity</param-name>
<param-value>false</param-value>
</init-param>
<init-param>
<param-name>allowScriptTagRemoting</param-name>
<param-value>true</param-value>
</init-param>
</servlet>
变红的部分是新加上去的。这样就不会出现跨域访问安全的问题了。
5、在Tomcat下,引用另外一个jsp的时候正反斜杠是不区分的。但是到了weblogic下,会报文件找不到的情况。将 \ 改为 / 即可。
6、我单位上使用的是ISA2006,在ISA里要将以前的专门的发布网站协议去掉,然后自己新建一个普通的访问协议即可。否则会出现端口占用的情况。
7、最后是制作成自启动系统服务。在weblogic安装目录下,找到wlserver_10.3\server\bin下的installSvc.cmd文件。在"%WL_HOME%\server\bin\beasvc" -install -svcname:"beasvc %DOMAIN_NAME%_%SERVER_NAME%" -javahome:"%JAVA_HOME%" -execdir:"%USERDOMAIN_HOME%" -maxconnectretries:"%MAX_CONNECT_RETRIES%" -host:"%HOST%" -port:"%PORT%" -extrapath:"%EXTRAPATH%" -password:"%WLS_PW%" -cmdline:%CMDLINE%
之前加上
set PRODUCTION_MODE=true
set DOMAIN_NAME=base_domain
set SERVER_NAME=AdminServer
set USERDOMAIN_HOME=C:\Ora\user_projects\domains\base_domain
set WLS_PW=xxxxxx
在命令行执行后就可以了。
删除服务用uninstallSvc.cmd,在执行之前先设好
set DOMAIN_NAME=base_domain
set SERVER_NAME=AdminServer
以上就是我在移植时碰到的问题。如有其它问题,请大家一起探讨。
Oracle高可用架构
作者: Uwe Hesse, 译者: Jametong
Oracle高可用架构是我所讲课程里的一个热门话题.本文尝试对此话题做一个总体的说明,内容涵盖"普通的"单实例数据库,DataGuard,RAC以及扩展RAC(有时也被称为"伸展集群").Rac与Dataguard组合在一起就是Oracle公司推广的最大可用性架构(Maximum Availability Architecture,MAA).除这些Oracle的HA解决方案外,我还会简单介绍一个第三方的HA解决方案(远程镜像,Remote Mirroring).我不准备深入介绍所有这些解决方案的细节,而只是想做出一点区分的工作,并简要介绍它们各自的优势以及可能的缺陷.
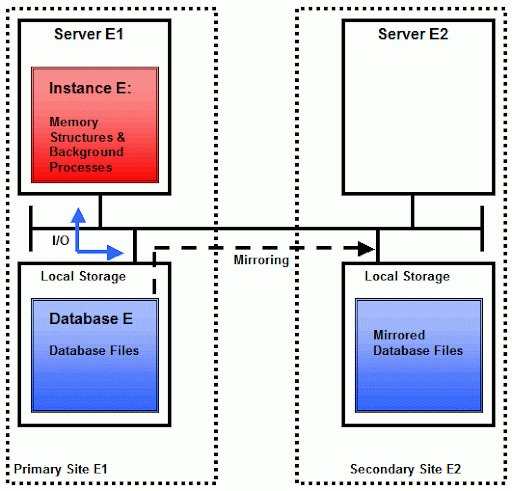
首先,我们将考察目前为止仍然是应用最为广泛的Oracle数据库架构:单实例数据库.一个Oracle数据库总是由一个数据库(由数据文件,在线重做日志控制文件组成)与一个实例(有内存结构,比如数据库高速缓冲区;以及后台进程,例如数据库写进程)组成.如果我们有一个数据库以及多个访问这个数据库的实例,这就是一个RAC.如果只有一个实例访问这个数据库,就是单实例数据库.下图是一个所有组件都存储在一个服务器上的简单安装版本:
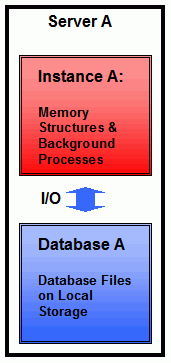
将数据库文件放置在SAN(存储区域网络)的配置也是目前比较常见的配置,如下图所示:
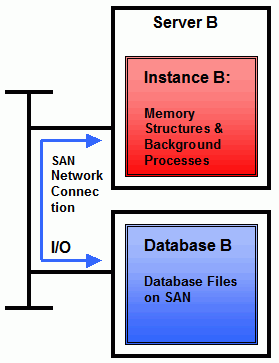
从高可用的角度来看,这个架构是非常脆弱的:服务器A与服务器B都是单点故障,数据库A与数据库B也都是单点故障.从而这些服务器所在的站点也是单点故障.这样,只要其中一个单点发生故障,整个数据库将不可用.一个"普通的"RAC就是为了解决其中的服务器单点故障的,如下图所示:
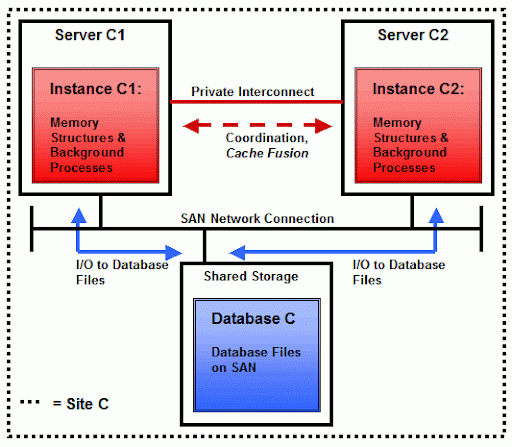
如果两个服务器的其中一个发生故障,数据库C将仍然可用.当然,使用RAC并不仅仅是为了实现HA.在使用RAC的其它的理由中,一个比较可靠的理由是为了实现伸缩性(Scalability):如果应用需求在将来出现增长,我们可以通过添加新的节点(Node)到集群中来解决.另外,通过使用RAC我们还可以选择使用服务管理(Service-Management)与负载均衡(Load Balance).简言之,RAC不仅仅是HA,在此详述其它原因已经超出本文的范畴了.从HA的视角看,使用RAC的缺陷是:数据库C以及相应的站点C是单点.如果站点C发生故障(比如火灾),数据库C将不可用.因此,将数据库伸展到两个站点就成为我们的选择了,这也是通常所说的扩展RAC.
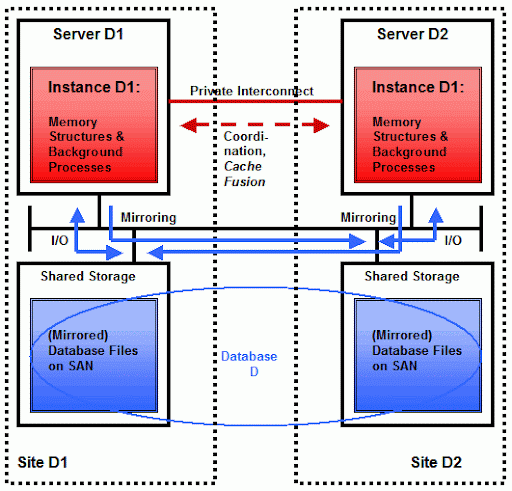
现在,这两个站点就不再是单点了.数据库D是在两个站点之间做镜像的.这个架构的缺陷是两个站点之间的网络连接的成本,如果两个站点之间的距离比较远的话.这很关键,因为需要镜像的数据量会非常大.实际上,这使得两个站点之间的距离局限于几公里以内,而这与想要实现的灾难保护目标之间有冲突.这时,Dataguard就隆重登场了:利用DataGuard,我们很容易就可以实现长距离的灾难保护,因为,此时我们不再需要传输所有的数据量,而仅仅需要传输(相对小)的重做日志.在下图中,每个服务器都像上面的服务器A与服务器B一样,只有一个实例:
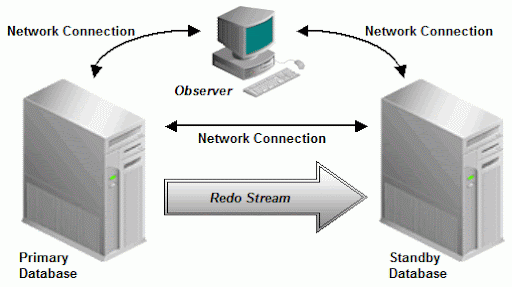
备用数据库由来自主数据库的重做日志. 当主库发生故障时,我们可以失败切换(Failover)到备库上并继续有效工作.这个失败切换工作可以由一个Observer(观察员程序,通常称为快速启动失败切换,Fast-Start Failover)自动实现.两个站点之间的距离达到几千公里(依赖于重做日志的传输策略与保护级别(protection level)).如果我们将RAC与Dataguard集合起来,我们就实现了MAA.显然,MAA是一个昂贵的解决方案,不过它也同时享有RAC与Dataguard的所有好处.
远程镜像是一个广受欢迎的第三方HA解决方案.总体上,它的架构与下图类似:
这时,也没有哪个站点是单点的,类似于使用扩展RAC架构.这个解决方案的缺陷是:站点间的距离也是严格受限制的,理由与扩展RAC架构类似.同时,在镜像进行的时候,第二个站点是无法提供服务的,这一点与上述的Oracle提供的HA解决方案不同.使用RAC时,所有的服务器与相应的站点都可以提供服务.哪怕是使用Dataguard,备用数据库也不仅仅是等待主库发生故障.除此之外,它还可以提供只读访问服务,这将可以有效降低主库的负载.
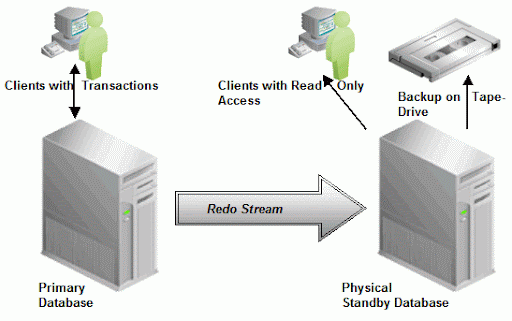
上图展示了Oracle 11g的新特性"物理备用数据库上的实时查询".在恢复过程中时,备用数据库也在同时提供只读访问.另外,还可以在物理备库(Physical Standby)上做离线备份(OffLoad Backup).
附注:
其实还有另外一种可选择的架构. 基于Data Guard与单实例的一个结合.
类似于上面介绍的远程Data Guard方案, 做了一点修正: 将当前主库的一组Redo 日志放到远程(当然也受限于距离所产生的San 访问延时).
软件架构概念大观
软件架构对于每一个人的理解都是不同的,通过分类可以在包容细节差异的小基础上明确共性,达到“概念总体上的清晰”。 将软件架构概念分派别: 1.组成派 软件系统的架构将系统描述为计算组件及组件之间的交互。 计算组件是泛指的,可以进一步细分为处理组件,数据组件,连接组件可以是子系统,框架,模块,类等不同粒度的软件单元 特征: (1.关注架构实践中的客体--软件,以软件本身为描述对象; (2.分析了软件的组成,即软件由承担不同计算任务的组件组成,这些组件通过相互交互完成更高层次的计算。 2.决策派 软件架构包含了关于一下问题的重要决策,对关键问题进行决策: ×软件系统的组织 ×选择组成系统的结构元素和他们之间的接口,以及当这些元素相互协作时所体现的行为; ×如何组成这些元素,使他们逐渐合成为更大的子系统 *用于指导这个系统组织的架构风格,这些元素以及他们的接口,协作和组合。 软件架构并不仅仅注重软件本身的结构和行为,还组中其他特性,使用,功能性,性能,弹性,重用,可理解性,经济和技术的限制的权衡。 特征: (1关注架构实践中的主体--人,一人为决策为描述的对象; (2归纳了架构决策的类型,指出架构决策不仅包括关于软件系统的组织,元素,子系统和架构风格等几类决策,还包括非功能性决策。 如前所述,将软件架构概念分类的好处是:包容细节差异、明确本质共性、促成概念总体上的清晰。下面我们再列举几个著名的软件架构定义,以期达到下列目的: (1)体会和证明众多软件架构概念都是围绕“组成”和“决策”两个视角展开的; (2)开阔视野,说不定和你合作的同事所接受的软件架构概念就是其中的一种。 具体而言,下面的定义1和定义2属于架构概念的“决策派”,而定义3、4、5、6、7属于架构概念的“组成派”。值得说明的是,定义7是来自SEI的Bass等人的相对比较新的定义,它将架构的多视图“本性”体现到了架构的定义当中,本书认为这种做法非常值得肯定。在第4章中,我们将专门讨论软件架构视图这一主题。 1.2.1 Booch、Rumbaugh和Jacobson的定义 架构是一系列重要决策的集合,这些决策与以下内容有关:软件的组织,构成系统的结构元素及其接口的选择,这些元素在相互协作中明确表现出的行为,这些结构元素和行为元素进一步组合所构成的更大规模的子系统,以及指导这一组织——包括这些元素及其接口、它们的协作和它们的组合——架构风格。 1.2.2 Woods的观点 Eoin Woods是这样认为的:软件架构是一系列设计决策,如果作了不正确的决策,你的项目可能最终会被取消(Software architecture is the set of design decisions which, if made incorrectly, may cause your project to be cancelled.)。 1.2.3 Garlan和Shaw的定义 Garlan和Shaw认为:架构包括组件(Component)、连接件(Connector)和约束(Constrain)三大要素。组件可以是一组代码(例如程序模块),也可以是独立的程序(例如数据库服务器)。连接件可以是过程调用、管道和消息等,用于表示组件之间的相互关系。“约束”一般为组件连接时的条件。 1.2.4 Perry和Wolf的定义 Perry和Wolf提出:软件架构是一组具有特定形式的架构元素,这些元素分为三类:负责完成数据加工的处理元素(Processing Elements)、作为被加工信息的数据元素(Data Elements)及用于把架构的不同部分组合在一起的连接元素(Connecting Elements)。 1.2.5 Boehm的定义 Barry Boehm和他的学生提出:软件架构包括系统组件、连接件和约束的集合,反应不同涉众需求的集合,以及原理(Rationale)的集合。其中的原理,用于说明由组件、连接件和约束所定义的系统在实现时,是如何满足不同涉众需求的。 1.2.6 IEEE的定义 IEEE 610.12-1990软件工程标准词汇中是这样定义架构的:架构是以组件、组件之间的关系、组件与环境之间的关系为内容的某一系统的基本组织结构,以及指导上述内容设计与演化的原理(Principle)。 1.2.7 Bass的定义 SEI(Software Engineering Institute, SEI,美国卡内基梅隆大学软件研究所)的Bass等人给架构的定义是:某个软件或计算机系统的软件架构是该系统的一个或多个结构,每个结构均由软件元素、这些元素的外部可见属性、这些元素之间的关系组成(The software architecture of a program or computing system is the structure or structures of the system, which comprise software elements, the externally visible properties of those elements, and the relationships among them.)。
java 线程超时中断实现
有一个需求,就是当一个方法执行超时的时候就中断该方法.
java的超时实现,在网上搜到的大部分是:
方法1.
中断线程最好的,最受推荐的方式是,使用共享变量(shared variable)发出信号,告诉线程必须停止正在运行的任务。线程必须周期性的核查这一变量(尤其在冗余操作期间),然后有秩序地中止任务。Listing B描述了这一方式。
Listing B
class Example2 extends Thread {
volatile boolean stop = false;
public static void main( String args[] ) throws Exception {
Example2 thread = new Example2();
System.out.println( "Starting thread..." );
thread.start();
Thread.sleep( 3000 );
System.out.println( "Asking thread to stop..." );
thread.stop = true;
Thread.sleep( 3000 );
System.out.println( "Stopping application..." );
//System.exit( 0 );
}
public void run() {
while ( !stop ) {
System.out.println( "Thread is running..." );
long time = System.currentTimeMillis();
while ( (System.currentTimeMillis()-time < 1000) && (!stop) ) {
}
}
System.out.println( "Thread exiting under request..." );
}
}
另外,httpclient中就提供了这样一个class- timeoutcontroller(位于org.Apache.commons.httpclient.util包内)查看该class的源代码可知其实现细节:
public static void execute(thread task, long timeout) throws timeoutexception {
task.start();
try {
task.join(timeout);
} catch (interruptedexception e) {
/* if somebody interrupts us he knows what he is doing */
}
if (task.isalive()) {
task.interrupt();
throw new timeoutexception();
}
}
其实就是通过join()和interrupt()方法实现这种功能,文档中强调了task的interrupt()方法必须重写(override)
方法2.
用join,就是在主线程里开一个子线程(t),在子线程里去处理超时任务,主线程t.join(3000),3000为要等待的时间(ms),如果子线程没有超时则正常继续执行,如果超时了则中断该子线程t.interrupt();
代码如下:
- public class ThreadTest {
- public static void main(String[] args) {
- CounterThread ct = new CounterThread(5000);
- System.out.println("start...");
- System.out.println("ct start...");
- ct.start();
- System.out.println("ct join...");
- try {
- ct.join(2000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println(ct.isAlive());
- ct.interrupt();
- System.out.println(ct.isAlive());
- System.out.println("the result is " + ct.getResult());
- }
- }
- class CounterThread extends Thread {
- private int time;
- public CounterThread(int time) {
- this.time = time;
- }
- private int result;
- public int getResult() {
- return result;
- }
- public void run() {
- try {
- Thread.sleep(time);
- System.out.println(Thread.currentThread().getName()
- + " is blocked for " + time + "ms");
- } catch (InterruptedException ex) {
- }
- result = 5;
- }
- }
这种方式是可以的,其实还有另外一种方式,就是
- public class TimeoutTest1 {
- public static void main(String[] args) {
- final ExecutorService service = Executors.newFixedThreadPool(1);
- TaskThread taskThread = new TaskThread();
- System.out.println("提交任务...begin");
- Future<Object> taskFuture = service.submit(taskThread);
- System.out.println("提交任务...end");
- try {
- System.out.println("get .... begin");
- Object re = taskFuture.get(1000, TimeUnit.MILLISECONDS);
- System.out.println(re);
- System.out.println("get .... end");
- } catch (InterruptedException e) {
- e.printStackTrace();
- } catch (ExecutionException e) {
- e.printStackTrace();
- } catch (TimeoutException e) {
- System.out.println("超时 取消任务");
- taskFuture.cancel(true);
- System.out.println("超时 取消任务OK");
- }finally{
- System.out.println("关闭服务");
- service.shutdown();
- System.out.println("关闭服务OK");
- }
- }
- }
- class TaskThread implements Callable<Object> {
- public Object call() throws Exception {
- String result = "空结果";
- try {
- System.out.println("任务开始....");
- Thread.sleep(5000);
- result = "正确结果";
- System.out.println("任务结束....");
- } catch (Exception e) {
- System.out.println("Task is interrupted!");
- }
- return result ;
- }
- }
换一种态度看程序员
有这样一群人,他们经常孤独地工作到深夜,漆黑夜里的显示器成为房间中唯一的光源,手边残留着比萨饼和碳酸饮料。繁重的编码任务让他们很少离开座位,即便是周五的深夜,这些人依旧在办公室中奋战。
乍一听,这像是在描述黑客们的工作状态。但实际上,大多数普通的开发人员就是这样生活着。除了工作,他们有家庭、兴趣以及责任,但项目的压力让他们无暇顾及工作以外的事情。工时长、假期短以及与当前社会发展脱节等问题普遍存在于他们当中。
虽然现在社会大力倡导所谓的知识经济,但这群聪明且高度专业化的人员不被重视,因为经理们认为,程序员是替代性很强的群体。这样的观念导致这些潜在的社会精英不得不重新考虑他们的职业规划。最终,他们当中的大多数另谋高就,另一些则踏入到全新的行业之中。
你认为游戏行业真的是一片乐土吗?一名业内人士讲,游戏开发几乎会占据程序员生活的全部,因为产品质量总会有改进的余地。他们工作时间长,没有加班费以及应有的假期。有些员工甚至连续四年薪水都没有调整过。他身边不少同事都是因为工作而导致了离婚。
当工作条件变得无法忍受时,最聪明以及最有天分的员工通常是最先离开的。凭借他们的资质,他们可以在其他领域挖掘到更多的机会。这样势必导致开发团队整体水平的下降。经理对开发者施加的压力越大,长期来看团队的效率就越低。IT顾问布鲁斯·韦伯斯特将这种情况称为“死海效应”。如果公司发展每况愈下,它就更难得到真正的人才,也更难留住这些人,这样的恶性循环无疑会拖垮公司。离岸外包的出现则加剧了这种趋势:内部开发团队的效率越低,公司就越希望通过低成本外包取代这个团队。而内部开发者会强烈地感到他们即将被替代,因此无法集中精力工作。
员工的倦怠会毁掉公司的未来,而经理们是可以降低死海效应的。他们可以设定合理的工作时长并且提供加班费,可以规定公休日并严格地执行,可以设置合理的产品发布时间以减少过度的压力。他们甚至可以尝试调整项目的开发方法,比如采用敏捷开发等。但是,最重要的一点就是,他们必须重新审视开发人员的价值。在这样一个与互联网发展速度同步的领域,每一个员工都应该被公平、公正地对待,并且获得应有的尊重,即使他们真地喜欢比萨饼和碳酸饮料。
《中国计算机报》
19个心得 明明白白说Linux下的负载均衡
二、F5是通过硬件的方式来实现负载均衡,它较多应用于CDN系统,用于squid反向加速集群的负载均衡,是专业的硬件负载均衡设备,尤其适用于每秒新建连接数和并发连接数要求高的场景;LVS和Nginx是通过软件的方式来实现的,但稳定性也相当强悍,在处理高并发的情况也有相当不俗的表现。
三、Nginx对网络的依赖较小,理论上只要ping得通,网页访问正常,nginx就能连得通,nginx同时还能区分内外网,如果是同时拥有内外网的节点,就相当于单机拥有了备份线路;lvs就比较依赖于网络环境,目前来看服务器在同一网段内并且lvs使用direct方式分流,效果较能得到保证。
四、目前较成熟的负载均衡高可用技术有LVS+Keepalived、Nginx+Keepalived,以前Nginx没有成熟的双机备份方案,但通过shell脚本监控是可以实现的,有兴趣的可具体参考我在51cto上的项目实施方案;另外,如果考虑Nginx的负载均衡高可用,也可以通过DNS轮询的方式来实现,有兴趣的可以参考张宴的相关文章。
五、集群是指负载均衡后面的web集群或tomcat集群等,但现在的集群意义泛指了整个系统架构,它包括了负载均衡器以及后端的应用服务器集群等,现在许多人都喜欢把Linux集群指为LVS,但我觉得严格意义上应该区分开。
六、负载均衡高可用中的高可用指的是实现负载均衡器的HA,即一台负载均衡器坏掉后另一台可以在<1s秒内切换,最常用的软件就是Keepalived和Heatbeat,成熟的生产环境下的负载均衡器方案有Lvs+Keepalived、Nginx+Keepalived。
七、LVS的优势非常多:①抗负载能力强;②工作稳定(因为有成熟的HA方案);③无流量;④基本上能支持所有的应用,基于以上的优点,LVS拥有不少的粉丝;但世事无绝对,LVS对网络的依赖性太大了,在网络环境相对复杂的应用场景中,我不得不放弃它而选用Nginx。
八、Nginx对网络的依赖性小,而且它的正则强大而灵活,强悍的特点吸引了不少人,而且配置也是相当的方便和简约,小中型项目实施中我基本是考虑它的;当然,如果资金充足,F5是不二的选择。
九、大型网站架构中其实可以结合使用F5、LVS或Nginx,选择它们中的二种或三种全部选择;如果因为预算的原因不选择F5,那么网站最前端的指向应该是LVS,也就是DNS的指向应为lvs均衡器,lvs的优点令它非常适合做这个任务。重要的ip地址,最好交由lvs托管,比如数据库的ip、webservice服务器的ip等等,这些ip地址随着时间推移,使用面会越来越大,如果更换ip则故障会接踵而至。所以将这些重要ip交给lvs托管是最为稳妥的。
十、VIP地址是Keepalived虚拟的一个IP,它是一个对外的公开IP,也是DNS指向的IP;所以在设计网站架构时,你必须向你的IDC多申请一个对外IP
十一、在实际项目实施过程中发现,Lvs和Nginx对https的支持都非常好,尤其是LVS,相对而言处理起来更为简便。
十二、在LVS+Keepalived及Nginx+Keepalived的故障处理中,这二者都是很方便的;如果发生了系统故障或服务器相关故障,即可将DNS指向由它们后端的某台真实web,达到短期处理故障的效果,毕竟广告网站和电子商务网站的PV就是金钱,这也是为什么要将负载均衡高可用设计于此的原因;大型的广告网站我就建议直接上CDN系统了。
十三、现在Linux集群都被大家神话了,其实这个也没多少复杂;关键看你的应用场景,哪种适用就选用哪种,Nginx和LVS、F5都不是神话,哪种方便哪种适用就选用哪种。
十四、另外关于session共享的问题,这也是一个老生长谈的问题了;Nginx可以用ip_hash机制来解决session的问题,而F5和LVS都有会话保持机制来解决这个问题,此外,还可以将session写进数据库,这也是一个解决session共享的好办法,当然这个也会加重数据库的负担,这个看系统架构师的取舍了。
十五、我现在目前维护的电子商务网站并发大约是1000左右,以前的证券资讯类网站是100左右,大型网上广告大约是3000,我感觉web层的并发越来越不是一个问题;现在由于服务器的强悍,再加上Nginx作web的高抗并发性,web层的并发并不是什么大问题;相反而言,文件服务器层和数据库层的压力是越来越大了,单NFS不可能胜任目前的工作,现在好的方案是moosefs和DRDB+Heartbeat+NFS;而我喜欢的Mysql服务器,成熟的应用方案还是主从,如果压力过大,我不得不选择oracle的RAC双机方案。
十六、现在受张宴的影响,大家都去玩Nginx了(尤其是作web),其实在服务器性能优异,内存足够的情况下,Apache的抗并发能力并不弱,整个网站的瓶颈应该还是在数据库方面;我建议可以双方面了解Apache和Nginx,前端用Nginx作负载均衡,后端用Apache作web,效果也是相当的好。
十七、Heartbeat的脑裂问题没有想象中那么严重,在线上环境可以考虑使用;DRDB+Heartbeat算是成熟的应用了,建议掌握。我在相当多的场合用此组合来替代EMC共享存储,毕竟30万的价格并不是每个客户都愿意接受的。
十八、无论设计的方案是多么的成熟,还是建议要配置Nagios监控机来实时监控我们的服务器情况;邮件和短信报警都可以开启,毕竟手机可以随身携带嘛;有条件的还可以购买专门的商业扫描网站服务,它会每隔一分钟扫描你的网站,如果发现没有alive会向你的邮件发警告信息或直接电话联系。
十九、至少网站的安全性问题,我建议用硬件防火墙,比较推荐的是华赛三层防火墙+天泰web防火墙,DDOS的安全防护一定要到位;Linux服务器本身的iptables和SElinux均可关闭,当然,端口开放越少越好。
如何诊断和解决CPU高度消耗(100%)的数据库问题
很多时候我们的服务器可能会经历CPU消耗100%的性能问题.
排除系统的异常,这类问题通常都是因为系统中存在性能低下甚至存在错误的SQL语句, 消耗了大量的CPU所致.
本文通过一个案例就如何捕获这样的SQL给出一个通用的方法.
问题描述:系统CPU高度消耗,系统运行缓慢
OS:Sun Solaris8
Oracle:Oracle9203
1.首先通过Top命令查看
$ top
load averages: 1.61, 1.28, 1.25 HSWAPJSDB 10:50:44
172 processes: 160 sleeping, 1 running, 3 zombie, 6 stopped, 2 on cpu
CPU states: % idle, % user, % kernel, % iowait, % swap
Memory: 4.0G real, 1.4G free, 1.9G swap in use, 8.9G swap free
PID USERNAME THR PR NCE SIZE RES STATE TIME FLTS CPU COMMAND
20521 oracle 1 40 0 1.8G 1.7G run 6:37 0 47.77% oracle
20845 oracle 1 40 0 1.8G 1.7G cpu02 0:41 0 40.98% oracle
20847 oracle 1 58 0 1.8G 1.7G sleep 0:00 0 0.84% oracle
20780 oracle 1 48 0 1.8G 1.7G sleep 0:02 0 0.83% oracle
15828 oracle 1 58 0 1.8G 1.7G sleep 0:58 0 0.53% oracle
20867 root 1 58 0 4384K 2560K sleep 0:00 0 0.29% sshd2
20493 oracle 1 58 0 1.8G 1.7G sleep 0:03 0 0.29% oracle
20887 oracle 1 48 0 1.8G 1.7G sleep 0:00 0 0.13% oracle
20851 oracle 1 58 0 1.8G 1.7G sleep 0:00 0 0.10% oracle
20483 oracle 1 48 0 1.8G 1.7G sleep 0:00 0 0.09% oracle
20875 oracle 1 45 0 1064K 896K sleep 0:00 0 0.07% sh
20794 oracle 1 58 0 1.8G 1.7G sleep 0:00 0 0.06% oracle
20842 jiankong 1 52 2 1224K 896K sleep 0:00 0 0.05% sadc
20888 oracle 1 55 0 1712K 1272K cpu00 0:00 0 0.05% top
19954 oracle 1 58 0 1.8G 1.7G sleep 84:25 0 0.04% oracle
|
我们发现在进城列表里,存在两个高CPU耗用的Oracle进城,分别消耗了47.77%和40.98%的CPU资源.
2.找到存在问题的进程信息
|
$ ps -ef|grep 20521
oracle 20909 20875 0 10:50:53 pts/10 0:00 grep 20521
oracle 20521 1 47 10:43:59 ? 6:45 oraclejshs (LOCAL=NO)
$ ps -ef|grep 20845
oracle 20845 1 44 10:50:00 ? 0:55 oraclejshs (LOCAL=NO)
oracle 20918 20875 0 10:50:59 pts/10 0:00 grep 20845
|
确认这是两个远程连接的用户进程.
3.熟悉一下我的getsql.sql脚本
|
SELECT /*+ ORDERED */
sql_text
FROM v$sqltext a
WHERE (a.hash_value, a.address) IN (
SELECT DECODE (sql_hash_value,
0, prev_hash_value,
sql_hash_value
),
DECODE (sql_hash_value, 0, prev_sql_addr, sql_address)
FROM v$session b
WHERE b.paddr = (SELECT addr
FROM v$process c
WHERE c.spid = '&pid'))
ORDER BY piece ASC
/
|
注意这里我们涉及了3个视图,并应用其关联进行数据获取.
首先需要输入一个pid,这个pid即process id,也就是在Top或ps中我们看到的PID.
通过pid和v$process.spid相关联我们可以获得Process的相关信息
进而通过v$process.addr和v$session.paddr相关联,我们就可以获得和session相关的所有信息.
再结合v$sqltext,我们即可获得当前session正在执行的SQL语句.
通过v$process视图,我们得以把操作系统和数据库关联了起来.
4.连接数据库,找到问题sql及进程
通过Top中我们观察到的PID,进而应用我的getsql脚本,我们得到以下结果输出.
|
$ sqlplus "/ as sysdba"
SQL*Plus: Release 9.2.0.3.0 - Production on Mon Dec 29 10:52:14 2003
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.3.0 - 64bit Production
With the Partitioning, OLAP and Oracle Data Mining options
JServer Release 9.2.0.3.0 - Production
SQL> @getsql
Enter value for spid: 20521
old 10: where c.spid = '&pid'
new 10: where c.spid = '20521'
SQL_TEXT
----------------------------------------------------------------
select * from (select VC2URL,VC2PVDID,VC2MOBILE,VC2ENCRYPTFLAG,S
ERVICEID,VC2SUB_TYPE,CISORDER,NUMGUID,VC2KEY1, VC2NEEDDISORDER,V
C2PACKFLAG,datopertime from hsv_2cpsync where datopertime<=sysda
te and numguid>70000000000308 order by NUMGUid) where rownum<=20
|
那么这段代码就是当前正在疯狂消耗CPU的罪魁祸首.
接下来需要进行的工作就是找出这段代码的问题,看是否可以通过优化提高其效率,减少资源消耗.
5.进一步的我们可以通过dbms_system包跟踪该进程
|
SQL> @getsid SID SERIAL# USERNAME MACHINE SQL> exec dbms_system.set_sql_trace_in_session(45,38991,true); PL/SQL procedure successfully completed. SQL> !
|