[慢查优化]建索引时注意字段选择性 & 范围查询注意组合索引的字段顺序 - 旁观者 - 博客园
- 之前曾说过“不要求每个人一定理解 联表查询(join/left join/inner join等)时的mysql运算过程”,但对于字段选择性差意味着什么,组合索引字段顺序意味着什么,要求每个人必须了解;
- 重复上一次的话:把mysql客户端(如SQLyog,如HeidiSQL)放在桌面上,时不时拿出来 explain 一把,这是一种美德!
- 确保亲手查过SQL的执行计划,一定要注意看执行计划里的 possible_keys、key和rows这三个值,让影响行数尽量少,保证使用到正确的索引,减少不必要的Using temporary/Using filesort;
- 不要在选择性非常差的字段上建索引,原因参见优化策略A;
- 查询条件里出现范围查询(如A>7,A in (2,3))时,要警惕,不要建了组合索引却完全用不上,原因参见优化策略B;
我们先回顾一下字段选择性的基础知识。
——字段选择性的基础知识——
引子:什么字段都可以建索引吗?
如下表所示,sort 字段的选择性非常差,你可以执行 show index from ads 命令可以看到 sort 的 Cardinality(散列程度)只有 9,这种字段上本不应该建索引:
|
Table |
Non_unique |
Key_name |
Seq_in_index |
Column_name |
Collation |
Cardinality |
Sub_part |
Packed |
Null |
Index_type |
Comment |
|
ads |
1 |
sort |
1 |
sort |
A |
9 |
\N |
\N |
|
BTREE |
|
- 选择性较低索引 可能带来的性能问题
- 索引选择性=索引列唯一值/表记录数;
- 选择性越高索引检索价值越高,消耗系统资源越少;选择性越低索引检索价值越低,消耗系统资源越多;
- 查询条件含有多个字段时,不要在选择性很低字段上创建索引
- 可通过创建组合索引来增强低字段选择性和避免选择性很低字段创建索引带来副作用;
- 尽量减少possible_keys,正确索引会提高sql查询速度,过多索引会增加优化器选择索引的代价,不要滥用索引;
——组合索引字段顺序与范围查询之间的关系——
引子:范围查询 city_id in (0,8,10) 能用组合索引 (ads_id,city_id) 吗?
举例,
ac 表有一个组合索引(ads_id,city_id)。
那么如下 ac.city_id IN (0, 8005) 查询条件能用到 ac表的组合索引(ads_id,city_id) 吗?
EXPLAIN
SELECT ac.ads_id
FROM ads, ac
WHERE
ads.id = ac.ads_id
AND ac.city_id IN (0, 8005)
AND ads.status = 'online'
AND ac.start_time<UNIX_TIMESTAMP()
AND ac.end_time>UNIX_TIMESTAMP()
优化策略B:
由于 mysql 索引是基于 B-Tree 的,所以组合索引有“字段顺序”概念。
所以,查询条件中有 ac.city_id IN (0, 8005),而组合索引是 (ads_id,city_id),则该查询无法使用到这个组合索引。
DBA总结道:
- 下面条件可以用上该组合索引查询:
- A>5
- A=5 AND B>6
- A=5 AND B=6 AND C=7
- A=5 AND B IN (2,3) AND C>5
- 下面条件将不能用上组合索引查询:
- B>5 ——查询条件不包含组合索引首列字段
- B=6 AND C=7 ——查询条件不包含组合索引首列字段
- 下面条件将能用上部分组合索引查询:
- A>5 AND B=2 ——当范围查询使用第一列,查询条件仅仅能使用第一列
- A=5 AND B>6 AND C=2 ——范围查询使用第二列,查询条件仅仅能使用前二列
- 下面条件可以用上组合索引排序:
- ORDER BY A——首列排序
- A=5 ORDER BY B——第一列过滤后第二列排序
- ORDER BY A DESC, B DESC——注意,此时两列以相同顺序排序
- A>5 ORDER BY A——数据检索和排序都在第一列
- 下面条件不能用上组合索引排序:
- ORDER BY B ——排序在索引的第二列
- A>5 ORDER BY B ——范围查询在第一列,排序在第二列
- A IN(1,2) ORDER BY B ——理由同上
- ORDER BY A ASC, B DESC ——注意,此时两列以不同顺序排序
- MySQL 5,0以下版本,SQL查询时,一张表只能用一个索引(use at most only one index for each referenced table),
- 从 MySQL 5.0开始,引入了 index merge 概念,包括 Index Merge Union Access Algorithm(多个索引并集访问),包括Index Merge Intersection Access Algorithm(多个索引交集访问),可以在一个SQL查询里用到一张表里的多个索引。
- MySQL 在5.6.7之前,使用 index merge 有一个重要的前提条件:没有 range 可以使用。[出自参考资源2]
- MySQL 索引合并能使用多个索引
- SELECT * FROM TB WHERE A=5 AND B=6
- 能分别使用索引(A) 和 (B) 或 索引合并;
- 创建组合索引(A,B) 更好;
- SELECT * FROM TB WHERE A=5 OR B=6
- 能分别使用索引(A) 和 (B) 或 索引合并;
- 组合索引(A,B)不能用于此查询,分别创建索引(A) 和 (B)会更好;
- SELECT * FROM TB WHERE A=5 AND B=6
记住,explain 后再提测是一种美德!
浅谈 SpringMVC 数据绑定 - Senton - 博客频道 - CSDN.NET
2. 包装类型(以Integer为例,其他类似):
Controller代码:
- @RequestMapping("test.do")
- public void test(Integer num) {
- }
JSP表单代码:
- <form action="test.do" method="post">
- <input name="num" value="10" type="text"/>
- ......
- </form>
和基本数据类型基本一样,不同之处在于,JSP表单传递过来的数据可以为null或"",以上面代码为例,如果jsp中num为""或者表单中无num这个input,那么,Controller方法参数中的num值则为null。
3. 自定义对象类型:
Model代码:
- public class User {
- private String firstName;
- private String lastName;
- public String getFirstName() {
- return firstName;
- }
- public void setFirstName(String firstName) {
- this.firstName = firstName;
- }
- public String getLastName() {
- return lastName;
- }
- public void setLastName(String lastName) {
- this.lastName = lastName;
- }
- }
Controller代码:
- @RequestMapping("test.do")
- public void test(User user) {
- }
JSP表单代码:
- <form action="test.do" method="post">
- <input name="firstName" value="张" type="text"/>
- <input name="lastName" value="三" type="text"/>
- ......
- </form>
非常简单,只需将对象的属性名和input的name值一一对应即可。
如何进行项目管理才具有执行力 - 心情驿站 - 51CTO技术博客
解惑 spring 嵌套事务 - Spring - Java - ITeye论坛
PROPAGATION_REQUIRED -- 支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
PROPAGATION_SUPPORTS -- 支持当前事务,如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY -- 支持当前事务,如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW -- 新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED -- 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER -- 以非事务方式执行,如果当前存在事务,则抛出异常。
PROPAGATION_NESTED -- 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作。
前六个策略类似于EJB CMT,第七个(PROPAGATION_NESTED)是Spring所提供的一个特殊变量。
它要求事务管理器或者使用JDBC 3.0 Savepoint API提供嵌套事务行为(如Spring的DataSourceTransactionManager)
PROPAGATION_REQUIRES_NEW 启动一个新的, 不依赖于环境的 "内部" 事务. 这个事务将被完全 commited 或 rolled back 而不依赖于外部事务, 它拥有自己的隔离范围, 自己的锁, 等等. 当内部事务开始执行时, 外部事务将被挂起, 内务事务结束时, 外部事务将继续执行.
另一方面, PROPAGATION_NESTED 开始一个 "嵌套的" 事务, 它是已经存在事务的一个真正的子事务. 潜套事务开始执行时, 它将取得一个 savepoint. 如果这个嵌套事务失败, 我们将回滚到此 savepoint. 潜套事务是外部事务的一部分, 只有外部事务结束后它才会被提交.
由此可见, PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的最大区别在于, PROPAGATION_REQUIRES_NEW 完全是一个新的事务, 而 PROPAGATION_NESTED 则是外部事务的子事务, 如果外部事务 commit, 潜套事务也会被 commit, 这个规则同样适用于 roll back.
那么外部事务如何利用嵌套事务的 savepoint 特性呢, 我们用代码来说话
- ServiceA {
- /**
- * 事务属性配置为 PROPAGATION_REQUIRED
- */
- void methodA() {
- ServiceB.methodB();
- }
- }
- ServiceB {
- /**
- * 事务属性配置为 PROPAGATION_REQUIRES_NEW
- */
- void methodB() {
- }
- }
这种情况下, 因为 ServiceB#methodB 的事务属性为 PROPAGATION_REQUIRES_NEW, 所以两者不会发生任何关系, ServiceA#methodA 和 ServiceB#methodB 不会因为对方的执行情况而影响事务的结果, 因为它们根本就是两个事务, 在 ServiceB#methodB 执行时 ServiceA#methodA 的事务已经挂起了 (关于事务挂起的内容已经超出了本文的讨论范围, 有时间我会再写一些挂起的文章) .
那么 PROPAGATION_NESTED 又是怎么回事呢? 继续看代码
- ServiceA {
- /**
- * 事务属性配置为 PROPAGATION_REQUIRED
- */
- void methodA() {
- ServiceB.methodB();
- }
- }
- ServiceB {
- /**
- * 事务属性配置为 PROPAGATION_NESTED
- */
- void methodB() {
- }
- }
现在的情况就变得比较复杂了, ServiceB#methodB 的事务属性被配置为 PROPAGATION_NESTED, 此时两者之间又将如何协作呢? 从 Juergen Hoeller 的原话中我们可以找到答案, ServiceB#methodB 如果 rollback, 那么内部事务(即 ServiceB#methodB) 将回滚到它执行前的 SavePoint(注意, 这是本文中第一次提到它, 潜套事务中最核心的概念), 而外部事务(即 ServiceA#methodA) 可以有以下两种处理方式:
1. 改写 ServiceA 如下
- ServiceA {
- /**
- * 事务属性配置为 PROPAGATION_REQUIRED
- */
- void methodA() {
- try {
- ServiceB.methodB();
- } catch (SomeException) {
- // 执行其他业务, 如 ServiceC.methodC();
- }
- }
- }
这种方式也是潜套事务最有价值的地方, 它起到了分支执行的效果, 如果 ServiceB.methodB 失败, 那么执行 ServiceC.methodC(), 而 ServiceB.methodB 已经回滚到它执行之前的 SavePoint, 所以不会产生脏数据(相当于此方法从未执行过), 这种特性可以用在某些特殊的业务中, 而 PROPAGATION_REQUIRED 和 PROPAGATION_REQUIRES_NEW 都没有办法做到这一点. (题外话 : 看到这种代码, 似乎似曾相识, 想起了 prototype.js 中的 Try 函数 )
2. 代码不做任何修改, 那么如果内部事务(即 ServiceB#methodB) rollback, 那么首先 ServiceB.methodB 回滚到它执行之前的 SavePoint(在任何情况下都会如此),
外部事务(即 ServiceA#methodA) 将根据具体的配置决定自己是 commit 还是 rollback (+MyCheckedException).
ORACLE 索引失效_jzj5202003_新浪博客
以下情况会导致索引失效:
1) 直接导入:
imp with SKIP_UNUSABLE_INDEXES=Y
or sqlldr with SKIP_INDEX_MAINTENANCE
2) 在索引维护过程中出现ORA-1652/1653错误:
sqlldr DIRECT=Y failes with ORA-1652 or 1653
3) 分区维护导致ROWID发生改变:
ALTER TABLE MOVE PARTITION
ALTER TABLE TRUNCATE PARTITION
ALTER TABLE SPLIT PARTITION
****************************************************
索引失效问题解决方法:
1)导致的原因:
2)解决方法:
3)如何重建索引
select
索引名称
GNOS_PROD_BALANCE_AA_N1
b)非分区索引
重建索引:alter index
c)分区索引
select t.Index_Name, t.Partition_Name, t.Tablespace_Name, t.Status
重建所有状态为unusable的索引
ALTER INDEX 索引名
JVM 内存模型/内存溢出测试深入笔记
JVM 深入笔记(1)内存区域是如何划分的?
一个超短的前言
JVM 是一个从事 Java 开发的软件工程师的修炼之路上必然要翻阅的一座山。当你了解了 Java 的基本语言特性,当你熟悉了 Java SDK 中的常用 API,当你写过一些或大或小的程序后,你就会有去了解 JVM 的需求出现。如果你现在没有这种感觉,那么可能此时去了解 JVM 并不是一个好的时机,因为你不会带着问题去探索。
从本篇开始的系列博文,记录本人的 JVM 深入学习总结,其中结合了本人自己的一些经验,也参考了一些书籍和网络资源,然后根据自己的理解写出这些博文。如有版权问题,请伊妹儿我 :)
谨以此系列博文分享给我的朋友们。
1 JVM 简史
屏蔽不同的硬件平台或操作系统上的环境差异,通过一个向上层提供统一编程接口来实现Java程序可移植性的软件层,我们称之为 Java 虚拟机(Java Virtual Machine,简称 JVM)。
虽然 Java 的发展史可以追溯到 1991年4月由著名的 James Gosling 领导的 Green Project 计划,但是 JDK 1.0 版本的正式发布是在 1996年的1月23日,该版本提供的 JVM 是一个纯解释执行的 Sun Classic VM,不过是以外部加载的方式来使用的。而该版本的 JDK 所包含的主要技术除了 JVM 之外,就是 Applet 和 AWT。当然,此前在 Java 还叫做 Oak 的时候就已经有了一个完整的编程语言的外形,而 1995年5月23日,Oak 正式更名为 Java,并由 Sun 公司发布了 Java 1.0 版本。
关于 Java 语言的背景,这里就不多说了,主要还是介绍 JVM 的发展历程。到 1998年发展出了 JDK 1.2,在该版本中 JVM 内置了 JIT (Just In Time) 编译器,而 JDK 1.2 中也曾有过 Sun Classic VM、Hot Spot VM 和 Sun Exact VM 三种虚拟机。其中 Hot Spot VM 和 Extract VM 都内置 JIT 编译器。1997年,Sun 收购了开发 Hot Spot VM 的名为 Longview Technologies 的公司。也从此该虚拟机改叫 Sun Hot Spot VM,当然那么一个前缀对于 Developers 来说是没所谓的。从 JDK 1.3 开始,Sun Hot Spot VM 成为 Sun 公司发布的 JDK 的默认 JVM。
目前活跃的商用 JVM 有 Sun Hot Spot、BEA JRockit 和 IBM J9。不过要说的是,JRockit 的主人 BEA 被 Oracle 收购了,而 Hot Spot 的主人被 Sun 公司在 2010 年也被 Oracle 收购了。因此 Hot Spot 和 JRockit 都隶属于 Oracle 公司。Oracle 曾称将会将这个两个 JVM 的优势相融合,产生一款新的 JVM,届时 Hot Spot 和 JRockit 也将进入历史博物馆了。JVM 的鼻祖 Sun Classic VM 早已被淘汰使用了,而 曾在 JDK 1.2 中灵光乍现过的 Sun Extract VM 也已经退出了历史舞台。另一个由 Apache 基金会主导的 Harmony 项目也有很大的影响,且间接由其催生的 Dalvik 虚拟机,为 Google Android 的火爆发展做出了巨大的贡献。在应用于手机、平板电脑、IVI、PDA 等设备上的嵌入式 JVM 领域,除了 Dalvik,还有 KVM、CDC Hot Spot、CLDC Hot Spot 等 JVM 也较有影响力。
从本文开始的系列博文《JVM 原理与实战》中所有实验性程序的环境,都是 Mac OS X 10.7.3,JDK 1.6.0 Update 29,Oracle Hot Spot 20.4-b02。
2 初识 JVM 内存区域划分
大多数 JVM 将内存区域划分为 Method Area(Non-Heap), Heap, Program Counter Register, Java Method Stack,Native Method Stack 和 Direct Memomry(注意 Directory Memory 并不属于 JVM 管理的内存区域)。前三者一般译为:方法区、堆、程序计数器。但不同的资料和书籍上对于后三者的中文译名不尽相同,这里将它们分别译作:Java 方法栈、原生方法栈和直接内存区。对于不同的 JVM,内存区域划分可能会有所差异,比如 Hot Spot 就将 Java 方法栈和原生方法栈合二为一,我们可以同城为方法栈(Method Stack)。
首先我们熟悉一下一个一般性的 Java 程序的工作过程。一个 Java 源程序文件,会被编译为字节码文件(以 class 为扩展名),然后告知 JVM 程序的运行入口,再被 JVM 通过字节码解释器加载运行。那么程序开始运行后,都是如何涉及到各内存区域的呢?
概括地说来,JVM 每遇到一个线程,就为其分配一个程序计数器、Java 方法栈和原生方法栈。当线程终止时,两者所占用的内存空间也会被释放掉。栈中存储的是栈帧,可以说每个栈帧对应一个“运行现场”。在每个“运行现场”中,如果出现了一个局部对象,则它的实例数据被保存在堆中,而类数据被保存在方法区。
我们用上面这一小段文字就描述完了每个内存区域的基本功能。但是这还比较粗糙,下面分别介绍它们的存储对象、生存期与空间管理策略。
2.1 程序计数器
- 线程特性:私有
- 存储内容:字节码文件指令地址(Java Methods),或 Undefined(Native Methods)
- 生命周期:随线程而生死
- 空间策略:占用内存很小
这个最简单,就先捡它说吧。程序计数器,是线程私有(与线程共享相对)的,也就是说有 N 个线程,JVM 就会分配 N 个程序计数器。如果当前线程在执行一个 Java 方法,则程序计数器记录着该线程所执行的字节码文件中的指令地址。如果线程执行的是一个 Native 方法,则计数器值为 Undefined。
程序计数器的生存期多长呢?显然程序计数器是伴随线程生而生,伴随线程死而死的。而它所占用的内存空间也很小。
2.2 Java 方法栈与原生方法栈
Java 方法栈也是线程私有的,每个 Java 方法栈都是由一个个栈帧组成的,每个栈帧是一个方法运行期的基础数据结构,它存储着局部变量表、操作数栈、动态链接、方法出口等信息。当线程调用调用了一个 Java 方法时,一个栈帧就被压入(push)到相应的 Java 方法栈。当线程从一个 Java 方法返回时,相应的 Java 方法栈就弹出(pop)一个栈帧。
其中要详细介绍的是局部变量表,它保存者各种基本数据类型和对象引用(Object reference)。基本数据类型包括 boolean、byte、char、short、int、long、float、double。对象引用,本质就是一个地址(也可以说是一个“指针”),该地址是堆中的一个地址,通过这个地址可以找到相应的 Object(注意是“找到”,原因会在下面解释)。而这个地址找到相应 Object 的方式有两种。一种是该地址存储着 Pointer to Object Instance Data 和 Pointer to Object Class Data,另一种是该地址存储着 Object Instance Data,其中又包含有 Pointer to Object Class Data。如下两图所示。
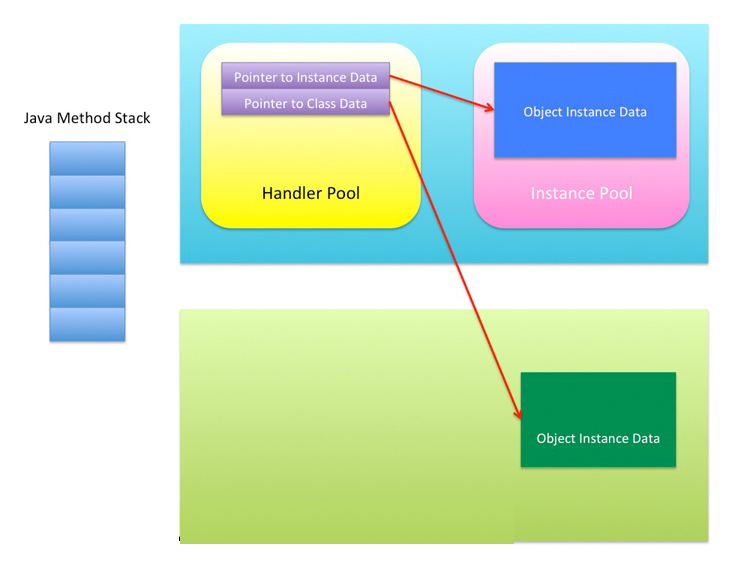
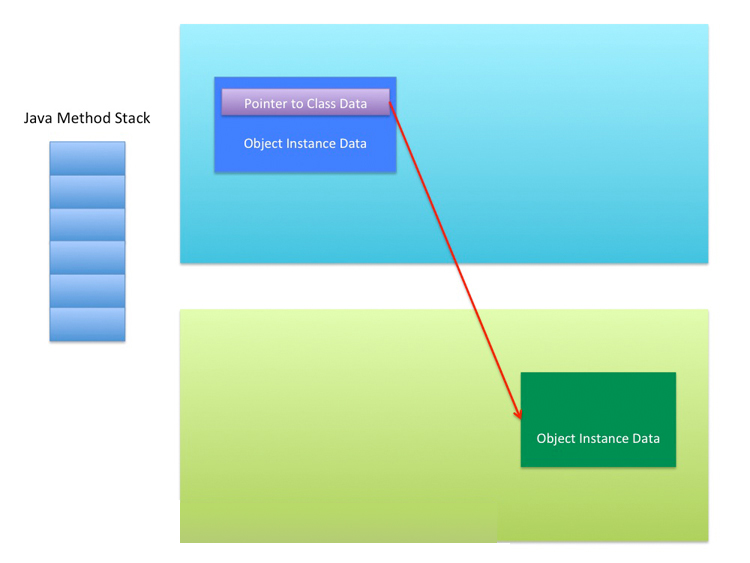
第一种方式,Java 方法栈中有 Handler Pool 和 Instance Pool。无论哪种方式,Object Class Data 都是存储在方法区的,Object Instance Data 都是存储在堆中的。
原生方法栈与 Java 方法栈相类似,这里不再赘述。
2.3 堆
堆是在启动虚拟机的时候划分出来的区域,其大小由参数或默认参数指定。当虚拟机终止运行时,会释放堆内存。一个 JVM 只有一个堆,它自然是线程共享的。堆中存储的是所有的 Object Instant Data 以及数组(不过随着栈上分配技术、标量替换技术等优化手段的发展,对象也不一定都存储在堆上了),这些 Instance 由垃圾管理器(Garbage Collector)管理,具体的算法会在后面提到。
堆可以是由不连续的物理内存空间组成的,并且既可以固定大小,也可以设置为可扩展的(Scalable)。
2.4 方法区
通过(2)中 Java 方法栈的介绍,你已经知道了 Object Class Data 是存储在方法区的。除此之外,常量、静态变量、JIT 编译后的代码也都在方法区。正因为方法区所存储的数据与堆有一种类比关系,所以它还被称为 Non-Heap。方法区也可以是内存不连续的区域组成的,并且可设置为固定大小,也可以设置为可扩展的,这点与堆一样。
方法区内部有一个非常重要的区域,叫做运行时常量池(Runtime Constant Pool,简称 RCP)。在字节码文件中有常量池(Constant Pool Table),用于存储编译器产生的字面量和符号引用。每个字节码文件中的常量池在类被加载后,都会存储到方法区中。值得注意的是,运行时产生的新常量也可以被放入常量池中,比如 String 类中的 intern() 方法产生的常量。
2.5 直接内存区
直接内存区并不是 JVM 管理的内存区域的一部分,而是其之外的。该区域也会在 Java 开发中使用到,并且存在导致内存溢出的隐患。如果你对 NIO 有所了解,可能会知道 NIO 是可以使用 Native Methods 来使用直接内存区的。
JVM 深入笔记(2)各内存区溢出场景模拟
《JVM 深入笔记(1)内存区域是如何划分的?》一文已经介绍了 JVM 对内存区域的划分与管理。在现实的编程过程中,会遇到一些 OutOfMemoryError (OOM) 的情形。通过模拟,我们可以直接点中这些场景的本质,从而在纷繁复杂的千万行代码中避免这样去 coding。导致 OOM 的情况有多种,包括 Java 或 Native Method Stack 的内存不足或者栈空间溢出、Heap 内存溢出、Non-heap 内存溢出、Direct Memory 溢出。
1. Java Method Stack 栈溢出实验
什么时候会让 Java Method Stack 栈溢出啊?栈的基本特点就是 FILO(First In Last Out),如果 in 的太多而 out 的太少,就好 overflow 了。而 Java Method Stack 的功能就是保存每一次函数调用时的“现场”,即为入栈,函数返回就对应着出栈,所以函数调用的深度越大,栈就变得越大,足够大的时候就会溢出。所以模拟 Java Method Stack 溢出,只要不断递归调用某一函数就可以。
程序源码-1
// Author: Poechant
// Blog: blog.csdn.net/poechant
// Email: zhognchao.ustc#gmail.com (#->@)
// Args: -verbose:gc -Xss128K
package com.sinosuperman.main;
public class Test {
private int stackLength = 0;
public void stackOverflow() {
++stackLength;
stackOverflow();
}
public static void main(String[] args) throws Throwable {
Test test = new Test();
try {
test.stackOverflow();
} catch (Throwable e) {
System.out.println("stack length: " + test.stackLength);
throw e;
}
}
}
运行结果
stack length: 1052
Exception in thread "main" java.lang.StackOverflowError
at com.sinosuperman.main.Test.stackOverflow(Test.java:8)
at com.sinosuperman.main.Test.stackOverflow(Test.java:9)
at com.sinosuperman.main.Test.stackOverflow(Test.java:9)
at com.sinosuperman.main.Test.stackOverflow(Test.java:9)
at com.sinosuperman.main.Test.stackOverflow(Test.java:9)
...
2. Java Method Stack 内存溢出实验
Heap 内存溢出
堆是用来存储对象的,当然对象不一定都存在堆里(由于逃逸技术的发展)。那么堆如果溢出了,一定是不能被杀掉的对象太多了。模拟 Heap 内存溢出,只要不断创建对象并保持有引用存在即可。
程序源码-2
// Author: Poechant
// Blog: blog.csdn.net/poechant
// Email: zhongchao.ustc#gmail.com (#->@)
// Args: -verbose:gc -Xmx50m -Xms50m
package com.sinosuperman.main;
import java.util.ArrayList;
import java.util.List;
public class Test {
private static class HeapOomObject {
}
public static void main(String[] args) {
List<HeapOomObject> list = new ArrayList<HeapOomObject>();
while (true) {
list.add(new HeapOomObject());
}
}
}
运行结果
[GC 17024K->14184K(49088K), 0.1645899 secs]
[GC 26215K->29421K(49088K), 0.0795283 secs]
[GC 35311K(49088K), 0.0095602 secs]
[Full GC 43400K->37709K(49088K), 0.1636702 secs]
[Full GC 49088K->45160K(49088K), 0.1609499 secs]
[GC 45312K(49088K), 0.0265257 secs]
[Full GC 49088K->49087K(49088K), 0.1656715 secs]
[Full GC 49087K->49087K(49088K), 0.1656147 secs]
[Full GC 49087K->49062K(49088K), 0.1976727 secs]
[GC 49063K(49088K), 0.0287960 secs]
[Full GC 49087K->49087K(49088K), 0.1901410 secs]
[Full GC 49087K->49087K(49088K), 0.1673056 secs]
[Full GC 49087K->316K(49088K), 0.0426515 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.sinosuperman.main.Test.main(Test.java:14)
3. Method Area 内存溢出
也就是 Non-heap,是用来存储 Object Class Data、常量、静态变量、JIT 编译后的代码等。如果该区域溢出,则说明某种数据创建的实在是太多了。模拟的话,可以不断创建新的 class,直到溢出为止。
以下代码使用到 cglib-2.2.2.jar 和 asm-all-3.0.jar。
程序源码-3
package com.sinosuperman.main;
import java.lang.reflect.Method;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
public class Test {
static class MethodAreaOomObject {
}
public static void main(String[] args) {
while(true){
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(MethodAreaOomObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
public Object intercept(Object obj, Method method, Object[] args,
MethodProxy proxy) throws Throwable {
return proxy.invoke(obj, args);
}
});
enhancer.create();
}
}
}
运行结果
Exception in thread "main" net.sf.cglib.core.CodeGenerationException: java.lang.reflect.InvocationTargetException-->null
at net.sf.cglib.core.AbstractClassGenerator.create(AbstractClassGenerator.java:237)
at net.sf.cglib.proxy.Enhancer.createHelper(Enhancer.java:377)
at net.sf.cglib.proxy.Enhancer.create(Enhancer.java:285)
at com.sinosuperman.main.Test.main(Test.java:24)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.GeneratedMethodAccessor1.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at net.sf.cglib.core.ReflectUtils.defineClass(ReflectUtils.java:384)
at net.sf.cglib.core.AbstractClassGenerator.create(AbstractClassGenerator.java:219)
... 3 more
Caused by: java.lang.OutOfMemoryError: PermGen space
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClassCond(ClassLoader.java:631)
at java.lang.ClassLoader.defineClass(ClassLoader.java:615)
... 8 more
4. Runtime Constant Pool in Method Area 内存溢出
在运行时产生大量常量就可以实现让 Method Area 溢出的目的。运行是常量可以用 String 类的 intern 方法,不断地产生新的常量。
程序源码-4
package com.sinosuperman.main;
import java.util.ArrayList;
import java.util.List;
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
int i = 0;
while (true) {
list.add(String.valueOf(i++).intern());
}
}
}
运行结果
Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
at java.lang.String.intern(Native Method)
at com.sinosuperman.main.Test.main(Test.java:12)
结语
在实际编码中要尽量避免此类错误。不过大多数程序设计的结构比这里的示例要复杂的多,使得问题被隐藏。但 JVM 的内存溢出问题本质上大都可归结为以上这几种情况。
JVM深入笔记(3)垃圾标记算法
如果您还不了解 JVM 的基本概念和内存划分,请先阅读《JVM 深入笔记(1)内存区域是如何划分的?》一文。然后再回来 :)
因为 Java 中没有留给开发者直接与内存打交道的指针(C++工程师很熟悉),所以如何回收不再使用的对象的问题,就丢给了 JVM。所以下面就介绍一下目前主流的垃圾收集器所采用的算法。不过在此之前,有必要先讲一下 Reference。
1 引用(Reference)
你现在还是 JDK 1.0 或者 1.1 版本的开发者吗?如果是的话,可以告诉你跳过“5 Reference”这一部分吧,甚至跳过本文。如果不是的话,下面这些内容还是有参考价值的。你可能会问,Reference 还有什么可讲的?还是有一点的,你知道 Reference 有四种分类吗?这可不是孔乙己的四种“回”字写法可以类比的。说引用,我们最先想到的一般是:
Object obj = new Object();
这种属于 Strong Reference(JDK 1.2 之后引入),这类 ref 的特点就是,只要 ref 还在,目标对象就不能被干掉。我们可以想一下为什么要干掉一些对象?很简单,因为内存不够了。如果内存始终够用,大家都活着就好了。所以当内存不够时,会先干掉一些“必死无疑的家伙”(下面会解释),如果这时候内存还不够用,就该干掉那些“可死可不死的家伙”了。
JDK 1.2 之后还引入了 SoftReference 和 WeakReference,前者就是那些“可死可不死的家伙”。当进行了一次内存清理(干掉“必死无疑”的家伙)后,还是不够用,就再进行一次清理,这次清理的内容就是 SoftReference 了。如果干掉 Soft Reference 后还是不够用,JVM 就抛出 OOM 异常了。
好像 WeakReference 还没说呢?它是干嘛的?其实它就是那些“必死无疑的家伙”。每一次 JVM 进行清理时,都会将这类 ref 干掉。所以一个 WeakReference 出生后,它的死期,就是下一次 JVM 的清理。
“回”字的最后一种写法,是 PhantomReference,名字很恐怖吧(Phantom是鬼魂的意思,不仅含义恐怖,而且发音也恐怖——“坟头”)。这类 ref 的唯一作用,就是当相应的 Object 被 clean 掉的时候,通知 JVM。
虽然有四种“回”字,但是 Strong Reference 却没有相应的类,java.lang.ref.Reference 只有三个子类。
你可能会发现,在 Reference 这一部分,我经常性地提到“清理”。什么“清理”?就是下面要说的 Garbage Collection 中对”无用”对象的 clean。
这是 JVM 的核心功能之一,同时也是为什么绝大多数 Java 工程师不需要像 C++ 程序员那样考虑对象的生存期问题。至于因此而同时导致 Java 工程师不能够放任自由地控制内存的结果,其实是一个 Freedom 与 Effeciency 之间的 trade-off,而 C++ 工程师与 Java 工程师恰如生存在两个国度的人,好像“幸福生活”的天朝人民与“水深火热”的西方百姓之间的“时而嘲笑、时而艳羡”一般。
言归正传,Garbage Collector(GC)是 JVM 中筛选并清理 Garbage 的工具。那么第一个要搞清楚的问题是,什么是 Garbage?严谨的说,Garbage 就是不再被使用、或者认为不再被使用、甚至是某些情况下被选作“牺牲品”的对象。看上去很罗嗦,那就先理解成“不再被使用”吧。这就出现了第二个问题,怎么判断不再被使用?这就是下面首先要介绍的 Object Marking Algorithms。
2 对象标记算法(Object Marking Algorithms)
下面还是先从本质一点的东西开始说吧。一个对象变得 useless 了,其实就是它目前没有称为任何一个 reference 的 target,并且认为今后也不会成为(这是从逻辑上说,实际上此刻没有被引用的对象,今后也没有人会去引用了??)
2.1 引用计数法(Reference Counting)
核心思想:很简单。每个对象都有一个引用计数器,当在某处该对象被引用的时候,它的引用计数器就加一,引用失效就减一。引用计数器中的值一旦变为0,则该对象就成为垃圾了。但目前的 JVM 没有用这种标记方式的。为什么呢?
因为引用计数法无法解决循环引用(对象引用关系组成“有向有环图”的情况,涉及一些图论的知识,在根搜索算法中会解释)的问题。比如下面的例子:
package com.sinosuperman.jvm;
class _1MB_Data {
public Object instance = null;
private byte[] data = new byte[1024 * 1024 * 1];
}
public class CycledReferenceProblem {
public static void main(String[] args) {
_1MB_Data d1 = new _1MB_Data();
_1MB_Data d2 = new _1MB_Data();
d1.instance = d2;
d2.instance = d1;
d1 = null;
d2 = null;
System.gc();
}
}
在这个程序中,首先在堆内存中创建了两个 1MB 大小的对象,并且其中分别存储的 instance 成员引用了对方。那么即使 d1和 d2 被置为 null 时,引用数并没有变为零。如果这是采用引用计数法来标记的话,内存就被浪费了,gc 的时候不会被回收。好悲催啊 :(
重复一下在《JVM 深入笔记(1)内存区域是如何划分的?》中提到的运行环境:
**Mac OS X 10.7.3**,**JDK 1.6.0 Update 29**,**Oracle Hot Spot 20.4-b02**。
那么我们来试试Oracle Hot Spot 20.4-b02是不是采用引用计数法来标记的。对了,别忘了为CycledReferenceProblem使用的虚拟机开启-XX:+PrintGCDetails参数,然后运行结果如下:
[Full GC (System) [CMS: 0K->366K(63872K), 0.0191521 secs] 3778K->366K(83008K), [CMS Perm : 4905K->4903K(21248K)], 0.0192274 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
Heap
par new generation total 19136K, used 681K [7f3000000, 7f44c0000, 7f44c0000)
eden space 17024K, 4% used [7f3000000, 7f30aa468, 7f40a0000)
from space 2112K, 0% used [7f40a0000, 7f40a0000, 7f42b0000)
to space 2112K, 0% used [7f42b0000, 7f42b0000, 7f44c0000)
concurrent mark-sweep generation total 63872K, used 366K [7f44c0000, 7f8320000, 7fae00000)
concurrent-mark-sweep perm gen total 21248K, used 4966K [7fae00000, 7fc2c0000, 800000000)
可以看到,在Full GC时,清理掉了 (3778-366)KB=3412KB 的对象。这一共有 3MB 多,可以确定其中包括两个我们创建的 1MB 的对象吗?貌似无法确定。好吧,那下面我们使用_2M_Data对象来重复上面的程序。
package com.sinosuperman.jvm;
class _2MB_Data {
public Object instance = null;
private byte[] data = new byte[1024 * 1024 * 2];
}
public class CycledReferenceProblem {
public static void main(String[] args) {
_2MB_Data d1 = new _2MB_Data();
_2MB_Data d2 = new _2MB_Data();
d1.instance = d2;
d2.instance = d1;
d1 = null;
d2 = null;
System.gc();
}
}
运行结果如下:
[Full GC (System) [CMS: 0K->366K(63872K), 0.0185981 secs] 5826K->366K(83008K), [CMS Perm : 4905K->4903K(21248K)], 0.0186886 secs] [Times: user=0.04 sys=0.00, real=0.02 secs]
Heap
par new generation total 19136K, used 681K [7f3000000, 7f44c0000, 7f44c0000)
eden space 17024K, 4% used [7f3000000, 7f30aa4b0, 7f40a0000)
from space 2112K, 0% used [7f40a0000, 7f40a0000, 7f42b0000)
to space 2112K, 0% used [7f42b0000, 7f42b0000, 7f44c0000)
concurrent mark-sweep generation total 63872K, used 366K [7f44c0000, 7f8320000, 7fae00000)
concurrent-mark-sweep perm gen total 21248K, used 4966K [7fae00000, 7fc2c0000, 800000000)
这次清理掉了 (5826-366)=5460KB 的对象。我们发现两次清理相差 2048KB,刚好是 2MB,也就是 d1 和 d2 刚好各相差 1MB。我想这可以确定,gc 的时候确实回收了两个循环引用的对象。如果你还不信,可以再试试 3MB、4MB,都是刚好相差 2MB。
这说明Oracle Hot Spot 20.4-b02虚拟机并不是采用引用计数方法。事实上,现在没有什么流行的 JVM 会去采用简陋而问题多多的引用计数法来标记。不过要承认,它确实简单而且大多数时候有效。
那么,这些主流的 JVM 都是使用什么标记算法的呢?
2.2. 根搜索算法(Garbage Collection Roots Tracing)
对,没错,就是“跟搜索算法”。我来介绍以下吧。
2.2.1 基本思想
其实思路也很简单(算法领域,除了红黑树、KMP等等比较复杂外,大多数思路都很简单),可以概括为如下几步:
选定一些对象,作为 GC Roots,组成基对象集(这个词是我自己造的,与其他文献资料的说法可能不一样。但这无所谓,名字只是个代号,理解算法内涵才是根本);
由基对象集内的对象出发,搜索所有可达的对象;
其余的不可达的对象,就是可以被回收的对象。
这里的“可达”与“不可达”与图论中的定义一样,所有的对象被看做点,引用被看做有向连接,整个引用关系就是一个有向图。在“引用计数法”中提到的循环引用,其实就是有向图中有环的情况,即构成“有向有环图”。引用计数法不适用于“有向有环图”,而根搜索算法适用于所有“有向图”,包括有环的和无环的。那么是如何解决的呢?
2.2.2 GC Roots
如果你的逻辑思维够清晰,你会说“一定与选取基对象集的方法有关”。是的,没错。选取 GC Roots 组成基对象集,其实就是选取如下这些对象:
《深入理解 Java 虚拟机:JVM 高级特性与最佳实践》一书中提到的 GC Roots 为:
方法区(Method Area,即 Non-Heap)中的类的 static 成员引用的对象,和 final 成员引用的对象;
Java 方法栈(Java Method Stack)的局部变量表(Local Variable Table)中引用的对象;
原生方法栈(Native Method Stack)中 JNI 中引用的对象。
但显然不够全面,[参考2]中提到的要更全面:(March 6th,2012 update)
由系统类加载器加载的类相应的对象:这些类永远不会被卸载,且这些类创建的对象都是 static 的。注意用户使用的类加载器加载的类创建的对象,不属于 GC Roots,除非是 java.lang.Class 的相应实例有可能会称为其他类的 GC Roots。
正在运行的线程。
Java 方法栈(Java Method Stack)的局部变量表(Local Variable Table)中引用的对象。
原生方法栈(Native Method Stack)的局部变量表(Local Variable Table)中引用的对象。
JNI 中引用的对象。
同步监控器使用的对象。
由 JVM 的 GC 控制的对象:这些对象是用于 JVM 内部的,是实现相关的。一般情况下,可能包括系统类加载器(注意与“1”不一样,“1”中是 objects created by the classes loaded by system class loaders,这里是 the objects, corresponding instances of system class loaders)、JVM 内部的一些重要的异常类的对象、异常句柄的预分配对象和在类加载过程中自定义的类加载器。不幸的是,JVM 并不提供这些对象的任何额外的详细信息。因此这些实现相关的内容,需要依靠分析来判定。
所以这个算法实施起来有两部分,第一部分就是到 JVM 的几个内存区域中“找对象”,第二部分就是运用图论算法。
3. 废话
JVM 的标记算法并不是 JVM 垃圾回收策略中最重要的。真正的核心,是回收算法,当然标记算法是基础。
SpringMVC强大的数据绑定(1)——第六章 注解式控制器详解——跟着开涛学SpringMVC - 开涛的博客(最近太忙,无法解决各位朋友的问题,见谅) - ITeye技术网站
到目前为止,请求已经能交给我们的处理器进行处理了,接下来的事情是要进行收集数据啦,接下来我们看看我们能从请求中收集到哪些数据,如图6-11:

图6-11
1、@RequestParam绑定单个请求参数值;
2、@PathVariable绑定URI模板变量值;
3、@CookieValue绑定Cookie数据值
4、@RequestHeader绑定请求头数据;
5、@ModelValue绑定参数到命令对象;
6、@SessionAttributes绑定命令对象到session;
7、@RequestBody绑定请求的内容区数据并能进行自动类型转换等。
8、@RequestPart绑定“multipart/data”数据,除了能绑定@RequestParam能做到的请求参数外,还能绑定上传的文件等。
除了上边提到的注解,我们还可以通过如HttpServletRequest等API得到请求数据,但推荐使用注解方式,因为使用起来更简单。
接下来先看一下功能处理方法支持的参数类型吧。
6.6.1、功能处理方法支持的参数类型
在继续学习之前,我们需要首先看看功能处理方法支持哪些类型的形式参数,以及他们的具体含义。
一、ServletRequest/HttpServletRequest 和 ServletResponse/HttpServletResponse
- public String requestOrResponse (
- ServletRequest servletRequest, HttpServletRequest httpServletRequest,
- ServletResponse servletResponse, HttpServletResponse httpServletResponse
- )
Spring Web MVC框架会自动帮助我们把相应的Servlet请求/响应(Servlet API)作为参数传递过来。
二、InputStream/OutputStream 和 Reader/Writer
- public void inputOrOutBody(InputStream requestBodyIn, OutputStream responseBodyOut)
- throws IOException {
- responseBodyOut.write("success".getBytes());
- }
requestBodyIn:获取请求的内容区字节流,等价于request.getInputStream();
responseBodyOut:获取相应的内容区字节流,等价于response.getOutputStream()。
- public void readerOrWriteBody(Reader reader, Writer writer)
- throws IOException {
- writer.write("hello");
- }
reader:获取请求的内容区字符流,等价于request.getReader();
writer:获取相应的内容区字符流,等价于response.getWriter()。
InputStream/OutputStream 和 Reader/Writer两组不能同时使用,只能使用其中的一组。
三、WebRequest/NativeWebRequest
WebRequest是Spring Web MVC提供的统一请求访问接口,不仅仅可以访问请求相关数据(如参数区数据、请求头数据,但访问不到Cookie区数据),还可以访问会话和上下文中的数据;NativeWebRequest继承了WebRequest,并提供访问本地Servlet API的方法。
- public String webRequest(WebRequest webRequest, NativeWebRequest nativeWebRequest) {
- System.out.println(webRequest.getParameter("test"));//①得到请求参数test的值
- webRequest.setAttribute("name", "value", WebRequest.SCOPE_REQUEST);//②
- System.out.println(webRequest.getAttribute("name", WebRequest.SCOPE_REQUEST));
- HttpServletRequest request =
- nativeWebRequest.getNativeRequest(HttpServletRequest.class);//③
- HttpServletResponse response =
- nativeWebRequest.getNativeResponse(HttpServletResponse.class);
- return "success";
- }
① webRequest.getParameter:访问请求参数区的数据,可以通过getHeader()访问请求头数据;
② webRequest.setAttribute/getAttribute:到指定的作用范围内取/放属性数据,Servlet定义的三个作用范围分别使用如下常量代表:
SCOPE_REQUEST :代表请求作用范围;
SCOPE_SESSION :代表会话作用范围;
SCOPE_GLOBAL_SESSION :代表全局会话作用范围,即ServletContext上下文作用范围。
③ nativeWebRequest.getNativeRequest/nativeWebRequest.getNativeResponse:得到本地的Servlet API。
四、HttpSession
- public String session(HttpSession session) {
- System.out.println(session);
- return "success";
- }
此处的session永远不为null。
注意:session访问不是线程安全的,如果需要线程安全,需要设置AnnotationMethodHandlerAdapter或RequestMappingHandlerAdapter的synchronizeOnSession属性为true,即可线程安全的访问session。
五、命令/表单对象
Spring Web MVC能够自动将请求参数绑定到功能处理方法的命令/表单对象上。
- @RequestMapping(value = "/commandObject", method = RequestMethod.GET)
- public String toCreateUser(HttpServletRequest request, UserModel user) {
- return "customer/create";
- }
- @RequestMapping(value = "/commandObject", method = RequestMethod.POST)
- public String createUser(HttpServletRequest request, UserModel user) {
- System.out.println(user);
- return "success";
- }
如果提交的表单(包含username和password文本域),将自动将请求参数绑定到命令对象user中去。
六、Model、Map、ModelMap
Spring Web MVC 提供Model、Map或ModelMap让我们能去暴露渲染视图需要的模型数据。
- @RequestMapping(value = "/model")
- public String createUser(Model model, Map model2, ModelMap model3) {
- model.addAttribute("a", "a");
- model2.put("b", "b");
- model3.put("c", "c");
- System.out.println(model == model2);
- System.out.println(model2 == model3);
- return "success";}
虽然此处注入的是三个不同的类型(Model model, Map model2, ModelMap model3),但三者是同一个对象,如图6-12所示:

图6-11
AnnotationMethodHandlerAdapter和RequestMappingHandlerAdapter将使用BindingAwareModelMap作为模型对象的实现,即此处我们的形参(Model model, Map model2, ModelMap model3)都是同一个BindingAwareModelMap实例。
此处还有一点需要我们注意:
- @RequestMapping(value = "/mergeModel")
- public ModelAndView mergeModel(Model model) {
- model.addAttribute("a", "a");//①添加模型数据
- ModelAndView mv = new ModelAndView("success");
- mv.addObject("a", "update");//②在视图渲染之前更新③处同名模型数据
- model.addAttribute("a", "new");//③修改①处同名模型数据
- //视图页面的a将显示为"update" 而不是"new"
- return mv;
- }
从代码中我们可以总结出功能处理方法的返回值中的模型数据(如ModelAndView)会 合并 功能处理方法形式参数中的模型数据(如Model),但如果两者之间有同名的,返回值中的模型数据会覆盖形式参数中的模型数据。
七、Errors/BindingResult
- @RequestMapping(value = "/error1")
- public String error1(UserModel user, BindingResult result)
- @RequestMapping(value = "/error2")
- public String error2(UserModel user, BindingResult result, Model model) {
- @RequestMapping(value = "/error3")
- public String error3(UserModel user, Errors errors)
以上代码都能获取错误对象。
Spring3.1之前(使用AnnotationMethodHandlerAdapter)错误对象必须紧跟在命令对象/表单对象之后,如下定义是错误的:
- @RequestMapping(value = "/error4")
- public String error4(UserModel user, Model model, Errors errors)
- }
如上代码从Spring3.1开始(使用RequestMappingHandlerAdapter)将能正常工作,但还是推荐“错误对象紧跟在命令对象/表单对象之后”,这样是万无一失的。
Errors及BindingResult的详细使用请参考4.16.2数据验证。
八、其他杂项
- public String other(Locale locale, Principal principal)
java.util.Locale:得到当前请求的本地化信息,默认等价于ServletRequest.getLocale(),如果配置LocaleResolver解析器则由它决定Locale,后续介绍;
java.security.Principal:该主体对象包含了验证通过的用户信息,等价于HttpServletRequest.getUserPrincipal()。
以上测试在cn.javass.chapter6.web.controller.paramtype.MethodParamTypeController中。
其他功能处理方法的形式参数类型(如HttpEntity、UriComponentsBuilder、SessionStatus、RedirectAttributes)将在后续章节详细讲解。
Java 导出Word几种方法
1,Java使用freemarker导出word和excel:先新建一份word文档,使用word编辑好内容, 然后把这份word文档另存为word 2003 XML (.xml)文件, 注意是在office里面另存为, 不是直接改后缀哈。 保存后就会得到一份XML的文件, 然后把这份文件的.xml改为*.ftl, 没错!将它改为freemarker的模版, 放到项目中去, 然后在顶部加上一行XML申明,并对需要动态生成的地方设置特殊标记,使用程序拿数据结果集替换之。
http://my.oschina.net/codingforme/blog/185110
2,使用RTFTemplate包生成RTF导出Word:设计 *.fields.xml文件,在此文件中定义好你要填充的参数。RTFTemplate.dot 设计rtf模版文档。注意,最好将rtf模版文档、RTFTemplate.dot设计器、*.fields.xml文件放在统一文件夹下。否则有可能找不到word加载项里的在*.fields.xml里设定的参数。
http://3ge.iteye.com/blog/1883818
3,利用Java Apache POI 生成Word文档:http://blog.csdn.net/w8700569/article/details/7288149
Java 信任所有SSL证书(解决PKIX path building failed问题) | PHP & Java
Java在请求某些不受信任的https网站时会报:PKIX path building failed
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target at sun.security.ssl.Alerts.getSSLException(Alerts.java:192) at sun.security.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:1884) at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:276) at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:270) at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1341) at sun.security.ssl.ClientHandshaker.processMessage(ClientHandshaker.java:153) at sun.security.ssl.Handshaker.processLoop(Handshaker.java:868) at sun.security.ssl.Handshaker.process_record(Handshaker.java:804) at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:1016) at sun.security.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1312) at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1339) at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1323) at sun.net.www.protocol.https.HttpsClient.afterConnect(HttpsClient.java:563) at sun.net.www.protocol.https.AbstractDelegateHttpsURLConnection.connect(AbstractDelegateHttpsURLConnection.java:185) at sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1300) at sun.net.www.protocol.https.HttpsURLConnectionImpl.getInputStream(HttpsURLConnectionImpl.java:254) at SslTest.getRequest(SslTest.java:16) at SslTest.main(SslTest.java:40)Caused by: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:385) at sun.security.validator.PKIXValidator.engineValidate(PKIXValidator.java:230) at sun.security.validator.Validator.validate(Validator.java:260) at sun.security.ssl.X509TrustManagerImpl.validate(X509TrustManagerImpl.java:326) at sun.security.ssl.X509TrustManagerImpl.checkTrusted(X509TrustManagerImpl.java:231) at sun.security.ssl.X509TrustManagerImpl.checkServerTrusted(X509TrustManagerImpl.java:126) at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1323) ... 13 moreCaused by: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target at sun.security.provider.certpath.SunCertPathBuilder.engineBuild(SunCertPathBuilder.java:196) at java.security.cert.CertPathBuilder.build(CertPathBuilder.java:268) at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:380) ... 19 more |
解决办法:
1、导入证书到本地证书库
2、信任所有SSL证书
最好的解决办法或许是信任所有SSL证书,因为某些时候不能每次都手动的导入证书非常麻烦。现在封装了个方法,在连接openConnection的时候忽略掉证书就行了。
|
1
|
SslUtils.ignoreSsl(); |
SslUtils.java:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
import java.security.cert.CertificateException;import java.security.cert.X509Certificate;import javax.net.ssl.HostnameVerifier;import javax.net.ssl.HttpsURLConnection;import javax.net.ssl.SSLContext;import javax.net.ssl.SSLSession;import javax.net.ssl.TrustManager;import javax.net.ssl.X509TrustManager;public class SslUtils { private static void trustAllHttpsCertificates() throws Exception { TrustManager[] trustAllCerts = new TrustManager[1]; TrustManager tm = new miTM(); trustAllCerts[0] = tm; SSLContext sc = SSLContext.getInstance("SSL"); sc.init(null, trustAllCerts, null); HttpsURLConnection.setDefaultSSLSocketFactory(sc.getSocketFactory()); } static class miTM implements TrustManager,X509TrustManager { public X509Certificate[] getAcceptedIssuers() { return null; } public boolean isServerTrusted(X509Certificate[] certs) { return true; } public boolean isClientTrusted(X509Certificate[] certs) { return true; } public void checkServerTrusted(X509Certificate[] certs, String authType) throws CertificateException { return; } public void checkClientTrusted(X509Certificate[] certs, String authType) throws CertificateException { return; } } /** * 忽略HTTPS请求的SSL证书,必须在openConnection之前调用 * @throws Exception */ public static void ignoreSsl() throws Exception{ HostnameVerifier hv = new HostnameVerifier() { public boolean verify(String urlHostName, SSLSession session) { System.out.println("Warning: URL Host: " + urlHostName + " vs. " + session.getPeerHost()); return true; } }; trustAllHttpsCertificates(); HttpsURLConnection.setDefaultHostnameVerifier(hv); }} |
SslTest.java:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
import java.io.OutputStreamWriter;import java.net.URL;import java.net.URLConnection;import org.apache.commons.io.IOUtils;public class SslTest { public String getRequest(String url,int timeOut) throws Exception{ URL u = new URL(url); if("https".equalsIgnoreCase(u.getProtocol())){ SslUtils.ignoreSsl(); } URLConnection conn = u.openConnection(); conn.setConnectTimeout(timeOut); conn.setReadTimeout(timeOut); return IOUtils.toString(conn.getInputStream()); } public String postRequest(String urlAddress,String args,int timeOut) throws Exception{ URL url = new URL(urlAddress); if("https".equalsIgnoreCase(url.getProtocol())){ SslUtils.ignoreSsl(); } URLConnection u = url.openConnection(); u.setDoInput(true); u.setDoOutput(true); u.setConnectTimeout(timeOut); u.setReadTimeout(timeOut); OutputStreamWriter osw = new OutputStreamWriter(u.getOutputStream(), "UTF-8"); osw.write(args); osw.flush(); osw.close(); u.getOutputStream(); return IOUtils.toString(u.getInputStream()); } public static void main(String[] args) { try { SslTest st = new SslTest(); System.out.println(a); } catch (Exception e) { e.printStackTrace(); } }} |
使用 Spring 2.5 注释驱动的 IoC 功能
注释配置相对于 XML 配置具有很多的优势:
- 它可以充分利用 Java 的反射机制获取类结构信息,这些信息可以有效减少配置的工作。如使用 JPA 注释配置 ORM 映射时,我们就不需要指定 PO 的属性名、类型等信息,如果关系表字段和 PO 属性名、类型都一致,您甚至无需编写任务属性映射信息——因为这些信息都可以通过 Java 反射机制获取。
- 注释和 Java 代码位于一个文件中,而 XML 配置采用独立的配置文件,大多数配置信息在程序开发完成后都不会调整,如果配置信息和 Java 代码放在一起,有助于增强程序的内聚性。而采用独立的 XML 配置文件,程序员在编写一个功能时,往往需要在程序文件和配置文件中不停切换,这种思维上的不连贯会降低开发效率。
因此在很多情况下,注释配置比 XML 配置更受欢迎,注释配置有进一步流行的趋势。Spring 2.5 的一大增强就是引入了很多注释类,现在您已经可以使用注释配置完成大部分 XML 配置的功能。在这篇文章里,我们将向您讲述使用注释进行 Bean 定义和依赖注入的内容。
下面是一个简单的例子:
<context:component-scan base-package="com.baobaotao">
<context:include-filter type="regex"
expression="com\.baobaotao\.service\..*"/>
<context:exclude-filter type="aspectj"
expression="com.baobaotao.util..*"/>
</context:component-scan>
值得注意的是 <context:component-scan/> 配置项不但启用了对类包进行扫描以实施注释驱动 Bean 定义的功能,同时还启用了注释驱动自动注入的功能(即还隐式地在内部注册了 AutowiredAnnotationBeanPostProcessor 和 CommonAnnotationBeanPostProcessor),因此当使用 <context:component-scan/> 后,就可以将 <context:annotation-config/> 移除了。
java - Under what conditions is a JSESSIONID created? - Stack Overflow
JSESSIONID cookie is created/sent when session is created. Session is created when your code calls request.getSession() or request.getSession(true) for the first time. If you just want get session, but not create it if it doesn't exists, use request.getSession(false) -- this will return you a session or null. In this case, new session is not created, and JSESSIONID cookie is not sent. (This also means that session isn't necessarily created on first request... you and your code is in controlwhen the session is created)
Sessions are per-context:
SRV.7.3 Session Scope
HttpSession objects must be scoped at the application (or servlet context) level. The underlying mechanism, such as the cookie used to establish the session, can be the same for different contexts, but the object referenced, including the attributes in that object, must never be shared between contexts by the container.
Update: Every call to JSP page implicitly creates new session if there is no session yet. This can be turned off by session='false' page directive, in which case session variable is not available on JSP page at all.