构建高可用的缓存集群的开源解决方案
很多应用都通过使用缓存来避免所有的请求都查询数据库,以加快系统的响应速度,Memcached是常用的缓存服务器(现在比较流行的还有Redis),它一个高性能的分布式内存对象缓存系统,旨在通过缓存数据库查询结果,减少数据库的访问次数。但是在运行多个Memcached服务器时,往往还需要考虑其它的问题,比如缓存一致性、缓存失效等,缓存一致性是指要保证多个Memcached服务器中数据的一致,缓存失效的后果相对来说比较严重,当在大并发访问的场景下,如果Memcached缓存失效,所有请求会在同一瞬间并发访问数据库,可能会导致数据库宕机。为了保证缓存系统的稳定和高可用,很多公司都研发了相应的系统。本文汇总了Twitter、Facebook、Youtube在缓存方面的解决方案,供读者参考。
-
Twitter的Redis/Memcached代理服务:Twemproxy
Twemproxy是一个使用C语言编写的Redis 和 Memcache 代理服务器,通过引入一个代理层,将应用程序后端的多台Redis或Memcached实例进行统一管理,使应用程序只需要在Twemproxy上进行操作,而不用关心后面具体有多少个真实的Redis或Memcached实例。当某个节点宕掉时,Twemproxy可以自动将它从集群中剔除,而当它恢复服务时,Twemproxy也会自动连接。由于是代理,所以Twemproxy会有微小的性能损失。 -
Facebook的Memcached协议路由器:McRouter
McRouter是一个使用C++(主要语言,使用了大量的C++ 11特性)开发的基于Memcached协议的路由器,它是Facebook和Instagram缓存架构的核心组件,在高峰时期可以处理近50亿请求。McRouter中客户端可以共享连接池,这样能减少连接的数量。McRouter可以根据key前缀把客户端分配到不同的Memcached池中,允许以主机、池或者集群为单位设置任何请求的速率的阀值,同时也支持限制请求的速度以减缓请求的发送速度,以保障服务质量。 -
Youtube的Mysql中间件:Vitess
缓存层存在的初衷是减少应用与数据库的交互,以提高响应时间,与其将缓存与数据库分离,不如直接将缓存嵌入数据库中。Vitess是Youtube的开源分布式MySQL工具集,主要使用Go语言编写,已经用于Youtube生产环境。Vitess支持行级缓存,并与Memcached进行了集成,可以有效提高带主键查询的速率,查询只有在Memcached中查询不到时才会进入数据库查询,而当数据被修改或者数据库表结构发生变化时,缓存数据会被删除。
另外,还有一些未开源的解决方案,比如Box的Tron。同时,InfoQ也非常关注国内相关问题的解决方案,欢迎读者在评论中留言与我探讨。
孩子上课注意力不集中,爱走神,怎么办?_王金战_新浪博客
如果家长发现孩子上课注意力不能集中,可参考如下几方面对孩子及时去矫正:
1、培养兴趣
解决孩子上课走神,首要的是想办法培养孩子对学习的兴趣。一是让孩子把学到的东西及时应用到实际生活中,让孩子感觉知识是非常重要、非常有用和有意思的,通过知识的运用过程激发孩子学习的兴趣。
2、培养孩子的自制力
家长在日常生活中,要有意识地培养孩子的自我控制能力,使注意力服从于活动的目的和任务。可以通过让孩子在一段时间内专心做一件事入手,如做作业、绘画、练琴、手工制作等等来培养孩子的自制力。从开始的十分钟,慢慢过渡到四十分钟,也就是一节课。要循序渐进,一次增加五分钟,心急吃不了热豆腐。让孩子在固定的时间和固定的地点,完成固定的任务,以便形成一种心理活动的定向。
3、注意劳逸结合
学习是脑力劳动,大脑要消耗大量的氧。因此,家长要合理安排孩子的作息时间,控制看电视和玩电子游戏的时间,保证孩子充足的睡眠,养成劳逸结合的好习惯。这样,孩子才能有充足的精力专心听课。
4、和老师沟通
孩子上课走神,请老师帮忙配合效果应该是最好的。家长要耐心和老师交流、沟通,请老师帮忙,课堂上如发现孩子走神能及时提醒,或有意识的安排孩子上黑板做题、回答老师的提问等具体任务,帮孩子尽快把心收回来。
5、专业指导
如果孩子是因为营养方面或心理因素导致的上课走神,家长就要请专业儿童教育的专家和医生,对孩子进行综合考察、诊断,然后再对孩子进行针对性的治疗和矫正。
纠正孩子的不良习惯,家长一要有耐心,给孩子一段时间适应。只要我们耐心坚持,相信孩子会进步的。
培养孩子注意力六大金律
俄国教育家乌申斯基说过,“注意是心灵的天窗”。只有打开注意力的这扇窗户,智慧的阳光才能撒满心田。
注意力是孩子学习和生活的基本能力,注意力的好与坏直接影响孩子的认知和社会性情感等身心各方面的发展及其入学后学业成绩的高低。
孩子注意力的形成虽然与先天的遗传有一定关系,但后天的环境与教育的影响更为重要。家长应当根据孩子的身心发展规律与特点,为他创造良好的教育环境,从孩子出生起就有意识地培养孩子的注意力,帮助孩子养成良好的注意品质与能力。
(一)营造安静、简单的环境
幼儿注意稳定性差,容易因新异刺激而转移,这是学前期幼儿的普遍特点。因此,父母应根据这一特点,排除各种可能分散孩子注意的因素,为孩子创造安静、简朴的物质环境。
例如,孩子玩安静游戏或看图书的地方应远离过道,避免他人的来回走动影响孩子的活动;墙面布置不应过于花哨;电视、糖果等可能吸引孩子注意力的物品也应摆放在较远的位置。
父母还应注意调整自己的言行举止,适时地对孩子提出适当的要求,与孩子形成良好的互动模式。
例如,当孩子全神贯注地做某件事时,成人不应随意地去打扰孩子。我们经常会看到,孩子正聚精会神地玩着插塑或搭积木,爸爸走过来问一问吃饱了吗,一会儿,奶奶又走过来让孩子去喝果汁,又一会儿,妈妈又叫他帮忙去拿样东西。孩子短短几分钟的活动被大人们打断数次,时间一长,自然无法集中注意力。所以,在孩子专心做事时,家长最好也坐下来做些安静的活动,切忌在旁边走来走去,打扰孩子。
(二)有规律的生活
孩子一日生活的节奏以及各种活动的时间长短都会影响他的注意力。因此,家长应当注意安排好孩子的生活作息。
让孩子的生活有张有弛、动静交替。不同性质活动之间的转换要平和,给孩子一个过渡准备。
例如,孩子在户外跑来跑去,心跳加速,全身的每一个细胞都处于一种兴奋状态。进到户内后,孩子很难立刻进入到绘画或读书等安静活动中。一些家长却要求孩子立刻安静下来,集中注意力。这种要求本身就是不合理的,是违背孩子的身体器官的运作规律的。
要求孩子集中注意力的时间不宜太长。研究表明,大班末期的幼儿能够集中注意力的时间为15分钟左右。因此,家长在安排孩子的活动时,应当注意调整时间,切忌一天到晚强迫孩子坐着一动不动。
(三)培养孩子的自我约束力
孩子的自控能力较差是注意力容易分散的另一个重要原因。当有新异刺激出现时,成人可以约束自己不去关注它,但孩子却很难做到。因此,为培养孩子的注意力,成人可以有意识地创设情景逐渐提高孩子的自我约束能力。
采用游戏的方式,将持久注意的要求变为游戏角色本身的行为规则。
例如,与孩子一起玩“指挥交通”的游戏,让孩子扮演交通警察,事先约定每班交通警察要站3分钟的岗,时间到后才能换岗。在游戏中,对注意力持续时间的要求可以循序渐进地提高。通过不同的游戏活动,幼儿可以慢慢地将外在的游戏规则内化为内在的自我约束。
有意识地增加干扰因素来增强孩子的自我控制能力。
比如,家长可以偶尔在孩子做事时,假装无意地把他感兴趣的玩具、图书或糖果等放在他旁边。当孩子表现出要放弃当前的活动去选择新的诱惑时,家长应及时地明确提出要求,让孩子集中注意力。
(四)培养孩子注意事物的广度
幼儿注意力差的另一表现是不能同时注意多个事物。为此,家长应当有意识地设计一些活动来培养孩子的注意广度。
“猜物游戏”
先在孩子面前摆放上汽车、小球、铅笔等多种物品,让孩子观察几秒种,然后让他闭上眼睛,趁机悄悄拿走几样物品,然后让他说出哪些东西不见了。这个游戏要求孩子在观察时,能快速地注意到几个物品,从而锻炼了孩子的注意广度。
注意事项
家长应当注意幼儿的年龄和个体之间的差异,呈现的物品的数量多少、拿走的物品的多少以及观察时间的长短等都应当适当。对于年龄大的孩子,呈现的物品可以多一些,观察的时间可以短一些。
(五)激发孩子对活动的兴趣与需要
兴趣与需要是孩子活动的内在推动力,是直接影响孩子注意力的情感系统。为维持孩子对某一活动的持续兴趣,父母应当注意活动内容的难度要适合孩子的水平,既要让孩子体验到成功的快乐,同时又能感受到一定的挑战。
如果活动内容与孩子的先前经验无关,孩子没有充分的经验准备和能力准备,活动任务超出了其驾驭的范围,即使形式再活泼有趣,也不能吸引他们的注意;如果任务难度过低,对孩子来说没有一点挑战,孩子也不会感兴趣,不能集中注意力。
(六)明确活动的目的和要求
注意是为任务服务的,任务越明确,完成任务的愿望越迫切,注意就越能集中和持久。要想使孩子的注意持久,成人不能强迫他做什么,而要让他知道为什么要这样做,激发他做好这件事的愿望。
因此,在活动之前,家长应当帮助孩子明确活动的目的和要求。在活动过程中,家长应当及时提醒孩子,使其注意力始终指向某个方向。
例如,家长和孩子种一颗豆放在窗台上。最初几天,孩子可能出于好奇而经常来看一看。但时间久了,兴趣趋于淡化,自然不会来光顾了。
如果家长能在种豆之前对孩子说:“这颗豆不久会长出绿色的长长的叶子,你要是看到它发芽了,就赶紧来告诉妈妈”。这样就交给孩子一个任务,为了完成妈妈交给的任务,他就必须经常注意它。
小提示
家长向孩子提出活动目的和要求时,应当注意要求一定要具体,要有明确的指向性。笼统模糊的要求对于孩子维持注意并没有太多的积极作用,因为孩子并不明白应当如何去关注,什么时候去关注以及去关注什么。
如在上述例子中,如果家长仅仅说“你要注意它的变化”,孩子可能会感到无所适从,从而失去对观察的兴趣,不能持久注意。这时就要求家长能明确地提出具体要求,将孩子的注意指向具体的某物。所以,如果家长能说出“有没有长出绿色的叶子”,或“看一看它的叶子有什么变化”,效果会更好一些。
解决策略:
1.教给孩子一些小技巧,来延长孩子的注意力集中时间。
比如,让孩子看着老师的脸,这样能通过动作提醒自己跟着老师的节奏来听课;桌上不要放与学习无关的东西,也不要放太花哨的学习用具,等。
游戏也是延长孩子注意力时间的好方式。比如搭积木、 “一二三木头人”等。“一二三木头人”是一个传统的团体游戏,即家长说“一二三”,孩子就小心翼翼地挪动脚步;当家长喊“木头人”的时候,孩子就马上站住不动。四岁以上的孩子就可以玩得很好,也可以变化成一二三机器人、一二三睡美人等。您在家里陪孩子玩一玩,让他练习控制身体,在一段时间不动。
2.让孩子知道上课的纪律。
针对孩子暂时还未适应小学的学习特点,我们家长需要配合老师给孩子讲一讲上课的纪律,让他知道上课应该怎么做,如果说话或者有其他动作,会影响到其他同学的学习的。同时,家长朋友也可以多一些耐心,不要吵孩子。随着对新的学习环境的适应,他会逐渐学会听课。
3.正确对待孩子为获取关注的心理。
如果孩子是为了满足自己被关注的心理,家长可以多给孩子一些关爱,对孩子的行为和情绪表示理解,让孩子得到被关注的满足。也可以告诉孩子,只有良好的行为才能更被关注,改变孩子原有的观念。如果想得到老师和同学的关注,就正确做一个积极思考、热爱学习的学生。
另外,家长也可以联系老师,请老师对孩子因希望得到关注而不专心听课的行为进行冷处理。这样孩子就能逐渐认识到“小动作”不能引起大家的关注,没什么意思,会减少不专心听课的行为。
4.请教老师给孩子“开小灶”。
对于孩子觉得课程内容过难或过易,家长朋友也可以有针对性地帮孩子进行调整。如果孩子觉得内容比较简单,家长可以事与老师沟通好,让老师针对孩子的特别需要准备一些课程内容,如更难的题目、更深入的内容等。如果孩子因为觉得内容过于简单而注意力不集中,家长朋友也可以向老师请教一下如何辅导孩子,争取让孩子尽快跟上老师上课的进度。
好动是孩子的天性,家长对于孩子上课注意力不集中的问题,一定要有足够的耐心,帮孩子分析原因并给予恰当地引导。 “教育是慢的艺术!”家长浓浓的爱、足够的耐心与恰当的引导,一定能让孩子在自己的求学之路上变得成熟。
孩子上课注意力不集中问题的方法
孩子注意力不集中将严重影响孩子的学习和生活。专家为我们提出了以下解决孩子上课注意力不集中问题的方法:
一、为孩子营造安静、舒适的学习与生活环境。因为青少年多以无意注意为主,一切好奇、多变的事物都会很容易地分散他们的注意力,干扰他们正在进行的活动。所以安静舒适的学习环境对他们很重要。
二、充分提高孩子的学习兴趣,将孩子的兴趣与注意力的培养结合起来。
三、注意让孩子在学习中劳逸结合、避免疲劳战术,这样才不会打击孩子学习的积极性。
四、通过有效的训练方法提高孩子的注意力水平。
1、拼图及七巧板练习 。这是二维空间中最有效的集中注意力的练习项目,要求孩子在相当长的一段时间内,保持连续不断的判断力、观察能力、想象能力和分析能力。而这种游戏的挑战性又会给孩子带来成就感,成就感是孩子将注意力集中到底的一个巨大推动力。
2、传话游戏。 找篇文章。六人一组,一个人说话的人在屋里,然后由小组的第一个人进屋听故事,然后这个人再将故事讲给小组里第二个人,依次类推直到最后一个人,然后让最后一个人陈述故事内容。
3、听口令做动作。玩法:在爷爷妈妈、幼儿中任选一人喊口令,其余两人做动作。 游戏开始,喊口令的人说一个动作,做动作的人做和口令相反的动作,如口令为“向右转”,则做“向左转”,口令为“踏步”,则做“立定”等。可交换角色继续做游戏。
4、多米诺骨牌练习 。 大约有七成“难以集中注意力”的孩子,通过这个骨牌堆放的游戏,其耐心得到长足的进步。
5、舒尔特方格游戏训练。舒尔特方格是在一张方形卡片上画上 1CM × 1CM 的 25 个方格,格子内任意填写上阿拉伯数字 1 — 25 的共 25 个数字。训练时,要求被测者用手指按 1 — 25 的顺序依次指出其位置,同时诵读出声,施测者一旁记录所用时间。数完 25 个数字所用时间越短,注意力水平越高。以 7—12 岁年龄组为例,能达到26"以上为优秀,学习成绩应是名列前茅, 42"属于中等水平,班级排名会在中游或偏下, 50"则问题较大,考试会出现不及格现象。
18 岁及以上成年人最好可达到 8"的水平, 25"为中等水平。“舒尔特方格”不但可以简单测量注意力水平,而且是很好的训练方法。又是心理咨询师进行心理治疗时常用的基本方法。 运用这种方法的时候,家长可以自制几套卡片,绘制表格,任意填上数字。从1开始,边念边指出相应的数字,直到25为止。同时诵读出声,施测者一旁记录所用时间。数完 25 个数字所用时间越短,注意力水平越高。以 12 —14 岁年龄组为例,能达到 16 "以上为优秀,学习成绩应是名列前茅, 26 "属于中等水平,班级排名会在中游或偏下, 36 "则问题较大,考试会出现不及格现象。 18 岁及以上成年人最好可达到 8 "的水平, 20 "为中等水平。
该心理训练系统适用于 1 — 12 年级学生及成年人,由家长主持,每日坚持对学生进行 5 分钟训练,可有效地改善学生注意力分散的症状,明显改善和提高学生的注意力水平,从根本上做到上课注意听讲,高效率、高质量完成作业,提高学习效率,自然而然地降低考试错误率,顺理成章地达到提高考试成绩的目的。(舒尔特方格在线小游戏)
相信通过上述方法,您的孩子一定会改变现状,提高上课的注意力水平,使学习成绩大幅提升。
Metrics 1.3.6
Metrics是一个十分强大的分析工具,主要分析代码的复杂性。同时可以统计如包的依赖性、代码的有效行数、方法的有效行数、包的数量、属性的数量等等。
Run Eclipse, go to Help menu -> Software Updates -> Find and Install ... On the opening dialog choose Search for new features to install. Add a new Remote site with the following url http://metrics.sourceforge.net/update and follow the instructions for installation.
To use the metrics plugin you have to be in a Java or Java Browsing perspective or any other perspective that shows java resources as source folders, packages and compilation units. The simple resource perspective won't do. This makes sense since the metrics are all about counting aspects of your java code.
To start using the Metrics View, use Windows -> Show View -> Other and navigate to the Metrics View, as shown in the next image.
Initially the resulting view will show a brief usage message because no metrics have been calculated yet. To start collecting metrics for a project, right click on the project and from the popup menu select "Metrics->Enable" (or alternatively, use the properties page ).This will tell Eclipse to calculate metrics every time a compile happens. Now that you've enabled a project, the easiest way to calculate all its metrics is to do a full rebuild of that project. The metrics view will indicate the progress of the metrics calculations as they are being performed in the background. When it's all done, the metrics view will look something like this:
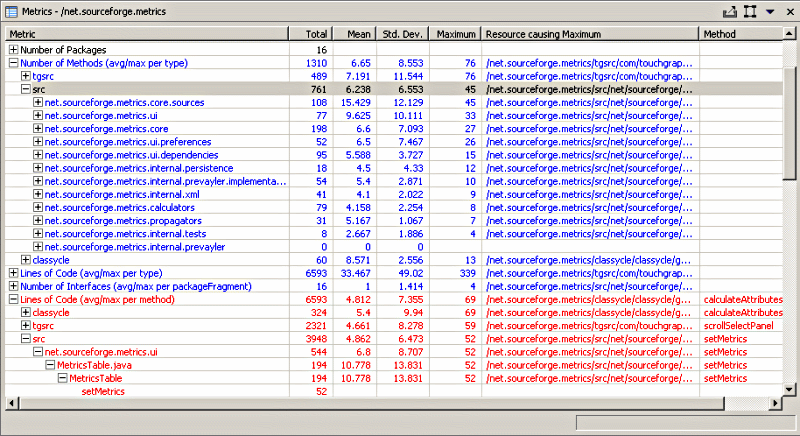
Note that any metric shown in blue can be double-clicked to navigate to the resource causing the maximum value for the metric. Since 1.2.0, the metrics table is actualy a table tree, allowing you to expand each metric to show the values at levels below the selected resource. The child elements at each level are sorted in descending metric (maximum) value order.
java版的Metric工具介绍-hustfxj-ChinaUnix博客
Metrics是一个给JAVA服务的各项指标提供度量工具的包,在JAVA代码中嵌入Metrics代码,可以方便的对业务代码的各个指标进行监控,同时,Metrics能够很好的跟Ganlia、Graphite结合,方便的提供图形化接口。基本使用方式直接将core包(目前稳定版本3.0.1)导入pom文件即可,配置如下:
<dependency> <groupId>com.codahale.metrics</groupId> <artifactId>metrics-core</artifactId> <version>3.0.1</version> </dependency>
core包主要提供如下核心功能:
- Metrics Registries类似一个metrics容器,维护一个Map,可以是一个服务一个实例。
- 支持五种metric类型:Gauges、Counters、Meters、Histograms和Timers。
- 可以将metrics值通过JMX、Console,CSV文件和SLF4J loggers发布出来。
五种Metrics类型:
1. Gauges
Gauges是一个最简单的计量,一般用来统计瞬时状态的数据信息,比如系统中处于pending状态的job。测试代码
点击(此处)折叠或打开
- package com.netease.test.metrics;
- import com.codahale.metrics.ConsoleReporter;
- import com.codahale.metrics.Gauge;
- import com.codahale.metrics.JmxReporter;
- import com.codahale.metrics.MetricRegistry;
- import java.util.Queue;
- import java.util.concurrent.LinkedBlockingDeque;
- import java.util.concurrent.TimeUnit;
- /**
- * User: hzwangxx
- * Date: 14-2-17
- * Time: 14:47
- * 测试Gauges,实时统计pending状态的job个数
- */
- public class TestGauges {
- /**
- * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map
- */
- private static final MetricRegistry metrics = new MetricRegistry();
- private static Queue<String> queue = new LinkedBlockingDeque<String>();
- /**
- * 在控制台上打印输出
- */
- private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build();
- public static void main(String[] args) throws InterruptedException {
- reporter.start(3, TimeUnit.SECONDS);
- //实例化一个Gauge
- Gauge<Integer> gauge = new Gauge<Integer>() {
- @Override
- public Integer getValue() {
- return queue.size();
- }
- };
- //注册到容器中
- metrics.register(MetricRegistry.name(TestGauges.class, "pending-job", "size"), gauge);
- //测试JMX
- JmxReporter jmxReporter = JmxReporter.forRegistry(metrics).build();
- jmxReporter.start();
- //模拟数据
- for (int i=0; i<20; i++){
- queue.add("a");
- Thread.sleep(1000);
- }
- }
- }
- /*
- console output:
- 14-2-17 15:29:35 ===============================================================
- -- Gauges ----------------------------------------------------------------------
- com.netease.test.metrics.TestGauges.pending-job.size
- value = 4
- 14-2-17 15:29:38 ===============================================================
- -- Gauges ----------------------------------------------------------------------
- com.netease.test.metrics.TestGauges.pending-job.size
- value = 6
- 14-2-17 15:29:41 ===============================================================
- -- Gauges ----------------------------------------------------------------------
- com.netease.test.metrics.TestGauges.pending-job.size
- value = 9
- */
- JMX Gauges—提供给第三方库只通过JMX将指标暴露出来。
- Ratio Gauges—简单地通过创建一个gauge计算两个数的比值。
- Cached Gauges—对某些计量指标提供缓存
Derivative Gauges—提供Gauge的值是基于其他Gauge值的接口。
2. Counter
Counter是Gauge的一个特例,维护一个计数器,可以通过inc()和dec()方法对计数器做修改。使用步骤与Gauge基本类似,在MetricRegistry中提供了静态方法可以直接实例化一个Counter。
点击(此处)折叠或打开
- package com.netease.test.metrics;
- import com.codahale.metrics.ConsoleReporter;
- import com.codahale.metrics.Counter;
- import com.codahale.metrics.MetricRegistry;
- import java.util.LinkedList;
- import java.util.Queue;
- import java.util.concurrent.TimeUnit;
- import static com.codahale.metrics.MetricRegistry.*;
- /**
- * User: hzwangxx
- * Date: 14-2-14
- * Time: 14:02
- * 测试Counter
- */
- public class TestCounter {
- /**
- * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map
- */
- private static final MetricRegistry metrics = new MetricRegistry();
- /**
- * 在控制台上打印输出
- */
- private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build();
- /**
- * 实例化一个counter,同样可以通过如下方式进行实例化再注册进去
- * pendingJobs = new Counter();
- * metrics.register(MetricRegistry.name(TestCounter.class, "pending-jobs"), pendingJobs);
- */
- private static Counter pendingJobs = metrics.counter(name(TestCounter.class, "pedding-jobs"));
- // private static Counter pendingJobs = metrics.counter(MetricRegistry.name(TestCounter.class, "pedding-jobs"));
- private static Queue<String> queue = new LinkedList<String>();
- public static void add(String str) {
- pendingJobs.inc();
- queue.offer(str);
- }
- public String take() {
- pendingJobs.dec();
- return queue.poll();
- }
- public static void main(String[]args) throws InterruptedException {
- reporter.start(3, TimeUnit.SECONDS);
- while(true){
- add("1");
- Thread.sleep(1000);
- }
- }
- }
- /*
- console output:
- 14-2-17 17:52:34 ===============================================================
- -- Counters --------------------------------------------------------------------
- com.netease.test.metrics.TestCounter.pedding-jobs
- count = 4
- 14-2-17 17:52:37 ===============================================================
- -- Counters --------------------------------------------------------------------
- com.netease.test.metrics.TestCounter.pedding-jobs
- count = 6
- 14-2-17 17:52:40 ===============================================================
- -- Counters --------------------------------------------------------------------
- com.netease.test.metrics.TestCounter.pedding-jobs
- count = 9
- */
Meters用来度量某个时间段的平均处理次数(request per second),每1、5、15分钟的TPS。比如一个service的请求数,通过metrics.meter()实例化一个Meter之后,然后通过meter.mark()方法就能将本次请求记录下来。统计结果有总的请求数,平均每秒的请求数,以及最近的1、5、15分钟的平均TPS。
点击(此处)折叠或打开
- package com.netease.test.metrics;
- import com.codahale.metrics.ConsoleReporter;
- import com.codahale.metrics.Meter;
- import com.codahale.metrics.MetricRegistry;
- import java.util.concurrent.TimeUnit;
- import static com.codahale.metrics.MetricRegistry.*;
- /**
- * User: hzwangxx
- * Date: 14-2-17
- * Time: 18:34
- * 测试Meters
- */
- public class TestMeters {
- /**
- * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map
- */
- private static final MetricRegistry metrics = new MetricRegistry();
- /**
- * 在控制台上打印输出
- */
- private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build();
- /**
- * 实例化一个Meter
- */
- private static final Meter requests = metrics.meter(name(TestMeters.class, "request"));
- public static void handleRequest() {
- requests.mark();
- }
- public static void main(String[] args) throws InterruptedException {
- reporter.start(3, TimeUnit.SECONDS);
- while(true){
- handleRequest();
- Thread.sleep(100);
- }
- }
- }
- /*
- 14-2-17 18:43:08 ===============================================================
- -- Meters ----------------------------------------------------------------------
- com.netease.test.metrics.TestMeters.request
- count = 30
- mean rate = 9.95 events/second
- 1-minute rate = 0.00 events/second
- 5-minute rate = 0.00 events/second
- 15-minute rate = 0.00 events/second
- 14-2-17 18:43:11 ===============================================================
- -- Meters ----------------------------------------------------------------------
- com.netease.test.metrics.TestMeters.request
- count = 60
- mean rate = 9.99 events/second
- 1-minute rate = 10.00 events/second
- 5-minute rate = 10.00 events/second
- 15-minute rate = 10.00 events/second
- 14-2-17 18:43:14 ===============================================================
- -- Meters ----------------------------------------------------------------------
- com.netease.test.metrics.TestMeters.request
- count = 90
- mean rate = 9.99 events/second
- 1-minute rate = 10.00 events/second
- 5-minute rate = 10.00 events/second
- 15-minute rate = 10.00 events/second
- */
Histograms主要使用来统计数据的分布情况,最大值、最小值、平均值、中位数,百分比(75%、90%、95%、98%、99%和99.9%)。例如,需要统计某个页面的请求响应时间分布情况,可以使用该种类型的Metrics进行统计。具体的样例代码如下:
点击(此处)折叠或打开
- package com.netease.test.metrics;
- import com.codahale.metrics.ConsoleReporter;
- import com.codahale.metrics.Histogram;
- import com.codahale.metrics.MetricRegistry;
- import java.util.Random;
- import java.util.concurrent.TimeUnit;
- import static com.codahale.metrics.MetricRegistry.name;
- /**
- * User: hzwangxx
- * Date: 14-2-17
- * Time: 18:34
- * 测试Histograms
- */
- public class TestHistograms {
- /**
- * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map
- */
- private static final MetricRegistry metrics = new MetricRegistry();
- /**
- * 在控制台上打印输出
- */
- private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build();
- /**
- * 实例化一个Histograms
- */
- private static final Histogram randomNums = metrics.histogram(name(TestHistograms.class, "random"));
- public static void handleRequest(double random) {
- randomNums.update((int) (random*100));
- }
- public static void main(String[] args) throws InterruptedException {
- reporter.start(3, TimeUnit.SECONDS);
- Random rand = new Random();
- while(true){
- handleRequest(rand.nextDouble());
- Thread.sleep(100);
- }
- }
- }
- /*
- 14-2-17 19:39:11 ===============================================================
- -- Histograms ------------------------------------------------------------------
- com.netease.test.metrics.TestHistograms.random
- count = 30
- min = 1
- max = 97
- mean = 45.93
- stddev = 29.12
- median = 39.50
- 75% <= 71.00
- 95% <= 95.90
- 98% <= 97.00
- 99% <= 97.00
- 99.9% <= 97.00
- 14-2-17 19:39:14 ===============================================================
- -- Histograms ------------------------------------------------------------------
- com.netease.test.metrics.TestHistograms.random
- count = 60
- min = 0
- max = 97
- mean = 41.17
- stddev = 28.60
- median = 34.50
- 75% <= 69.75
- 95% <= 92.90
- 98% <= 96.56
- 99% <= 97.00
- 99.9% <= 97.00
- 14-2-17 19:39:17 ===============================================================
- -- Histograms ------------------------------------------------------------------
- com.netease.test.metrics.TestHistograms.random
- count = 90
- min = 0
- max = 97
- mean = 44.67
- stddev = 28.47
- median = 43.00
- 75% <= 71.00
- 95% <= 91.90
- 98% <= 96.18
- 99% <= 97.00
- 99.9% <= 97.00
- */
5. Timers
Timers主要是用来统计某一块代码段的执行时间以及其分布情况,具体是基于Histograms和Meters来实现的。样例代码如下:
点击(此处)折叠或打开
- package com.netease.test.metrics;
- import com.codahale.metrics.ConsoleReporter;
- import com.codahale.metrics.MetricRegistry;
- import com.codahale.metrics.Timer;
- import java.util.Random;
- import java.util.concurrent.TimeUnit;
- import static com.codahale.metrics.MetricRegistry.name;
- /**
- * User: hzwangxx
- * Date: 14-2-17
- * Time: 18:34
- * 测试Timers
- */
- public class TestTimers {
- /**
- * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map
- */
- private static final MetricRegistry metrics = new MetricRegistry();
- /**
- * 在控制台上打印输出
- */
- private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build();
- /**
- * 实例化一个Meter
- */
- // private static final Timer requests = metrics.timer(name(TestTimers.class, "request"));
- private static final Timer requests = metrics.timer(name(TestTimers.class, "request"));
- public static void handleRequest(int sleep) {
- Timer.Context context = requests.time();
- try {
- //some operator
- Thread.sleep(sleep);
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- context.stop();
- }
- }
- public static void main(String[] args) throws InterruptedException {
- reporter.start(3, TimeUnit.SECONDS);
- Random random = new Random();
- while(true){
- handleRequest(random.nextInt(1000));
- }
- }
- }
- /*
- 14-2-18 9:31:54 ================================================================
- -- Timers ----------------------------------------------------------------------
- com.netease.test.metrics.TestTimers.request
- count = 4
- mean rate = 1.33 calls/second
- 1-minute rate = 0.00 calls/second
- 5-minute rate = 0.00 calls/second
- 15-minute rate = 0.00 calls/second
- min = 483.07 milliseconds
- max = 901.92 milliseconds
- mean = 612.64 milliseconds
- stddev = 196.32 milliseconds
- median = 532.79 milliseconds
- 75% <= 818.31 milliseconds
- 95% <= 901.92 milliseconds
- 98% <= 901.92 milliseconds
- 99% <= 901.92 milliseconds
- 99.9% <= 901.92 milliseconds
- 14-2-18 9:31:57 ================================================================
- -- Timers ----------------------------------------------------------------------
- com.netease.test.metrics.TestTimers.request
- count = 8
- mean rate = 1.33 calls/second
- 1-minute rate = 1.40 calls/second
- 5-minute rate = 1.40 calls/second
- 15-minute rate = 1.40 calls/second
- min = 41.07 milliseconds
- max = 968.19 milliseconds
- mean = 639.50 milliseconds
- stddev = 306.12 milliseconds
- median = 692.77 milliseconds
- 75% <= 885.96 milliseconds
- 95% <= 968.19 milliseconds
- 98% <= 968.19 milliseconds
- 99% <= 968.19 milliseconds
- 99.9% <= 968.19 milliseconds
- 14-2-18 9:32:00 ================================================================
- -- Timers ----------------------------------------------------------------------
- com.netease.test.metrics.TestTimers.request
- count = 15
- mean rate = 1.67 calls/second
- 1-minute rate = 1.40 calls/second
- 5-minute rate = 1.40 calls/second
- 15-minute rate = 1.40 calls/second
- min = 41.07 milliseconds
- max = 968.19 milliseconds
- mean = 591.35 milliseconds
- stddev = 302.96 milliseconds
- median = 650.56 milliseconds
- 75% <= 838.07 milliseconds
- 95% <= 968.19 milliseconds
- 98% <= 968.19 milliseconds
- 99% <= 968.19 milliseconds
- 99.9% <= 968.19 milliseconds
- */
Metrics提供了一个独立的模块:Health Checks,用于对Application、其子模块或者关联模块的运行是否正常做检测。该模块是独立metrics-core模块的,使用时则导入metrics-healthchecks包。
<dependency> <groupId>com.codahale.metrics</groupId> <artifactId>metrics-healthchecks</artifactId> <version>3.0.1</version> </dependency>
使用起来和与上述几种类型的Metrics有点类似,但是需要重新实例化一个Metrics容器HealthCheckRegistry,待检测模块继承抽象类HealthCheck并实现check()方法即可,然后将该模块注册到HealthCheckRegistry中,判断的时候通过isHealthy()接口即可。如下示例代码:
点击(此处)折叠或打开
- package com.netease.test.metrics;
- import com.codahale.metrics.health.HealthCheck;
- import com.codahale.metrics.health.HealthCheckRegistry;
- import java.util.Map;
- import java.util.Random;
- /**
- * User: hzwangxx
- * Date: 14-2-18
- * Time: 9:57
- */
- public class DatabaseHealthCheck extends HealthCheck{
- private final Database database;
- public DatabaseHealthCheck(Database database) {
- this.database = database;
- }
- @Override
- protected Result check() throws Exception {
- if (database.ping()) {
- return Result.healthy();
- }
- return Result.unhealthy("Can't ping database.");
- }
- /**
- * 模拟Database对象
- */
- static class Database {
- /**
- * 模拟database的ping方法
- * @return 随机返回boolean值
- */
- public boolean ping() {
- Random random = new Random();
- return random.nextBoolean();
- }
- }
- public static void main(String[] args) {
- // MetricRegistry metrics = new MetricRegistry();
- // ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build();
- HealthCheckRegistry registry = new HealthCheckRegistry();
- registry.register("database1", new DatabaseHealthCheck(new Database()));
- registry.register("database2", new DatabaseHealthCheck(new Database()));
- while (true) {
- for (Map.Entry<String, Result> entry : registry.runHealthChecks().entrySet()) {
- if (entry.getValue().isHealthy()) {
- System.out.println(entry.getKey() + ": OK");
- } else {
- System.err.println(entry.getKey() + ": FAIL, error message: " + entry.getValue().getMessage());
- final Throwable e = entry.getValue().getError();
- if (e != null) {
- e.printStackTrace();
- }
- }
- }
- try {
- Thread.sleep(1000);
- } catch (InterruptedException e) {
- }
- }
- }
- }
- /*
- console output:
- database1: OK
- database2: FAIL, error message: Can't ping database.
- database1: FAIL, error message: Can't ping database.
- database2: OK
- database1: OK
- database2: FAIL, error message: Can't ping database.
- database1: FAIL, error message: Can't ping database.
- database2: OK
- database1: FAIL, error message: Can't ping database.
- database2: FAIL, error message: Can't ping database.
- database1: FAIL, error message: Can't ping database.
- database2: FAIL, error message: Can't ping database.
- database1: OK
- database2: OK
- database1: OK
- database2: FAIL, error message: Can't ping database.
- database1: FAIL, error message: Can't ping database.
- database2: OK
- database1: OK
- database2: OK
- database1: FAIL, error message: Can't ping database.
- database2: OK
- database1: OK
- database2: OK
- database1: OK
- database2: OK
- database1: OK
- database2: FAIL, error message: Can't ping database.
- database1: FAIL, error message: Can't ping database.
- database2: FAIL, error message: Can't ping database.
- */
metrics提供了对Ehcache、Apache HttpClient、JDBI、Jersey、Jetty、Log4J、Logback、JVM等的集成,可以方便地将Metrics输出到Ganglia、Graphite中,供用户图形化展示。
如何使用百度云下载电影等热门资源 - 忘我的追寻
对于喜欢观看高清电影的同学来说,在线视频网站的影片清晰质量是难以满足要求的,一个高效稳定的下载工具是必备看片神器。P2P提供了强大的资源分享机制,在那个服务器资源匮乏的网络时代,P2P起到了极大的作用,但是到了云时代,更加稳定的云端资源存放分享比P2P下载提供了更加可靠和稳定的下载源:所有的资源都保存在云盘提供商的云服务端,永不下线,不限下载速度。可以预见,P2P会逐渐被云替代。
一般而言,热门资源在百度网盘上面早就已经有了,离线下载只是将该资源关联到用户的账号上面而已。因此提交了离线下载任务后,很快就会在当前目录下看到需要的资源了。然后通过云管家下载到本地,由于百度云的服务器稳定,单线程的下载就足以跑满所有带宽了。再也不用担心P2P方式下载时网络连接过多,有效连接少导致下载速度慢的问题了。
1、准备工作1:登录云盘,申请百度云账号。
2、准备工作2:下载安装百度云管家。也有移动应用版本,各个应用商店均有。
3、找到需要下载的资源的BT种子文件:Bittorrent种子文件、磁力链接、ed2k,甚至是http和ftp地址也可以。一般都是去BT天堂和电影天堂论坛下载种子文件。
4、上传种子文件:

如上图,将torrent格式的文件上传到网盘的指定目录下。然后点击该文件,会自动创建离线下载任务。单击“离线下载”,可以查看下载进度。
也可以通过“离线下载”窗口直接粘帖种子文件路径,磁力链接和ed2k链接来新建下载任务。

5、这些操作也可以直接在百度云盘点客户端百度云管家上面操作。
6、百度云也提供在线播放视频的功能。可以不用下载到本地,直接在线观看。
MySQL性能优化的最佳经验,随时补充 - 简书
1、为查询优化你的查询
大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的。因为,我们某些查询语句会让MySQL不使用缓存。请看下面的示例:
// 查询缓存不开启 $r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()"); // 开启查询缓存 $today = date("Y-m-d"); $r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");上面两条SQL语句的差别就是 CURDATE() ,MySQL的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而开启缓存。
2、EXPLAIN 你的SELECT查询
使用EXPLAIN关键字可以让你知道MySQL是如何处理你的SQL语句的。
有表关联的查询,如下列:
select username, group_name from users u joins groups g on (u.group_id = g.id)发现查询缓慢,然后在group_id字段上增加索引,则会加快查询
3、当只要一行数据时使用LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,单因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上LIMIT 1 可以增加性能。这样一样, MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查找下一条符合记录的数据。
下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1)
// 没有效率的: $r = mysql_query("SELECT * FROM user WHERE country = 'China'"); if (mysql_num_rows($r) > 0) { // ... } // 有效率的: $r = mysql_query("SELECT 1 FROM user WHERE country = 'China' LIMIT 1"); if (mysql_num_rows($r) > 0) { // ... }4、为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。5、在Join表的时候使用相当类型的列,并将其索引
如果你的应用程序有很多JOIN查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。 而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把DECIMAL字段和一个INT字段JOIN在一起,MYSQL就无法使用他们的索引。对于那些STRING类型,还需要有相同的字符集才行(两个表的字符集有可能不一样)6、千万不要ORDER BY RAND()
7、避免SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。
所以,你应该养成一个需要什么就取什么的好的习惯。
// 不推荐 $r = mysql_query("SELECT * FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welcome {$d['username']}"; // 推荐 $r = mysql_query("SELECT username FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welcome {$d['username']}";8、永远为两张表设置一个ID
我们应该为数据库里的每张表都设置一个ID作为其主键,而最好的是一个INT型(推荐使用UNSIGNED),并设置上自动增长的AUTO INCREMENT标志。 就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的ID来构造你的数据结构。而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区……
9、使用 ENUM 而不是 VARCHAR ?
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
10、从 PROCEDURE ANALYSE() 取得建议 ?
PROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。
例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成 MEDIUMINT 。或是你使用了一个 VARCHAR 字段,因为数据不多,你可能会得到一个让你把它改成 ENUM 的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。
11、尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!)
不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
下面摘自MySQL自己的文档
“NULL columns require additional space in the row to record whether their values are NULL. For MyISAM tables, each NULL column takes one bit extra, rounded up to the nearest byte.”
12、把IP地址存成 UNSIGNED INT
很多程序员都会创建一个 VARCHAR(15) 字段来存放字符串形式的IP而不是整形的IP。如果你用整形来存放,只需要4个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当你需要使用这样的WHERE条件:IP between ip1 and ip2。我们必需要使用UNSIGNED INT,因为 IP地址会使用整个32位的无符号整形
13、固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
14、垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。(以前,在银行做过项目,见过一张表有100多个字段,很恐怖)
示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改写这个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有好的性能。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。
15、拆分大的 DELETE 或 INSERT 语句
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊WEB服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。下面是一个示例:
while (1) { //每次只做1000条 mysql_query("DELETE FROM logs WHERE log_date <= '2009-11-01' LIMIT 1000"); if (mysql_affected_rows() == 0) { // 没得可删了,退出! break; } // 每次都要休息一会儿 usleep(50000);}
16、 越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
参看 MySQL 的文档 Storage Requirements 查看所有的数据类型。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009年11月06日),一个简单的ALTER TABLE语句花了3个多小时,因为里面有一千六百万条数据。
17、选择一个正确的存储引擎
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。酷壳以前文章《MySQL: InnoDB 还是 MyISAM?》讨论和这个事情。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
18、小心“永久链接”
“永久链接”的目的是用来减少重新创建MySQL链接的次数。当一个链接被创建了,它会永远处在连接的状态,就算是数据库操作已经结束了。而且,自从我们的Apache开始重用它的子进程后——也就是说,下一次的HTTP请求会重用Apache的子进程,并重用相同的 MySQL 链接。
PHP手册:mysql_pconnect()
在理论上来说,这听起来非常的不错。但是从个人经验(也是大多数人的)上来说,这个功能制造出来的麻烦事更多。因为,你只有有限的链接数,内存问题,文件句柄数,等等。
而且,Apache 运行在极端并行的环境中,会创建很多很多的了进程。这就是为什么这种“永久链接”的机制工作地不好的原因。在你决定要使用“永久链接”之前,你需要好好地考虑一下你的整个系统的架构。
参考
19、当查询较慢的时候,可用Join来改写一下该查询来进行优化
mysql> select sql_no_cache * from guang_deal_outs where deal_id in (select id from guang_deals where id = 100017151) ; Empty set (18.87 sec) mysql> select sql_no_cache a.* from guang_deal_outs a inner join guang_deals b on a.deal_id = b.id where b.id = 100017151; Empty set (0.01 sec) 原因 mysql> desc select sql_no_cache * from guang_deal_outs where deal_id in (select id from guang_deals where id = 100017151) ; +----+--------------------+-----------------+-------+---------------+---------+---------+-------+----------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+--------------------+-----------------+-------+---------------+--------- +---------+-------+----------+-------------+ | 1 | PRIMARY | guang_deal_outs | ALL | NULL | NULL | NULL | NULL | 18633779 | Using where | | 2 | DEPENDENT SUBQUERY | guang_deals | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index | +----+--------------------+-----------------+-------+---------------+--------- +---------+-------+----------+-------------+ 2 rows in set (0.04 sec) mysql> desc select sql_no_cache a.* from guang_deal_outs a inner join guang_deals b on a.deal_id = b.id where b.id = 100017151; +----+-------------+-------+-------+---------------------- +----------------------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------------- +----------------------+---------+-------+------+-------------+ | 1 | SIMPLE | b | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index | | 1 | SIMPLE | a | ref | idx_guang_dlout_dlid | idx_guang_dlout_dlid | 4 | const | 1 | | +----+-------------+-------+-------+---------------------- +----------------------+---------+-------+------+-------------+ 2 rows in set (0.05 sec)其实在 guang_deal_outs 在deal_id 上也是有索引的。
其实我想把子查询设置为
select * from guang_deal_outs where deal_id in (select id from guang_deals where id = 100017151);变成下面的样子
select * from guang_deal_outs where deal_id in (100017151);但不幸的是,实际情况正好相反。MySQL试图让它和外面的表产生联系来“帮助”优化查询,它认为下面的exists形式更有效率
select * from guang_deal_outs where exists (select * from guang_deals where id = 100017151 and id = guang_deal_outs.deal_id);这种in子查询的形式,在外部表(比如上面的guang_deals)数据量比较大的时候效率是很差的(如果对于较小的表,不会造成显著地影响)
参考:
http://codingstandards.iteye.com/blog/1344833
http://coolshell.cn/articles/1846.html
http://hi.baidu.com/yzx110/item/74892ab6fc4601a5eaba93e1
arcgis api for flex 开发入门(一)环境搭建 - 温景良(Jason) - 博客园
arcgis api for flex 是arcgis 今年四月新推出来的进行RIA开发的flex库,是arcgis server9.3的一部分,使用 ArcGIS API for Flex可以基于ArcGIS Server建立漂亮的富互联网应用程序 rich internet applications (RIAs) ,优点是运行速度快,用户体验效果会比目前的WEBGIS好。
使用arcgis api for flex 可以达到下面的效果
1,显示你的地图数据并可以和数据交互
2,在服务器上执行空间处理模型并显示结果
3,基于ArcGIS Online上的底图显示你自己的数据
4,根据属性或者位置查找你的数据并显示结果
5,查找地址并显示结果
6,用创新的方式可视化结果
7,创建mashups
具体详情可以参考http://resources.esri.com/arcgisserver/apis/flex/index.cfm?fa=samples上面有一些例子。
arcgis api for flex 下载地址为
http://resources.esri.com/arcgisserver/apis/flex/index.cfm?fa=home
里面有个download。
开发arcgis api for flex 的程序需要flex 环境的支持。
flex sdk3 的下载地址为
http://opensource.adobe.com/wiki/display/flexsdk/download?build=3.0.1.2012&pkgtype=1
有了flex sdk3 和arcgis api for flex 我们就可以开发RIA的flex 程序了。
为了开发方便,我们最好使用flex builder,可以从adobe 的官方网站上下载试用版,下载地址为http://download.macromedia.com/pub/flex/flex_builder/FB3_win.exe
安装好flex builder之后会安装flex sdk3 ,所以就不用自己手工安装了。
第一个arcgis api for flex程序。
1,打开flex builder,创建一个flex 工程(名称Demo)。
2,右键单击工程名,选择属性,在属性对话框中选择flex build path ,选择libaray path选项卡,单击add swc 把下载的arcgis api for flex添加进去,环境就配置好了。

3 ,在Demo.mxml文件中输入下面这代码
- <?xml version="1.0" encoding="utf-8"?>
- <mx:Application
- xmlns:mx="http://www.adobe.com/2006/mxml"
- xmlns:esri="http://www.esri.com/2008/ags"
- pageTitle="Using ArcGIS API for Flex to connect to a cached ArcGIS Online service"
- styleName="plain">
- <esri:Map crosshairVisible="true">
- <esri:ArcGISTiledMapServiceLayer
- url="http://server.arcgisonline.com/ArcGIS/rest/services/ESRI_StreetMap_World_2D/MapServer" />
- </esri:Map>
- </mx:Application>
编译,执行。第一个简单的ags flex程序就写好了。
效果如图2
