App Store排名算法和Google Play排名算法
App Store:
有下面这样一张图:
图片的意思是:
今天的排名=今天的下载量x8 + 昨天的下载量x5 + 前天的下载量x5 + 大前天的下载量x2。 很明显,前3天的下载量是最重要的核心排名因素。
下载量永远都会是APP store算法的核心
想想sotre最容易得到的,最直观体现用户对APP喜爱程度的因素是什么——下载量。也许今天很多人认为几次算法更新后,下载量所占算法权重越来越低,但这个核心数据在算法中的比重绝对会是第一位的。
哪些因素可能被app store排名算法因素?
下面这些是我认为会影响第二天排名的一些因素,我以重要程度进行了排序:
1. 下载量:这个谁都懂;
2. 好评比例:今天有多少好评,好评占总评论量多少,这个也是可以当天获得的数据。
3. 当天卸载率:这个数据itunes官方也很容易得到。
4. 当天用户对该APP的使用时长。
5. 用户下载及好评用的IP地址:这会影响APP所在地区的排名。
用户活跃度因素不会是APP排名的重要因素
APPYING认为采集APP活跃度是需要一个时间段的过程,这样采集起来技术上绝对可行,但如果把这个作为app store排名的重要因素,那会更大的降低新APP获得好排名的机会。
Google Play:
指标A=“总安装/总下载”,即下载转安装的转换率;B=“评分/5”,即产品得分比上Market的满分;C=“留存安装/总安装”,即安装的留存率。不要急着问我a、b、c等于多少,准确数值只有Google知道、而且可以调,我只能告诉你它们加起来等于100,还有就是b>max(a,c)
「热门付费项目」、「热门免费项目」,是依照Google Play的新用户安装数来计算,而「最卖座排行榜」则是以依照实际营收来计算。至于「最新热门付费」、「最新热门免费」则是以Google Play旧用户的安装数为主,而且计算周期以「上架后30天内」为主。Ankit Jain说,上架日是以全球上架日(Global Publish Date)为主,因此在单一国家上架后,若逐步推展到其他国家,即便在某国一夕爆红,但是因为超过上架日30天的范围,所以并不会出现在「最新热门」之列。
另外,Ankit Jain也说,常有人问他「我的APP下载量明明比别一款APP多,为什么排名在它后面?」,这是因为Google Play其实不只看安装数,同时也会查看「卸载数」,并且计算两者的比例,当许多用户安装后却又移除,就会影响排名。
除了排行榜之外,Ankit Jain建议开发者可以留意Google Play几个推荐的方式,例如「热门应用程序」(Trending)指的是上架后成长率超过Google Play预期的,就会被列为热门。
分类相关、字词相关、功能相关的APP会被归类在一起呈现,举例来说当用户安装了一个时钟Widget,也许会另外安装其他的Widget。
BOSS系统_通信百科
目前国内还处在BOSS建设的初级阶段,首先能做到的是将业务流程中某个环节中的不同业务进行纵向整合,如帐务管理中的长话、市话、数据各部分的整合,以及服务不同业务的综合客服系统。因为中国移动业务比较单一,所以启动BOSS相对较早,中国联通也有类似的系统,但不叫BOSS,其他如中国网通、中国电信也将会有类似的系统,但建设起来会更加困难。今后的横向整合则使营业、帐务、客户关系以及针对管理层的决策支持各部分共同形成一个有机的整体,将会提高一个电信企业的运营效率。
一般把BOSS系统划分成四个部分:计费及结算系统、营业与账务系统、客户服务系统和决策支持系统。
boss是业务操作支撑系统的简称。BOSS的组成包括:
1.计费及结算系统
狭义的计费系统是指处理计费数据采集和批价两个过程的系统。计费数据采集工作包括计算机从电信基础网络(如交换机、网关等)上收集有关的原始基础数据和信息,进行相应的差错检验,格式转换等预处理,生成的结果只记录了用户使用网络(如通话)的情况,并不体现应向用户收取的费用。而批价的动作则是根据既定的原则和规则,对用户使用网络的情况计算费用。
结算系统是电信企业间的行为,它包括两种情况:一种称为漫游结算,另一种称为互联结算。当互联结算发生在两个甚至多个网络之间时,称为网间结算。结算的流程本身比较复杂,再加上数据量很大,出现得比较晚,使结算系统逐渐区别于传统的计费系统,成为业务运营支撑系统相对独立的组成部分。
2.营业、账务系统
营业系统通常完成的是受理和处理用户的业务请求,而帐务系统是将用户使用电信网络的情况汇总形成帐单。这两个过程在以往是比较单调的,但随着个性化服务的需求越来越强烈,要求系统实现功能的数量越来越多,越来越复杂,建设相对独立、灵活的营业系统和帐务系统的呼声也越来越高。
帐务系统要充分满足客户化的帐务要求。支持灵活,多途径的收费功能,满足客户个性化的帐单及其详细话单,并支持多样化的帐单分发方式;提供强大灵活的客户信用度的管理,完善恶意消费控制和欺诈控制;对市场变化做出迅速反映,方便地支持新品牌、新的资费套餐及其新的服务手段的推出。
3.客户服务系统
客户服务系统原来指的是企业的服务热线,如中国电信的"1000"和中国联通的"1001"等,但随着发展,客户服务系统有了全新的定义和功能。客户服务系统一方面能保证为客户提供快速方便的服务;另一方面保证在未来新业务开放的情况下,系统能及时提供相应的功能保证。从更高的角度来看,客户服务系统要实现多元化服务、个性化服务、交互式服务、异地服务的要求。
多元化服务即系统能为客户提供多种的接入渠道,多项的使用功能,多样的服务项目;个性化服务即能识别客户身份,根据不同客户的要求和系统数据,提供不同的服务和相应的营销,实现准确的服务;交互式服务主要是改变以往只有被动接受客户要求的状况,通过主动地调查市场,与客户联系,了解客户需求提供主动的服务和营销,同时增加系统的客户参与功能,鼓励客户进行自助服务。
这部分与CRM的概念接近。北京电信大客户部总经理赵恒礼认为,CRM是BOSS的一部分;中国移动的宁宇也表示,中国移动现在建的CRM正是基于其BOSS系统。对于电信运营商来说,如何有效地抓住大客户是必须面对的问题,在市场上,保住一个老客户的成本要远远低于新发展一个客户;而且新发展客户的成色怎样,对企业的贡献多大,并不好衡量,因此必须建立一套比较好的CRM。
4.决策支持系统
决策支持系统的主要任务是通过动态、有选择性地采集和更新数据源的有效信息及企业处部相关信息,进行智能化地分析、处理、预测、模拟等,最终向各级决策管理者或专业人员提供及时、科学、有效的分析报告,做好信息、智力支持工作。
lucene实现自定义的评分 - 学习笔记 - 博客频道 - CSDN.NET
Lucene按一个或多个字段进行排序是基本的功能,但可能需要更高级的自定义排序功能,并通过调整得分。Lucene自定义排序调整打分方法,有下面几种:
1、在索引阶段设置Document Boost和Field Boost,提升文档或字段的排名,例如:
Document doc1 = new Document();
Field f1 = new Field("contents", "common hello hello", Field.Store.NO, Field.Index.ANALYZED);
doc1.add(f1);
doc1.setBoost(100);
writer.addDocument(doc1);
Document doc1 = new Document();
Field f1 = new Field("title", "common hello hello", Field.Store.NO, Field.Index.ANALYZED);
f1.setBoost(100);
doc1.add(f1);
writer.addDocument(doc1);
2、通过继承并实现自己的Similarity,覆盖方法float scorePayload(int docId, String fieldName, int start, int end, byte [] payload, int offset, int length)
class PayloadSimilarity extends DefaultSimilarity {
@Override
public float scorePayload(int docId, String fieldName, int start, int end, byte[] payload, int offset, int length) {
int isbold = BoldFilter.bytes2int(payload);
if(isbold == BoldFilter.IS_BOLD){
System.out.println("It is a bold char.");
return 10;
} else {
System.out.println("It is not a bold char.");
return 1;
}
}
}
4、继承并实现自定义CustomScoreProvider和CustomScoreQuery,对评分进行干预,影响排名排序,例如:
- package util;
- import java.io.IOException;
- import org.apache.lucene.index.IndexReader;
- import org.apache.lucene.index.Term;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.search.Query;
- import org.apache.lucene.search.TermQuery;
- import org.apache.lucene.search.TopDocs;
- import org.apache.lucene.search.function.CustomScoreProvider;
- import org.apache.lucene.search.function.CustomScoreQuery;
- import org.apache.lucene.search.function.FieldScoreQuery;
- import org.apache.lucene.search.function.ValueSourceQuery;
- import org.apache.lucene.search.function.FieldScoreQuery.Type;
- public class MyScoreQuery1{
- public void searchByScoreQuery() throws Exception{
- IndexSearcher searcher = DocUtil.getSearcher();
- Query query = new TermQuery(new Term("content","java"));
- //1、创建评分域,如果Type是String类型,那么是Type.BYTE
- //该域必须是数值型的,并且不能使用norms索引,以及每个文档中该域只能由一个语汇
- //单元,通常可用Field.Index.not_analyzer_no_norms来进行创建索引
- FieldScoreQuery fieldScoreQuery = new FieldScoreQuery("size",Type.INT);
- //2、根据评分域和原有的Query创建自定义的Query对象
- //query是原有的query,fieldScoreQuery是专门做评分的query
- MyCustomScoreQuery customQuery = new MyCustomScoreQuery(query, fieldScoreQuery);
- TopDocs topdoc = searcher.search(customQuery, 100);
- DocUtil.printDocument(topdoc, searcher);
- searcher.close();
- }
- @SuppressWarnings("serial")
- private class MyCustomScoreQuery extends CustomScoreQuery{
- public MyCustomScoreQuery(Query subQuery, ValueSourceQuery valSrcQuery) {
- super(subQuery, valSrcQuery);
- }
- /**
- * 这里的reader是针对段的,意思是如果索引包含的段不止一个,那么搜索期间会多次调用
- * 这个方法,强调这点是重要的,因为它使你的评分逻辑能够有效使用段reader来对域缓存
- * 中的值进行检索
- */
- @Override
- protected CustomScoreProvider getCustomScoreProvider(IndexReader reader)
- throws IOException {
- //默认情况实现的评分是通过原有的评分*传入进来的评分域所获取的评分来确定最终打分的
- //为了根据不同的需求进行评分,需要自己进行评分的设定
- /**
- * 自定评分的步骤
- * 创建一个类继承于CustomScoreProvider
- * 覆盖customScore方法
- */
- // return super.getCustomScoreProvider(reader);
- return new MyCustomScoreProvider(reader);
- }
- }
- private class MyCustomScoreProvider extends CustomScoreProvider{
- public MyCustomScoreProvider(IndexReader reader) {
- super(reader);
- }
- /**
- * subQueryScore表示默认文档的打分
- * valSrcScore表示的评分域的打分
- * 默认是subQueryScore*valSrcScore返回的
- */
- @Override
- public float customScore(int doc, float subQueryScore, float valSrcScore)throws IOException {
- System.out.println("Doc:"+doc);
- System.out.println("subQueryScore:"+subQueryScore);
- System.out.println("valSrcScore:"+valSrcScore);
- // return super.customScore(doc, subQueryScore, valSrcScore);
- return subQueryScore / valSrcScore;
- }
- }
- }
根据特定的几个文件名来评分,选中的文件名权重变大
- package util;
- import java.io.IOException;
- import org.apache.lucene.index.IndexReader;
- import org.apache.lucene.index.Term;
- import org.apache.lucene.search.FieldCache;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.search.Query;
- import org.apache.lucene.search.TermQuery;
- import org.apache.lucene.search.TopDocs;
- import org.apache.lucene.search.function.CustomScoreProvider;
- import org.apache.lucene.search.function.CustomScoreQuery;
- /**
- * 此类的功能是给特定的文件名加权,也就是加评分
- * 也可以实现搜索书籍的时候把近一两年的出版的图书给增加权重
- * @author user
- */
- public class MyScoreQuery2 {
- public void searchByFileScoreQuery() throws Exception{
- IndexSearcher searcher = DocUtil.getSearcher();
- Query query = new TermQuery(new Term("content","java"));
- FilenameScoreQuery fieldScoreQuery = new FilenameScoreQuery(query);
- TopDocs topdoc = searcher.search(fieldScoreQuery, 100);
- DocUtil.printDocument(topdoc, searcher);
- searcher.close();
- }
- @SuppressWarnings("serial")
- private class FilenameScoreQuery extends CustomScoreQuery{
- public FilenameScoreQuery(Query subQuery) {
- super(subQuery);
- }
- @Override
- protected CustomScoreProvider getCustomScoreProvider(IndexReader reader)
- throws IOException {
- // return super.getCustomScoreProvider(reader);
- return new FilenameScoreProvider(reader);
- }
- }
- private class FilenameScoreProvider extends CustomScoreProvider{
- String[] filenames = null;
- public FilenameScoreProvider(IndexReader reader) {
- super(reader);
- try {
- filenames = FieldCache.DEFAULT.getStrings(reader, "filename");
- } catch (IOException e) {e.printStackTrace();}
- }
- //如何根据doc获取相应的field的值
- /*
- * 在reader没有关闭之前,所有的数据会存储要一个域缓存中,可以通过域缓存获取很多有用
- * 的信息filenames = FieldCache.DEFAULT.getStrings(reader, "filename");可以获取
- * 所有的filename域的信息
- */
- @Override
- public float customScore(int doc, float subQueryScore, float valSrcScore)
- throws IOException {
- String fileName = filenames[doc];
- System.out.println(doc+":"+fileName);
- // return super.customScore(doc, subQueryScore, valSrcScore);
- if("9.txt".equals(fileName) || "4.txt".equals(fileName)) {
- return subQueryScore*1.5f;
- }
- return subQueryScore/1.5f;
- }
- }
- }
Lucene索引阶段设置Document Boost和Field Boost 实现合理打分 - 漫步天涯-IT - 博客频道 - CSDN.NET
在索引阶段设置Document Boost和Field Boost,存储在(.nrm)文件中。
如果希望某些文档和某些域比其他的域更重要,如果此文档和此域包含所要查询的词则应该得分较高,则可以在索引阶段设定文档的boost和域的boost值。
这些值是在索引阶段就写入索引文件的,存储在标准化因子(.nrm)文件中,一旦设定,除非删除此文档,否则无法改变。
如果不进行设定,则Document Boost和Field Boost默认为1。
Document Boost及FieldBoost的设定方式如下:
|
Document doc = new Document(); Field f = new Field("contents", "hello world", Field.Store.NO, Field.Index.ANALYZED); f.setBoost(100); doc.add(f); doc.setBoost(100); |
两者是如何影响Lucene的文档打分的呢?
让我们首先来看一下Lucene的文档打分的公式:
|
score(q,d) = coord(q,d) · queryNorm(q) · ∑( tf(t in d) · idf(t)2 · t.getBoost() · norm(t,d) ) t in q |
Document Boost和Field Boost影响的是norm(t, d),其公式如下:
|
norm(t,d) = field f in d named as t |
它包括三个参数:
- Document boost:此值越大,说明此文档越重要。
- Field boost:此域越大,说明此域越重要。
- lengthNorm(field) = (1.0 / Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大。
其中第三个参数可以在自己的Similarity中影响打分,下面会论述。
当然,也可以在添加Field的时候,设置Field.Index.ANALYZED_NO_NORMS或Field.Index.NOT_ANALYZED_NO_NORMS,完全不用norm,来节约空间。
根据Lucene的注释,No norms means that index-time field and document boosting and field length normalization are disabled. The benefit is less memory usage as norms take up one byte of RAM per indexed field for every document in the index, during searching. Note that once you index a given field with norms enabled, disabling norms will have no effect. 没有norms意味着索引阶段禁用了文档boost和域的boost及长度标准化。好处在于节省内存,不用在搜索阶段为索引中的每篇文档的每个域都占用一个字节来保存norms信息了。但是对norms信息的禁用是必须全部域都禁用的,一旦有一个域不禁用,则其他禁用的域也会存放默认的norms值。因为为了加快norms的搜索速度,Lucene是根据文档号乘以每篇文档的norms信息所占用的大小来计算偏移量的,中间少一篇文档,偏移量将无法计算。也即norms信息要么都保存,要么都不保存。
下面几个试验可以验证norms信息的作用:
试验一:Document Boost的作用
|
public void testNormsDocBoost() throws Exception { IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); |
如果第一篇文档的域f1也为Field.Index.ANALYZED_NO_NORMS的时候,搜索排名如下:
|
docid : 2 score : 1.2337708 |
如果第一篇文档的域f1设为Field.Index.ANALYZED,则搜索排名如下:
|
docid : 0 score : 39.889805 |
试验二:Field Boost的作用
如果我们觉得title要比contents要重要,可以做一下设定。
|
public void testNormsFieldBoost() throws Exception { IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); |
如果第一篇文档的域f1也为Field.Index.ANALYZED_NO_NORMS的时候,搜索排名如下:
|
docid : 1 score : 0.49999997 |
如果第一篇文档的域f1设为Field.Index.ANALYZED,则搜索排名如下:
|
docid : 0 score : 19.79899 |
试验三:norms中文档长度对打分的影响
|
public void testNormsLength() throws Exception { IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); |
当norms被禁用的时候,包含两个common的第二篇文档打分较高:
|
docid : 1 score : 0.13928263 |
当norms起作用的时候,虽然包含两个common的第二篇文档,由于长度较长,因而打分较低:
|
docid : 0 score : 0.09848769 |
试验四:norms信息要么都保存,要么都不保存的特性
|
public void testOmitNorms() throws Exception { |
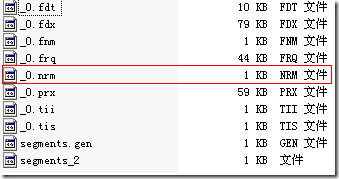
当我们添加10001篇文档,所有的文档都设为Field.Index.ANALYZED_NO_NORMS的时候,我们看索引文件,发现.nrm文件只有1K,也即其中除了保持一定的格式信息,并无其他数据。
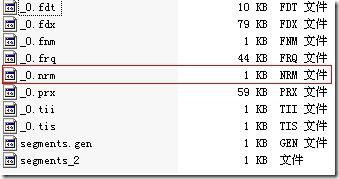
当我们把第一篇文档设为Field.Index.ANALYZED,而其他10000篇文档都设为Field.Index.ANALYZED_NO_NORMS的时候,发现.nrm文件又10K,也即所有的文档都存储了norms信息,而非只有第一篇文档。
在搜索语句中,设置Query Boost.
在搜索中,我们可以指定,某些词对我们来说更重要,我们可以设置这个词的boost:
common^4 hello |
使得包含common的文档比包含hello的文档获得更高的分数。
由于在Lucene中,一个Term定义为Field:Term,则也可以影响不同域的打分:
|
title:common^4 content:common |
使得title中包含common的文档比content中包含common的文档获得更高的分数。
实例:
|
public void testQueryBoost() throws Exception { IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); |
根据tf/idf,包含两个common2的第二篇文档打分较高:
|
docid : 1 score : 0.24999999 |
如果我们输入的查询语句为:"common1^100 common2",则第一篇文档打分较高:
|
docid : 0 score : 0.2499875 |
那Query Boost是如何影响文档打分的呢?
根据Lucene的打分计算公式:
|
score(q,d) = coord(q,d) · queryNorm(q) · ∑( tf(t in d) · idf(t)2 · t.getBoost() · norm(t,d) ) t in q |
注:在queryNorm的部分,也有q.getBoost()的部分,但是对query向量的归一化(见向量空间模型与Lucene的打分机制[http://forfuture1978.javaeye.com/blog/588721])。
继承并实现自己的Similarity
Similariy是计算Lucene打分的最主要的类,实现其中的很多借口可以干预打分的过程。
(1) float computeNorm(String field, FieldInvertState state)
(2) float lengthNorm(String fieldName, int numTokens)
(3) float queryNorm(float sumOfSquaredWeights)
(4) float tf(float freq)
(5) float idf(int docFreq, int numDocs)
(6) float coord(int overlap, int maxOverlap)
(7) float scorePayload(int docId, String fieldName, int start, int end, byte [] payload, int offset, int length)
它们分别影响Lucene打分计算的如下部分:
|
score(q,d) = (6)coord(q,d) · (3)queryNorm(q) · ∑( (4)tf(t in d) · (5)idf(t)2 · t.getBoost() · (1)norm(t,d) ) t in q |
|
norm(t,d) = field f in d named as t |
下面逐个进行解释:
(1) float computeNorm(String field, FieldInvertState state)
影响标准化因子的计算,如上述,他主要包含了三部分:文档boost,域boost,以及文档长度归一化。此函数一般按照上面norm(t, d)的公式进行计算。
(2) float lengthNorm(String fieldName, int numTokens)
主要计算文档长度的归一化,默认是1.0 / Math.sqrt(numTerms)。
因为在索引中,不同的文档长度不一样,很显然,对于任意一个term,在长的文档中的tf要大的多,因而分数也越高,这样对小的文档不公平,举一个极端的例子,在一篇1000万个词的鸿篇巨著中,"lucene"这个词出现了11次,而在一篇12个词的短小文档中,"lucene"这个词出现了10次,如果不考虑长度在内,当然鸿篇巨著应该分数更高,然而显然这篇小文档才是真正关注"lucene"的。
因而在此处是要除以文档的长度,从而减少因文档长度带来的打分不公。
然而现在这个公式是偏向于首先返回短小的文档的,这样在实际应用中使得搜索结果也很难看。
于是在实践中,要根据项目的需要,根据搜索的领域,改写lengthNorm的计算公式。比如我想做一个经济学论文的搜索系统,经过一定时间的调研,发现大多数的经济学论文的长度在8000到10000词,因而lengthNorm的公式应该是一个倒抛物线型的,8000到10000词的论文分数最高,更短或更长的分数都应该偏低,方能够返回给用户最好的数据。
(3) float queryNorm(float sumOfSquaredWeights)
这是按照向量空间模型,对query向量的归一化。此值并不影响排序,而仅仅使得不同的query之间的分数可以比较。
(4) float tf(float freq)
freq是指在一篇文档中包含的某个词的数目。tf是根据此数目给出的分数,默认为Math.sqrt(freq)。也即此项并不是随着包含的数目的增多而线性增加的。
(5) float idf(int docFreq, int numDocs)
idf是根据包含某个词的文档数以及总文档数计算出的分数,默认为(Math.log(numDocs/(double)(docFreq+1)) + 1.0)。
由于此项计算涉及到总文档数和包含此词的文档数,因而需要全局的文档数信息,这给跨索引搜索造成麻烦。
从下面的例子我们可以看出,用MultiSearcher来一起搜索两个索引和分别用IndexSearcher来搜索两个索引所得出的分数是有很大差异的。
究其原因是MultiSearcher的docFreq(Term term)函数计算了包含两个索引中包含此词的总文档数,而IndexSearcher仅仅计算了每个索引中包含此词的文档数。当两个索引包含的文档总数是有很大不同的时候,分数是无法比较的。
|
public void testMultiIndex() throws Exception{ |
|
结果为: ------------------------------- |
如果几个索引都是在一台机器上,则用MultiSearcher或者MultiReader就解决问题了,然而有时候索引是分布在多台机器上的,虽然Lucene也提供了RMI,或用NFS保存索引的方法,然而效率和并行性一直是一个问题。
一个可以尝试的办法是在Similarity中,idf返回1,然后多个机器上的索引并行搜索,在汇总结果的机器上,再融入idf的计算。
如下面的例子可以看出,当idf返回1的时候,打分可以比较了:
|
class MultiIndexSimilarity extends Similarity { @Override |
|
----------------------------- |
(6) float coord(int overlap, int maxOverlap)
一次搜索可能包含多个搜索词,而一篇文档中也可能包含多个搜索词,此项表示,当一篇文档中包含的搜索词越多,则此文档则打分越高。
|
public void TestCoord() throws Exception { IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); |
|
class MySimilarity extends Similarity { @Override } |
如上面的实例,当coord返回1,不起作用的时候,文档一虽然包含了两个搜索词common和world,但由于world的所在的文档数太多,而文档二包含common的次数比较多,因而文档二分数较高:
|
docid : 1 score : 1.9059997 |
而当coord起作用的时候,文档一由于包含了两个搜索词而分数较高:
|
class MySimilarity extends Similarity { @Override } |
|
docid : 0 score : 1.2936771 |
(7) float scorePayload(int docId, String fieldName, int start, int end, byte [] payload, int offset, int length)
由于Lucene引入了payload,因而可以存储一些自己的信息,用户可以根据自己存储的信息,来影响Lucene的打分。
由payload的定义我们知道,索引是以倒排表形式存储的,对于每一个词,都保存了包含这个词的一个链表,当然为了加快查询速度,此链表多用跳跃表进行存储。Payload信息就是存储在倒排表中的,同文档号一起存放,多用于存储与每篇文档相关的一些信息。当然这部分信息也可以存储域里(stored Field),两者从功能上基本是一样的,然而当要存储的信息很多的时候,存放在倒排表里,利用跳跃表,有利于大大提高搜索速度。
Payload的存储方式如下图:
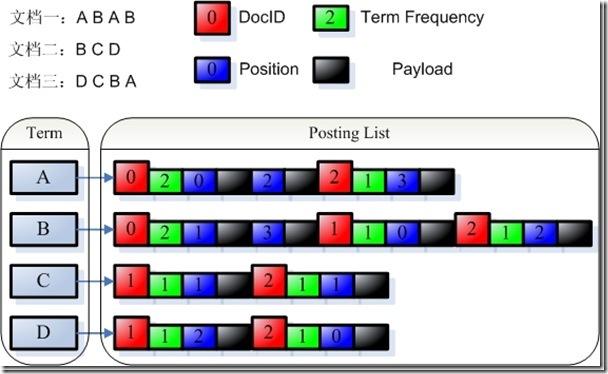
由payload的定义,我们可以看出,payload可以存储一些不但与文档相关,而且与查询词也相关的信息。比如某篇文档的某个词有特殊性,则可以在这个词的这个文档的position信息后存储payload信息,使得当搜索这个词的时候,这篇文档获得较高的分数。
要利用payload来影响查询需要做到以下几点,下面举例用<b></b>标记的词在payload中存储1,否则存储0:
首先要实现自己的Analyzer从而在Token中放入payload信息:
|
class BoldAnalyzer extends Analyzer { @Override } class BoldFilter extends TokenFilter { private TermAttribute termAtt; protected BoldFilter(TokenStream input) { @Override final char[] buffer = termAtt.termBuffer(); String tokenstring = new String(buffer, 0, length); public static int bytes2int(byte[] b) { public static byte[] int2bytes(int num) { } |
然后,实现自己的Similarity,从payload中读出信息,根据信息来打分。
|
class PayloadSimilarity extends DefaultSimilarity { @Override |
最后,查询的时候,一定要用PayloadXXXQuery(在此用PayloadTermQuery,在Lucene 2.4.1中,用BoostingTermQuery),否则scorePayload不起作用。
|
public void testPayloadScore() throws Exception { IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); |
如果scorePayload函数始终是返回1,则结果如下,<b></b>不起作用。
|
It is not a bold char. |
如果scorePayload函数如下:
|
class PayloadSimilarity extends DefaultSimilarity { @Override |
则结果如下,同样是包含hello,包含加粗的文档获得较高分:
|
It is not a bold char. |
继承并实现自己的collector
以上各种方法,已经把Lucene score计算公式的所有变量都涉及了,如果这还不能满足您的要求,还可以继承实现自己的collector。
在Lucene 2.4中,HitCollector有个函数public abstract void collect(int doc, float score),用来收集搜索的结果。
其中TopDocCollector的实现如下:
|
public void collect(int doc, float score) { |
此函数将docid和score插入一个PriorityQueue中,使得得分最高的文档先返回。
我们可以继承HitCollector,并在此函数中对score进行修改,然后再插入PriorityQueue,或者插入自己的数据结构。
比如我们在另外的地方存储docid和文档创建时间的对应,我们希望当文档时间是一天之内的分数最高,一周之内的分数其次,一个月之外的分数很低。
我们可以这样修改:
|
public static long milisecondsOneDay = 24L * 3600L * 1000L; public static long millisecondsOneWeek = 7L * 24L * 3600L * 1000L; public static long millisecondsOneMonth = 30L * 24L * 3600L * 1000L; public void collect(int doc, float score) { long time = getTimeByDocId(doc); if(time < milisecondsOneDay) { score = score * 1.0; } else if (time < millisecondsOneWeek){ score = score * 0.8; } else if (time < millisecondsOneMonth) { score = score * 0.3; } else { score = score * 0.1; } totalHits++; |
在Lucene 3.0中,Collector接口为void collect(int doc),TopScoreDocCollector实现如下:
|
public void collect(int doc) throws IOException { |
同样可以用上面的方式影响其打分。
lucene FieldCache 实现分组统计 - 记录我的点点滴滴 - 51CTO技术博客
- fieldCache中的字段值是从倒排表中读出来的,而不是从索引文件中存储的字段值,所以排序的字段必须是为设为索引字段
- 用来排序的字段在索引的时候不能拆分(tokenized),因为fieldCache数组中,每个文档只对应一个字段值,拆分的话,cache中只会保存在词典中靠后的值。
fieldcache是lucene最占用的内存的部分,大部分内存溢出的错误都是由它而起,需要特别注意。
分组统计可以借用fieldCache来高效率的实现。调用lucene进行查询,通过读取倒排表并进行boolean运算,得到一个满足条件的文档的集合。通过每个结果文档号读取fieldCache数组中的值,并分不同的值累加数目,即可实现分组统计的功能。其中,如果某个字段对应多值,则在索引的时候不拆分,从filedCache数组读出后,再进行拆分统计。
好了,说了半天,现在来看看实现代码:Test.java
import java.io.IOException;
import java.util.List;
import jeasy.analysis.MMAnalyzer;
import org.apache.lucene.analysis.PerFieldAnalyzerWrapper;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.FieldCache;
import org.apache.lucene.search.HBxx2Similarity;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.MatchAllDocsQuery;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Searcher;
import org.apache.lucene.search.TopDocsCollector;
import org.apache.lucene.search.TopScoreDocCollector;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.util.Version;
GroupField.java
GroupCollector.java
Lucene 搜索性能优化
搜索优化:
1、设置boost
有些时候在搜索时某个字段的权重需要大一些,例如你可能认为标题中出现关键词的文章比正文中出现关键词的文章更有价值,你可以把标题的boost设置的更大,那么搜索结果会优先显示标题中出现关键词的文章(没有使用排序的前题下)。使用方法:
Field. setBoost(float boost);默认值是1.0,也就是说要增加权重的需要设置得比1大。
2、将不需要使用范围查询的数字字段设置precisionstep为Intger.max,这样数字写入倒排仅存一个term,能极大降低term数量。
复制代码
1 public final class CustomFieldType {
2 public static final FieldType INT_TYPE_NOT_STORED_NO_TIRE = new FieldType();
3 static {
4 INT_TYPE_NOT_STORED_NO_TIRE.setIndexed(true);
5 INT_TYPE_NOT_STORED_NO_TIRE.setTokenized(true);
6 INT_TYPE_NOT_STORED_NO_TIRE.setOmitNorms(true);
7 INT_TYPE_NOT_STORED_NO_TIRE.setIndexOptions(FieldInfo.IndexOptions.DOCS_ONLY);
8 INT_TYPE_NOT_STORED_NO_TIRE.setNumericType(FieldType.NumericType.INT);
9 INT_TYPE_NOT_STORED_NO_TIRE.setNumericPrecisionStep(Integer.MAX_VALUE);
10 INT_TYPE_NOT_STORED_NO_TIRE.freeze();
11 }
12 }
复制代码
1
doc.add(new IntField("price", price, CustomFieldType.INT_TYPE_NOT_STORED_NO_TIRE));//人均消费
3、优化方法是只存储id等必须的字段,对于大部分字段我们只索引而不存储,通过这种方法,索引压缩文件降低了10%左右。
1 doc.add(new StringField("price", each, Field.Store.NO));
4、索引更新:indexWriter.updateDocument(new Term("id", "1"), doc);
5、lucene 3.5后删除了optimize(),将IndexWriter.optimize重命名为forceMerge,以便去阻止使用这种方法,因为它的使用代价较高,且也不需要使用
6、新版本的Lucene通常性能都会有些改善
7、使用更快的硬件,例如,改善IO系统性能
8、在建立索引过程中,使用单例的 Writer(注:应该是有有助于避免锁)
9、使用内存索引:
// 打开索引目录
File indexDir = new File(idxDir);
Directory directory = FSDirectory.open(indexDir);
Directory ramDir = new RAMDirectory(directory);
// 获取访问索引的接口,进行搜索
IndexReader indexReader = IndexReader.open(ramDir);
10、// TopDocs 提前返回搜索结果
TopDocs topDocs = indexSearcher.search(query, 100);// 只返回前100条记录
11、不需要highlight则可以将term vector关掉
12、业务能不能拆分, 比如之前音乐图书视频资讯和app一起做搜索, 可以考虑将他们分开
13、调整内存Xms和Xmx,采用多线程gc
14、在频繁更新索引的情况下,使用两个索引,一个大的优化好的历史索引,一个小的实时添加的索引
15、使用FieldSelector仔细的选择哪些字段需要获取,如何获取
Lucene-与索引库的交互 - 球球之家 - 博客频道 - CSDN.NET
内存索引库:数据是临时的、访问速度比文件索引库要快、索引库中的数据不能存放太多、内存索引库和文件索引库能结合在一起
两个或者两个以上的索引库的合并:
如果是内存索引库,直接调用构造函数进行合并就可以了 内存索引库中。也可以调用addIndexesNoOptimize进行合并
如果是文件索引库,调用addIndexesNoOptimize进行合并,该方法可以接受多个索引库
- /**
- * 文件索引库和内存索引库的结合
- */
- @Test
- public void testRamAndFile() throws Exception{
- /**
- * 1、当应用程序启动的时候,把文件索引库的内容复制到内存库中
- * 2、让内存索引库和应用程序交互
- * 3、把内存索引库的内容同步到文件索引库
- */
- Directory fileDirectory = FSDirectory.open(new File("./indexDir"));
- Directory ramDirectory = new RAMDirectory(fileDirectory);
- IndexWriter ramIndexWriter = new IndexWriter(ramDirectory,LuceneUtils.analyzer,MaxFieldLength.LIMITED);
- IndexWriter fileIndexWriter = new IndexWriter(fileDirectory,LuceneUtils.analyzer,true,MaxFieldLength.LIMITED);
- /**
- * 在内存索引库中根据关键词查询
- */
- this.showData(ramDirectory);
- System.out.println("上面的是从内存索引库中查询出来的");
- /**
- * 把一条信息插入到内存索引库
- */
- Article article = new Article();
- article.setId(1L);
- article.setTitle("lucene可以做搜索引擎");
- article.setContent("baidu,google都是很好的搜索引擎");
- ramIndexWriter.addDocument(DocumentUtils.article2Document(article));
- ramIndexWriter.close();
- /*
- * 把内存索引库中的内容同步到文件索引库中
- */
- fileIndexWriter.addIndexesNoOptimize(ramDirectory);
- fileIndexWriter.close();
- this.showData(fileDirectory);
- System.out.println("上面的是从文件索引库中查询出来的");
记录Presto数据查询引擎的配置过程 - 夜丶帝 - 博客园
配置准备:
1、centos6.4系统的虚拟机4个(master、secondary、node1、node2)
2、准备安装包
hadoop-cdh4.4.0、hive-cdh4.4.0、presto、discovery-server、hbase、JDK7.0+64bit、pythin2.4+、postgresql
注:Ssh 权限配置问题:
用户目录权限为 755 或者 700就是不能是77x
.ssh目录权限必须为755
rsa_id.pub 及authorized_keys权限必须为644
rsa_id权限必须为600
最后,在master中测试:ssh master date、ssh secondary date、ssh node1 date、ssh node2 date 不需要密码,则成功。
如果ssh secondary 、ssh node1、ssh node2 连接速度慢,需要更改/etc/ssh/ssh_config 为GSSAPIAuthentication no
修改root的ssh权限,/etc/ssh/sshd_config,将PermitRootLogin no 改为yes
重启sshd服务:/etc/init.d/sshd restrat
5、配置环境变量
[root@master~]# gedit .bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
export JAVA_HOME=/usr/java/jdk1.7.0_45
export JRE_HOME=$JAVA_HOME/jre
export CLASS_PATH=./:$JAVA_HOME/lib:$JRE_HOME/lib:$JRE_HOME/lib/tools.jar:/usr/presto/server/lib:/usr/discovery-server/lib
export HADOOP_HOME=/usr/hadoop
export HIVE_HOME=/usr/hive
export HBASE_HOME=/usr/hbase
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin
master环境变量配置好后,secondary、node1和node2同样配置,可以使用scp命令同步到secondary、node1和node2中
6、配置hadoop

<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--fs.default.name for MRV1 ,fs.defaultFS for MRV2(yarn) --> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> <property> <name>fs.trash.interval</name> <value>10080</value> </property> <property> <name>fs.trash.checkpoint.interval</name> <value>10080</value> </property> </configuration>
c、hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/hadoop-${user.name}</value> </property> <property> <name>dfs.namenode.http-address</name> <value>master:50070</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>secondary:50090</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
d、masters(没有则创建该文件)
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
g、yarn-site.xml
<?xml version="1.0"?> <configuration> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> <property> <description>Classpath for typical applications.</description> <name>yarn.application.classpath</name> <value>$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*, $HADOOP_COMMON_HOME/share/hadoop/common/lib/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*, $YARN_HOME/share/hadoop/yarn/*,$YARN_HOME/share/hadoop/yarn/lib/*, $YARN_HOME/share/hadoop/mapreduce/*,$YARN_HOME/share/hadoop/mapreduce/lib/*</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce.shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/opt/data/yarn/local</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/opt/data/yarn/logs</value> </property> <property> <description>Where to aggregate logs</description> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/opt/data/yarn/logs</value> </property> <property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/user</value> </property> </configuration>
h、复制hadoop到secondary、node1和node2
i、hadoop第一次运行需要先格式化,命令如下:[root@tamaster hadoop]hadoop namenode -format
j、关闭hadoop安全模式,命令如下:hdfs dfsadmin -safemode leave
k、运行hadoop,命令: [root@tamaster:~]start-all.sh
master
secondary
node1
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://master/hbase-${user.name}</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.tmp.dir</name> <value>/opt/data/hbase-${user.name}</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,secondary,node1,node2</value> </property> </configuration>
d、将hbase同步到secondary、node1、node2中
e、启动hbase,命令如下:
[root@master:~]# start-hbase.sh
8、安装hive
a、下载hive压缩包,并将其解压到/usr,即:/usr/hive
b、hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:postgresql://master/testdb</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>org.postgresql.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hiveuser</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>redhat</value> <description>password to use against metastore database</description> </property> <property> <name>mapred.job.tracker</name> <value>master:8031</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>hive.aux.jars.path</name> <value>file:///usr/hive/lib/zookeeper-3.4.5-cdh4.4.0.jar, file:///usr/hive/lib/hive-hbase-handler-0.10.0-cdh4.4.0.jar, file:///usr/hive/lib/hbase-0.94.2-cdh4.4.0.jar, file:///usr/hive/lib/guava-11.0.2.jar</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/opt/data/warehouse-${user.name}</value> <description>location of default database for the warehouse</description> </property> <property> <name>hive.exec.scratchdir</name> <value>/opt/data/hive-${user.name}</value> <description>Scratch space for Hive jobs</description> </property> <property> <name>hive.querylog.location</name> <value>/opt/data/querylog-${user.name}</value> <description> Location of Hive run time structured log file </description> </property> <property> <name>hive.support.concurrency</name> <description>Enable Hive's Table Lock Manager Service</description> <value>true</value> </property> <property> <name>hive.zookeeper.quorum</name> <description>Zookeeper quorum used by Hive's Table Lock Manager</description> <value>node1</value> </property> <property> <name>hive.hwi.listen.host</name> <value>desktop1</value> <description>This is the host address the Hive Web Interface will listen on</description> </property> <property> <name>hive.hwi.listen.port</name> <value>9999</value> <description>This is the port the Hive Web Interface will listen on</description> </property> <property> <name>hive.hwi.war.file</name> <value>lib/hive-hwi-0.10.0-cdh4.2.0.war</value> <description>This is the WAR file with the jsp content for Hive Web Interface</description> </property> </configuration>
9、安装postgresql(用postgresql作为元数据库)
a、下载postgresql,并安装
b、使用pgadmin创建用户sa
c、使用pgadmin创建数据库testdb,并指定所属角色为sa
d、配置pg_hba.conf的访问地址,允许主机访问
e、配置postgresql.conf
standard_conforming_strings = off
f、复制postgres 的jdbc驱动 到 /usr/hive-cdh4.4.0/lib
1)node.properties
node.environment=production
node.id=F25B16CB-5D5B-50FD-A30D-B2221D71C882
node.data-dir=/var/presto/data
注意每台服务器node.id必须是唯一的
2)jvm.config
-server
-Xmx16G
-XX:+UseConcMarkSweepGC
-XX:+ExplicitGCInvokesConcurrent
-XX:+CMSClassUnloadingEnabled
-XX:+AggressiveOpts
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p
-XX:PermSize=150M
-XX:MaxPermSize=150M
-XX:ReservedCodeCacheSize=150M
-Xbootclasspath/p:/var/presto/installation/lib/floatingdecimal-0.1.jar
下载floatingdecimal-0.1.jar包放在/var/presto/installation/lib/目录下
3)config.properties
coordinator=true
datasources=jmx
http-server.http.port=8080
presto-metastore.db.type=h2
presto-metastore.db.filename=var/db/MetaStore
task.max-memory=1GB
discovery-server.enabled=true
discovery.uri=http://master:8411
以上为master的配置,secondary、node1和node2中需将coordinator=true值改为false,将discovery-server.enabled=true删除掉
4)log.properties
com.facebook.presto=DEBUG
5)在/usr/presto/etc中创建catalog文件夹,并创建以下配置文件
jmx.properties
connector.name=jmx
hive.propertes
connector.name=hive-cdh4
hive.metastore.uri=thrift://master:9083
1)node.properties
node.environment=production
node.id=D28C24CF-78A1-CD09-C693-7BDE66A51EFD
node.data-dir=/var/discovery/data
2)jvm.config
-server
-Xmx1G
-XX:+UseConcMarkSweepGC
-XX:+ExplicitGCInvokesConcurrent
-XX:+AggressiveOpts
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p
3)config.properties
http-server.http.port=8411
运行:
master机器上运行命令如下:
start-all.sh(启动每台机器上的hadoop)
start-hbase.sh(启动每台机器上的hbase)
转入usr/disdiscovery-server/bin中启动disdiscovery-server,命令如下
1、启动hadoop命令:
hadoop namenode -format
hadoop datanode -format
start-all.sh
hadoop dfsadmin -safemode leave
hdfs dfsadmin -safemode leave
2、hive启动命令:
./hive
./hive --service hiveserver -p 9083 //thrift模式
3、hbase 命令
./start-hbase.sh
4、discovery-server命令:
laucher start //启动
laucher run //运行
lancher stop //停止
5、presto命令
laucher start //启动
laucher run //运行
lancher stop //停止
6、presto 客户端启动
./presto --server localhost:8080 --catalog hive --schema default
4 nodes select Count(*) from mytable; 10s
4 nodes select Count(*),num from mytable group by num; 10s
4 nodes select num from mytable group by num having count(*)>1000; 10s
4 nodes select min(num) from mytable group by num; 9s
4 nodes select min(num) from mytable; 9s
4 nodes select max(num) from mytable; 9s
4 nodes select min(num) from mytable group by num; 9s
4 nodes select row_number() over(partition by name order by num) as row_index from mytable; 16s