Kibana+Logstash+Elasticsearch 日志查询系统 - 扫榻人 - 51CTO技术博客
1 安装需求
1.1 理论拓扑
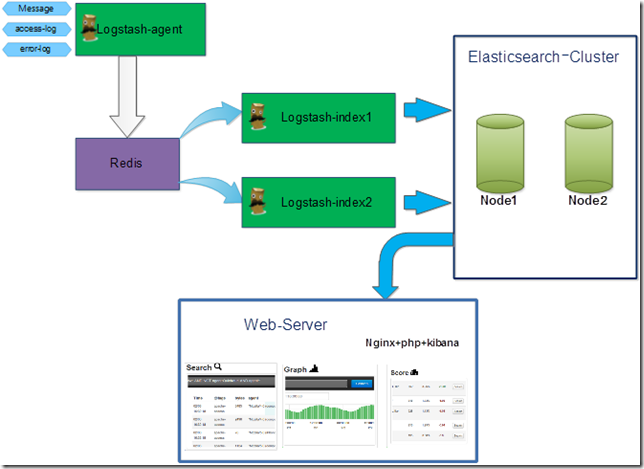
1.2 安装环境
1.2.1 硬件环境
1.2.2 操作系统
1.2.3 Web-server基础环境
1.2.4 软件列表
1.3 获取方法
1.3.1 Jdk获取路径
1.3.2 Logstash获取路径
1.3.3 Elasticsearch获取路径
1.3.4 Kibana获取路径
2 安装步骤
2.1 JDK的下载及安装
2.2 Redis下载及安装
2.3 Elasticsearch下载及安装
2.4 Logstash下载及安装
2.5 Kibana下载及安装
3 相关配置及启动
3.1 Redis配置及启动
3.1.1 配置文件
3.1.2 Redis启动(192.168.50.98)
3.2 Elasticsearch 配置及启动(192.168.50.98)
3.2.1 Elasticsearch启动
3.3 Logstash配置及启动
3.3.1 Logstash配置文件(agent收集日志角色)
3.3.2 Logstash启动为Index(从redis读取日志,负责日志的切割,存储至Elasticsearch)
3.3.4 kibana配置
4 性能调优
4.1 Elasticsearch调优
4.1.1 JVM调优
4.1.2 Elasticsearch索引压缩
5 使用
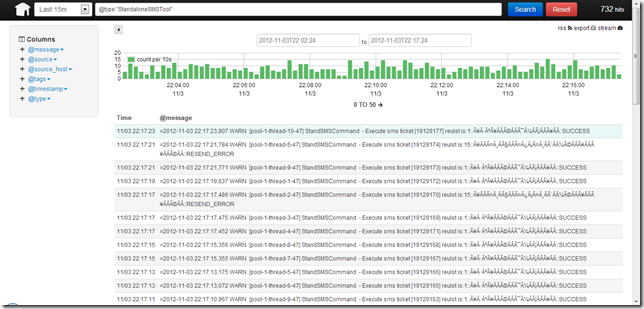
5.1 Logstash查询页
HDFS Permissions & Acls - 季石磊 - 博客园
1.概述
Hadoop分布式文件系统(HDFS)对文件和文件夹的权限控制模型与 POSIX文件系统的权限控制模型一样,每一个文件和文件夹都分配了所有者用户和所有者用户组。每个客户端访问HDFS的过程中,身份凭证由用户名和组列表两部分组成,Hadoop进行身份验证的时候,首先验证用户名,如果用户名验证不通过则验证用户组,如果用户名和用户组都验证失败则身份验证失败。
2.身份验证模式
Hadoop支持2种不同的身份验证模式,可以通过hadoop.security.authentication属性进行配置:
-
- simple
在simple身份认证模式下,用户的身份信息就是客户端的操作系统的登录用户,在Unix类的操作系统中,HDFS的用户名等同使用whoami命令查看结果的用户名。
-
- kerberos
在kerberos身份认证模式下,HDFS用户的身份是由kerberos凭证决定的。kerberos认证的安全性较高,但配置相对复杂,一般情况下很少使用。
3.Hadoop的Super-User
哪个用户启动Hadoop的Namenode,哪个用户就是Hadoop的超级管理员,拥有Hadoop全部权限。HDFS的超级管理员不必是操作系统的超级管理员。
4.配置参数
假设有一个HDFS集群,有两个用户UserA和UserB。要求HDFS只允许UserA和UserB访问,不允许其它用户访问,且UserA创建的文件UserB不能访问,同样UserB创建的文件UserA也不能访问。可以执行以下配置:
(1) 在core-site.xmll中配置以下属性:

<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
(2) 配置${HADOOP_CONF_DIR}/hadoop-policy.xml
<property> <name> security.client.protocol.acl </name> <value>UserA,UserB</value> </property>
只允许UserA,UserB访问Hdfs,不允许其它用户访问,注意这个地方如果设置用户组的话,用户组前面需要加一个空格。
(3)修改core-site.xmll中配置以下属性,开启dfs安全配置,同时设置新创建文件的umask码为077
<property> <name>dfs.permissions</name> <value>true</value> </property> <property> <name>fs.permissions.umask-mode</name> <value>077</value> </property>
如果用户通过通过跳板机或者客户端访问Hdfs的时候,建议使用final关键字以防止Hdfs服务器配置被客户端的配置覆盖,具体配置如下:
<property> <name>dfs.permissions</name> <value>true</value> <final>true</final> </property>
最后,使用hadoop启动hadoop执行start-all.sh 启动Hadoop,不能使用UserA或者UserB启动Hadoop。
5.umask
POSIX文件权限有读,写,执行三种权限,分别用r,w,x代表,这三种权限的数值大小如下表所示:
1 x
2 w
4 r
根据这三个数值可以得到混合权限数值表
1 --x
2 -w-
3 -wx
4 r--
5 r-x
6 rw-
7 rwx
这样Hdfs的文件有三种权限组成,可以通过hadoop fs -ls查看
drwxr-xr-x
以上权限的解释为
d rwx r-x r-x
目录 文件所有者的权限 同组用户的权限 其它用户的权限
表示为数值就是755
可以理解umask的作用为屏蔽权限位,例如umask 022,不屏蔽所属用户的权限,屏蔽同组用户的w权限,屏蔽其他用户的w权限,于是文件的默认权限为755,更简便的方法是用777减去022,得到755
6.其它问题
需要更改相关文件夹的权限,确保Hadoop在运行过程中的各类临时数据可以有写入权限,如果需要运行Mapreduce则需要修改Hdfs上面的${hadoop-tmp}/mapred/staging 文件夹权限,可以给737权限。如果需要运行Hive则需要给客户端本地硬盘的${hadoop-tmp}赋予其它用户写入权限
在对葡萄酒一无所知的情况下,如何根据酒标判断酒的好坏和风格? - 知乎
如果童鞋们想买酸爽口感的,要找酒精度较低的(11-12度);
想买浓郁圆润的,要找酒精度高的(13-14度);
想买口感甜的,去找酒精度过低(<11度)或过高(>17度)的
对于目前来说,只需知道新世界国家的气候普遍偏热,旧世界国家的气候普遍偏冷。气候的原因部分导致了新世界的酒偏浓郁、有更多偏甜香的果味;旧世界的酒偏酸、有更多偏咸香的非果味。
年份在距现在1年之内的一定是非木桶路线。
如果你选择非木桶路线,那么酒的风格多是以酸爽做主打,或以品种芳香做主打(某些品种芳香和木桶味完全不兼容,比如雷司令Riesling)。
年份在距现在3年以外的一般是木桶路线。2年的情况更复杂一些,但如果是距现在2年的白葡萄酒,则很有可能用了木桶。
如果你选择木桶路线,有两种基本方向——要不然是“简单果味+明显木桶辛香”的年轻派组合,要不然就是“复杂味道+不明显木桶辛香”的沉郁派组合。
但是我们要注意,独立酒庄不一定是精品级别(premium wine),但量产品牌一定不是精品级别(除非是他们的最高级别酒款)。此外,也有很多极烂的独立酒庄,不要让独立二字晃了眼了哦。
在我国葡萄酒中,长城葡萄酒就是量产品牌的典型代表。事实上,在2013年的Drink Business报道中,长城排名世界最强品牌第二名,听说马上还要扩张到智利、澳大利亚。
频次和密度:SNS战争的秘密 - 一个VC的胡思乱想 - 知乎专栏
先不说话,看图:
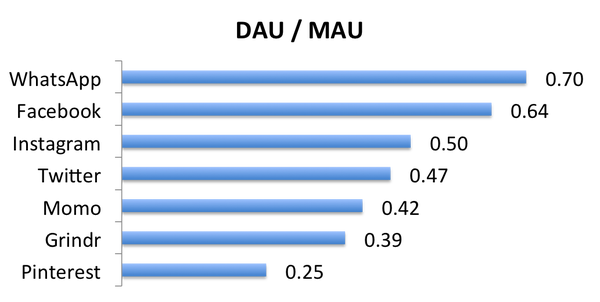
这是我随手整理的几个社交网络的“DAU比MAU”(日活跃用户除以月活跃用户),日期不一样,不过都尽量找了最新的数据,大家凑合着看。这个数字越接近1,说明用户使用该应用越频繁。仔细看看这些应用的属性,可以简单归纳几个特点:
- 需求本身的频次越高,使用频次越高。这个不解释了。
- 移动设备用户越多,使用频次越高。这个也不解释了。
- 熟人关系链越多,使用频次越高。解释一下:Instagram有一半的社交关系是真实好友。据说Momo的用户其实有相当多的好友关系是手机通讯录好友,而且每天所有消息中,80%的消息是双向关注的好友发的(你小看它了吧?)。
以上的总结基本是废话,因为大家基本已经知道了,这里我想讨论的其实是背后隐藏的战争规律。
好了,我开始抛砖引玉。
战争规律一:社交关系图相似,需求类型不互斥 ==> 高频打低频
我在知乎上曾经回答过一个问题“facebook社交网站会受到诸如微信等新的社交工具的影响吗?”。
我的基本观点是:如果WhatsApp做一个类似微信朋友圈的东西,对Facebook会有巨大的威胁。逻辑如下:
- “发朋友圈”的核心体验是“发了以后立即有好友赞或回复”。WhatsApp的“永久在线+高频使用”属性,让它对Facebook有战略优势,如果做了类似朋友圈的东西,用户发了内容可以比Facebook更快地获得更多好友的反馈。
- “看朋友圈”的核心体验是“有很多好友发的新鲜、真实而有趣的内容”。基于第1条,WhatsApp的朋友圈的会有更多的好友发内容,而且更加新鲜,而且因为楼主在线概率更高,留言以后更容易和“楼主”形成互动。
- 朋友圈的这两个核心体验都对用户密度和使用频次高度依赖,第1条和第2条互相促进,形成良性循环。
不久以后,Facebook就以190亿美金的可怕的价格收购了WhatsApp。其实WhatsApp在美国的渗透率还不是特别高(而且一直没有上线朋友圈的功能,这点我真想不通),否则很可能挺着不卖,和FB好好干一仗。
这第一条规律可以总结为“高频需求能够带来用户密度拉动低频需求”。
战争规律二:社交关系图相似,频次相仿 ==> 原创为王
80后们应该都还记得2008年上演的SNS大战。先是程炳皓的开心网利用熟人社交小游戏(以及MSN通讯录)像火箭一样成了都市白领的“上班开机必刷”的网站。与此同时,陈一舟的千橡集团收购了校内网(后改名人人网),在校园市场送鸡腿,在白领市场用假开心网阻击真开心网的扩张,而且一下子融了4亿多美金。
面对激烈的竞争,开心网继续开发好玩的社交游戏,并且开发了神奇的“转帖”功能,一时间来势汹汹,占领了用户大量的时间。人人网一开始扛着还是坚持以UGC为主,后来还是决定跟进。“转帖”和各种社交游戏的消息渐渐占据了用户的主feed(用户信息流)。虽然看上去用户使用时长和PV数在增加,但是慢慢地用户行为发生了变化:发照片发状态也开始没人赞也没人留言了,因为好友们的feed里面的转帖和社交游戏的消息淹没了用户原创的内容。
这时一个神奇的网站“新浪微博”伴随着智能手机出现了。自己关注的名人以及好友发布的新鲜信息流和即时的社交交互体验,迅速PK掉开心网和人人网的充满了转帖的信息流。一时间微博红透了半边天,去餐馆吃饭都要打开微博“互粉”一下,吃到美食买了漂亮衣服也都先到新浪微博上给朋友们汇报一下。当时新浪微博气势之汹涌,腾讯砸重金加无限流量支持“腾讯微博”,还是扛不过它。
后来,随着微博feed被公众账号和段子手(甚至机器人)占领,活跃度大幅下降。有人也许要说,微博活跃度下降是因为微信朋友圈的替代效应,我也同意,不过我想说两点。1)微博的社交图谱和微信不一样,其实有独特存在价值,其实不应该这么快被替代(Twitter比它活的好多了),是它自己的feed衰老过快才让竞争对手有可乘之机;2)微信朋友圈里也在feed里引入了大量公众账号和转帖,其实是伤敌一千自损八百(仗着自己有能“无限补血”的高频的通信功能),也许时过境迁,它也要自食其果的。在美国的青少年中,Instagram的使用率已经比Facebook要高了,原因之一就是嫌Facebook的feed里面乱七八糟的东西太多。
这第二条规律可以总结为:基于用户原创内容的交互的需求更“基础”、更“普遍”、更不可替代,而转帖和社交游戏实际上稀释了基于用户原创内容的交互,降低了真实的社交行为的密度,让竞争对手有可乘之机。
战争规律三:社交关系图类似的UGC社区 ==> 内容生产成本越低越好
观察社交网络的变迁,还发现一个现象,就是内容生产成本越低的网站用户越多,使用越频繁。举两个例子:
1) 图片社交。美国以前有个流行的图片社交网站叫Flickr,可流量一直在降。Flickr里面聚集了许多摄影高手用高级摄影器材拍的好照片,可是Instagram让普通人用手机就能拍出还不错的照片出来,不但能洋洋自得,还有好友来点个赞,如果按DAU或者使用时长,Instagram比Flickr高一个数量级。Instagram其实做了大量工作来降低内容生产成本: a) 用方框(容易取景);b) 提供一些滤镜让照片看上去有逼格;c) 用手机就可以拍,随时可以拍。还有个更奇葩的公司Pinterest,连拍照片都省了,用户直接从别的网站扒图片过来“钉”到自己的墙上,就“生产”了内容,还真有人愿意看,不过它是不是个真的SNS其实值得商榷,这里就不展开聊了。
2) 博客和微博(Twitter)。微博出来以后,写博客的人大幅下降。一个重要原因就是写博客门槛太高了,能写高质量博客的人其实不多,而且要隔很久才写一篇,所以基本上只能逛逛网络红人的博客(名人都未必写得好博客)。微博出来以后,不但名人们都能写微博,而且自己认识的朋友也能写出让自己感兴趣的微博。
这第三条规律可以总结为:通过降低内容生产成本可以提高用户关系密度,进而促进内容生产和用户活跃。
总结:频次和密度
其实这些规律背后都是“密度”。补充定义一下“密度”的概念:使用频次,其实是时间维度上的密度,而用户渗透率,代表了用户关系维度上的密度。SNS的核心体验是用户之间的交互,而高密度的用户关系和使用频次能够带来更好的社交交互体验。
最后,按惯例给创业者提几个建议:
1)社交类的创业者,请关注你们自己的DAU/MAU,不断思考需求够不够刚性,有没有保护用户原创内容的积极性,高质量内容的生产成本是不是还可以继续降低,熟人关系比例是不是还可以继续提高?(顺便说一句,如果计划未来利用通讯录引入熟人关系的计划,那么一开始就要搞用户的手机号,要搞手机号,要搞手机号......)
2)许多工具型的应用的开发者想转社区,建议先仔细想想你的用户是否有真实的社交需求,然后再从社交关系和使用频次的不同维度来计算一下自己的有效用户密度,如果需求不强烈或者密度不够,还是别把宝押在这上面。