使用API网关构建微服务
让我们想象一下,你要为一个购物应用程序开发一个原生移动客户端。你很可能需要实现一个产品详情页面,上面展示任何指定产品的信息。
例如,下图展示了在Amazon Android移动应用中滚动产品详情时看到的内容。

虽然这是个智能手机应用,产品详情页面也显示了大量的信息。例如,该页面不仅包含基本的产品信息(如名称、描述、价格),而且还显示了如下内容:
- 购物车中的件数
- 订单历史
- 客户评论
- 低库存预警
- 送货选项
- 各种推荐,包括经常与该产品一起购买的其它产品,购买该产品的客户购买的其它产品,购买该产品的客户看过的其它产品。
- 可选的购买选项。
当使用单体应用程序架构时,移动客户端将通过向应用程序发起一次REST调用(GET api.company.com/productdetails/<productId>)来获取这些数据。负载均衡器将请求路由给N个相同的应用程序实例中的一个。然后,应用程序会查询各种数据库表,并将响应返回给客户端。
相比之下,当使用微服务架构时,产品详情页面显示的数据归多个微服务所有。下面是部分可能的微服务,它们拥有要显示在示例中产品详情页面上的数据:
- 购物车服务——购物车中的件数
- 订单服务——订单历史
- 目录服务——产品基本信息,如名称、图片和价格
- 评论服务——客户的评论
- 库存服务——低库存预警
- 送货服务——送货选项、期限和费用,这些单独从送货方的API获取
- 推荐服务——建议的产品

我们需要决定移动客户端如何访问这些服务。让我们看看都有哪些选项。
客户端与微服务直接通信
从理论上讲,客户端可以直接向每个微服务发送请求。每个微服务都有一个公开的端点(https ://<serviceName>.api.company.name)。该URL将映射到微服务的负载均衡器,由它负责在可用实例之间分发请求。为了获取产品详情,移动客户端将逐一向上面列出的N个服务发送请求。
遗憾的是,这种方法存在挑战和局限。一个问题是客户端需求和每个微服务暴露的细粒度API不匹配。在这个例子中,客户端需要发送7个独立请求。在更复杂的应用程序中,可能要发送更多的请求。例如,按照Amazon的说法,他们在显示他们的产品页面时就调用了数百个服务。然而,客户端通过LAN发送许多请求,这在公网上可能会很低效,而在移动网络上就根本不可行。这种方法还使得客户端代码非常复杂。
客户端直接调用微服务的另一个问题是,部分服务使用的协议不是Web友好协议。一个服务可能使用Thrift二进制RPC,而另一个服务可能使用AMQP消息传递协议。不管哪种协议都不是浏览器友好或防火墙友好的,最好是内部使用。在防火墙之外,应用程序应该使用诸如HTTP和WebSocket之类的协议。
这种方法的另一个缺点是,它会使得微服务难以重构。随着时间推移,我们可能想要更改系统划分成服务的方式。例如,我们可能合并两个服务,或者将一个服务拆分成两个或更多服务。然而,如果客户端与微服务直接通信,那么执行这类重构就非常困难了。
由于这些问题的存在,客户端与微服务直接通信很少是合理的。
使用API网关
通常,一个更好的方法是使用所谓的API网关。API网关是一个服务器,是系统的唯一入口。从面向对象设计的角度看,它与外观模式类似。API网关封装了系统内部架构,为每个客户端提供一个定制的API。它可能还具有其它职责,如身份验证、监控、负载均衡、缓存、“请求整形(request shaping)”与管理、静态响应处理。
下图展示了API网关通常如何融入架构:

API网关负责服务请求路由、组合及协议转换。客户端的所有请求都首先经过API网关,然后由它将请求路由到合适的微服务。API网管经常会通过调用多个微服务并合并结果来处理一个请求。它可以在Web协议(如HTTP与WebSocket)与内部使用的非Web友好协议之间转换。
API网关还能为每个客户端提供一个定制的API。通常,它会向移动客户端暴露一个粗粒度的API。例如,考虑下产品详情的场景。API网关可以提供一个端点(/productdetails?productid=xxx),使移动客户端可以通过一个请求获取所有的产品详情。API网关通过调用各个服务(产品信息、推荐、评论等等)并合并结果来处理请求。
Netflix API网关是一个很好的API网关实例。Netflix流服务提供给数以百计的不同类型的设备使用,包括电视、机顶盒、智能手机、游戏系统、平板电脑等等。最初,Netflix试图为他们的流服务提供一个通用的API。然而他们发现,由于各种各样的设备都有自己独特的需求,这种方式并不能很好地工作。如今,他们使用一个API网关,通过运行特定于设备的适配器代码来为每个设备提供一个定制的API。通常,一个适配器通过调用平均6到7个后端服务来处理每个请求。Netflix API网关每天处理数十亿请求。
API网关的优点和不足
如你所料,使用API网关有优点也有不足。使用API网关的最大优点是,它封装了应用程序的内部结构。客户端只需要同网关交互,而不必调用特定的服务。API网关为每一类客户端提供了特定的API。这减少了客户端与应用程序间的交互次数,还简化了客户端代码。
API网关也有一些不足。它增加了一个我们必须开发、部署和维护的高可用组件。还有一个风险是,API网关变成了开发瓶颈。为了暴露每个微服务的端点,开发人员必须更新API网关。API网关的更新过程要尽可能地简单,这很重要。否则,为了更新网关,开发人员将不得不排队等待。不过,虽然有这些不足,但对于大多数现实世界的应用程序而言,使用API网关是合理的。
实现API网关
到目前为止,我们已经探讨了使用API网关的动机及其优缺点。下面让我们看一下需要考虑的各种设计问题。
性能和可扩展性
只有少数公司有Netflix的规模,每天需要处理数十亿请求。不管怎样,对于大多数应用程序而言,API网关的性能和可扩展性通常都非常重要。因此,将API网关构建在一个支持异步、I/O非阻塞的平台上是合理的。有多种不同的技术可以用于实现一个可扩展的API网关。在JVM上,可以使用一种基于NIO的框架,比如Netty、Vertx、Spring Reactor或JBoss Undertow中的一种。一个非常流行的非JVM选项是Node.js,它是一个以Chrome JavaScript引擎为基础构建的平台。另一个选项是使用NGINX Plus。NGINX Plus提供了一个成熟的、可扩展的、高性能Web服务器和一个易于部署的、可配置可编程的反向代理。NGINX Plus可以管理身份验证、访问控制、负载均衡请求、缓存响应,并提供应用程序可感知的健康检查和监控。
使用响应式编程模型
API网关通过简单地将请求路由给合适的后端服务来处理部分请求,而通过调用多个后端服务并合并结果来处理其它请求。对于部分请求,比如产品详情相关的多个请求,它们对后端服务的请求是独立于其它请求的。为了最小化响应时间,API网关应该并发执行独立请求。然而,有时候,请求之间存在依赖。在将请求路由到后端服务之前,API网关可能首先需要调用身份验证服务验证请求的合法性。类似地,为了获取客户意愿清单中的产品信息,API网关必须首先获取包含那些信息的客户资料,然后再获取每个产品的信息。关于API组合,另一个有趣的例子是Netflix Video Grid。
使用传统的异步回调方法编写API组合代码会让你迅速坠入回调地狱。代码会变得混乱、难以理解且容易出错。一个更好的方法是使用响应式方法以一种声明式样式编写API网关代码。响应式抽象概念的例子有Scala中的Future、Java 8中的CompletableFuture和JavaScript中的Promise,还有最初是微软为.NET平台开发的Reactive Extensions(RX)。Netflix创建了RxJava for JVM,专门用于他们的API网关。此外,还有RxJS for JavaScript,它既可以在浏览器中运行,也可以在Node.js中运行。使用响应式方法将使你可以编写简单但高效的API网关代码。
服务调用
基于微服务的应用程序是一个分布式系统,必须使用一种进程间通信机制。有两种类型的进程间通信机制可供选择。一种是使用异步的、基于消息传递的机制。有些实现使用诸如JMS或AMQP那样的消息代理,而其它的实现(如Zeromq)则没有代理,服务间直接通信。另一种进程间通信类型是诸如HTTP或Thrift那样的同步机制。通常,一个系统会同时使用异步和同步两种类型。它甚至还可能使用同一类型的多种实现。总之,API网关需要支持多种通信机制。
服务发现
API网关需要知道它与之通信的每个微服务的位置(IP地址和端口)。在传统的应用程序中,或许可以硬连线这个位置,但在现代的、基于云的微服务应用程序中,这并不是一个容易解决的问题。基础设施服务(如消息代理)通常会有一个静态位置,可以通过OS环境变量指定。但是,确定一个应用程序服务的位置没有这么简单。应用程序服务的位置是动态分配的。而且,单个服务的一组实例也会随着自动扩展或升级而动态变化。总之,像系统中的其它服务客户端一样,API网关需要使用系统的服务发现机制,可以是服务器端发现,也可以是客户端发现。下一篇文章将更详细地描述服务发现。现在,需要注意的是,如果系统使用客户端发现,那么API网关必须能够查询服务注册中心,这是一个包含所有微服务实例及其位置的数据库。
处理局部失败
在实现API网关时,还有一个问题需要处理,就是局部失败的问题。该问题在所有的分布式系统中都会出现,无论什么时候,当一个服务调用另一个响应慢或不可用的服务,就会出现这个问题。API网关永远不能因为无限期地等待下游服务而阻塞。不过,如何处理失败取决于特定的场景以及哪个服务失败。例如,在产品详情场景下,如果推荐服务无响应,那么API网关应该向客户端返回产品详情的其它内容,因为它们对用户依然有用。推荐内容可以为空,也可以,比如说,用一个固定的TOP 10列表取代。不过,如果产品信息服务无响应,那么API网关应该向客户端返回一个错误信息。
如果缓存数据可用,那么API网关还可以返回缓存数据。例如,由于产品价格不经常变化,所以如果价格服务不可用,API网关可以返回缓存的价格数据。数据可以由API网关自己缓存,也可以存储在像Redis或Memcached那样的外部缓存中。通过返回默认数据或者缓存数据,API网关可以确保系统故障不影响用户的体验。
在编写代码调用远程服务方面,Netflix Hystrix是一个异常有用的库。Hystrix会将超出设定阀值的调用超时。它实现了一个“断路器(circuit breaker)”模式,可以防止客户端对无响应的服务进行不必要的等待。如果服务的错误率超出了设定的阀值,那么Hystrix会切断断路器,在一个指定的时间范围内,所有请求都会立即失败。Hystrix允许用户定义一个请求失败后的后援操作,比如从缓存读取数据,或者返回一个默认值。如果你正在使用JVM,那么你绝对应该考虑使用Hystrix。而如果你正在使用一个非JVM环境,那么你应该使用一个等效的库。
小结
对于大多数基于微服务的应用程序而言,实现一个API网关是有意义的,它可以作为系统的唯一入口。API网关负责服务请求路由、组合及协议转换。它为每个应用程序客户端提供一个定制的API。API网关还可以通过返回缓存数据或默认数据屏蔽后端服务失败。在本系列的下一篇文章中,我们将探讨服务间通信。
Oracle中B-TREE索引的深入理解(原创) - CzmMiao的博客生活 - ITeye技术网站
索引概述
索引与表一样,也属于段(segment)的一种。里面存放了用户的数据,跟表一样需要占用磁盘空间。只不过,在索引里的数据存放形式与表里的数据存放形式非常的不一样。在理解索引时,可以想象一本书,其中书的内容就相当于表里的数据,而书前面的目录就相当于该表的索引。同时,通常情况下,索引所占用的磁盘空间要比表要小的多,其主要作用是为了加快对数据的搜索速度,也可以用来保证数据的唯一性。
但是,索引作为一种可选的数据结构,你可以选择为某个表里的创建索引,也可以不创建。这是因为一旦创建了索引,就意味着oracle对表进行DML(包括INSERT、UPDATE、DELETE)时,必须处理额外的工作量(也就是对索引结构的维护)以及存储方面的开销。所以创建索引时,需要考虑创建索引所带来的查询性能方面的提高,与引起的额外的开销相比,是否值得。
从物理上说,索引通常可以分为:分区和非分区索引、常规B树索引、位图(bitmap)索引、翻转(reverse)索引等。其中,B树索引属于最常见的索引,由于我们的这篇文章主要就是对B树索引所做的探讨,因此下面只要说到索引,都是指B树索引。
B树索引内部结构
B树索引是一个典型的树结构,其包含的组件主要是:
1) 叶子节点(Leaf node):数据行的键值(key value)、键值对应数据行的 ROWID。
2) 分支节点(Branch node):最小的键值前缀(minimum key prefix),用于在(本块的)两个键值之间做出分支选择,指向包含所查找键值的子块(child block)的指针()所有的 键值-ROWID 对(key and ROWID pair)都与其左右的兄弟节点(sibling)向链接(link),并按照(key,ROWID)的顺序排序
3) 根节点(Root node):一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
可以用下图一来描述B树索引的结构。其中,B表示分支节点,而L表示叶子节点。

对于分支节点块(包括根节点块)来说,其所包含的索引条目都是按照顺序排列的(缺省是升序排列,也可以在创建索引时指定为降序排列)。每个索引条目(也可以叫做每条记录)都具有两个字段。第一个字段表示当前该分支节点块下面所链接的索引块中所包含的最小键值;第二个字段为四个字节,表示所链接的索引块的地址,该地址指向下面一个索引块。在一个分支节点块中所能容纳的记录行数由数据块大小以及索引键值的长度决定。比如从上图一可以看到,对于根节点块来说,包含三条记录,分别为(0 B1)、(500 B2)、(1000 B3),它们指向三个分支节点块。其中的0、500和1000分别表示这三个分支节点块所链接的键值的最小值。而B1、B2和B3则表示所指向的三个分支节点块的地址。
对于叶子节点块来说,其所包含的索引条目与分支节点一样,都是按照顺序排列的(缺省是升序排列,也可以在创建索引时指定为降序排列)。每个索引条目(也可以叫做每条记录)也具有两个字段。第一个字段表示索引的键值,对于单列索引来说是一个值;而对于多列索引来说则是多个值组合在一起的。第二个字段表示键值所对应的记录行的ROWID,该ROWID是记录行在表里的物理地址。如果索引是创建在非分区表上或者索引是分区表上的本地索引的话,则该ROWID占用6个字节;如果索引是创建在分区表上的全局索引的话,则该ROWID占用10个字节。
知道这些信息以后,我们可以举个例子来说明如何估算每个索引能够包含多少条目,以及对于表来说,所产生的索引大约多大。对于每个索引块来说,缺省的PCTFREE为10%,也就是说最多只能使用其中的90%。同时9i以后,这90%中也不可能用尽,只能使用其中的87%左右。也就是说,8KB的数据块中能够实际用来存放索引数据的空间大约为6488(8192×90%×88%)个字节。
假设我们有一个非分区表,表名为warecountd,其数据行数为130万行。该表中有一个列,列名为goodid,其类型为char(8),那么也就是说该goodid的长度为固定值:8。同时在该列上创建了一个B树索引。
在叶子节点中,每个索引条目都会在数据块中占一行空间。每一行用2到3个字节作为行头,行头用来存放标记以及锁定类型等信息。同时,在第一个表示索引的键值的字段中,每一个索引列都有1个字节表示数据长度,后面则是该列具体的值。那么对于本例来说,在叶子节点中的一行所包含的数据大致如下图二所示:

从上图可以看到,在本例的叶子节点中,一个索引条目占 18 个字节。同时我们知道 8KB 的数据块中真正可以用来存放索引条目的空间为 6488 字节,那么在本例中,一个数据块中大约可以放 360 ( 6488/18 )个索引条目。而对于我们表中的130 万条记录来说,则需要大约 3611 ( 1300000/360 )个叶子节点块。
而对于分支节点里的一个条目(一行)来说,由于它只需保存所链接的其他索引块的地址即可,而不需要保存具体的数据行在哪里,因此它所占用的空间要比叶子节点要少。分支节点的一行中所存放的所链接的最小键值所需空间与上面所描述的叶子节点相同;而存放的索引块的地址只需要 4 个字节,比叶子节点中所存放的 ROWID 少了 2 个字节,少的这 2 个字节也就是 ROWID 中用来描述在数据块中的行号所需的空间。因此,本例中在分支节点中的一行所包含的数据大致如下图三所示:

从上图可以看到,在本例的分支节点中,一个索引条目占 16 个字节。根据上面叶子节点相同的方式,我们可以知道一个分支索引块可以存放大约 405 ( 6488/16 )个索引条目。而对于我们所需要的 3611 个叶子节点来说,则总共需要大约 9 个分支索引块。
这样,我们就知道了我们的这个索引有 2 层,第一层为 1 个根节点,第二层为 9 个分支节点,而叶子节点数为 3611 个,所指向的表的行数为 1300000 行。但是要注意,在 oracle 的索引中,层级号是倒过来的,也就是说假设某个索引有 N层,则根节点的层级号为 N ,而根节点下一层的分支节点的层级号为 N-1 ,依此类推。对本例来说, 9 个分支节点所在的层级号为 1 ,而根节点所在的层级号为 2 。
注意:在Oracle中null被定义为无限大,且null不等于null,故在索引不会存有与null值对应的条目。如果不加其他限制条件的对表进行is null扫描,将会是全表扫描,如果是is not null扫描将会是全索引扫描
这里仅仅是作为研究来讨论如何估算,学习一样东西,我们当然要知其然,也知其所以然,实际环境中可以利用explain plan for 查看创建索引的执行计划,从而对索引大小,创建时间进行预判,具体可参见
http://czmmiao.iteye.com/blog/1471756
B树索引的访问
当oracle进程需要访问数据文件里的数据块时,oracle会有两种类型的I/O操作方式:
1) 随机访问,每次读取一个数据块(通过等待事件“db file sequential read”体现出来)。
2) 顺序访问,每次读取多个数据块(通过等待事件“db file scattered read”体现出来)。
第一种方式则是访问索引里的数据块,而第二种方式的I/O操作属于全表扫描。这里顺带有一个问题,为
何随机访问会对应到db file sequential read等待事件,而顺序访问则会对应到db file scattered read等待事件呢?这似乎反过来了,随机访问才应该是分散(scattered)的,而顺序访问才应该是顺序(sequential)的。其实,等待事件主要根据实际获取物理I/O块的方式来命名的,而不是根据其在I/O子系统的逻辑方式来命名的。下面对于如何获取索引数据块的方式中会对此进行说明。
事实上在B树索引虽然为一个树状的立体结构,但其对应到数据文件里的排列当然还是一个平面的形式,也就是像下面这样。
/根/分支/分支/叶子/…/叶子/分支/叶子/叶子/…/叶子/分支/叶子/叶子/…/叶子/分支/.....
因此,当oracle需要访问某个索引块的时候,势必会在这个结构上跳跃的移动。
当oracle需要获得一个索引块时,首先从根节点开始,根据所要查找的键值,从而知道其所在的下一层的分支节点,然后访问下一层的分支节点,再次同样根据键值访问再下一层的分支节点,如此这般,最终访问到最底层的叶子节点。可以看出,其获得物理I/O块时,是一个接着一个,按照顺序,串行进行的。在获得最终物理块的过程中,我们不能同时读取多个块,因为我们在没有获得当前块的时候是不知道接下来应该访问哪个块的。因此,在索引上访问数据块时,会对应到db file sequential read等待事件,其根源在于我们是按照顺序从一个索引块跳到另一个索引块,从而找到最终的索引块的。
那么对于全表扫描来说,则不存在访问下一个块之前需要先访问上一个块的情况。全表扫描时,oracle知道要访问所有的数据块,因此唯一的问题就是尽可能高效的访问这些数据块。因此,这时oracle可以采用同步的方式,分几批,同时获取多个数据块。这几批的数据块在物理上可能是分散在表里的,因此其对应到db file scattered read等待事件。
DML对B树索引的影响
INSERT
在每个INSERT操作过程中,关键字必须被插入在正确叶节点的位置。如果叶节点已满,不能容纳更多的关键字,就必须将叶节点拆分。拆分的方法有两种:
1)如果新关键字值在所有旧叶节点块的所有关键字中是最大的,那么所有的关键字将按照99:1的比例进行拆分,使得在新的叶节点块中只存放有新关键字,而其他的所有关键字(包括所有删除的关键字)仍然保存在旧叶节点块中。
2)如果新关键字值不是最大的,那么所有的关键字将按照50:50的比例进行拆分,这时每个叶节点块(旧与新)中将各包含原始叶节点中的一半关键字。
这个拆分必须通过一个指向新叶节点的新入口向上传送到父节点。如果父节点已满,那么这个父节点也必须进行拆分,并且需要将这种拆分向上传送到父节点的父节点。这时,如果这个父节点也已满,将继续进行这个过程。这样,某个拆分可能最终被一直传送到根节点。如果根节点满了,根结点也将进行分裂。根结点在进行分裂的时候,就是树的高度增加的时候。根节点进行分裂的方式跟其他的的节点分裂的方式相比较,在物理位置上的处理也是不同的。根节点分裂时,将原来的根结点分裂为分支节点或叶节点,保存到新的块中,而将新的根节点信息保存到原来的根结点块中,这样做的是为因为避免修改数据字典所带来的相对较大的开销。
注意:现在Oracle都是采用了平衡算法,正常情况下即使索引关键字不断增大,也不会产生不平衡树。当索引关键字不断增大,导致树级别单方向增长时,Oracle会自动进行索引翻转以维持索引的平衡,当然这种操作非常消耗资源
在索引的每一个层次之间,每一个层最左边的节点的block头部都有一个指向下层最左边的块的指针,这样有利于fast full scan 的快速定位最左边的叶子节点。
每个拆分过程都是要花费一定的开销的,特别是要进行物理硬盘I/O动作。此外,在进行拆分之前,Oracle必须查找到一个空块,用来保存这个拆分。可以用以下步骤来进行查找空块的动作:
1) 在索引的自由列表(free-list, 又称为空闲列表) 中查到一个空闲块,可以通过CREATE/ALTER INDEX命令为一个索引定义多个空闲列表。索引空闲列表并不能帮助Oracle查找一个可用来存放将要被插入的新关键字的块。这是因为关键字值不能随机地存放在索引中可用的第一个“空闲”叶节点块中,这个值必须经过适当的排序之后,放置在某个特定的叶节点块中。只有在块拆分过程中才需要使用索引的空闲列表,每个空闲列表都包含有一个关于“空”块的链接列表。当为某个索引定义了多个空闲列表时,首先将从分配给进程的空间列表中扫描一个空闲块。如果没有找到所需要的空闲块,将从主空闲列表中进行扫描空闲块的动作。
2) 如果没有找到任何空闲块,Oracle将试图分配另一个扩展段。如果在表空间中没有更多的自由空间,Oracle将产生错误ORA-01654。
3) 如果通过上述步骤,找到了所需的空闲块,那么这个索引的高水位标(HWM)将加大。
4) 所找到的空闲块将用来执行拆分动作。
在创建B*树索引时,一个需要注意的问题就是要避免在运行时进行拆分,或者,要在索引创建过程中进行拆分(“预拆分”),从而使得在进行拆分时能够快速命中,以便避免运行时插入动作。当然,这些拆分也不仅仅局限于插入动作,在进行更新的过程中也有可能会发生拆分动作。
UPDATE
索引更新完全不同于表更新,在表更新中,数据是在数据块内部改变的(假设数据块中有足够的空间来允许进行这种改变);但在索引更新中,如果有关键字发生改变,那么它在树中的位置也需要发生改变。请记住,一个关键字在B*树中有且只有一个位置。因此,当某个关键字发生改变时,关键字的旧表项必须被删除,并且需要在一个新的叶节点上创建一个新的关键字。旧的表项有可能永远不会被重新使用,这是因为只有在非常特殊的情况下, Oracle才会重用关键字表项槽,例如,新插入的关键字正好是被删除的那个关键字(包括数据类型、长度等等)。(这里重用的是块,但完全插入相同的值的时候,也不一定插入在原来的被删除的位置,只是插入在原来的块中,可能是该块中的一个新位置。也正因为如此,在索引块中保存的的记录可能并不是根据关键字顺序排列的,随着update等的操作,会发生变化。)那么,这种情况发生的可能性有多大呢?许多应用程序使用一个数列来产生NUMBER关键字(特别是主关键字)。除非它们使用了RECYCLE选项,否则这个数列将不会两次产生完全相同的数。这样,索引中被删除的空间一直没有被使用。这就是在大规模删除与更新过程中,表大小不断减小或至少保持不变但索引不断加大的原因。
DELETE
当删除表里的一条记录时,其对应于索引里的索引条目并不会被物理的删除,只是做了一个删除标记。当一个新的索引条目进入一个索引叶子节点的时候,oracle会检查该叶子节点里是否存在被标记为删除的索引条目,如果存在,则会将所有具有删除标记的索引条目从该叶子节点里物理的删除。
当一个新的索引条目进入索引时,oracle会将当前所有被清空的叶子节点(该叶子节点中所有的索引条目都被设置为删除标记)收回,从而再次成为可用索引块。
尽管被删除的索引条目所占用的空间大部分情况下都能够被重用,但仍然存在一些情况可能导致索引空间被浪费,并造成索引数据块很多但是索引条目很少的后果,这时该索引可以认为出现碎片。而导致索引出现碎片的情况主要包括:
1、不合理的、较高的PCTFREE。很明显,这将导致索引块的可用空间减少。
2、索引键值持续增加(比如采用sequence生成序列号的键值),同时对索引键值按照顺序连续删除,这时可能导致索引碎片的发生。因为前面我们知道,某个索引块中删除了部分的索引条目,只有当有键值进入该索引块时才能将空间收回。而持续增加的索引键值永远只会向插入排在前面的索引块中,因此这种索引里的空间几乎不能收回,而只有其所含的索引条目全部删除时,该索引块才能被重新利用。
3、经常被删除或更新的键值,以后几乎不再会被插入时,这种情况与上面的情况类似。
总结
通过上面对B树的分析,可以得出以下的应用准则:
1、避免对那些可能会产生很高的更新动作的列进行索引。
2、避免对那些经常会被删除的表中的多个列进行索引。若有可能,只对那些在这样的表上会进行删除的主关键字与/或列进行索引。如果对多个列进行索引是不可避免的,那么就应该考虑根据这些列对表进行划分,然后在每个这样的划分上执行TRUNCATE动作(而不是DELETE动作)。TRUNCATE在与DROP STORAGE短语一同使用时,通过重新设置高水位标来模拟删除表与索引以及重新创建表与索引的过程。
3、避免为那些唯一度不高的列创建B*树索引。这样的低选择性将会导致树节点块的稠密性,从而导致由于索引“平铺( flat)”而出现的大规模索引扫描。唯一性的程度越高,性能就越好,因为这样能够减少范围扫描,甚至可能用唯一扫描来取代范围扫描。
4)空值不存储在单列索引中。对于复合索引的方式,只有当某个列不空时,才需要进行值的存储。在为DML语句创建IS NULL或IS NOT NULL短语时,应该切记这个问题。
5)IS NULL不会导致索引扫描,而一个没有带任何限制的IS NOT NULL则可能会导致完全索引扫描。
本文未 进行 索引内部结构的转储实验,全部为理论研究,感兴趣的朋友可以自行搜索网上的相关文档进行研究学习
参考至:http://btxigua.itpub.net/post/34419/406433
http://space.itpub.net/?uid-9842-action-viewspace-itemid-324139
http://space.itpub.net/?uid-9842-action-viewspace-itemid-312607
http://space.itpub.net/?uid-9842-action-viewspace-itemid-324586
How to make searching faster ImproveSearchingSpeed - Lucene-java Wiki
How to make searching faster
Here are some things to try to speed up the seaching speed of your Lucene application. Please see ImproveIndexingSpeed for how to speed up indexing.
-
Be sure you really need to speed things up. Many of the ideas here are simple to try, but others will necessarily add some complexity to your application. So be sure your searching speed is indeed too slow and the slowness is indeed within Lucene.
-
Make sure you are using the latest version of Lucene.
-
Use a local filesystem. Remote filesystems are typically quite a bit slower for searching. If the index must be remote, try to mount the remote filesystem as a "readonly" mount. In some cases this could improve performance.
-
Get faster hardware, especially a faster IO system. Flash-based Solid State Drives works very well for Lucene searches. As seek-times for SSD's are about 100 times faster than traditional platter-based harddrives, the usual penalty for seeking is virtually eliminated. This means that SSD-equipped machines need less RAM for file caching and that searchers require less warm-up time before they respond quickly.
-
Tune the OS
One tunable that stands out on Linux is swappiness (http://kerneltrap.org/node/3000), which controls how aggressively the OS will swap out RAM used by processes in favor of the IO Cache. Most Linux distros default this to a highish number (meaning, aggressive) but this can easily cause horrible search latency, especially if you are searching a large index with a low query rate. Experiment by turning swappiness down or off entirely (by setting it to 0). Windows also has a checkbox, under My Computer -> Properties -> Advanced -> Performance Settings -> Advanced -> Memory Usage, that lets you favor Programs or System Cache, that's likely doing something similar.
-
Open the IndexReader with readOnly=true. This makes a big difference when multiple threads are sharing the same reader, as it removes certain sources of thread contention.
-
On non-Windows platform, using NIOFSDirectory instead of FSDirectory.
This also removes sources of contention when accessing the underlying files. Unfortunately, due to a longstanding bug on Windows in Sun's JRE (http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=6265734 -- feel particularly free to go vote for it), NIOFSDirectory gets poor performance on Windows.
-
Add RAM to your hardware and/or increase the heap size for the JVM. For a large index, searching can use alot of RAM. If you don't have enough RAM or your JVM is not running with a large enough HEAP size then the JVM can hit swapping and thrashing at which point everything will run slowly.
-
Use one instance of IndexSearcher.
Share a single IndexSearcher across queries and across threads in your application.
-
When measuring performance, disregard the first query.
The first query to a searcher pays the price of initializing caches (especially when sorting by fields) and thus will skew your results (assuming you re-use the searcher for many queries). On the other hand, if you re-run the same query again and again, results won't be realistic either, because the operating system will use its cache to speed up IO operations. On Linux (kernel 2.6.16 and later) you can clean the disk cache usingsync ; echo 3 > /proc/sys/vm/drop_caches. See http://linux-mm.org/Drop_Caches for details.
-
Re-open the IndexSearcher only when necessary.
You must re-open the IndexSearcher in order to make newly committed changes visible to searching. However, re-opening the searcher has a certain overhead (noticeable mostly with large indexes and with sorting turned on) and should thus be minimized. Consider using a so called warming technique which allows the searcher to warm up its caches before the first query hits.
-
Decrease mergeFactor. Smaller mergeFactors mean fewer segments and searching will be faster. However, this will slow down indexing speed, so you should test values to strike an appropriate balance for your application.
-
Limit usage of stored fields and term vectors. Retrieving these from the index is quite costly. Typically you should only retrieve these for the current "page" the user will see, not for all documents in the full result set. For each document retrieved, Lucene must seek to a different location in various files. Try sorting the documents you need to retrieve by docID order first.
-
Use FieldSelector to carefully pick which fields are loaded, and how they are loaded, when you retrieve a document.
-
Don't iterate over more hits than needed.
Iterating over all hits is slow for two reasons. Firstly, the search() method that returns a Hits object re-executes the search internally when you need more than 100 hits. Solution: use the search method that takes a HitCollector instead. Secondly, the hits will probably be spread over the disk so accessing them all requires much I/O activity. This cannot easily be avoided unless the index is small enough to be loaded into RAM. If you don't need the complete documents but only one (small) field you could also use the FieldCache class to cache that one field and have fast access to it.
-
When using fuzzy queries use a minimum prefix length.
Fuzzy queries perform CPU-intensive string comparisons - avoid comparing all unique terms with the user input by only examining terms starting with the first "N" characters. This prefix length is a property on both QueryParser and FuzzyQuery - default is zero so ALL terms are compared.
-
Consider using filters. It can be much more efficient to restrict results to a part of the index using a cached bit set filter rather than using a query clause. This is especially true for restrictions that match a great number of documents of a large index. Filters are typically used to restrict the results to a category but could in many cases be used to replace any query clause. One difference between using a Query and a Filter is that the Query has an impact on the score while a Filter does not.
-
Find the bottleneck.
Complex query analysis or heavy post-processing of results are examples of hidden bottlenecks for searches. Profiling with at tool such as VisualVM helps locating the problem.
Java NIO通信框架在电信领域的实践
Netty是业界最流行的NIO框架之一,它的健壮性、功能、性能、可定制性和可扩展性在同类框架中都是首屈一指的,它已经得到成百上千的商用项目验证,例如Hadoop的RPC框架avro使用Netty作为底层通信框架;很多其他业界主流的RPC框架,也使用Netty来构建高性能的异步通信能力。
通过对Netty的分析,我们将它的优点总结如下:
1) API使用简单,开发门槛低;
2) 功能强大,预置了多种编解码功能,支持多种主流协议;
3) 定制能力强,可以通过ChannelHandler对通信框架进行灵活地扩展;
4) 性能高,通过与其他业界主流的NIO框架对比,Netty的综合性能最优;
5) 成熟、稳定,Netty修复了已经发现的所有JDK NIO BUG,业务开发人员不需要再为NIO的BUG而烦恼;
6) 社区活跃,版本迭代周期短,发现的BUG可以被及时修复,同时,更多的新功能会加入;
7) 经历了大规模的商业应用考验,质量得到验证。在互联网、大数据、网络游戏、企业应用、电信软件等众多行业得到成功商用,证明了它已经完全能够满足不同行业的商业应用了。
正是因为这些优点,Netty逐渐成为Java NIO编程的首选框架,它也是华为公司首选的Java NIO通信框架,公司已经将其纳入到公司级的优选开源第三方软件库中。
3. Netty在电信领域的实践
电信行业软件的几个特点:
1) 高可靠性:5个9;
2) 高性能、低时延;
3) 大规模组网:例如中国移动、Telfonica 拉美十三国、沃达丰等,业务组网规模都非常大;
4) 复杂的网络形态:对接不同设备提供商的网元和系统。
3.1. 高性能、低时延
3.1.1. 非阻塞I/O模型
在I/O编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者I/O多路复用技术进行处理。I/O多路复用技术通过把多个I/O的阻塞复用到同一个select的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。与传统的多线程/多进程模型比,I/O多路复用的最大优势是系统开销小,系统不需要创建新的额外进程或者线程,也不需要维护这些进程和线程的运行,降低了系统的维护工作量,节省了系统资源。
我们采用Netty的NIO传输模式来提升I/O操作的效率,节省线程等其它资源开销,它的模型如下所示:

图3-1 Netty的非阻塞I/O调度模型
3.1.2. 高性能的序列化框架
在华为软件,对于序列化框架的选择,我们遵循如下几个原则:
1) 序列化后的码流大小(网络带宽的占用);
2) 序列化&反序列化的性能(CPU、内存等资源占用);
3) 是否支持跨语言(异构系统的对接和开发语言切换);
4) 高并发调用时的性能,是否随着线程并发数线性增长。
基于上述的指标,目前最常用的选择是:Google的ProtoBuf和Apache的Thrift。
Netty原生提供了对ProtoBuf序列化框架的支持,它的优点如下:
1) 在谷歌内部长期使用,产品成熟度高;
2) 跨语言、支持多种语言,包括C++、Java和Python;
3) 编码后的消息更小,更加有利于存储和传输;
4) 编解码的性能非常高;
5) 支持不同协议版本的前向兼容;
6) 支持定义可选和必选字段。
Netty ProtoBuf 服务端开发示例如下:
// 配置服务端的NIO线程组
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 100)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(
new ProtobufVarint32FrameDecoder());
ch.pipeline().addLast(
new ProtobufDecoder(
SubscribeReqProto.SubscribeReq
.getDefaultInstance()));
ch.pipeline().addLast(
new ProtobufVarint32LengthFieldPrepender());
ch.pipeline().addLast(new ProtobufEncoder());
ch.pipeline().addLast(new SubReqServerHandler());
}
});
Thrift相对复杂一些,需要将编解码框架从Thrift中剥离出来,然后利用Netty编解码框架的扩展性定制实现,在此不再赘述。
3.1.3. 收敛的Reactor线程模型
Java线程采用抢占的方式争夺CPU等资源,当系统线程数增大到一定量级之后,性能不仅没有提升,反而下降。
对于大型的电信应用,如果使用Tomcat等做Web容器,为了保证吞吐量和性能,HTTP线程池的最大线程数往往配置为1024。在系统运行期间我们Dump线程堆栈,发现大量的线程竞争,这不仅导致HTTP协议栈的性能下降,更影响其它业务处理线程的执行效率。
使用Netty之后,我们通过控制NioEventLoopGroup的NioEventLoop个数来收敛线程,防止线程膨胀。NioEventLoop聚合了一个多路复用器Selector,可以高效的处理N个Channel,它的线程模型如下:

图3-1 Netty Reactor线程模型
3.1.4. 其它优化
为了进一步提升性能,降低时延,我们还采用了其它一些优化措施,总结如下:
1) 使用Netty 4的内存池,减少业务高峰期ByteBuf频繁创建和销毁导致的GC频率和时间;
2) 在程序中充分利用Netty提供的“零拷贝”特性,减少额外的内存拷贝,例如使用CompositeByteBuf而不是分别为Head和Body各创建一个ByteBuf对象;
3) TCP参数的优化,设置合理的Send和Receive Buffer,通常建议值为64K - 128K;
4) 软中断:如果Linux内核版本支持RPS(2.6.35以上版本),开启RPS后可以实现软中断,提升网络吞吐量;
5) 无锁化串行开发理念:使用Netty 4.X版本,天生支持串行化处理;业务开发过程中,遵循Netty 4的线程模型优化理念,防止人为增加线程竞争。
3.2. 高HA
3.2.1. 内存保护
为了提升内存的利用率,Netty提供了内存池和对象池。但是,基于缓存池实现以后需要对内存的申请和释放进行严格的管理,否则很容易导致内存泄漏。
如果不采用内存池技术实现,每次对象都是以方法的局部变量形式被创建,使用完成之后,只要不再继续引用它,JVM会自动释放。但是,一旦引入内存池机制,对象的生命周期将由内存池负责管理,这通常是个全局引用,如果不显式释放JVM是不会回收这部分内存的。
对于Netty的用户而言,使用者的技术水平差异很大,一些对JVM内存模型和内存泄漏机制不了解的用户,可能只记得申请内存,忘记主动释放内存,特别是JAVA程序员。
为了防止因为用户遗漏导致内存泄漏,Netty在Pipe line的尾Handler中自动对内存进行释放。
缓冲区内存溢出保护:做过协议栈的读者都知道,当我们对消息进行解码的时候,需要创建缓冲区。缓冲区的创建方式通常有两种:
1) 容量预分配,在实际读写过程中如果不够再扩展;
2) 根据协议消息长度创建缓冲区。
在实际的商用环境中,如果遇到畸形码流攻击、协议消息编码异常、消息丢包等问题时,可能会解析到一个超长的长度字段。笔者曾经遇到过类似问题,报文长度字段值竟然是2G多,由于代码的一个分支没有对长度上限做有效保护,结果导致内存溢出。系统重启后几秒内再次内存溢出,幸好及时定位出问题根因,险些酿成严重的事故。
Netty提供了编解码框架,因此对于解码缓冲区的上限保护就显得非常重要。下面,我们看下Netty是如何对缓冲区进行上限保护的:
1) 在内存分配的时候指定缓冲区长度上限;
2) 在对缓冲区进行写入操作的时候,如果缓冲区容量不足需要扩展,首先对最大容量进行判断,如果扩展后的容量超过上限,则拒绝扩展;
3) 在解码的时候,对消息长度进行判断,如果超过最大容量上限,则抛出解码异常,拒绝分配内存。
3.2.2. 流量整形
电信系统一般都有多个网元组成,例如参与短信互动,会涉及到手机、基站、短信中心、短信网关、SP/CP等网元。不同网元或者部件的处理性能不同。为了防止因为浪涌业务或者下游网元性能低导致下游网元被压垮,有时候需要系统提供流量整形功能。
流量整形(Traffic Shaping)是一种主动调整流量输出速率的措施。一个典型应用是基于下游网络结点的TP指标来控制本地流量的输出。流量整形与流量监管的主要区别在于,流量整形对流量监管中需要丢弃的报文进行缓存——通常是将它们放入缓冲区或队列内,也称流量整形(Traffic Shaping,简称TS)。当令牌桶有足够的令牌时,再均匀的向外发送这些被缓存的报文。流量整形与流量监管的另一区别是,整形可能会增加延迟,而监管几乎不引入额外的延迟。
流量整形的原理示意图如下:

图3-2 Netty 流量整形原理图
Netty内置两种流量整形策略,可以方便的被用户添加和使用:
1) 全局流量整形的作用范围是进程级的,无论你创建了多少个Channel,它的作用域针对所有的Channel。用户可以通过参数设置:报文的接收速率、报文的发送速率、整形周期;
2) 单链路流量整形与全局流量整形的最大区别就是它以单个链路为作用域,可以对不同的链路设置不同的整形策略,整形参数与全局流量整形相同。
3.2.3. 其它可靠性措施
其它比较重要的可靠性措施如下:
1) 客户端连接超时控制策略;
2) 链路断连重连策略;
3) 链路异常关闭资源释放;
4) 解码失败的异常处理策略;
5) 链路异常的捕获和处理;
6) I/O线程的释放。
参考:
http://www.infoq.com/cn/articles/netty-high-performance
http://normanmaurer.me/presentations/2014-facebook-eng-netty/slides.html
【亲述】Uber容错设计与多机房容灾方案 - 高可用架构系列
此文是根据赵磊在【QCON高可用架构群】中的分享内容整理而成,转发请注明来自公众号高可用架构(ArchNotes)。
赵磊,Uber高级工程师,08年上海交通大学毕业,曾就职于微软,后加入Facebook主要负责Messenger的后端消息服务。这个系统在当时支持Facebook全球5亿人同时在线。目前在Uber负责消息系统的构建并推进核心服务在高可用性方向的发展。
前言
赵磊在7月21号的全球架构师峰会深圳站上,做了主题演讲:Uber高可用消息系统构建,对于这个热门主题,高可用架构群展开了热议,大家对分布式系统中的各种错误处理非常感兴趣。Tim Yang特邀赵磊通过微信群,在大洋彼岸的硅谷给大家进一步分享。
分布式系统单点故障怎么办
non-sharded, stateless 类型服务非常容易解决单点故障。 通常load balancer可以按照固定的时间间隔,去health check每个node, 当某一个node出现故障时,load balancer可以把故障的node从pool中排除。
很多服务的health check设计成简单的TCP connect, 或者用HTTP GET的方式,去ping一个特定的endpoint。当业务逻辑比较复杂时,可能业务endpoint故障,但是health endpoint还能正常返回,导致load balancer无法发现单点故障,这种情况可以考虑在health check endpoint中增加简单的业务逻辑判断。
对于短时间的network故障,可能会导致这段时间很多RPC call failures。 在RPC client端通常会实现backoff retry。 failure可能有几种原因:
-
TCP connect fail,这种情况下retry不会影响业务逻辑,因为Handler还没有执行。
-
receive timeout, client无法确定handler是不是已经收到了request 而且处理了request,如果handler重复执行会产生side effect,比如database write或者访问其他的service, client retry可能会影响业务逻辑。
对于sharded service,关键是如何找到故障点,而且将更新的membership同步到所有的nodes。下面讨论几种sharding的方案:
-
将key space hash到很多个小的shard space, 比如4K个shards。 通过zookeeper (distributed mutex) 选出一个master,来将shard分配到node上,而且health check每一个node。当遇到单点故障时,将已经assigned的shards转移到其他的nodes上。 因为全局只有一个single master, 从而保证了shard map的全局一致。当master故障时,其他的backup node会获得lock成为Master
-
Consistent hashing方式。consistent hashing 通常用来实现cache cluster,不保证一致性。 因为每个client会独立health check每一个node, 同时更新局部的membership。 在network partition的情况或者某一个node不停的重启, 很可能不同的client上的membership不一致,从而将相同的key写在了不同的node上。 当一致性的需求提高时,需要collaborative health check, 即每个node要monitor所有其他node的health。 Uber在这里使用的是gossip protocol,node之间交换health check的信息。
大面积故障怎么办
大面积故障时,比如交换机故障(rack switch failure),可用的机器不足以处理所有的请求。 我们尽可能做的就是用50%的capacity 处理50%的请求或者50%用户的所有请求。而尽量避免整个服务故障。 当设计一个服务的时候,它的throughput应该是可linear scale的。
-
在同样的CPU占用情况下,1个机器应该处理100个请求,那么5个机器应该可以处理500个请求。
-
而且在同样的机器数量下,20%的CPU可以处理200个请求,那么60%的CPU应该可以处理3倍即600个请求。
后者是很难实现的,而且当CPU越高的时候,服务的throughput并不是线性的。 通常在80%CPU以上的情况,throughput会下降非常快。 随着CPU使用增加,request的latency也会提高。 这对上下游的服务可能都是一个挑战,可能会导致cascade failure。
对于nodejs或者java nio一类的async IO框架来说,另外一个问题就是event loop lag。 这两者可能导致connection数量增加。下面举两个例子
-
有些RPC transport支持pipelining但不支持multiplexing (out of order responses), pipelining是指在同一个TCP连接上可以连续发出Req1, Req2, Req3, Response1, Response2, Response3,即Response的顺序必须和Request的顺序是一致。Req1如果需要很长时间,Req2和3就都不能返回。一个Request如果占用太长时间,会导致后面的很多个Request timeout。RPC client通常也会限制在一个TCP connection上面的max pending requests。但timeout发生,或者max pending requests情况下,client会主动创建新的connection。
-
event loop lag 是指程序占用太长时间执行连续的CPU intensive任务。 只有当任务结束时,event loop才会handle IO events,比如从socket上面读数据。否则收到的数据只能保存在kernel 的TCP buffer里,通常这个buffer size小于64KB。当buffer满时(而且service又很长时间没有读buffer),socket的远端就不能发送更多的数据。这时也会导致远端的transport error。同样的,client会主动创建新的connection,当connection增加到预设的fd limit时,service就不能继续accept新的TCP connection了,其实是不能open新的文件了。而且,绝大部分的程序没有测试过达到fd limit的场景。很多API需要open file, 比如logging和core dump. 所以,一旦达到fd limit, 就像out of memory一样,将很难recover,只能crash process. 而这时正是过载的时候,重启实际上减少了capacity。 任何crash在过载的情况下只会更糟。
facebook在这防止过载上做的很好,在C++实现的thrift server上,有一个或者多个threads只负责accept TCP connections. 你可以指定最多的connections for thrift calls。 这个connection limit是远小于fd limit, 当connection太多时,thrift server可以fail fast。所以,这种情况下可以让service能一直保持在max qps。
整个数据中心挂掉怎么办
在Uber的场景中,如果rider已经在一个trip上了,我们通产会等trip结束后才把rider迁移到其他的数据中心,我们叫做soft failover。
否则需要hard failover,我们会把DNS指向其他的数据中心。 而且用户的DNS服务器很可能在一段时间内还是cache以前的ip,而且这个cache的时间是基本没办法控制的,所以我们会在load balancer上返回HTTP redirect,这样手机的客户端收到后会立即转向新的备份数据中心。
惊群问题(thundering herd), 很多服务在provision的时候根据平常的QPS预留了很少的容量空间,当数据中心或者load balancer重启的时候,如果所有的客户端同时发起请求,这时的QPS可以是平时的很多倍。 很可能导致大部分请求都失败。一方面需要在客户端实现exponential backoff, 即请求失败后retry的间隔时间是增长的,比如1秒,5秒,20秒等等。另外在load balancer上实现rate limiting或者global blackhole switch, 后者可以有效的丢掉一部分请求而避免过载,同时尽早触发客户端的backoff逻辑。
如果大家用AWS或者其他云服务的话,AWS的一个region通常包括几个数据中心。各个数据中心甚至在相邻的介个城市,有独立的空调系统和供电。
数据中心之间有独立的网络 high throughput low latency, 但是在region之间的网络通常是共有的 high throughput high lantecy
整个region挂掉很少发生。可以把服务部署在多个可用区(Availability Zone)来保证高可用性。
Q & A
Q1:health check endpoint中实现简单的业务逻辑,这个意思是load balancer中有业务逻辑检查的插件么?这样load balancer会不会很重啊,可以详细说一下么?
load balancer仍然是HTTP GET, health check 没有额外的开销,但是服务本身处理health的方式不同,可加入业务逻辑相关的检查 比如是不是能够访问数据库。
Q2:region切换时,用户的数据是怎么迁移的?
这个是个很好的问题,Uber采取的是个非常特别的方法。 realtime系统会在每次用户state change。state change的时候把新的state下载到手机上,而且是加密的。当用户需要迁移到新的数据中心的时候,手机需要上传之前下载的state,服务就可以从之前的state开始,但是non-realtime系统 比如用户数据是通过sql replication来同步的。是Master-master。而且Uber在上层有个数据抽象,数据是基本上immutable的 append-only 所以基本不存在冲突。
Q3:如果是req timeout,但另外一边已经执行成功了,这时候重试,那不就是产生了两次数据?特别是insert这种类型的。
是的,如果是GET类型的请求可以retry, 但是POST类型的请求 那么只能在conn timeout时可以安全的retry。 但是receive timeout不能重试。(Tim补充看法:对于POST请求,如果service实现了幂等操作也是可以retry)。 有些类型的数据可以自动merge比如set和map
Q4:那receive timeout,这种情况下,只能通过merge或者冲突对比解决?
恩 是的。 需要在逻辑层判断是不是能够retry。 这个我建议在更上层实现, 比如在消息系统中,全程不retry 就可以保证at most once delivery, 如果需要保证at least once delivery 需要加入数据库和client dedupe
Q5:大面积故障时Uber用什么手段来控制只处理部分用户请求?
我们实现了一些rate limiting 和 circuit breaking的库,但是这时针对所有请求的。 我们现在还没有做到只处理某些用户的请求。
Q6:“将key space hash到相对小的shard space, 因为全局只有一个single master, 从而保证了shard map的全局一致” 这个方案每次计算shard node的时候,必须先询问下master么?
是的。 在client端有一个shard map的cache, 每隔几秒钟可以refresh, 如果是复杂的实现,则可以是master 推送shardmap change。
Q7:多个机房的数据是sharding存储(就是每个机房只存储一部分用户数据),还是所有机房都有所有用户全量数据?
Uber现在的做法是每个机房有所有用户的数据。 facebook的做法是一个机房有一部分用户的数据。
Q8:那多个机房的数据同步采用什么方案?
facebook用的就是mysql replication,有些细节我不清楚。 Uber还没有跨数据中心的replication,但是我们考虑买riak的enterprise服务,可以支持跨数据中心的 replication。 对于sql数据 我们就2个方案:大部分用户数据还是在postgresql里的(没有sharding, 是个single node),因为Uber起家的时候就在postgres上,这个数据是用postgres原生支持的replication, 另外有个mysql的, mysql存的是trip的数据, 所以是append only而且不需要merge的。 这个我还需要确认是不是每个数据中心里面有全量的数据还是只有本地产生的trip数据
Uber数据抽象做的比较好,数据分为3类:
最小的 realtime的,跟ongoing trip的个数成正比。 正在迁移到riak
比较大 非realtime的,跟user个数成正比。在postgresql里面 用postgresql的relication,正在迁移到mysql,用mysql的replication
最大 非realtime的,跟trip个数成正比。 在MySQL里面有很多partition,一个用户在一个partitionl里面,一个partition一个全局的master,写都去master。 而且Partition很少迁移,所以当seconary变成Master时,可能没有用户之前的trip的信息,replication是offline的 好像是通过backup-restore实现的。
Q9: 那如何实现“每个机房都有全量数据”的?
不是实时的,是在应用层实现的,而且现在还没开始大规模使用。 另外问下riak 有同学在用么? Uber 的很多系统去年就开始迁移到riak上了,因为riak是保证availability的 。将来在Uber会是重点
Q10:Uber的消息系统是基于nodejs的吗?客户端长链接的性能和效率方面如何优化?
是基于nodejs的。我们没有特别优化性能,不过stress test看起来2个物理机可以保持800K连接
Q11:Uber消息系统协议自己DIY吗? 是否基于TLS? PUSH消息QPS能达到多少?
是的,基于HTTPS。 具体QPS我不太记得了。
Q12:riak的性能如何?主要存储哪些类型的数据呢?存储引擎用什么?raik的二级索引有没有用到呢?
riak性能我没测试过,跟数据类型和consistency level都有关系。 可能差别比较大。 我们现在用的好像是leveldb
Q13:应用层实现多机房数据一致的话,是同时多写吗? 这个latency会不会太长?
sql现在都是用在non-realtime系统里面,所以latency可能会比较长
Q14:Uber rpc用的什么框架,上面提到了Thrift有好的fail fast策略,Uber有没有在rpc框架层面进行fail fast设计?
Uber在RPC方面还刚开始。 我们一直是用http+json的,最近在朝tchannel+thrift发展, tchannel是一个类似http2.0的transport,tchannel 在github上能找到。
我们的nodejs thrift 是自己实现的,因为apache thrift在node上做的不是很好,thrift的实现叫做thriftify https://github.com/Uber/thriftify
正好推荐下我的开源项目哈。 在thrift server上我们没有做fail fast, 如何保护是在routing service中实现的。
Q15:Uber走https协议,有没有考虑spdy/http2.0之类的呢?在中国网速状况不是很好的,Uber有没有一些https连接方面的优化措施?
正在考虑迁移到HTTP2.0,这个主要是手机端有没有相应的client实现。 server端我们用的是nginx,nginx上有个experiemnt quality的extension可以支持spdy。 我们还考虑过用facebook的proxygen https://github.com/facebook/proxygen,proxygen支持spdy。 我在facebook的chat service是用proxygen实现的,而且facebook 几十万台PHP server都在proxygen上,所以可以说是工业级强度的基础设施,不过build起来要花点时间。
Q16:为了避免服务过载和cascade failure,除了在服务链的前端采用一些fail fast 的设计,还有没有其它的实践作法,比如还是想支持一部分用户或特定类型的请求,采用优先级队列等。 就这个问题,Uber,facebook在服务化系统中还有没有其它技术实践?另外出现大规模服务过载后的恢复流程方面,有没有碰到什么坑或建议?
“比如还是想支持一部分用户或特定类型的请求” 这个其实比较难实现 因为当服务过载的时候 在acceptor thread就停止接受新的connection了,那就不知道是哪个用户的请求 。这个需要在应】用层实现,比如feature flag可以针对一些用户关掉一些feature。 我发现有个很有用的东西就是facebook有个global kill switch,可以允许x%的流量,这个当所有service一起crash 重启的时候比较有用。
TIP:为了更好的理解赵磊的分享内容,大家可以参照ArchSummit 2015深圳赵磊的的ppt一起来理解。ppt可以通过stuq.org下载或微信添加”stuq”公众号。
想同赵磊及群专家进一步交流容错设计及多机房容灾方案,可回复arch申请进群。
利用 DexClassLoader 实现 Android 插件化,从而达到动态加载
1、作用
大多数朋友开始接触这个问题是因为 App 爆棚了,方法数超过了一个 Dex 最大方法数 65535 的上限,因而便有了插件化的概念,将一个 App 划分为多个插件(Apk 或相关格式)
常用的其他解决方法还包括:Google Multidex,用 H5 代替部分逻辑,删无用代码,买付费版的 Proguard
当插件化作用不止于此,还包括:(1) 模块解耦,(2) 动态升级,(3) 高效并行开发(编译速度更快) (4) 按需加载,内存占用更低 (5) 节省升级流量
2、概念
Android 插件化 —— 指将一个程序划分为不同的部分,比如一般 App 的皮肤样式就可以看成一个插件
Android 组件化 —— 这个概念实际跟上面相差不那么明显,组件和插件较大的区别就是:组件是指通用及复用性较高的构件,比如图片缓存就可以看成一个组件被多个 App 共用
Android 动态加载 —— 这个实际是更高层次的概念,也有叫法是热加载或 Android 动态部署,指容器(App)在运⾏状态下动态加载某个模块,从而新增功能或改变某⼀部分行为
3、相关资料
插件化的原理实际是 Java ClassLoader 的原理,看其他资料前请先看:Java ClassLoader基础
Android 也有自己的 ClassLoader,分为 dalvik.system.DexClassLoader 和 dalvik.system.PathClassLoader,区别在于 PathClassLoader 不能直接从 zip 包中得到 dex,因此只支持直接操作 dex 文件或者已经安装过的 apk(因为安装过的 apk 在 cache 中存在缓存的 dex 文件)。而 DexClassLoader 可以加载外部的 apk、jar 或 dex文件,并且会在指定的 outpath 路径存放其 dex 文件。
目前开源的插件化框架有:
(1) DynamicLoadApk
GitHub:https://github.com/singwhatiwanna/dynamic-load-apk
这个项目实现了一部分的动态加载,原理是 DexClassLoader 加 Activity 代理,可以看看。即在容器中注册几个代理的 Activity,启动插件的 Activity 时实际启动的都是代理的 Activity,这样就解决了 Activity 必须注册的问题。
当然这个项目里也有不少问题没解决,有兴趣可以加入他们。
(2) AndroidDynamicLoader GitHub:https://github.com/mmin18/AndroidDynamicLoader
这是点评一个工程师介绍的方式,和上面不同的是:他不是用代理 Activity 的方式实现而是用 Fragment 以及 schema 的方式实现
(3) Android PluginManager GitHub:https://github.com/houkx/android-pluginmgr
这个项目的原理实际也是 DexClassLoader 加 Activity 代理,不同的是上面的 dynamic-load-apk 项目中,插件需要依赖框架的 lib,插件组件继承框架 lib 的 Base 组件。而这个框架通过字节码操作动态生成一个子类去继承插件组件解决插件必须依赖框架的问题,从而达到插件无需做任何改动(理论上)即可加载的效果。
(4) 其他资料
淘宝伯奎:Android插件化及动态部署—ATLAS http://v.youku.com/v_show/id_XNTMzMjYzMzM2.html
Netty 长连接服务
推送服务
还记得一年半前,做的一个项目需要用到 Android 推送服务。和 iOS 不同,Android 生态中没有统一的推送服务。Google 虽然有 Google Cloud Messaging ,但是连国外都没统一,更别说国内了,直接被墙。
所以之前在 Android 上做推送大部分只能靠轮询。而我们之前在技术调研的时候,搜到了 jPush 的博客,上面介绍了一些他们的技术特点,他们主要做的其实就是移动网络下的长连接服务。单机 50W-100W 的连接的确是吓我一跳!后来我们也采用了他们的免费方案,因为是一个受众面很小的产品,所以他们的免费版够我们用了。一年多下来,运作稳定,非常不错!
时隔两年,换了部门后,竟然接到了一项任务,优化公司自己的长连接服务端。
再次搜索网上技术资料后才发现,相关的很多难点都被攻破,网上也有了很多的总结文章,单机 50W-100W 的连接完全不是梦,其实人人都可以做到。但是光有连接还不够,QPS 也要一起上去。
所以,这篇文章就是汇总一下利用 Netty 实现长连接服务过程中的各种难点和可优化点。
Netty 是什么
Netty: http://netty.io/
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
官方的解释最精准了,期中最吸引人的就是高性能了。但是很多人会有这样的疑问:直接用 NIO 实现的话,一定会更快吧?就像我直接手写 JDBC 虽然代码量大了点,但是一定比 iBatis 快!
但是,如果了解 Netty 后你才会发现,这个还真不一定!
利用 Netty 而不用 NIO 直接写的优势有这些:
- 高性能高扩展的架构设计,大部分情况下你只需要关注业务而不需要关注架构
Zero-Copy技术尽量减少内存拷贝- 为 Linux 实现 Native 版 Socket
- 写同一份代码,兼容 java 1.7 的 NIO2 和 1.7 之前版本的 NIO
Pooled Buffers大大减轻声请Buffer和释放Buffer的压力- ……
特性太多,大家可以去看一下《Netty in Action》这本书了解更多。
另外,Netty 源码是一本很好的教科书!大家在使用的过程中可以多看看它的源码,非常棒!
瓶颈是什么
想要做一个长链服务的话,最终的目标是什么?而它的瓶颈又是什么?
其实目标主要就两个:
- 更多的连接
- 更高的 QPS
所以,下面就针对这连个目标来说说他们的难点和注意点吧。
更多的连接
非阻塞 IO
其实无论是用 Java NIO 还是用 Netty,达到百万连接都没有任何难度。因为它们都是非阻塞的 IO,不需要为每个连接创建一个线程了。
欲知详情,可以搜索一下BIO,NIO,AIO的相关知识点。
Java NIO 实现百万连接
ServerSocketChannel ssc = ServerSocketChannel.open();
Selector sel = Selector.open();
ssc.configureBlocking(false);
ssc.socket().bind(new InetSocketAddress(8080));
SelectionKey key = ssc.register(sel, SelectionKey.OP_ACCEPT);
while(true) {
sel.select();
Iterator it = sel.selectedKeys().iterator();
while(it.hasNext()) {
SelectionKey skey = (SelectionKey)it.next();
it.remove();
if(skey.isAcceptable()) {
ch = ssc.accept();
}
}
}
这段代码只会接受连过来的连接,不做任何操作,仅仅用来测试待机连接数极限。
大家可以看到这段代码是 NIO 的基本写法,没什么特别的。
Netty 实现百万连接
NioEventLoopGroup bossGroup = new NioEventLoopGroup();
NioEventLoopGroup workerGroup= new NioEventLoopGroup();
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup);
bootstrap.channel( NioServerSocketChannel.class);
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//todo: add handler
}});
bootstrap.bind(8080).sync();
这段其实也是非常简单的 Netty 初始化代码。同样,为了实现百万连接根本没有什么特殊的地方。
瓶颈到底在哪
上面两种不同的实现都非常简单,没有任何难度,那有人肯定会问了:实现百万连接的瓶颈到底是什么?
其实只要 java 中用的是非阻塞 IO(NIO 和 AIO 都算),那么它们都可以用单线程来实现大量的 Socket 连接。 不会像 BIO 那样为每个连接创建一个线程,因为代码层面不会成为瓶颈。
其实真正的瓶颈是在 Linux 内核配置上,默认的配置会限制全局最大打开文件数(Max Open Files)还会限制进程数。 所以需要对 Linux 内核配置进行一定的修改才可以。
这个东西现在看似很简单,按照网上的配置改一下就行了,但是大家一定不知道第一个研究这个人有多难。
这里直接贴几篇文章,介绍了相关配置的修改方式:
如何验证
让服务器支持百万连接一点也不难,我们当时很快就搞定了一个测试服务端,但是最大的问题是,我怎么去验证这个服务器可以支撑百万连接呢?
我们用 Netty 写了一个测试客户端,它同样用了非阻塞 IO ,所以不用开大量的线程。 但是一台机器上的端口数是有限制的,用root权限的话,最多也就 6W 多个连接了。 所以我们这里用 Netty 写一个客户端,用尽单机所有的连接吧。
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
Bootstrap b = new Bootstrap();
b.group(workerGroup);
b.channel( NioSocketChannel.class);
b.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//todo:add handler
}
});
for (int k = 0; k < 60000; k++) {
//请自行修改成服务端的IP
b.connect(127.0.0.1, 8080);
}
代码同样很简单,只要连上就行了,不需要做任何其他的操作。
这样只要找到一台电脑启动这个程序即可。这里需要注意一点,客户端最好和服务端一样,修改一下 Linux 内核参数配置。
怎么去找那么多机器
按照上面的做法,单机最多可以有 6W 的连接,百万连接起码需要17台机器!
如何才能突破这个限制呢?其实这个限制来自于网卡。 我们后来通过使用虚拟机,并且把虚拟机的虚拟网卡配置成了桥接模式解决了问题。
根据物理机内存大小,单个物理机起码可以跑4-5个虚拟机,所以最终百万连接只要4台物理机就够了。
讨巧的做法
除了用虚拟机充分压榨机器资源外,还有一个非常讨巧的做法,这个做法也是我在验证过程中偶然发现的。
根据 TCP/IP 协议,任何一方发送FIN后就会启动正常的断开流程。而如果遇到网络瞬断的情况,连接并不会自动断开。
那我们是不是可以这样做?
- 启动服务端,千万别设置 Socket 的
keep-alive属性,默认是不设置的 - 用虚拟机连接服务器
- 强制关闭虚拟机
- 修改虚拟机网卡的 MAC 地址,重新启动并连接服务器
- 服务端接受新的连接,并保持之前的连接不断
我们要验证的是服务端的极限,所以只要一直让服务端认为有那么多连接就行了,不是吗?
经过我们的试验后,这种方法和用真实的机器连接服务端的表现是一样的,因为服务端只是认为对方网络不好罢了,不会将你断开。
另外,禁用keep-alive是因为如果不禁用,Socket 连接会自动探测连接是否可用,如果不可用会强制断开。
更高的 QPS
由于 NIO 和 Netty 都是非阻塞 IO,所以无论有多少连接,都只需要少量的线程即可。而且 QPS 不会因为连接数的增长而降低(在内存足够的前提下)。
而且 Netty 本身设计得足够好了,Netty 不是高 QPS 的瓶颈。那高 QPS 的瓶颈是什么?
是数据结构的设计!
如何优化数据结构
首先要熟悉各种数据结构的特点是必需的,但是在复杂的项目中,不是用了一个集合就可以搞定的,有时候往往是各种集合的组合使用。
既要做到高性能,还要做到一致性,还不能有死锁,这里难度真的不小…
我在这里总结的经验是,不要过早优化。优先考虑一致性,保证数据的准确,然后再去想办法优化性能。
因为一致性比性能重要得多,而且很多性能问题在量小和量大的时候,瓶颈完全会在不同的地方。 所以,我觉得最佳的做法是,编写过程中以一致性为主,性能为辅;代码完成后再去找那个 TOP1,然后去解决它!
解决 CPU 瓶颈
在做这个优化前,先在测试环境中去狠狠地压你的服务器,量小量大,天壤之别。
有了压力测试后,就需要用工具来发现性能瓶颈了!
我喜欢用的是 VisualVM,打开工具后看抽样器(Sample),根据自用时间(Self Time (CPU))倒序,排名第一的就是你需要去优化的点了!
备注:Sample 和 Profiler 有什么区别?前者是抽样,数据不是最准但是不影响性能;后者是统计准确,但是非常影响性能。 如果你的程序非常耗 CPU,那么尽量用 Sample,否则开启 Profiler 后降低性能,反而会影响准确性。
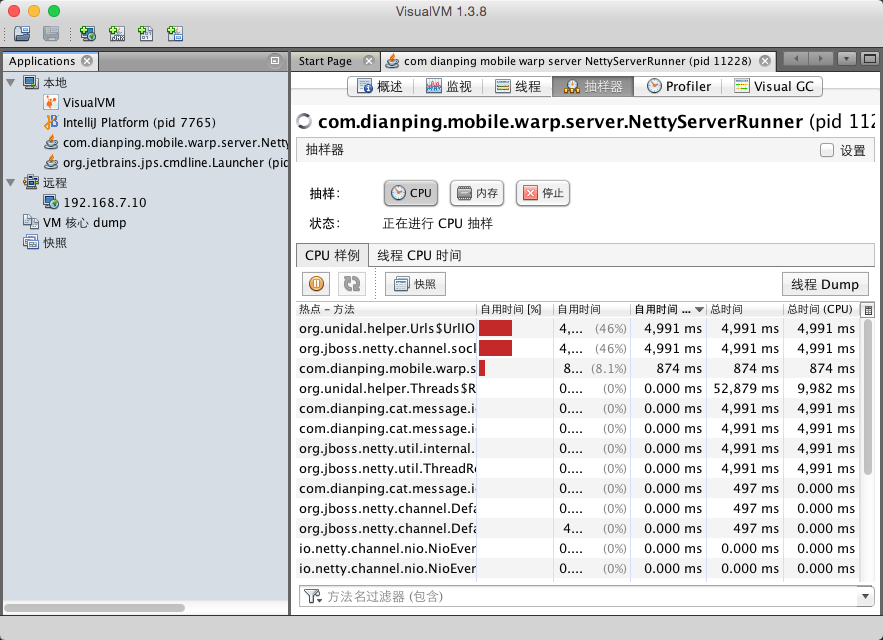
还记得我们项目第一次发现的瓶颈竟然是ConcurrentLinkedQueue这个类中的size()方法。 量小的时候没有影响,但是Queue很大的时候,它每次都是从头统计总数的,而这个size()方法我们又是非常频繁地调用的,所以对性能产生了影响。
size()的实现如下:
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
return count;
}
后来我们通过额外使用一个AtomicInteger来计数,解决了问题。但是分离后岂不是做不到高一致性呢? 没关系,我们的这部分代码关心最终一致性,所以只要保证最终一致就可以了。
总之,具体案例要具体分析,不同的业务要用不同的实现。
解决 GC 瓶颈
GC 瓶颈也是 CPU 瓶颈的一部分,因为不合理的 GC 会大大影响 CPU 性能。
这里还是在用 VisualVM,但是你需要装一个插件:VisualGC
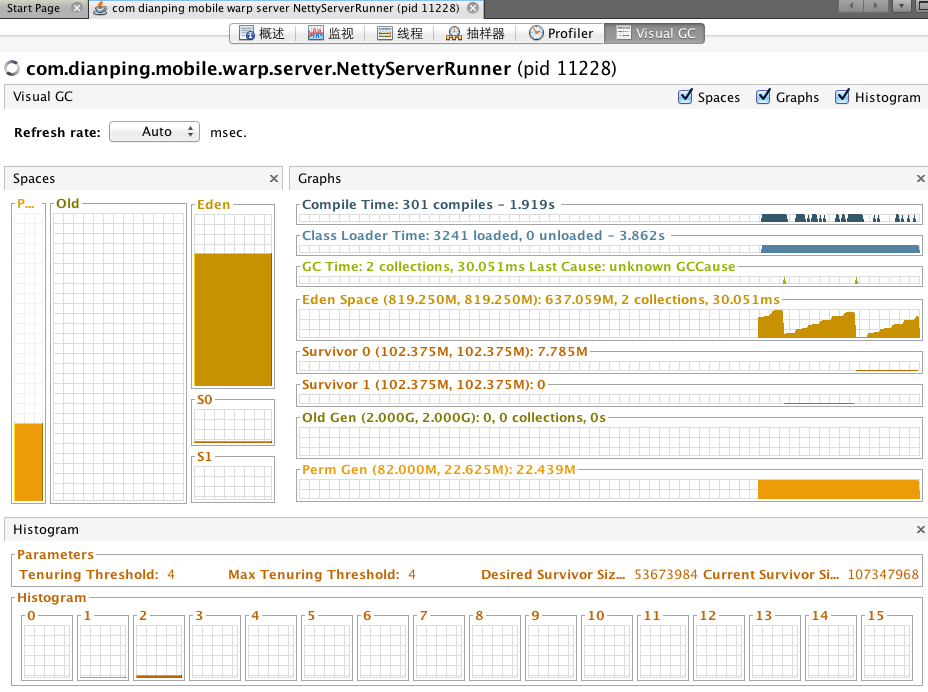
有了这个插件后,你就可以直观的看到 GC 活动情况了。
按照我们的理解,在压测的时候,有大量的 New GC 是很正常的,因为有大量的对象在创建和销毁。
但是一开始有很多 Old GC 就有点说不过去了!
后来发现,在我们压测环境中,因为 Netty 的 QPS 和连接数关联不大,所以我们只连接了少量的连接。内存分配得也不是很多。
而 JVM 中,默认的新生代和老生代的比例是1:2,所以大量的老生代被浪费了,新生代不够用。
通过调整 -XX:NewRatio 后,Old GC 有了显著的降低。
但是,生产环境又不一样了,生产环境不会有那么大的 QPS,但是连接会很多,连接相关的对象存活时间非常长,所以生产环境更应该分配更多的老生代。
总之,GC 优化和 CPU 优化一样,也需要不断调整,不断优化,不是一蹴而就的。
其他优化
如果你已经完成了自己的程序,那么一定要看看《Netty in Action》作者的这个网站:Netty Best Practices a.k.a Faster == Better。
相信你会受益匪浅,经过里面提到的一些小小的优化后,我们的整体 QPS 提升了很多。
最后一点就是,java 1.7 比 java 1.6 性能高很多!因为 Netty 的编写风格是事件机制的,看似是 AIO。 可 java 1.6 是没有 AIO 的,java 1.7 是支持 AIO 的,所以如果用 java 1.7 的话,性能也会有显著提升。
最后成果
经过几周的不断压测和不断优化了,我们在一台16核、120G内存(JVM只分配8G)的机器上,用 java 1.6 达到了60万的连接和20万的QPS。
其实这还不是极限,JVM 只分配了8G内存,内存配置再大一点连接数还可以上去;
QPS 看似很高,System Load Average 很低,也就是说明瓶颈不在 CPU 也不在内存,那么应该是在 IO 了! 上面的 Linux 配置是为了达到百万连接而配置的,并没有针对我们自己的业务场景去做优化。
因为目前性能完全够用,线上单机 QPS 最多才 1W,所以我们先把精力放在了其他地方。 相信后面我们还会去继续优化这块的性能,期待 QPS 能有更大的突破!
分享转发:做股票应懂的十二条投资数学_巴曙松
做股票的应该懂这12条投资数学
1、关于收益率
假如你有100万,收益100%后资产达到200万,如果接下来亏损50%,则资产回到100万,显然亏损50%比赚取100%要容易得多。
2、关于涨跌停
假如你有100万,第一天涨停板后资产达到110万,然后第二天跌停,则资产剩余99万;反之第一天跌停,第二天涨停,资产还是99万元。
3、关于波动性
假如你有100万,第一年赚40%,第二年亏20%,第三年赚40%,第四年亏20%,第五年赚40%,第六年亏20%,资产剩余140.5万元,六年年化收益率仅为5.83%,甚至低于五年期凭证式国债票面利率。
4、关于每天1%
假如你有100万,每天不需要涨停板,只需要挣1%就离场,那么以每年250个交易日计算,一年下来你的资产可以达到1203.2万,两年后你就可以坐拥1.45亿。
5、关于每年200%
假如你有100万,连续5年每年200%收益率,那么5年后你也可以拥有2.43亿元个人资产,显然这样高额收益是很难持续的。
6、关于10年10倍
假如你有100万,希望十年后达到1000万,二十年达到1亿元,三十年达到10亿元,那么你需要做到年化收益率25.89%。
7、关于补仓
如果你在某只股票10元的时候买入1万元,如今跌到5元再买1万元,持有成本可以降到6.67元,而不是你想象中的7.50元。
8、关于持有成本
如果你有100万元,投资某股票盈利10%,当你做卖出决定的时候可以试着留下10万元市值的股票,那么你的持有成本将降为零,接下来你就可以毫无压力的长期持有了。
如果你极度看好公司的发展,也可以留下20万市值的股票,你会发现你的盈利从10%提升到了100%,不要得意,因为此时股票如果下跌超过了50%,你还是有可能亏损。
9、关于资产组合
有无风险资产A(每年5%)和风险资产B(每年-20%至40%),如果你有100万,你可以投资80万无风险资产A和20万风险资产B,那么你全年最差的收益可能就是零,而最佳收益可能是12%,这就是应用于保本基金CPPI技术的雏形。
10、关于做空
如果你有100万,融券做空某股票,那么你可能发生的最大收益率就是100%,前提是你做空的股票跌没了,而做多的收益率是没有上限的,因此不要永久的做空,如果你不相信人类社会会向前进步。
11、关于赌场赢利
分析了澳门赌客1000个数据,发现胜负的概率为53%与47%,其中赢钱离场的人平均赢利34%,而输钱离场的人平均亏损是72%,赌场并不需要做局赢利,保证公平依靠人性的弱点就可以持续赢利。股市亦如此。
12、关于货币的未来
如果国家的货币发行增速保持在10%以上(现在中国广义货币M2余额107万亿,年增速14%),100年后中国货币总量将突破1,474,525万亿,以20亿人口计算,人均存款将突破7.37亿(不含房地产、证券、收藏品及各类资产)。
如果按此发行速度,货币体系可能会面临重构。货币发行增速将逐步下移直至低于2%,每年20%的收益率到那时候中国人才会意识到真不容易。
云计算之路-柳暗花明:为什么memcached会堵车 - 博客园团队 - 博客园
一个故障期间的重要现象闪现在眼前——当时memcached的磁盘IO高!
memcached缓存的数据都在内存中,而且内存占用并不高,磁盘IO怎么会高?太奇怪了!
。。。
通过google搜索“memcached read timeout”,找到柳暗花明的线索——memcached timeout error because of slow response
直接看关键文字:
The problem seemed to boil down to the following:
vm.swappiness=60 (default) is a very bad idea, when combined
with deadline as a io scheduler....
conclusion:
if you use memcache and need high amounts of memory with
many objects, keep a look at your swap, and if there is
something in it (even 1 kb) - it might be too much.
after setting vm.swappiness to zero and paging in all swap,
the effects were gone.
登上昨天引发故障的那台memcached服务器,运行命令:
cat /proc/sys/vm/swappiness 60
输出结果是60!磁盘IO高就是内存交换引起的!memcached堵车的原因就在这!
只要将swappiness设置为0,就能解决问题,设置方法参考:Adjust Your swappiness。
关于memcached的连接超时:
对于用户来说,最主要的功能是存取数据,假设我们有一个 memcached 节点 IP 地址或者域名是 host ,端口是 11211 ,一个简单的存取数据的例子如下:
MemcachedClientBuilder builder = new XMemcachedClientBuilder(
AddrUtil.getAddresses (“localhost:11211”));
MemcachedClient memcachedClient = builder.build();
try {
memcachedClient. set ( "hello" , 0, "Hello,xmemcached" );
String value = memcachedClient. get ( "hello" );
System. out .println( "hello=" + value);
memcachedClient. delete ( "hello" );
value = memcachedClient.get( "hello" );
System. out .println( "hello=" + value);
} catch (MemcachedException e) {
System. err .println( "MemcachedClient operation fail" );
e.printStackTrace();
} catch (TimeoutException e) {
System. err .println( "MemcachedClient operation timeout" );
e.printStackTrace();
} catch (InterruptedException e) {
// ignore
}
try {
memcachedClient.shutdown();
} catch (IOException e) {
System. err .println( "Shutdown MemcachedClient fail" );
e.printStackTrace();
}
因为 XMemcachedClient 的创建有比较多的可选项,因此提供了一个 XMemcachedClientBuilder 用于构建 MemcachedClient 。 MemcachedClient 是主要接口,操作 memcached 的主要方法都在这个接口里, XMemcachedClient 是它的一个实现。传入的 memcached 节点列表要求是类似 ”host1:port1 host2:port2 …” 这样的字符串,通过 AddrUtil.getAddresses 方法获取实际的 IP 地址列表。存储数据是通过 set 方法,它有三个参数,第一个是存储的 key 名称,第二个是 expire 时间(单位秒) ,超过这个时间 ,memcached 将这个数据替换出去, 0 表示永久存储(默认是一个月) ,第三个参数就是实际存储的数据,可以是任意的 java 可序列化类型 。 获取存储的数据是通过 get 方法,传入 key 名称即可。如果要删除存储的数据,这是通过 delete 方法,它也是接受 key 名称作为参数。 XMemcached 由于是基于 nio ,因此通讯过程本身是异步的, client 发送一个请求给 memcached ,你是无法确定 memcached 什么时候返回这个应答,客户端此时只有等待,因此还有个等待超时的概念在这里。客户端在发送请求后,开始等待应答,如果超过一定时间就认为操作失败,这个等待时间默认是一秒,上面例子展现的 3 个方法调用的都是默认的超时时间,这三个方法同样有允许传入超时时间的重载方法,例如
Value=client.get(“hello”,3000);
就是等待 3 秒超时,如果 3 秒超时就跑出 TimeutException ,用户需要自己处理这个异常。因为等待是通过调用 CountDownLatch.await(timeout) 方法,因此用户还需要处理中断异常 InterruptException 。最后的 MemcachedException 表示 Xmemcached 内部发生的异常,如解码编码错误、网络断开等等异常情况。
linux 系统监控、诊断工具之 IO wait - leejun_2005的个人页面 - 开源中国社区
1、问题:
最近在做日志的实时同步,上线之前是做过单份线上日志压力测试的,消息队列和客户端、本机都没问题,但是没想到上了第二份日志之后,问题来了:
集群中的某台机器 top 看到负载巨高,集群中的机器硬件配置一样,部署的软件都一样,却单单这一台负载有问题,初步猜测可能硬件有问题了。
同时,我们还需要把负载有异常的罪魁祸首揪出来,到时候从软件、硬件层面分别寻找解决方案。
2、排查:
从 top 中可以看到 load average 偏高,%wa 很高,%us 偏低:
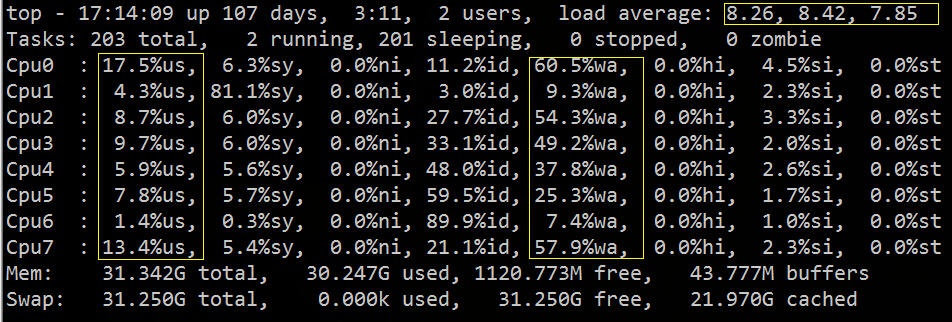
从上图我们大致可以推断 IO 遇到了瓶颈,下面我们可以再用相关的 IO 诊断工具,具体的验证排查下。
PS:如果你对 top 的用法不了解,请参考我去年写的一篇博文:
常用组合方式有如下几种:
- 用vmstat、sar、iostat检测是否是CPU瓶颈
- 用free、vmstat检测是否是内存瓶颈
- 用iostat、dmesg 检测是否是磁盘I/O瓶颈
- 用netstat检测是否是网络带宽瓶颈
2.1 vmstat
vmstat命令的含义为显示虚拟内存状态(“Viryual Memor Statics”),但是它可以报告关于进程、内存、I/O等系统整体运行状态。

它的相关字段说明如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
Procs(进程)• r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)• b: 等待IO的进程数量,也就是处在非中断睡眠状态的进程数,展示了正在执行和等待CPU资源的任务个数。当这个值超过了CPU数目,就会出现CPU瓶颈了Memory(内存)• swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。• free: 空闲物理内存大小。• buff: 用作缓冲的内存大小。• cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。Swap• si: 每秒从交换区写到内存的大小,由磁盘调入内存。• so: 每秒写入交换区的内存大小,由内存调入磁盘。注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。IO(现在的Linux版本块的大小为1kb)• bi: 每秒读取的块数• bo: 每秒写入的块数注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。system(系统)• in: 每秒中断数,包括时钟中断。• cs: 每秒上下文切换数。注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。CPU(以百分比表示)• us: 用户进程执行时间百分比(user time)us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。• sy: 内核系统进程执行时间百分比(system time)sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。• wa: IO等待时间百分比wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。• id: 空闲时间百分比 |
2.2 iostat
下面再用更加专业的磁盘 IO 诊断工具来看下相关统计数据。
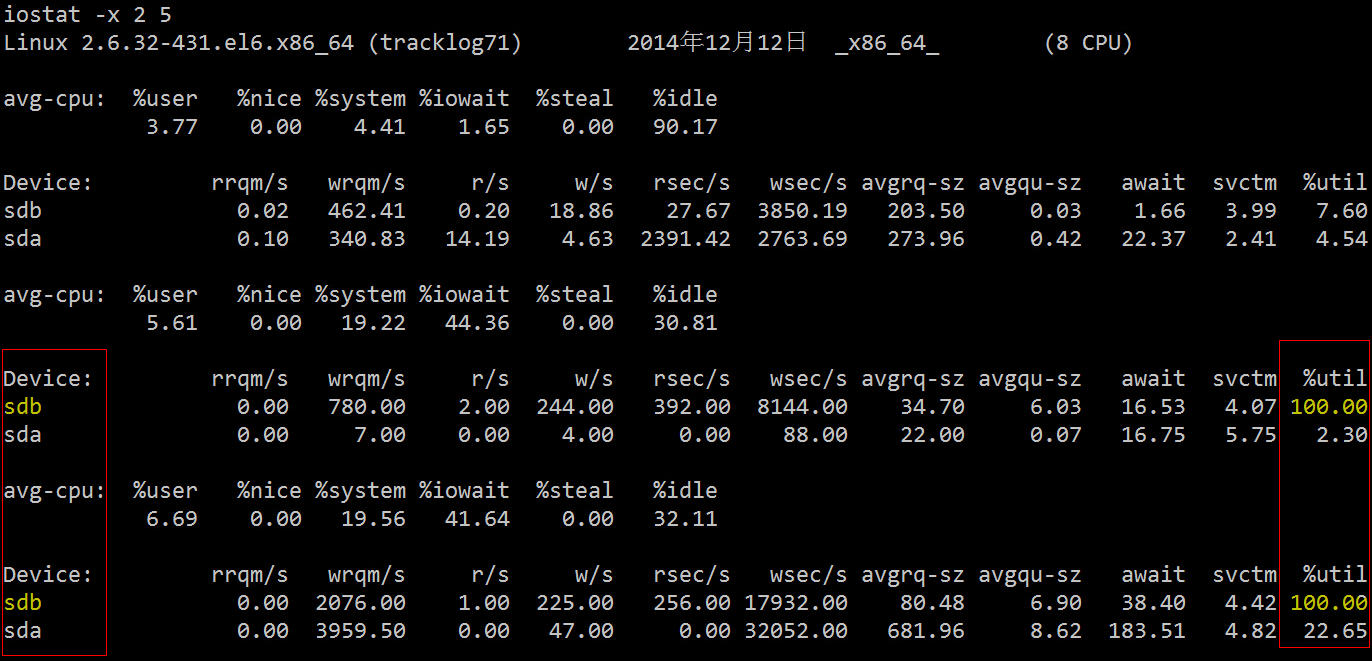
它的相关字段说明如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/swrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/sr/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/sw/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/srsec/s: 每秒读扇区数。即 delta(rsect)/swsec/s: 每秒写扇区数。即 delta(wsect)/srkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒) |
可以看到两块硬盘中的 sdb 的利用率已经 100%,存在严重的 IO 瓶颈,下一步我们就是要找出哪个进程在往这块硬盘读写数据。
2.3 iotop
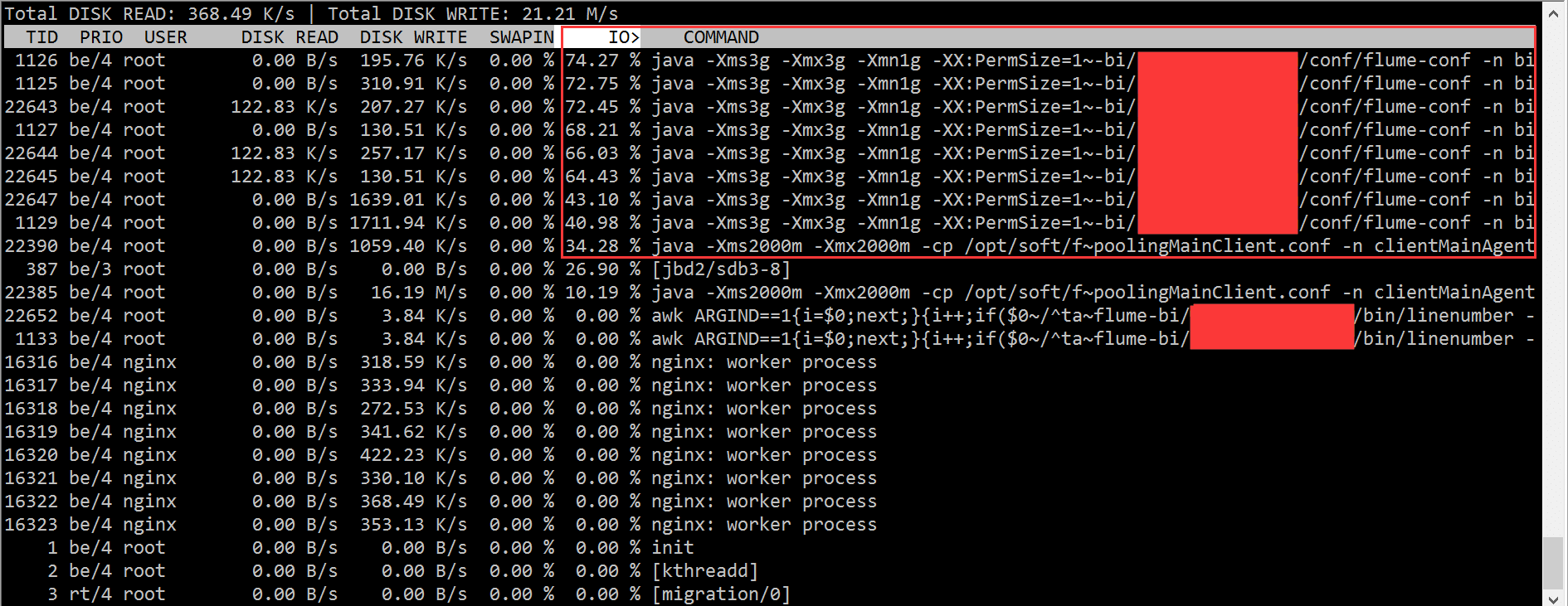
根据 iotop 的结果,我们迅速的定位到是 flume 进程的问题,造成了大量的 IO wait。
但是在开头我已经说了,集群中的机器配置一样,部署的程序也都 rsync 过去的一模一样,难道是硬盘坏了?
这得找运维同学来查证了,最后的结论是:
Sdb为双盘raid1,使用raid卡为“LSI Logic / Symbios Logic SAS1068E”,无cache。近400的IOPS压力已经达到了硬件极限。而其它机器使用的raid卡是“LSI Logic / Symbios Logic MegaRAID SAS 1078”,有256MB cache,并未达到硬件瓶颈,解决办法是更换能提供更大IOPS的机器,比如最后我们换了一台带 PERC6/i 集成RAID控制器卡的机器。需要说明的是,raid信息是在raid卡和磁盘固件里面各存一份,磁盘上的raid信息和raid卡上面的信息格式要是匹配的,否则raid卡识别不了就需要格式化磁盘。
IOPS本质上取决于磁盘本身,但是又很多提升IOPS的方法,加硬件cache、采用RAID阵列是常用的办法。如果是DB那种IOPS很高的场景,现在流行用SSD来取代传统的机械硬盘。
不过前面也说了,我们从软硬件两方面着手的目的就是看能否分别寻求代价最小的解决方案:
知道硬件的原因了,我们可以尝试把读写操作移到另一块盘,然后再看看效果:

3、最后的话:另辟蹊径
其实,除了用上述专业的工具定位这个问题外,我们可以直接利用进程状态来找到相关的进程。
我们知道进程有如下几种状态:
|
1
2
3
4
5
6
7
8
|
PROCESS STATE CODES D uninterruptible sleep (usually IO) R running or runnable (on run queue) S interruptible sleep (waiting for an event to complete) T stopped, either by a job control signal or because it is being traced. W paging (not valid since the 2.6.xx kernel) X dead (should never be seen) Z defunct ("zombie") process, terminated but not reaped by its parent. |
其中状态为 D 的一般就是由于 wait IO 而造成所谓的”非中断睡眠“,我们可以从这点入手然后一步步的定位问题:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
for x in `seq 10`; do ps -eo state,pid,cmd | grep "^D"; echo "----"; sleep 5; done D 248 [jbd2/dm-0-8] D 16528 bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp ---- D 22 [kdmflush] D 16528 bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp ----# 或者:while true; do date; ps auxf | awk '{if($8=="D") print $0;}'; sleep 1; done Tue Aug 23 20:03:54 CLT 2011 root 302 0.0 0.0 0 0 ? D May22 2:58 \_ [kdmflush] root 321 0.0 0.0 0 0 ? D May22 4:11 \_ [jbd2/dm-0-8] Tue Aug 23 20:03:55 CLT 2011 Tue Aug 23 20:03:56 CLT 2011cat /proc/16528/io rchar: 48752567 wchar: 549961789 syscr: 5967 syscw: 67138 read_bytes: 49020928 write_bytes: 549961728 cancelled_write_bytes: 0 lsof -p 16528 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME bonnie++ 16528 root cwd DIR 252,0 4096 130597 /tmp <truncated> bonnie++ 16528 root 8u REG 252,0 501219328 131869 /tmp/Bonnie.16528 bonnie++ 16528 root 9u REG 252,0 501219328 131869 /tmp/Bonnie.16528 bonnie++ 16528 root 10u REG 252,0 501219328 131869 /tmp/Bonnie.16528 bonnie++ 16528 root 11u REG 252,0 501219328 131869 /tmp/Bonnie.16528 bonnie++ 16528 root 12u REG 252,0 501219328 131869 <strong>/tmp/Bonnie.16528</strong> df /tmp Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/workstation-root 7667140 2628608 4653920 37% / fuser -vm /tmp USER PID ACCESS COMMAND /tmp: db2fenc1 1067 ....m db2fmp db2fenc1 1071 ....m db2fmp db2fenc1 2560 ....m db2fmp db2fenc1 5221 ....m db2fmp |
4、Refer:
[1] Troubleshooting High I/O Wait in Linux
——A walkthrough on how to find processes that are causing high I/O Wait on Linux Systems
http://bencane.com/2012/08/06/troubleshooting-high-io-wait-in-linux/
[2] 理解Linux系统负荷
http://www.ruanyifeng.com/blog/2011/07/linux_load_average_explained.html
[3] 24 iostat, vmstat and mpstat Examples for Linux Performance Monitoring
http://www.thegeekstuff.com/2011/07/iostat-vmstat-mpstat-examples/
[4] vmstat vmstat命令
http://man.linuxde.net/vmstat
[5] Linux vmstat命令实战详解
http://www.cnblogs.com/ggjucheng/archive/2012/01/05/2312625.html
[6] 影响Linux服务器性能的因素
http://www.rocklv.net/2004/news/article_284.html
[7] linux磁盘IO查看iostat,vmstat
http://blog.csdn.net/qiudakun/article/details/4699587
[8] What Process is using all of my disk IO
http://stackoverflow.com/questions/488826/what-process-is-using-all-of-my-disk-io
[9] Linux Wait IO Problem
http://www.chileoffshore.com/en/interesting-articles/126-linux-wait-io-problem
[10] Tracking Down High IO Wait in Linux
http://ostatic.com/blog/tracking-down-high-io-wait-in-linux
[11] 磁盘IOPS计算与测量
http://blog.csdn.net/liuaigui/article/details/6168186
[12] [DOC]磁盘性能指标—IOPS - Huawei
[13] RAID卡
拼写纠错设计 - quweiprotoss的日志 - 网易博客
一.计划解决的问题
1. 繁简转换
2. 拼音转汉字
3. 同音词拼写错误
4. 英文拼写错误
5. 形近词错误
6. 方言纠错
二. 核心思路
1. 繁体转简体是可以独立出来,最先处理。
2. 其它的4步从查询日志中找出纠错的候选查询词,全部在线下计算。
多数拼写纠错算法基于2 个基本原则(Introduction to IR 3.3.1节):
1. 在多个拼写纠错的可选结果中,选择与原term 最相似的一个,当然这就要求有一个相似的标准。
2. 当两个候选term 与要纠错的term 一样相似时,选择最常见的那个term,比如,grunt和grant,都与grnt 差不多相似,最简单的办法就是看grant 和grunt 在文档中的各出现了多少次,将出现次数多的返回。另一种更常见的做法是把用户最常搜索的查询返回。再讨论一下纠错的功能如何展示的方案:
数据的问题:
要进行纠错,首先要确定什么是正确的查询,最简单的想法就是确定一个阈值,比如说前80%的搜索查询算是正确的搜索词,但这有一个问题,比如在Introduction to IR里的一个例子,如果很多用户不太确定一个热搜词,britney spears,很多人搜索时用的是britian spears, britney’s spears, brandy spears, prittany spears,这些词都有可能是前80%的,所以最先就要对搜索查询进行过滤后,才能认为它们是正确的,过滤的方法可以是下面介绍的方法之一。
三.具体步骤
1. 繁简转换
使用繁简转换表转换。
2. 拼音转汉字
拼音转汉字想法是较为直接的,建立一个以拼音为term的查询词索引,posting list中只保存查询频率最高的K个查询词。
|
zhijiucaotang |
子九草堂, 子久草堂 |
|
xufuniuza |
徐福牛杂, 许府牛杂, 徐府牛杂 |
|
shoujichongzhi |
手机冲值, 手机充值 |
这一步可以在自动提示中使用,但自动提示与它的区别是,自动提示在拼音输入了一部分的情况下也要提示,比如输入 “xufu”就要提示“许府牛杂”。
3. 同音词拼音写
同音词拼音写也基于同样的想法,但是需要一个可能出错的查询词列表,这个列表可以为借鉴于下列几种情况 (Introduction to IR 3.3.1节)
1. 以carot为例,返回有carot的文档,也返回一些包含纠错后的term carrot和torot的文档。
2. 与(1)相似,但仅当carot不在词典中时,返回纠错后的结果。
3. 与(1)相似,但仅当包含carot的文档数小于一个预定义的阈值时。
4. 当原始查询返回文档数小于预定义的阈值时,搜索引擎给出纠错后的词列表。
情况(1)相当于是对所有查询都进行纠错处理,发现那些搜索比较少的,就给出一个纠错提示,比如“天浴”搜索次数比较少,而“天娱”搜索次数比较多,那么在用户搜索“天浴”时就提示“天娱”,即使“天娱”也是一个正常的查询词。
情况(2)就是得到所以没有返回结果的查询列表。
情况(3)是一个查询它返回的文档数少于一个预定义阈值时,我认为这个是最合适的,因为文档中也可能有人把字写错,这样就有可能漏掉一些应该纠错的词,但这需要搜索引擎结合,看到底有多少返回了。
情况(4)就是我想应该用的表现形式。
4. 英文拼写错误
在lucene中已有贡献者实现了spellchecker模块,主要算法有:Jaro Winkler distance,Levenstein Distance(Edit Distance),NGram Distance。
但Lucene中的实现过于简单,使用两两比较,时间复杂性是O(n2),可以用Introduction to IR中的3.3.4节中介绍的,k-gram与编辑距离结合的方法算。
5. 形近字错误
形近字一般是用户记错了形声字,或是使用五笔的用户输入错误。在网上可以下载SunWb_mb文件,它里面包含五笔的编码和笔画的编码,但字根比如“马”比“口”笔画更多,也更有代表性,但在这种方法中却是相同的。
6. 方言纠错
可以用soudex进行纠错,Introduction to IR 3.4节。