一段监控DirectBuffer的代码,以提高DirectBuffer的可用性
/**
* 监控DirectBuffer,提高DirectBuffer可用性
* 使用MaxDirectMemorySize可以指定DirectBuffer的最大可用空间,DirectBuffer的缓存空间不在堆上分配,
* 因此,可以使应用程序突破最大堆内存限制,对DirectBuffer的读写操作比普通Buffer快,但是对它的创建
* 与销毁比普通Buffer要慢
* @throws Exception
*/
@Test
public void monitorDirectBufferUsage() throws Exception {
Class c = Class.forName("java.nio.Bits");
Field maxMemory = c.getDeclaredField("maxMemory");
maxMemory.setAccessible(true);//通过反射取得私有数据
Field reservedMemory = c.getDeclaredField("reservedMemory");
reservedMemory.setAccessible(true);
synchronized(c) {
Long maxMemoryValue = (Long)maxMemory.get(null);
Long reservedMemoryValue = (Long) reservedMemory.get(null);
System.out.println("maxMemoryValue : " + maxMemoryValue);//总大小
System.out.println("reservedMemoryValue : " + reservedMemoryValue);//剩余大小
}
}
排查
首先怀疑是java heap的问题,查看heap占用内存,没有什么特殊。
$ jmap -heap pid
然后又怀疑是directbuffer的问题,jdk1.7之后对directbuffer监控的支持变得简单了一些,使用如下脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
import java.io.File;
import java.util.*;
import java.lang.management.BufferPoolMXBean;
import java.lang.management.ManagementFactory;
import javax.management.MBeanServerConnection;
import javax.management.ObjectName;
import javax.management.remote.*;
import com.sun.tools.attach.VirtualMachine; // Attach API
/**
* Simple tool to attach to running VM to report buffer pool usage.
*/
public class MonBuffers {
static final String CONNECTOR_ADDRESS =
"com.sun.management.jmxremote.localConnectorAddress";
public static void main(String args[]) throws Exception {
// attach to target VM to get connector address
VirtualMachine vm = VirtualMachine.attach(args[0]);
String connectorAddress = vm.getAgentProperties().getProperty(CONNECTOR_ADDRESS);
if (connectorAddress == null) {
// start management agent
String agent = vm.getSystemProperties().getProperty("java.home") +
File.separator + "lib" + File.separator + "management-agent.jar";
vm.loadAgent(agent);
connectorAddress = vm.getAgentProperties().getProperty(CONNECTOR_ADDRESS);
assert connectorAddress != null;
}
// connect to agent
JMXServiceURL url = new JMXServiceURL(connectorAddress);
JMXConnector c = JMXConnectorFactory.connect(url);
MBeanServerConnection server = c.getMBeanServerConnection();
// get the list of pools
Set<ObjectName> mbeans = server.queryNames(
new ObjectName("java.nio:type=BufferPool,*"), null);
List<BufferPoolMXBean> pools = new ArrayList<BufferPoolMXBean>();
for (ObjectName name: mbeans) {
BufferPoolMXBean pool = ManagementFactory
.newPlatformMXBeanProxy(server, name.toString(), BufferPoolMXBean.class);
pools.add(pool);
}
// print headers
for (BufferPoolMXBean pool: pools)
System.out.format(" %8s ", pool.getName());
System.out.println();
for (int i=0; i<pools.size(); i++)
System.out.format("%6s %10s %10s ", "Count", "Capacity", "Memory");
System.out.println();
// poll and print usage
for (;;) {
for (BufferPoolMXBean pool: pools) {
System.out.format("%6d %10d %10d ",
pool.getCount(), pool.getTotalCapacity(), pool.getMemoryUsed());
}
System.out.println();
Thread.sleep(2000);
}
}
}
|
发现directbuffer虽然在增长,但是也只有百兆左右。full gc之后缩小到十几兆,可以忽略。
查看java线程的情况,虽然线程数很多,但是内存增长时线程数基本没有什么变化。
$ jstack pid |grep 'java.lang.Thread.State' |wc -l
或者
$ cat /proc/pid/status |grep Thread
对java做了一次heap dump,使用eclipse的MAT查看堆内使用情况,没有发现明显有哪个对象数量有明显异常,heap的大小也只有几百兆。
$ jmap -dump:file=/tmp/heap.bin
发现stack dump里的global jni reference一直在增长,怀疑是jni调用存在内存溢出。
$ jstack pid |grep JNI
查找了jar包里的.so/.h等c文件,发现jruby、jthon等jar包里有jni相关的文件。
$ wtool jarfind *.so .
上网发现确实有不少jruby内存溢出的issue。把这些jar包直接删掉之后观察global jni reference数量还是在涨,内存增长情况也没有改善。
之后突然想到full gc的问题,对增长中的java进程做了一次full gc,global jni reference数量由几千个下降到几十个,但是占用内存还是没有变化,排除掉global reference的可能性。
用pmap查看进程内的内存情况,发现java的heap和stack大小都没啥变化,但是定期会多出来一个64M左右的内存块。
$ pmap -x pid |less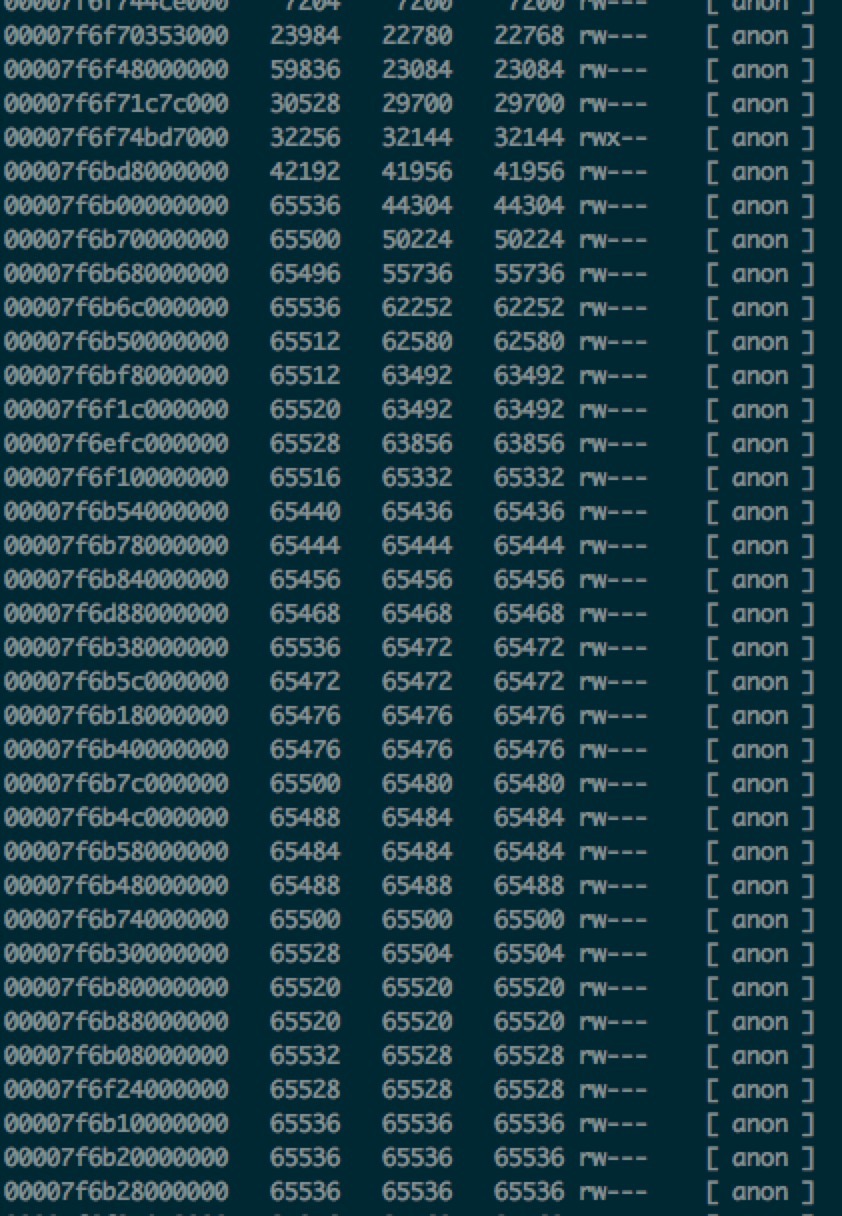
使用gdb观察内存块里的内容,发现里面有一些接口的返回值、mc的返回值、还有一些类名等等
gdb: dump memory /tmp/memory.bin 0x7f6b38000000 0x7f6b38000000+65535000
$ hexdump -C /tmp/memory.bin或$ strings /tmp/memory.bin |less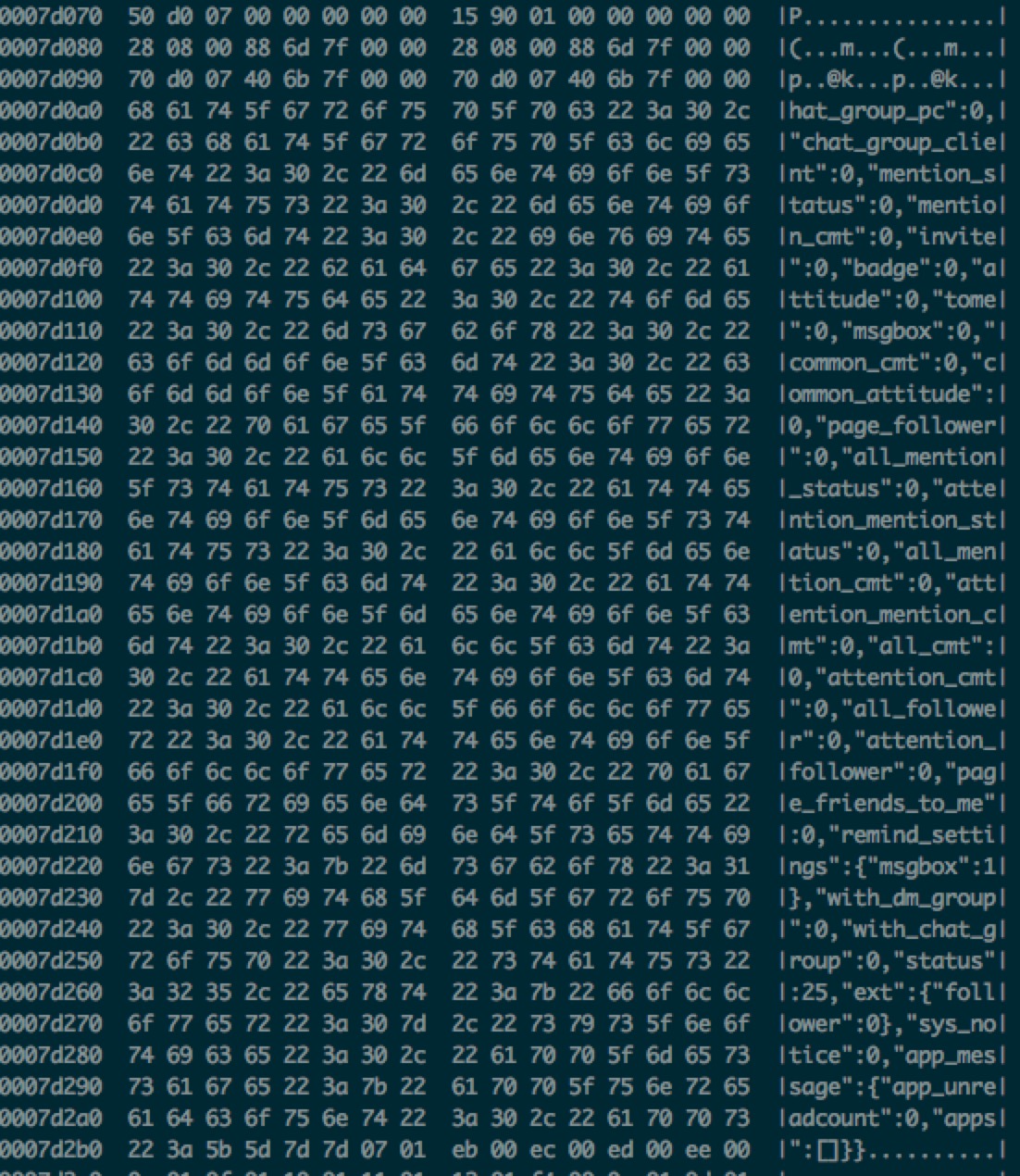
上网搜索后发现有人遇到过这个问题,在这个网页里有ibm对64M问题的研究。依照网站上说的办法,把MALLOC_ARENA_MAX参数调成1,发现virtual memory正常了,res也小了1G左右。同时hadoop的issue里也有一些性能方面的测试,发现MALLOC_ARENA_MAX=4的时候性能会提升,但是他们也说不清楚为什么。
修改之后程序启动时的virtual memory明显降低,res也降低到了3.2g: 
本来以为到这里应该算是解决了,但是这个程序跑了几天之后内存依然在上涨,只是内存块由很多64M变成了一个2g+的普通native heap。
继续寻找线索,在一些关于MALLOC_ARENA_MAX这个参数的讨论里也发现一些关于glibc的其它参数。比如M_TRIM_THRESHOLD和M_MMAP_THRESHOLD或者MALLOC_MMAP_MAX_,试用之后发现依然没有效果。
试着从glibc的malloc实现上找问题,比如这里和这里,同样没有什么进展。
尝试用strace和ltrace查找malloc调用,发现定期有32k的内存申请,但是无法确定是从哪调用的。
尝试用valgrind查找内存泄露,但是jvm跑在valgrind上几分钟就crash了。
在网上查到了一个关于thread pool用法错误有可能导致内存溢出的问题,可以写一个小程序重现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public static void main(String[] args) throws InterruptedException {
Logger.getRootLogger().setLevel(org.apache.log4j.Level.ERROR);
while(true) {
long max = Runtime.getRuntime().maxMemory();
long total = Runtime.getRuntime().totalMemory();
long free= Runtime.getRuntime().freeMemory();
System.out.println("max:"+max+",total:"+total+",free:"+free);
for (int i = 0; i < 10000; i++) {
ThreadPoolExecutor executor = new ThreadPoolExecutor();
}
Thread.sleep(1000);
}
}
|
但是用btrace挂了一天也没有发现有错误的调用,源代码里也没找到类似的用法。
重新用MAT在heap dump里查找是否有native reference,发现finalizer队列里有很多java.util.zip.Deflater的实例,上网搜索发现这个类有可能导致native内存溢出,使用的jesery框架里有这个问题导致gzip异常的issue;用btrace监视发现有大量这个类的构造函数被调用,但是经过几次full gc的观察,每次full gc后finalizer队列里的Deflater数量都会减少到个位数,但是内存依然在上涨;同时排查了线上配置,发现没有开启gzip。
也发现了有人说SunPKCS11有可能导致内存泄露,但是也没发现有相关java对象。
尝试把Xss参数调到256k,运行几天后发现内存维持在5.7g左右,比较稳定,但是从各种角度都无法解释为什么xss调小会影响native heap的大小。
怀疑是JIT的问题,用-Xint或者-XX:-Inline方式启动之后发现内存依然增长。
本来排查到这里已经绝望了,但是最后想到是不是JDK本身有什么bug?
查看jdk的changelog,发现线上使用的1.7-b15的版本比较老,之后有一些对native memory leak的修复。尝试用新的jdk1.7-u71启动应用,内存竟然稳定下来了!
在升级jdk、限制directbuffer大小为256M、调整MALLOC_ARENA_MAX=1后,4倍流量的tcpcopy运行几天后内存占用稳定在5G;只升级了jdk,其它参数不变,运行一天后内存为5.4G,是否上涨还有待观察。对比之前占用6.8G左右,效果还是比较明显的。
4.其它参考资料
阅读全文……