Kibana+Logstash+Elasticsearch 日志查询系统 - 扫榻人 - 51CTO技术博客
1 安装需求
1.1 理论拓扑
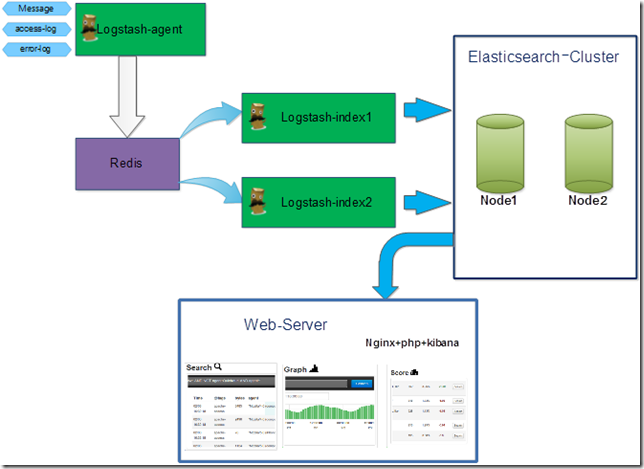
1.2 安装环境
1.2.1 硬件环境
1.2.2 操作系统
1.2.3 Web-server基础环境
1.2.4 软件列表
1.3 获取方法
1.3.1 Jdk获取路径
1.3.2 Logstash获取路径
1.3.3 Elasticsearch获取路径
1.3.4 Kibana获取路径
2 安装步骤
2.1 JDK的下载及安装
2.2 Redis下载及安装
2.3 Elasticsearch下载及安装
2.4 Logstash下载及安装
2.5 Kibana下载及安装
3 相关配置及启动
3.1 Redis配置及启动
3.1.1 配置文件
3.1.2 Redis启动(192.168.50.98)
3.2 Elasticsearch 配置及启动(192.168.50.98)
3.2.1 Elasticsearch启动
3.3 Logstash配置及启动
3.3.1 Logstash配置文件(agent收集日志角色)
3.3.2 Logstash启动为Index(从redis读取日志,负责日志的切割,存储至Elasticsearch)
3.3.4 kibana配置
4 性能调优
4.1 Elasticsearch调优
4.1.1 JVM调优
4.1.2 Elasticsearch索引压缩
5 使用
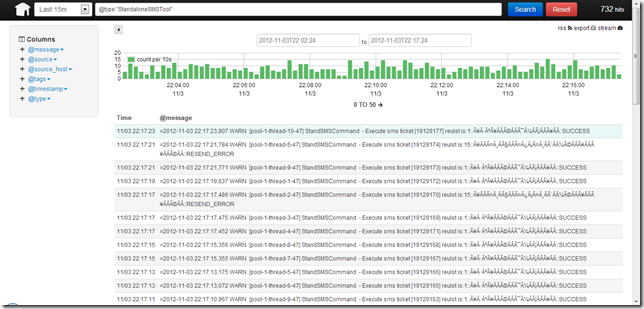
5.1 Logstash查询页
HDFS Permissions & Acls - 季石磊 - 博客园
1.概述
Hadoop分布式文件系统(HDFS)对文件和文件夹的权限控制模型与 POSIX文件系统的权限控制模型一样,每一个文件和文件夹都分配了所有者用户和所有者用户组。每个客户端访问HDFS的过程中,身份凭证由用户名和组列表两部分组成,Hadoop进行身份验证的时候,首先验证用户名,如果用户名验证不通过则验证用户组,如果用户名和用户组都验证失败则身份验证失败。
2.身份验证模式
Hadoop支持2种不同的身份验证模式,可以通过hadoop.security.authentication属性进行配置:
-
- simple
在simple身份认证模式下,用户的身份信息就是客户端的操作系统的登录用户,在Unix类的操作系统中,HDFS的用户名等同使用whoami命令查看结果的用户名。
-
- kerberos
在kerberos身份认证模式下,HDFS用户的身份是由kerberos凭证决定的。kerberos认证的安全性较高,但配置相对复杂,一般情况下很少使用。
3.Hadoop的Super-User
哪个用户启动Hadoop的Namenode,哪个用户就是Hadoop的超级管理员,拥有Hadoop全部权限。HDFS的超级管理员不必是操作系统的超级管理员。
4.配置参数
假设有一个HDFS集群,有两个用户UserA和UserB。要求HDFS只允许UserA和UserB访问,不允许其它用户访问,且UserA创建的文件UserB不能访问,同样UserB创建的文件UserA也不能访问。可以执行以下配置:
(1) 在core-site.xmll中配置以下属性:

<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
(2) 配置${HADOOP_CONF_DIR}/hadoop-policy.xml
<property> <name> security.client.protocol.acl </name> <value>UserA,UserB</value> </property>
只允许UserA,UserB访问Hdfs,不允许其它用户访问,注意这个地方如果设置用户组的话,用户组前面需要加一个空格。
(3)修改core-site.xmll中配置以下属性,开启dfs安全配置,同时设置新创建文件的umask码为077
<property> <name>dfs.permissions</name> <value>true</value> </property> <property> <name>fs.permissions.umask-mode</name> <value>077</value> </property>
如果用户通过通过跳板机或者客户端访问Hdfs的时候,建议使用final关键字以防止Hdfs服务器配置被客户端的配置覆盖,具体配置如下:
<property> <name>dfs.permissions</name> <value>true</value> <final>true</final> </property>
最后,使用hadoop启动hadoop执行start-all.sh 启动Hadoop,不能使用UserA或者UserB启动Hadoop。
5.umask
POSIX文件权限有读,写,执行三种权限,分别用r,w,x代表,这三种权限的数值大小如下表所示:
1 x
2 w
4 r
根据这三个数值可以得到混合权限数值表
1 --x
2 -w-
3 -wx
4 r--
5 r-x
6 rw-
7 rwx
这样Hdfs的文件有三种权限组成,可以通过hadoop fs -ls查看
drwxr-xr-x
以上权限的解释为
d rwx r-x r-x
目录 文件所有者的权限 同组用户的权限 其它用户的权限
表示为数值就是755
可以理解umask的作用为屏蔽权限位,例如umask 022,不屏蔽所属用户的权限,屏蔽同组用户的w权限,屏蔽其他用户的w权限,于是文件的默认权限为755,更简便的方法是用777减去022,得到755
6.其它问题
需要更改相关文件夹的权限,确保Hadoop在运行过程中的各类临时数据可以有写入权限,如果需要运行Mapreduce则需要修改Hdfs上面的${hadoop-tmp}/mapred/staging 文件夹权限,可以给737权限。如果需要运行Hive则需要给客户端本地硬盘的${hadoop-tmp}赋予其它用户写入权限
在对葡萄酒一无所知的情况下,如何根据酒标判断酒的好坏和风格? - 知乎
如果童鞋们想买酸爽口感的,要找酒精度较低的(11-12度);
想买浓郁圆润的,要找酒精度高的(13-14度);
想买口感甜的,去找酒精度过低(<11度)或过高(>17度)的
对于目前来说,只需知道新世界国家的气候普遍偏热,旧世界国家的气候普遍偏冷。气候的原因部分导致了新世界的酒偏浓郁、有更多偏甜香的果味;旧世界的酒偏酸、有更多偏咸香的非果味。
年份在距现在1年之内的一定是非木桶路线。
如果你选择非木桶路线,那么酒的风格多是以酸爽做主打,或以品种芳香做主打(某些品种芳香和木桶味完全不兼容,比如雷司令Riesling)。
年份在距现在3年以外的一般是木桶路线。2年的情况更复杂一些,但如果是距现在2年的白葡萄酒,则很有可能用了木桶。
如果你选择木桶路线,有两种基本方向——要不然是“简单果味+明显木桶辛香”的年轻派组合,要不然就是“复杂味道+不明显木桶辛香”的沉郁派组合。
但是我们要注意,独立酒庄不一定是精品级别(premium wine),但量产品牌一定不是精品级别(除非是他们的最高级别酒款)。此外,也有很多极烂的独立酒庄,不要让独立二字晃了眼了哦。
在我国葡萄酒中,长城葡萄酒就是量产品牌的典型代表。事实上,在2013年的Drink Business报道中,长城排名世界最强品牌第二名,听说马上还要扩张到智利、澳大利亚。