从B树、B+树、B*树谈到R 树 - 结构之法 算法之道 - 博客频道 - CSDN.NET
3.3文件查找的具体过程(涉及磁盘IO操作)
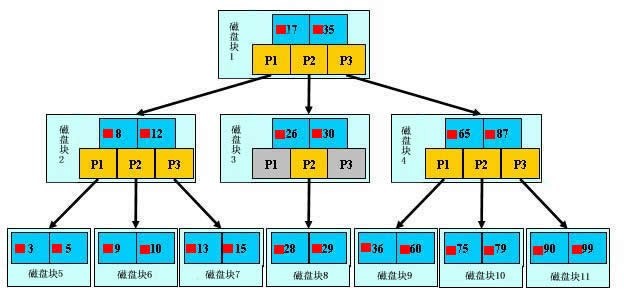
为了简单,这里用少量数据构造一棵3叉树的形式,实际应用中的B树结点中关键字很多的。上面的图中比如根结点,其中17表示一个磁盘文件的文件名;小红方块表示这个17文件内容在硬盘中的存储位置;p1表示指向17左子树的指针。
其结构可以简单定义为:
typedef struct {
/*文件数*/
int file_num;
/*文件名(key)*/
char * file_name[max_file_num];
/*指向子节点的指针*/
BTNode * BTptr[max_file_num+1];
/*文件在硬盘中的存储位置*/
FILE_HARD_ADDR offset[max_file_num];
}BTNode;
假如每个盘块可以正好存放一个B树的结点(正好存放2个文件名)。那么一个BTNODE结点就代表一个盘块,而子树指针就是存放另外一个盘块的地址。
下面,咱们来模拟下查找文件29的过程:
-
根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作 1次】
-
此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据。根据算法我们发现:17<29<35,因此我们找到指针p2。
-
根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作 2次】
-
此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30,因此我们找到指针p2。
-
根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
-
此时内存中有两个文件名28,29。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作是影响整个B树查找效率的决定因素。
当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘4次,最多5次,而且文件越多,B树比平衡二叉树所用的磁盘IO操作次数将越少,效率也越高。
[慢查优化]建索引时注意字段选择性 & 范围查询注意组合索引的字段顺序 - 旁观者 - 博客园
- 之前曾说过“不要求每个人一定理解 联表查询(join/left join/inner join等)时的mysql运算过程”,但对于字段选择性差意味着什么,组合索引字段顺序意味着什么,要求每个人必须了解;
- 重复上一次的话:把mysql客户端(如SQLyog,如HeidiSQL)放在桌面上,时不时拿出来 explain 一把,这是一种美德!
- 确保亲手查过SQL的执行计划,一定要注意看执行计划里的 possible_keys、key和rows这三个值,让影响行数尽量少,保证使用到正确的索引,减少不必要的Using temporary/Using filesort;
- 不要在选择性非常差的字段上建索引,原因参见优化策略A;
- 查询条件里出现范围查询(如A>7,A in (2,3))时,要警惕,不要建了组合索引却完全用不上,原因参见优化策略B;
我们先回顾一下字段选择性的基础知识。
——字段选择性的基础知识——
引子:什么字段都可以建索引吗?
如下表所示,sort 字段的选择性非常差,你可以执行 show index from ads 命令可以看到 sort 的 Cardinality(散列程度)只有 9,这种字段上本不应该建索引:
|
Table |
Non_unique |
Key_name |
Seq_in_index |
Column_name |
Collation |
Cardinality |
Sub_part |
Packed |
Null |
Index_type |
Comment |
|
ads |
1 |
sort |
1 |
sort |
A |
9 |
\N |
\N |
|
BTREE |
|
- 选择性较低索引 可能带来的性能问题
- 索引选择性=索引列唯一值/表记录数;
- 选择性越高索引检索价值越高,消耗系统资源越少;选择性越低索引检索价值越低,消耗系统资源越多;
- 查询条件含有多个字段时,不要在选择性很低字段上创建索引
- 可通过创建组合索引来增强低字段选择性和避免选择性很低字段创建索引带来副作用;
- 尽量减少possible_keys,正确索引会提高sql查询速度,过多索引会增加优化器选择索引的代价,不要滥用索引;
——组合索引字段顺序与范围查询之间的关系——
引子:范围查询 city_id in (0,8,10) 能用组合索引 (ads_id,city_id) 吗?
举例,
ac 表有一个组合索引(ads_id,city_id)。
那么如下 ac.city_id IN (0, 8005) 查询条件能用到 ac表的组合索引(ads_id,city_id) 吗?
EXPLAIN
SELECT ac.ads_id
FROM ads, ac
WHERE
ads.id = ac.ads_id
AND ac.city_id IN (0, 8005)
AND ads.status = 'online'
AND ac.start_time<UNIX_TIMESTAMP()
AND ac.end_time>UNIX_TIMESTAMP()
优化策略B:
由于 mysql 索引是基于 B-Tree 的,所以组合索引有“字段顺序”概念。
所以,查询条件中有 ac.city_id IN (0, 8005),而组合索引是 (ads_id,city_id),则该查询无法使用到这个组合索引。
DBA总结道:
- 下面条件可以用上该组合索引查询:
- A>5
- A=5 AND B>6
- A=5 AND B=6 AND C=7
- A=5 AND B IN (2,3) AND C>5
- 下面条件将不能用上组合索引查询:
- B>5 ——查询条件不包含组合索引首列字段
- B=6 AND C=7 ——查询条件不包含组合索引首列字段
- 下面条件将能用上部分组合索引查询:
- A>5 AND B=2 ——当范围查询使用第一列,查询条件仅仅能使用第一列
- A=5 AND B>6 AND C=2 ——范围查询使用第二列,查询条件仅仅能使用前二列
- 下面条件可以用上组合索引排序:
- ORDER BY A——首列排序
- A=5 ORDER BY B——第一列过滤后第二列排序
- ORDER BY A DESC, B DESC——注意,此时两列以相同顺序排序
- A>5 ORDER BY A——数据检索和排序都在第一列
- 下面条件不能用上组合索引排序:
- ORDER BY B ——排序在索引的第二列
- A>5 ORDER BY B ——范围查询在第一列,排序在第二列
- A IN(1,2) ORDER BY B ——理由同上
- ORDER BY A ASC, B DESC ——注意,此时两列以不同顺序排序
- MySQL 5,0以下版本,SQL查询时,一张表只能用一个索引(use at most only one index for each referenced table),
- 从 MySQL 5.0开始,引入了 index merge 概念,包括 Index Merge Union Access Algorithm(多个索引并集访问),包括Index Merge Intersection Access Algorithm(多个索引交集访问),可以在一个SQL查询里用到一张表里的多个索引。
- MySQL 在5.6.7之前,使用 index merge 有一个重要的前提条件:没有 range 可以使用。[出自参考资源2]
- MySQL 索引合并能使用多个索引
- SELECT * FROM TB WHERE A=5 AND B=6
- 能分别使用索引(A) 和 (B) 或 索引合并;
- 创建组合索引(A,B) 更好;
- SELECT * FROM TB WHERE A=5 OR B=6
- 能分别使用索引(A) 和 (B) 或 索引合并;
- 组合索引(A,B)不能用于此查询,分别创建索引(A) 和 (B)会更好;
- SELECT * FROM TB WHERE A=5 AND B=6
记住,explain 后再提测是一种美德!