从free到page cache
- xiao - 博客园-MrDB's 技术随笔我们经常用free查看服务器的内存使用情况,而free中的输出却有些让人困惑,如下:. 先看看各个数字的意义以及如何计算得到:. free命令输出的第二行(Mem):这行分别显示了物理内存的总量(total)、已使用的 (used)、空闲的(free)、共享的(shared)、buffer(buffer大小)、 cache(cache的大小)的内存.
我们经常用free查看服务器的内存使用情况,而free中的输出却有些让人困惑,如下:

图1-1
先看看各个数字的意义以及如何计算得到:
free命令输出的第二行(Mem):这行分别显示了物理内存的总量(total)、已使用的 (used)、空闲的(free)、共享的(shared)、buffer(buffer大小)、 cache(cache的大小)的内存。我们知道Total、free、buffers、cached这几个字段是从/proc/meminfo中获取的,而used = total – free。Share列已经过时,忽略(见参考)。
free命令输出的第三行(-/+ buffers/cache):
它显示的第一个值(used):548840,这个值表示系统本身使用的内存总量,即除去buffer/cache,等于Mem行used列 - Mem行buffers列 - Mem行cached列。
它显示的第二个值(free):1417380,这个值表示系统当前可用内存,它等于Mem行total列—used,也等于Mem行free列 + Mem行buffers列 + Mem行cached列。
free命令输出的第四行(Swap) 这行显示交换内存的总量、已使用量、 空闲量。
我们都知道free是从/proc/meminfo中读取相关的数据的。
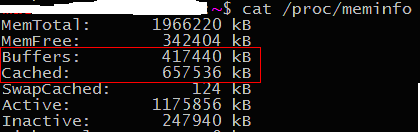
图1-2
来看看/proc/meminfo的相关实现:
|
// proc_misc.c static int meminfo_read_proc(char *page, char **start, off_t off, int count, int *eof, void *data) { … struct sysinfo i; si_meminfo(&i); //统计memory的使用情况 si_swapinfo(&i); //统计swap的使用情况 … len = sprintf(page, "MemTotal: %8lu kB\n" "MemFree: %8lu kB\n" "Buffers: %8lu kB\n" "Cached: %8lu kB\n" "SwapCached: %8lu kB\n" … K(i.totalram), K(i.freeram), K(i.bufferram), K(get_page_cache_size()-total_swapcache_pages-i.bufferram), K(total_swapcache_pages), … }
struct sysinfo { long uptime; /* Seconds since boot */ unsigned long loads[3]; /* 1, 5, and 15 minute load averages */ unsigned long totalram; /*总的页框数,Total usable main memory size */ unsigned long freeram; /* Available memory size */ unsigned long sharedram; /* Amount of shared memory */ unsigned long bufferram; /* Memory used by buffers */ unsigned long totalswap; /* Total swap space size */ unsigned long freeswap; /* swap space still available */ unsigned short procs; /* Number of current processes */ unsigned short pad; /* explicit padding for m68k */ unsigned long totalhigh; /* Total high memory size */ unsigned long freehigh; /* Available high memory size */ unsigned int mem_unit; /* Memory unit size in bytes */ char _f[20-2*sizeof(long)-sizeof(int)]; /* Padding: libc5 uses this.. */ }; |
图中,Buffers对应sysinfo.bufferram,内核中以页框为单位,通过宏K转化成以KB为单位输出。
|
void si_meminfo(struct sysinfo *val) { val->totalram = totalram_pages;//总的页框数 val->sharedram = 0; val->freeram = nr_free_pages();//计算空闲页框数 val->bufferram = nr_blockdev_pages();//block device使用的面框数 #ifdef CONFIG_HIGHMEM val->totalhigh = totalhigh_pages; val->freehigh = nr_free_highpages(); #else val->totalhigh = 0; val->freehigh = 0; #endif val->mem_unit = PAGE_SIZE; } //遍历所有的块设备,累加相应的页面数量 long nr_blockdev_pages(void) { struct list_head *p; long ret = 0; spin_lock(&bdev_lock); list_for_each(p, &all_bdevs) { struct block_device *bdev; bdev = list_entry(p, struct block_device, bd_list); ret += bdev->bd_inode->i_mapping->nrpages; } spin_unlock(&bdev_lock); return ret; } |
nr_blockdev_pages计算块设备使用的页框数,遍历所有块设备,将使用的页框数相加。而不包含普通文件使用的页框数。
Cached = get_page_cache_size()-total_swapcache_pages-i.bufferram。
|
static inline unsigned long get_page_cache_size(void) { int ret = atomic_read(&nr_pagecache); if (unlikely(ret < 0)) ret = 0; return ret; } |
Cache的大小为内核总的page cache减去swap cache和块设备占用的页框数量,实际上cache即为普通文件的占用的page cache。实际上,在函数add_to_page_cache和__add_to_swap_cache 中,都会通过调用pagecache_acct实现对内核变量nr_pagecache进行累加。前者对应page cache,内核读块设备和普通文件使用;后者对应swap cache,内核读交换分区使用。
Page cache(页面缓存)
在linux系统中,为了加快文件的读写,内核中提供了page cache作为缓存,称为页面缓存(page cache)。为了加快对块设备的读写,内核中还提供了buffer cache作为缓存。在2.4内核中,这两者是分开的。这样就造成了双缓冲,因为文件读写最后还是转化为对块设备的读写。在2.6中,buffer cache合并到page cache中,对应的页面叫作buffer page。当进行文件读写时,如果文件在磁盘上的存储块是连续的,那么文件在page cache中对应的页是普通的page,如果文件在磁盘上的数据块是不连续的,或者是设备文件,那么文件在page cache中对应的页是buffer page。buffer page与普通的page相比,每个页多了几个buffer_head结构体(个数视块的大小而定)。此外,如果对单独的块(如超级块)直接进行读写,对应的page cache中的页也是buffer page。这两种页面虽然形式略有不同,但是最终他们的数据都会被封装成bio结构体,提交到通用块设备驱动层,统一进行I/O调度。
|
// include/buffer_head.h struct buffer_head { /* First cache line: */ unsigned long b_state; /* buffer state bitmap (see above) */ struct buffer_head *b_this_page;/* circular list of page's buffers */ struct page *b_page; /* the page this bh is mapped to,页框 */ atomic_t b_count; /* users using this block */ u32 b_size; /* block size */
sector_t b_blocknr; /* block number,块设备中的逻辑块号 */ char *b_data; /* pointer to data block */
struct block_device *b_bdev;//块设备 bh_end_io_t *b_end_io; /* I/O completion */ void *b_private; /* reserved for b_end_io */ struct list_head b_assoc_buffers; /* associated with another mapping */ }; |
在kernel2.6之后,buffer_head没有别的作用,主要用来保持页框与块设备中数据块的映射关系。
Buffer page(缓冲页)
如果内核需要单独访问一个块,就会涉及到buffer page,并会检查对应的buffer head。
内核创建buffer page的两种常见情况:
(1)当读或者写一个文件页的数据块不相邻时。发生这种情况是因为文件系统为文件分配了非连续的块,或者文件有洞。具体请参见block_read_full_page(fs/buffer.c)函数:
|
///对于块设备文件和数据块不相邻的普通文件,都会调用该方法 int block_read_full_page(struct page *page, get_block_t *get_block) { … if (!page_has_buffers(page))///page没有分配buffer head,见buffer_head.h create_empty_buffers(page, blocksize, 0);//为page创建buffer_head head = page_buffers(page); } |
这里使用buffer head主要是通过buffer head建立页框与数据块的映射关系。因为页面中的数据不是连接的,而页框描述符struct page的字段又不足以表达这种信息。
(2)访问一个单独的磁盘块(比如,读超级块或者索引节点块时)。参见ext2_fill_super(fs/ext2/super.c),该函数在安装ext2文件系统时调用。
Buffer page和buffer head的关系:
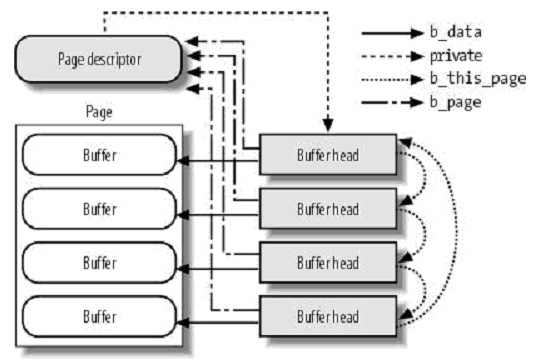
小结:对于普通文件,如果页面中的块是连续的,则页面没有对应buffer head;如果不连续,则页面有对应的buffer head,参见do_mpage_readpage函数。对于块设备,无论是读取单独的数据块,还是作为设备文件来进行读取,页面始终有对应的buffer head,参见block_read_full_page/__bread函数。
Swap cache(交换缓存)
在图1-2中,有一行swapcached,它表示交换缓存的大小。Page cache是磁盘数据在内存中的缓存,而swap cache则是交换分区在内存中的临时缓存。Swap cache对交换分区具有十分重要的意义,这里不再赘述,详细讨论请见参考文献。
Swap用来为非映射页在磁盘上提供备份。有三类页必须由交换子系统进行处理:(1)进程匿名线性区(anonymous memory region)的页,比如用户态的堆栈和堆,匿名内存映射也是。(2) 进程私有内存映射的脏页。(3)IPC共享内存区的页。1和3都比较好理解,因为它们都没有对应的磁盘文件,所以必须通过swap来临时存储数据。下面讨论一下第2点。
Memory mapping(内存映射)
内核有两种类型的内存映射:共享型(shared)和私有型(private)。私有型是当进程为了只读文件,而不写文件时使用,这时,私有映射更加高效。但是,任何对私有映射页的写操作都会导致内核停止映射该文件中的页。所以,写操作既不会改变磁盘上的文件,对访问该文件的其它进程也是不可见的。
共享内存中的页通常都位于page cache,私有内存映射只要没有修改,也位于page cache。当进程试图修改一个私有映射内存页时,内核就把该页进行复制,并在页表中用复制的页替换原来的页。由于修改了页表,尽管原来的页仍然在page cache,但是已经不再属于该内存映射。而新复制的页也不会插入page cache,而是添加到匿名页反向映射数据结构。参见do_no_page(mm/memory.c)。
|
static int do_no_page(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, int write_access, pte_t *page_table, pmd_t *pmd) { … //写私有内存映射,则复制页面 if (write_access && !(vma->vm_flags & VM_SHARED)) { struct page *page;
if (unlikely(anon_vma_prepare(vma))) goto oom; page = alloc_page_vma(GFP_HIGHUSER, vma, address); if (!page) goto oom; copy_user_highpage(page, new_page, address);///copy page page_cache_release(new_page); new_page = page; anon = 1; } … if (anon) { lru_cache_add_active(new_page);//将页插入LRU的活动链表 page_add_anon_rmap(new_page, vma, address);//将匿名页插入到反向映射数据结构 } … } |
释放cache
Free命令输出的第一行是对应的实实在在的内存,不管是buffer,还是cache。Swap对应磁盘上的交换分区。Kernel会尽量使用RAM做cache,所以一般cache都比较大:

8G的内存,而空闲(free)的内存只有约50M,比较惊人。其实,cached占了3G+。另外,我们看到第三行used列约为4G,是比较大的,确实,该机器上跑了好几个接入服务。
Kernel2.6.16之后的版本提供了一种释放cache的机制,通过修改内核参数/proc/sys/vm/drop_caches让内核释放干净的cache。
To free pagecache:
echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes:
echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes:
echo 3 > /proc/sys/vm/drop_caches
|
# free total used free shared buffers cached Mem: 1966220 1676428 289792 0 418900 705216 -/+ buffers/cache: 552312 1413908 Swap: 2104504 131084 1973420 # echo 1 > /proc/sys/vm/drop_caches # free total used free shared buffers cached Mem: 1966220 597840 1368380 0 324 65852 -/+ buffers/cache: 531664 1434556 Swap: 2104504 131084 1973420 |
设置内核参数drop_caches后,cached的值迅速下降。通常来说,Linux会尽量使用可用的RAM,cache过高,是正常的。而手动释放cache会增加I/O开销,导致系统性能下降。
最后,水平有限,欢迎指正和探讨。
主要参考:
《ULK》
http://linux.die.net/man/1/free
http://www.kernel.org/doc/Documentation/sysctl/vm.txt
http://linux-mm.org/Drop_Caches
作者:MrDB
出处:http://www.cnblogs.com/hustcat/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
作者: MrDB 发表于 2011-10-27 20:32 原文链接
最新新闻:
· 谷歌难回中国内地市场(2011-10-28 18:04)
· 诺基亚提振智能手机业务三大战略(2011-10-28 18:01)
· 雅虎日本意外倒向谷歌 雅虎亚洲资产再成焦点(2011-10-28 18:00)
· 11个强大热门的WordPress插件推荐(2011-10-28 17:49)
· 你知道互联网到底多耗电吗?(2011-10-28 17:41)
编辑推荐:乔布斯:初心与终点