Guava作为Google开源出来的工具库,Google自己对Guava的描述:The Guava project contains several of Google's core libraries that we rely on in our Java-based projects: collections, caching, primitives support, concurrency libraries, common annotations, string processing, I/O, and so forth.作为Google的core libraries,直接提供Cache实现,足以证明Cache应用的广泛程度。
然而作为工具库中的一部分,我们自然不能期待Guava对Cache有比较完善的实现。因而Guava中的Cache只能用于一些把Cache作为一种辅助设计的项目或者在项目的前期为了实现简单而引入。
在Guava CacheBuilder的注释中给定Guava Cache以下的需求:
- automatic loading of entries into the cache
- least-recently-used eviction when a maximum size is exceeded
- time-based expiration of entries, measured since last access or last write
- keys automatically wrapped in WeakReference
- values automatically wrapped in WeakReference or SoftReference soft
- notification of evicted (or otherwise removed) entries
- accumulation of cache access statistics
对于这样的需求,如果要我们自己来实现,我们应该怎么设计?对于我来说,对于其核心实现我会做如下的设计:
- 定义一个CacheConfig类用于纪录所有的配置,如CacheLoader,maximum size、expire time、key reference level、value reference level、eviction listener等。
- 定义一个Cache接口,该接口类似Map(或ConcurrentMap),但是为了和Map区别开来,因而重新定义一个Cache接口。
- 定义一个实现Cache接口的类CacheImpl,它接收CacheConfig作为参数的构造函数,并将CacheConfig实例保存在字段中。
- 在实现上模仿ConcurrentHashMap的实现方式,有一个Segment数组,其长度由配置的concurrencyLevel值决定。为了实现最近最少使用算法(LRU),添加AccessQueue和WriteQueue字段,这两个Queue内部采用双链表,每次新创建一个Entry,就将这个Entry加入到这两个Queue的末尾,而每读取一个Entry就将其添加到AccessQueue的末尾,没更新一个Entry将该Entry添加到WriteQueue末尾。为了实现key和value上的WeakReference、SoftReference,添加ReferenceQueue<K>类型的keyReferenceQueue和valueReferenceQueue字段。
- 在每次调用方法之前都遍历AccessQueue和WriteQueue,如果发现有Entry已经expire,就将该Entry从这两个Queue上和Cache中移除。然后遍历keyReferenceQueue和valueReference,如果发现有项存在,同样将它们移除。在移除时如果有EvictionListener注册着,则调用该listener。
- 对Segment实现,它时一个CacheEntry数组,CacheEntry是一个链节点,它包含hash、key、vlaue、next。CacheEntry根据是否需要包装在WeakReference中创建WeakEntry或StrongEntry,而对value根据是否需要包装在WeakReference、SoftReference中创建WeakValueReference、SoftValueReference、StrongValueReference。在get操作中对于需要使用CacheLoader加载的值先添加一个具有LoadingValueReference值的Entry,这样可以保证同一个Key只加载依次。在加载成功后将LoadingValueReference根据配置替换成其他Weak、Soft、Strong ValueReference。
- 对于cache access statistics,只需要有一个类在需要的地方做一些统计计数即可。
- 最后我必须得承认以上的设计有很多是对Guava Cache的参考,我有点后悔没有在看源码之前考虑这个问题,等看过以后思路就被它的实现给羁绊了。。。。
Guava Cache的数据结构
因为新进一家公司,要熟悉新公司项目以及项目用到的第三方库的代码,因而几个月来看了许多代码。然后越来越发现要理解一个项目的最快方法是先搞清楚该项目的底层数据结构,然后再去看构建于这些数据结构以上的逻辑就会容易许多。记得在还是学生的时候,有在一本书上看到过一个大牛说的一句话:程序=数据结构+算法;当时对这句话并不是和理解,现在是很赞同这句话,我对算法接触的不多,因而我更倾向于将这里的算法理解长控制数据流动的逻辑。因而我们先来熟悉一下Guava Cache的数据结构。
Cache类似于Map,它是存储键值对的集合,然而它和Map不同的是它还需要处理evict、expire、dynamic load等逻辑,需要一些额外信息来实现这些操作。在面向对象思想中,经常使用类对一些关联性比较强的数据做封装,同时把操作这些数据相关的操作放到该类中。因而Guava Cache使用ReferenceEntry接口来封装一个键值对,而用ValueReference来封装Value值。这里之所以用Reference命令,是因为Guava Cache要支持WeakReference Key和SoftReference、WeakReference value。
ValueReference
对于ValueReference,因为Guava Cache支持强引用的Value、SoftReference Value以及WeakReference Value,因而它对应三个实现类:StrongValueReference、SoftValueReference、WeakValueReference。为了支持动态加载机制,它还有一个LoadingValueReference,在需要动态加载一个key的值时,先把该值封装在LoadingValueReference中,以表达该key对应的值已经在加载了,如果其他线程也要查询该key对应的值,就能得到该引用,并且等待改值加载完成,从而保证该值只被加载一次(可以在evict以后重新加载)。在该只加载完成后,将LoadingValueReference替换成其他ValueReference类型。对新创建的LoadingValueReference,由于其内部oldValue的初始值是UNSET,它isActive为false,isLoading为false,因而此时的LoadingValueReference的isActive为false,但是isLoading为true。每个ValueReference都纪录了weight值,所谓weight从字面上理解是“该值的重量”,它由Weighter接口计算而得。weight在Guava Cache中由两个用途:1. 对weight值为0时,在计算因为size limit而evict是忽略该Entry(它可以通过其他机制evict);2. 如果设置了maximumWeight值,则当Cache中weight和超过了该值时,就会引起evict操作。但是目前还不知道这个设计的用途。最后,Guava Cache还定义了Stength枚举类型作为ValueReference的factory类,它有三个枚举值:Strong、Soft、Weak,这三个枚举值分别创建各自的ValueReference,并且根据传入的weight值是否为1而决定是否要创建Weight版本的ValueReference。以下是ValueReference的类图:
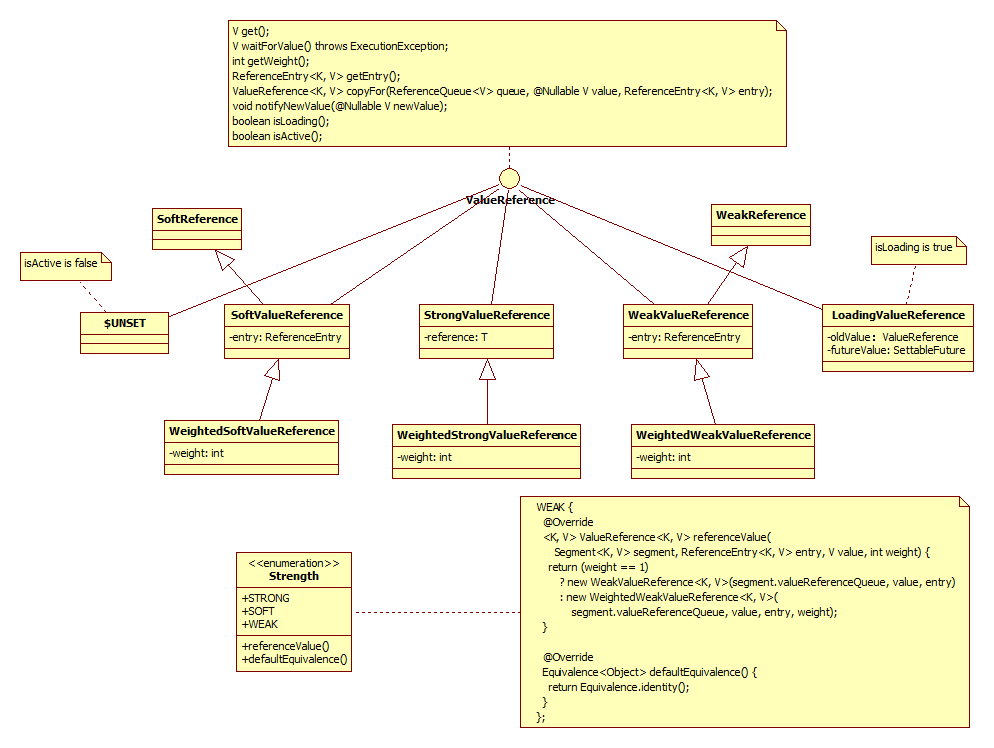
这里ValueReference之所以要有对ReferenceEntry的引用是因为在Value因为WeakReference、SoftReference被回收时,需要使用其key将对应的项从Segment的table中移除;copyFor()函数的存在是因为在expand(rehash)重新创建节点时,对WeakReference、SoftReference需要重新创建实例(个人感觉是为了保持对象状态不会相互影响,但是不确定是否还有其他原因),而对强引用来说,直接使用原来的值即可,这里很好的展示了对彼变化的封装思想;notifiyNewValue只用于LoadingValueReference,它的存在是为了对LoadingValueReference来说能更加及时的得到CacheLoader加载的值。
ReferenceEntry
ReferenceEntry是Guava Cache中对一个键值对节点的抽象。和ConcurrentHashMap一样,Guava Cache由多个Segment组成,而每个Segment包含一个ReferenceEntry数组,每个ReferenceEntry数组项都是一条ReferenceEntry链。并且一个ReferenceEntry包含key、hash、valueReference、next字段。除了在ReferenceEntry数组项中组成的链,在一个Segment中,所有ReferenceEntry还组成access链(accessQueue)和write链(writeQueue),这两条都是双向链表,分别通过previousAccess、nextAccess和previousWrite、nextWrite字段链接而成。在对每个节点的更新操作都会将该节点重新链到write链和access链末尾,并且更新其writeTime和accessTime字段,而没找到一个节点,都会将该节点重新链到access链末尾,并更新其accessTime字段。这两个双向链表的存在都是为了实现采用最近最少使用算法(LRU)的evict操作(expire、size limit引起的evict)。
Guava Cache中的ReferenceEntry可以是强引用类型的key,也可以WeakReference类型的key,为了减少内存使用量,还可以根据是否配置了expireAfterWrite、expireAfterAccess、maximumSize来决定是否需要write链和access链确定要创建的具体Reference:StrongEntry、StrongWriteEntry、StrongAccessEntry、StrongWriteAccessEntry等。创建不同类型的ReferenceEntry由其枚举工厂类EntryFactory来实现,它根据key的Strongth类型、是否使用accessQueue、是否使用writeQueue来决定不同的EntryFactry实例,并通过它创建相应的ReferenceEntry实例。ReferenceEntry类图如下:
 WriteQueue和AccessQueue
WriteQueue和AccessQueue
为了实现最近最少使用算法,Guava Cache在Segment中添加了两条链:write链(writeQueue)和access链(accessQueue),这两条链都是一个双向链表,通过ReferenceEntry中的previousInWriteQueue、nextInWriteQueue和previousInAccessQueue、nextInAccessQueue链接而成,但是以Queue的形式表达。WriteQueue和AccessQueue都是自定义了offer、add(直接调用offer)、remove、poll等操作的逻辑,对于offer(add)操作,如果是新加的节点,则直接加入到该链的结尾,如果是已存在的节点,则将该节点链接的链尾;对remove操作,直接从该链中移除该节点;对poll操作,将头节点的下一个节点移除,并返回。
static final class WriteQueue<K, V> extends AbstractQueue<ReferenceEntry<K, V>> {
final ReferenceEntry<K, V> head = new AbstractReferenceEntry<K, V>() ....
@Override
public boolean offer(ReferenceEntry<K, V> entry) {
// unlink
connectWriteOrder(entry.getPreviousInWriteQueue(), entry.getNextInWriteQueue());
// add to tail
connectWriteOrder(head.getPreviousInWriteQueue(), entry);
connectWriteOrder(entry, head);
return true;
}
@Override
public ReferenceEntry<K, V> peek() {
ReferenceEntry<K, V> next = head.getNextInWriteQueue();
return (next == head) ? null : next;
}
@Override
public ReferenceEntry<K, V> poll() {
ReferenceEntry<K, V> next = head.getNextInWriteQueue();
if (next == head) {
return null;
}
remove(next);
return next;
}
@Override
public boolean remove(Object o) {
ReferenceEntry<K, V> e = (ReferenceEntry) o;
ReferenceEntry<K, V> previous = e.getPreviousInWriteQueue();
ReferenceEntry<K, V> next = e.getNextInWriteQueue();
connectWriteOrder(previous, next);
nullifyWriteOrder(e);
return next != NullEntry.INSTANCE;
}
@Override
public boolean contains(Object o) {
ReferenceEntry<K, V> e = (ReferenceEntry) o;
return e.getNextInWriteQueue() != NullEntry.INSTANCE;
}
....
}
对于不需要维护WriteQueue和AccessQueue的配置(即没有expire time或size limit的evict策略)来说,我们可以使用DISCARDING_QUEUE以节省内存:
static final Queue<? extends Object> DISCARDING_QUEUE = new AbstractQueue<Object>() {
@Override
public boolean offer(Object o) {
return true;
}
@Override
public Object peek() {
return null;
}
@Override
public Object poll() {
return null;
}
....
};
Segment中的evict 在解决了所有数据结构的问题以后,让我们来看看LocalCache中的核心类Segment的实现,首先从evict开始。在Guava Cache的evict时机上,它没有使用另一个后台线程每隔一段时间扫瞄一次table以evict那些已经expire的entry。而是它在每次操作开始和结束时才做一遍清理工作,这样可以减少开销,但是如果长时间不调用方法的话,会引起有些entry不能及时被evict出去。evict主要处理四个Queue:1. keyReferenceQueue;2. valueReferenceQueue;3. writeQueue;4. accessQueue。前两个queue是因为WeakReference、SoftReference被垃圾回收时加入的,清理时只需要遍历整个queue,将对应的项从LocalCache中移除即可,这里keyReferenceQueue存放ReferenceEntry,而valueReferenceQueue存放的是ValueReference,要从LocalCache中移除需要有key,因而ValueReference需要有对ReferenceEntry的引用。这里的移除通过LocalCache而不是Segment是因为在移除时因为expand(rehash)可能导致原来在某个Segment中的ReferenceEntry后来被移动到另一个Segment中了。而对后两个Queue,只需要检查是否配置了相应的expire时间,然后从头开始查找已经expire的Entry,将它们移除即可。有不同的是在移除时,还会注册移除的事件,这些事件将会在接下来的操作调用注册的RemovalListener触发,这些代码比较简单,不详述。
在put的时候,还会清理recencyQueue,即将recencyQueue中的Entry添加到accessEntry中,此时可能会发生某个Entry实际上已经被移除了,但是又被添加回accessQueue中了,这种情况下,如果没有使用WeakReference、SoftReference,也没有配置expire时间,则会引起一些内存泄漏问题。recencyQueue在get操作时被添加,但是为什么会有这个Queue的存在一直没有想明白。
Segment中的put操作 put操作相对比较简单,首先它需要获得锁,然后尝试做一些清理工作,接下来的逻辑类似ConcurrentHashMap中的rehash,不详述。需要说明的是当找到一个已存在的Entry时,需要先判断当前的ValueRefernece中的值事实上已经被回收了,因为它们可以时WeakReference、SoftReference类型,如果已经被回收了,则将新值写入。并且在每次更新时注册当前操作引起的移除事件,指定相应的原因:COLLECTED、REPLACED等,这些注册的事件在退出的时候统一调用LocalCache注册的RemovalListener,由于事件处理可能会有很长时间,因而这里将事件处理的逻辑在退出锁以后才做。最后,在更新已存在的Entry结束后都尝试着将那些已经expire的Entry移除。另外put操作中还需要更新writeQueue和accessQueue的语义正确性。
V put(K key, int hash, V value, boolean onlyIfAbsent) {
....
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null && map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
if (entryValue == null) {
++modCount;
if (valueReference.isActive()) {
enqueueNotification(key, hash, valueReference, RemovalCause.COLLECTED);
setValue(e, key, value, now);
newCount = this.count; // count remains unchanged
} else {
setValue(e, key, value, now);
newCount = this.count + 1;
}
this.count = newCount; // write-volatile
evictEntries();
return null;
} else if (onlyIfAbsent) {
recordLockedRead(e, now);
return entryValue;
} else {
++modCount;
enqueueNotification(key, hash, valueReference, RemovalCause.REPLACED);
setValue(e, key, value, now);
evictEntries();
return entryValue;
}
}
}
...
} finally {
...
postWriteCleanup();
}
}
Segment带CacheLoader的get操作 这部分的代码有点不知道怎么说了,大概上的步骤是:1. 先查找table中是否已存在没有被回收、也没有expire的entry,如果找到,并在CacheBuilder中配置了refreshAfterWrite,并且当前时间间隔已经操作这个事件,则重新加载值,否则,直接返回原有的值;2. 如果查找到的ValueReference是LoadingValueReference,则等待该LoadingValueReference加载结束,并返回加载的值;3. 如果没有找到entry,或者找到的entry的值为null,则加锁后,继续table中已存在key对应的entry,如果找到并且对应的entry.isLoading()为true,则表示有另一个线程正在加载,因而等待那个线程加载完成,如果找到一个非null值,返回该值,否则创建一个LoadingValueReference,并调用loadSync加载相应的值,在加载完成后,将新加载的值更新到table中,即大部分情况下替换原来的LoadingValueReference。
Segment中的其他操作 其他操作包括不含CacheLoader的get、containsKey、containsValue、replace等操作逻辑重复性很大,而且和ConcurrentHashMap的实现方式也类似,不在详述。
Cache StatsCounter和CacheStats 为了纪录Cache的使用情况,如果命中次数、没有命中次数、evict次数等,Guava Cache中定义了StatsCounter做这些统计信息,它有一个简单的SimpleStatsCounter实现,我们也可以通过CacheBuilder配置自己的StatsCounter。
public interface StatsCounter {
public void recordHits(int count);
public void recordMisses(int count);
public void recordLoadSuccess(long loadTime);
public void recordLoadException(long loadTime);
public void recordEviction();
public CacheStats snapshot();
}
在得到StatsCounter实例后,可以使用CacheStats获取具体的统计信息:
public final class CacheStats {
private final long hitCount;
private final long missCount;
private final long loadSuccessCount;
private final long loadExceptionCount;
private final long totalLoadTime;
private final long evictionCount;

}
同ConcurrentHashMap,在知道Segment实现以后,其他的方法基本上都是代理给Segment内部方法,因而在LocalCache类中的其他方法看起来就比较容易理解,不在详述。然而Guava Cache并没有将ConcurrentMap直接提供给用户使用,而是为了区分Cache和Map,它自定义了一个自己的Cache接口和LoadingCache接口,我们可以通过CacheBuilder配置不同的参数,然后使用build()方法返回一个Cache或LoadingCache实例:
public interface Cache<K, V> {
V getIfPresent(Object key);
V get(K key, Callable<? extends V> valueLoader) throws ExecutionException;
ImmutableMap<K, V> getAllPresent(Iterable<?> keys);
void put(K key, V value);
void putAll(Map<? extends K,? extends V> m);
void invalidate(Object key);
void invalidateAll(Iterable<?> keys);
void invalidateAll();
long size();
CacheStats stats();
ConcurrentMap<K, V> asMap();
void cleanUp();
}
public interface LoadingCache<K, V> extends Cache<K, V>, Function<K, V> {
V get(K key) throws ExecutionException;
V getUnchecked(K key);
ImmutableMap<K, V> getAll(Iterable<? extends K> keys) throws ExecutionException;
V apply(K key);
void refresh(K key);
ConcurrentMap<K, V> asMap();
}
