数据挖掘-基于贝叶斯算法及KNN算法的newsgroup18828文档分类器的JAVA实现(上)
- - CSDN博客推荐文章本文主要研究基于贝叶斯算法及KNN算法的newsgroup18828文档分类器的设计及实现,数据预处理、贝叶斯算法及KNN算法实现工程源码下载见:. 对newsgroup文档集进行预处理,提取出30095 个特征词. 计算每篇文档中的特征词的TF*IDF值,实现文档向量化,在KNN算法中使用. 用JAVA实现了KNN算法及朴素贝叶斯算法的newsgroup文本分类器.
本文主要研究基于贝叶斯算法及KNN算法的newsgroup18828文档分类器的设计及实现,数据预处理、贝叶斯算法及KNN算法实现工程源码下载见:
本文主要内容如下
对newsgroup文档集进行预处理,提取出30095 个特征词
计算每篇文档中的特征词的TF*IDF值,实现文档向量化,在KNN算法中使用
用JAVA实现了KNN算法及朴素贝叶斯算法的newsgroup文本分类器
1、Newsgroup文档集介绍
Newsgroups最早由Lang于1995收集并在[Lang 1995]中使用。
它含有20000篇左右的Usenet文档,几乎平均分配20个不同的新闻组。
除了其中4.5%的文档属于两个或两个以上的新闻组以外,其余文档仅属于一个新闻组,因此它通常被作为单标注分类问题来处处理
Newsgroups已经成为文本分及聚类中常用的文档集
美国MIT大学Jason Rennie对Newsgroups作了必要的处理,使得每个文档只属于一个新闻组,形成Newsgroups-18828
2、Newsgroup文档预处理
要做文本分类首先得完成文本的预处理,预处理的主要步骤如下
package com.pku.yangliu; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.util.ArrayList; /** * Newsgroups文档集预处理类 * @author yangliu * @qq 772330184 * @mail [email protected] */ public class DataPreProcess { /**输入文件调用处理数据函数 * @param strDir newsgroup文件目录的绝对路径 * @throws IOException */ public void doProcess(String strDir) throws IOException{ File fileDir = new File(strDir); if(!fileDir.exists()){ System.out.println("File not exist:" + strDir); return; } String subStrDir = strDir.substring(strDir.lastIndexOf('/')); String dirTarget = strDir + "/../../processedSample_includeNotSpecial"+subStrDir; File fileTarget = new File(dirTarget); if(!fileTarget.exists()){//注意processedSample需要先建立目录建出来,否则会报错,因为母目录不存在 fileTarget.mkdir(); } File[] srcFiles = fileDir.listFiles(); String[] stemFileNames = new String[srcFiles.length]; for(int i = 0; i < srcFiles.length; i++){ String fileFullName = srcFiles[i].getCanonicalPath(); String fileShortName = srcFiles[i].getName(); if(!new File(fileFullName).isDirectory()){//确认子文件名不是目录如果是可以再次递归调用 System.out.println("Begin preprocess:"+fileFullName); StringBuilder stringBuilder = new StringBuilder(); stringBuilder.append(dirTarget + "/" + fileShortName); createProcessFile(fileFullName, stringBuilder.toString()); stemFileNames[i] = stringBuilder.toString(); } else { fileFullName = fileFullName.replace("\\","/"); doProcess(fileFullName); } } //下面调用stem算法 if(stemFileNames.length > 0 && stemFileNames[0] != null){ Stemmer.porterMain(stemFileNames); } } /**进行文本预处理生成目标文件 * @param srcDir 源文件文件目录的绝对路径 * @param targetDir 生成的目标文件的绝对路径 * @throws IOException */ private static void createProcessFile(String srcDir, String targetDir) throws IOException { // TODO Auto-generated method stub FileReader srcFileReader = new FileReader(srcDir); FileReader stopWordsReader = new FileReader("F:/DataMiningSample/stopwords.txt"); FileWriter targetFileWriter = new FileWriter(targetDir); BufferedReader srcFileBR = new BufferedReader(srcFileReader);//装饰模式 BufferedReader stopWordsBR = new BufferedReader(stopWordsReader); String line, resLine, stopWordsLine; //用stopWordsBR够着停用词的ArrayList容器 ArrayList<String> stopWordsArray = new ArrayList<String>(); while((stopWordsLine = stopWordsBR.readLine()) != null){ if(!stopWordsLine.isEmpty()){ stopWordsArray.add(stopWordsLine); } } while((line = srcFileBR.readLine()) != null){ resLine = lineProcess(line,stopWordsArray); if(!resLine.isEmpty()){ //按行写,一行写一个单词 String[] tempStr = resLine.split(" ");//\s for(int i = 0; i < tempStr.length; i++){ if(!tempStr[i].isEmpty()){ targetFileWriter.append(tempStr[i]+"\n"); } } } } targetFileWriter.flush(); targetFileWriter.close(); srcFileReader.close(); stopWordsReader.close(); srcFileBR.close(); stopWordsBR.close(); } /**对每行字符串进行处理,主要是词法分析、去停用词和stemming * @param line 待处理的一行字符串 * @param ArrayList<String> 停用词数组 * @return String 处理好的一行字符串,是由处理好的单词重新生成,以空格为分隔符 * @throws IOException */ private static String lineProcess(String line, ArrayList<String> stopWordsArray) throws IOException { // TODO Auto-generated method stub //step1 英文词法分析,去除数字、连字符、标点符号、特殊字符,所有大写字母转换成小写,可以考虑用正则表达式 String res[] = line.split("[^a-zA-Z]"); //这里要小心,防止把有单词中间有数字和连字符的单词 截断了,但是截断也没事 String resString = new String(); //step2去停用词 //step3stemming,返回后一起做 for(int i = 0; i < res.length; i++){ if(!res[i].isEmpty() && !stopWordsArray.contains(res[i].toLowerCase())){ resString += " " + res[i].toLowerCase() + " "; } } return resString; } /** * @param args * @throws IOException */ public void BPPMain(String[] args) throws IOException { // TODO Auto-generated method stub DataPreProcess dataPrePro = new DataPreProcess(); dataPrePro.doProcess("F:/DataMiningSample/orginSample"); } }
package com.pku.yangliu; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.util.SortedMap; import java.util.TreeMap; /**创建训练样例集合与测试样例集合 * @author yangliu * @qq 772330184 * @mail [email protected] * */ public class CreateTrainAndTestSample { void filterSpecialWords() throws IOException { // TODO Auto-generated method stub String word; ComputeWordsVector cwv = new ComputeWordsVector(); String fileDir = "F:/DataMiningSample/processedSample_includeNotSpecial"; SortedMap<String,Double> wordMap = new TreeMap<String,Double>(); wordMap = cwv.countWords(fileDir, wordMap); cwv.printWordMap(wordMap);//把wordMap输出到文件 File[] sampleDir = new File(fileDir).listFiles(); for(int i = 0; i < sampleDir.length; i++){ File[] sample = sampleDir[i].listFiles(); String targetDir = "F:/DataMiningSample/processedSampleOnlySpecial/"+sampleDir[i].getName(); File targetDirFile = new File(targetDir); if(!targetDirFile.exists()){ targetDirFile.mkdir(); } for(int j = 0;j < sample.length; j++){ String fileShortName = sample[j].getName(); if(fileShortName.contains("stemed")){ targetDir = "F:/DataMiningSample/processedSampleOnlySpecial/"+sampleDir[i].getName()+"/"+fileShortName.substring(0,5); FileWriter tgWriter= new FileWriter(targetDir); FileReader samReader = new FileReader(sample[j]); BufferedReader samBR = new BufferedReader(samReader); while((word = samBR.readLine()) != null){ if(wordMap.containsKey(word)){ tgWriter.append(word + "\n"); } } tgWriter.flush(); tgWriter.close(); } } } } void createTestSamples(String fileDir, double trainSamplePercent,int indexOfSample,String classifyResultFile) throws IOException { // TODO Auto-generated method stub String word, targetDir; FileWriter crWriter = new FileWriter(classifyResultFile);//测试样例正确类目记录文件 File[] sampleDir = new File(fileDir).listFiles(); for(int i = 0; i < sampleDir.length; i++){ File[] sample = sampleDir[i].listFiles(); double testBeginIndex = indexOfSample*(sample.length * (1-trainSamplePercent));//测试样例的起始文件序号 double testEndIndex = (indexOfSample+1)*(sample.length * (1-trainSamplePercent));//测试样例集的结束文件序号 for(int j = 0;j < sample.length; j++){ FileReader samReader = new FileReader(sample[j]); BufferedReader samBR = new BufferedReader(samReader); String fileShortName = sample[j].getName(); String subFileName = fileShortName; if(j > testBeginIndex && j< testEndIndex){//序号在规定区间内的作为测试样本,需要为测试样本生成类别-序号文件,最后加入分类的结果,一行对应一个文件,方便统计准确率 targetDir = "F:/DataMiningSample/TestSample"+indexOfSample+"/"+sampleDir[i].getName(); crWriter.append(subFileName + " " + sampleDir[i].getName()+"\n"); } else{//其余作为训练样本 targetDir = "F:/DataMiningSample/TrainSample"+indexOfSample+"/"+sampleDir[i].getName(); } targetDir = targetDir.replace("\\","/"); File trainSamFile = new File(targetDir); if(!trainSamFile.exists()){ trainSamFile.mkdir(); } targetDir += "/"+subFileName; FileWriter tsWriter = new FileWriter(new File(targetDir)); while((word = samBR.readLine()) != null){ tsWriter.append(word + "\n"); } tsWriter.flush(); tsWriter.close(); } } crWriter.flush(); crWriter.close(); } }
package com.pku.yangliu; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.math.BigDecimal; import java.util.Iterator; import java.util.Map; import java.util.Set; import java.util.SortedSet; import java.util.TreeMap; import java.util.TreeSet; import java.util.Vector; /**利用朴素贝叶斯算法对newsgroup文档集做分类,采用十组交叉测试取平均值 * 采用多项式模型,stanford信息检索导论课件上面言多项式模型比伯努利模型准确度高 * 类条件概率P(tk|c)=(类c 下单词tk 在各个文档中出现过的次数之和+1)/(类c下单词总数+|V|) * @author yangliu * @qq 772330184 * @mail [email protected] * */ public class NaiveBayesianClassifier { /**用贝叶斯法对测试文档集分类 * @param trainDir 训练文档集目录 * @param testDir 测试文档集目录 * @param classifyResultFileNew 分类结果文件路径 * @throws Exception */ private void doProcess(String trainDir, String testDir, String classifyResultFileNew) throws Exception { // TODO Auto-generated method stub Map<String,Double> cateWordsNum = new TreeMap<String,Double>();//保存训练集每个类别的总词数 Map<String,Double> cateWordsProb = new TreeMap<String,Double>();//保存训练样本每个类别中每个属性词的出现词数 cateWordsProb = getCateWordsProb(trainDir); cateWordsNum = getCateWordsNum(trainDir); double totalWordsNum = 0.0;//记录所有训练集的总词数 Set<Map.Entry<String,Double>> cateWordsNumSet = cateWordsNum.entrySet(); for(Iterator<Map.Entry<String,Double>> it = cateWordsNumSet.iterator(); it.hasNext();){ Map.Entry<String, Double> me = it.next(); totalWordsNum += me.getValue(); } //下面开始读取测试样例做分类 Vector<String> testFileWords = new Vector<String>(); String word; File[] testDirFiles = new File(testDir).listFiles(); FileWriter crWriter = new FileWriter(classifyResultFileNew); for(int i = 0; i < testDirFiles.length; i++){ File[] testSample = testDirFiles[i].listFiles(); for(int j = 0;j < testSample.length; j++){ testFileWords.clear(); FileReader spReader = new FileReader(testSample[j]); BufferedReader spBR = new BufferedReader(spReader); while((word = spBR.readLine()) != null){ testFileWords.add(word); } //下面分别计算该测试样例属于二十个类别的概率 File[] trainDirFiles = new File(trainDir).listFiles(); BigDecimal maxP = new BigDecimal(0); String bestCate = null; for(int k = 0; k < trainDirFiles.length; k++){ BigDecimal p = computeCateProb(trainDirFiles[k], testFileWords, cateWordsNum, totalWordsNum, cateWordsProb); if(k == 0){ maxP = p; bestCate = trainDirFiles[k].getName(); continue; } if(p.compareTo(maxP) == 1){ maxP = p; bestCate = trainDirFiles[k].getName(); } } crWriter.append(testSample[j].getName() + " " + bestCate + "\n"); crWriter.flush(); } } crWriter.close(); } /**统计某类训练样本中每个单词的出现次数 * @param strDir 训练样本集目录 * @return Map<String,Double> cateWordsProb 用"类目_单词"对来索引的map,保存的val就是该类目下该单词的出现次数 * @throws IOException */ public Map<String,Double> getCateWordsProb(String strDir) throws IOException{ Map<String,Double> cateWordsProb = new TreeMap<String,Double>(); File sampleFile = new File(strDir); File [] sampleDir = sampleFile.listFiles(); String word; for(int i = 0;i < sampleDir.length; i++){ File [] sample = sampleDir[i].listFiles(); for(int j = 0; j < sample.length; j++){ FileReader samReader = new FileReader(sample[j]); BufferedReader samBR = new BufferedReader(samReader); while((word = samBR.readLine()) != null){ String key = sampleDir[i].getName() + "_" + word; if(cateWordsProb.containsKey(key)){ double count = cateWordsProb.get(key) + 1.0; cateWordsProb.put(key, count); } else { cateWordsProb.put(key, 1.0); } } } } return cateWordsProb; } /**计算某一个测试样本属于某个类别的概率 * @param Map<String, Double> cateWordsProb 记录每个目录中出现的单词及次数 * @param File trainFile 该类别所有的训练样本所在目录 * @param Vector<String> testFileWords 该测试样本中的所有词构成的容器 * @param double totalWordsNum 记录所有训练样本的单词总数 * @param Map<String, Double> cateWordsNum 记录每个类别的单词总数 * @return BigDecimal 返回该测试样本在该类别中的概率 * @throws Exception * @throws IOException */ private BigDecimal computeCateProb(File trainFile, Vector<String> testFileWords, Map<String, Double> cateWordsNum, double totalWordsNum, Map<String, Double> cateWordsProb) throws Exception { // TODO Auto-generated method stub BigDecimal probability = new BigDecimal(1); double wordNumInCate = cateWordsNum.get(trainFile.getName()); BigDecimal wordNumInCateBD = new BigDecimal(wordNumInCate); BigDecimal totalWordsNumBD = new BigDecimal(totalWordsNum); for(Iterator<String> it = testFileWords.iterator(); it.hasNext();){ String me = it.next(); String key = trainFile.getName()+"_"+me; double testFileWordNumInCate; if(cateWordsProb.containsKey(key)){ testFileWordNumInCate = cateWordsProb.get(key); }else testFileWordNumInCate = 0.0; BigDecimal testFileWordNumInCateBD = new BigDecimal(testFileWordNumInCate); BigDecimal xcProb = (testFileWordNumInCateBD.add(new BigDecimal(0.0001))).divide(totalWordsNumBD.add(wordNumInCateBD),10, BigDecimal.ROUND_CEILING); probability = probability.multiply(xcProb); } BigDecimal res = probability.multiply(wordNumInCateBD.divide(totalWordsNumBD,10, BigDecimal.ROUND_CEILING)); return res; } /**获得每个类目下的单词总数 * @param trainDir 训练文档集目录 * @return Map<String, Double> <目录名,单词总数>的map * @throws IOException */ private Map<String, Double> getCateWordsNum(String trainDir) throws IOException { // TODO Auto-generated method stub Map<String,Double> cateWordsNum = new TreeMap<String,Double>(); File[] sampleDir = new File(trainDir).listFiles(); for(int i = 0; i < sampleDir.length; i++){ double count = 0; File[] sample = sampleDir[i].listFiles(); for(int j = 0;j < sample.length; j++){ FileReader spReader = new FileReader(sample[j]); BufferedReader spBR = new BufferedReader(spReader); while(spBR.readLine() != null){ count++; } } cateWordsNum.put(sampleDir[i].getName(), count); } return cateWordsNum; } /**根据正确类目文件和分类结果文件统计出准确率 * @param classifyResultFile 正确类目文件 * @param classifyResultFileNew 分类结果文件 * @return double 分类的准确率 * @throws IOException */ double computeAccuracy(String classifyResultFile, String classifyResultFileNew) throws IOException { // TODO Auto-generated method stub Map<String,String> rightCate = new TreeMap<String,String>(); Map<String,String> resultCate = new TreeMap<String,String>(); rightCate = getMapFromResultFile(classifyResultFile); resultCate = getMapFromResultFile(classifyResultFileNew); Set<Map.Entry<String, String>> resCateSet = resultCate.entrySet(); double rightCount = 0.0; for(Iterator<Map.Entry<String, String>> it = resCateSet.iterator(); it.hasNext();){ Map.Entry<String, String> me = it.next(); if(me.getValue().equals(rightCate.get(me.getKey()))){ rightCount ++; } } computerConfusionMatrix(rightCate,resultCate); return rightCount / resultCate.size(); } /**根据正确类目文件和分类结果文计算混淆矩阵并且输出 * @param rightCate 正确类目对应map * @param resultCate 分类结果对应map * @return double 分类的准确率 * @throws IOException */ private void computerConfusionMatrix(Map<String, String> rightCate, Map<String, String> resultCate) { // TODO Auto-generated method stub int[][] confusionMatrix = new int[20][20]; //首先求出类目对应的数组索引 SortedSet<String> cateNames = new TreeSet<String>(); Set<Map.Entry<String, String>> rightCateSet = rightCate.entrySet(); for(Iterator<Map.Entry<String, String>> it = rightCateSet.iterator(); it.hasNext();){ Map.Entry<String, String> me = it.next(); cateNames.add(me.getValue()); } cateNames.add("rec.sport.baseball");//防止数少一个类目 String[] cateNamesArray = cateNames.toArray(new String[0]); Map<String,Integer> cateNamesToIndex = new TreeMap<String,Integer>(); for(int i = 0; i < cateNamesArray.length; i++){ cateNamesToIndex.put(cateNamesArray[i],i); } for(Iterator<Map.Entry<String, String>> it = rightCateSet.iterator(); it.hasNext();){ Map.Entry<String, String> me = it.next(); confusionMatrix[cateNamesToIndex.get(me.getValue())][cateNamesToIndex.get(resultCate.get(me.getKey()))]++; } //输出混淆矩阵 double[] hangSum = new double[20]; System.out.print(" "); for(int i = 0; i < 20; i++){ System.out.print(i + " "); } System.out.println(); for(int i = 0; i < 20; i++){ System.out.print(i + " "); for(int j = 0; j < 20; j++){ System.out.print(confusionMatrix[i][j]+" "); hangSum[i] += confusionMatrix[i][j]; } System.out.println(confusionMatrix[i][i] / hangSum[i]); } System.out.println(); } /**从分类结果文件中读取map * @param classifyResultFileNew 类目文件 * @return Map<String, String> 由<文件名,类目名>保存的map * @throws IOException */ private Map<String, String> getMapFromResultFile( String classifyResultFileNew) throws IOException { // TODO Auto-generated method stub File crFile = new File(classifyResultFileNew); FileReader crReader = new FileReader(crFile); BufferedReader crBR = new BufferedReader(crReader); Map<String, String> res = new TreeMap<String, String>(); String[] s; String line; while((line = crBR.readLine()) != null){ s = line.split(" "); res.put(s[0], s[1]); } return res; } /** * @param args * @throws Exception */ public void NaiveBayesianClassifierMain(String[] args) throws Exception { //TODO Auto-generated method stub //首先创建训练集和测试集 CreateTrainAndTestSample ctt = new CreateTrainAndTestSample(); NaiveBayesianClassifier nbClassifier = new NaiveBayesianClassifier(); ctt.filterSpecialWords();//根据包含非特征词的文档集生成只包含特征词的文档集到processedSampleOnlySpecial目录下 double[] accuracyOfEveryExp = new double[10]; double accuracyAvg,sum = 0; for(int i = 0; i < 10; i++){//用交叉验证法做十次分类实验,对准确率取平均值 String TrainDir = "F:/DataMiningSample/TrainSample"+i; String TestDir = "F:/DataMiningSample/TestSample"+i; String classifyRightCate = "F:/DataMiningSample/classifyRightCate"+i+".txt"; String classifyResultFileNew = "F:/DataMiningSample/classifyResultNew"+i+".txt"; ctt.createTestSamples("F:/DataMiningSample/processedSampleOnlySpecial", 0.9, i,classifyRightCate); nbClassifier.doProcess(TrainDir,TestDir,classifyResultFileNew); accuracyOfEveryExp[i] = nbClassifier.computeAccuracy (classifyRightCate, classifyResultFileNew); System.out.println("The accuracy for Naive Bayesian Classifier in "+i+"th Exp is :" + accuracyOfEveryExp[i]); } for(int i = 0; i < 10; i++){ sum += accuracyOfEveryExp[i]; } accuracyAvg = sum / 10; System.out.println("The average accuracy for Naive Bayesian Classifier in all Exps is :" + accuracyAvg); } }
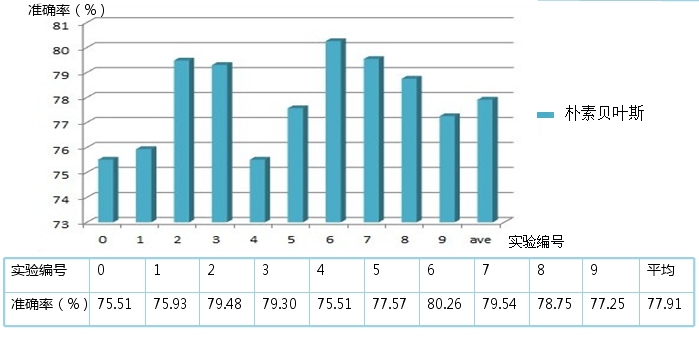
为方便计算混淆矩阵,将类目编号如下
0 alt.atheism
1 comp.graphics
2 comp.os.ms-windows.misc
3comp.sys.ibm.pc.hdwar
4comp.sys.mac.hardwar
5 comp.windows.x
6 misc.forsale
7 rec.autos
8 rec.motorcycles
9 rec.sport.baseball
10 rec.sport.hockey
11 sci.crypt
12 sci.electronics
13 sci.med
14 sci.space
15 soc.religion.christian
16 talk.politics.guns
17 talk.politics.mideast
18 talk.politics.misc
19 talk.religion.misc