2012·2汇总
Tumblr是世界上最流行的轻博客服务之一,2007年成立。
一,MySQL+Memcached
初期,其通知系统是由 MySQL+Memcached 的传统架构组成。
缺点:
MySQL负担重,表象就是 MySQL 并发事务数常常达到 InnoDB global transaction 最大值,即只能有1023个并发事务(注:特指
mysql5.0/5.1存在的问题,5.5.4以上版本修复)。
二,Tumblr 消息系统应用特性
- 按时间排序(Ordered by time)
- 唯一性,每一条消息都是唯一的(Unique (no duplicate notifications))
- 读写比大概是 60%/30%(Medium read/write ratio (60%/30%), mostly thanks to heavy caching)
- 每个用户的消息条数一定(Fixed number of notifications per user)
- 数据按用户划分,每个用户只能读自己的消息(Keyed by user, and read only by him/her)
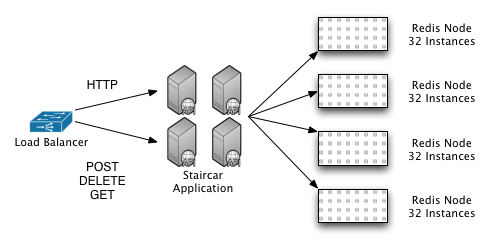
三,修改后的架构:Staircar+Redis
Staircar 的轻量级HTTP服务器+ Redis 集群。
架构图为:
四,性能指标要求
- notification request volume (over 7,500/s)
- data set size (23MM blogs, 100 notifications per blog, 160bytes per message),
- response times (<5ms)
Staircar 实际达到的指标:
在最高峰时的响应时间也在5ms以下,其性能测试结果是能处理每秒30,000次左右的请求。
五,引入 redis 的 presharding 思路
缺点是,引入了运维复杂度,导致运维管理成本增加;要用好 Presharing 方案,必须有相应的自动化运维手段相配套,比如:Redis实例的启停脚本、能检查Redis状态的运维监控手段。
优点是,更好的性能,更简单的容错,更能适应业务增长。
Presharding 思路大致的描述为:
『
假设有N台主机,每台主机上部署M个实例,整个系统有T = N × M个实例;
由于一个Redis实例的资源消耗非常小,所以一开始就可以部署比较多的 Redis 实例,比如128个实例;
在前期业务量比较低的时候,N可以比较少,M比较多,而且主机的配置(CPU+内存)可以较低;
在后期业务量较大的时候,N可以较多,M变小。
总之,通过这种方法,在容量增长过程可以始终保持Redis实例数(T)不变,所以避免了重新 Sharding 的问题。
』
拆分过程如下:
- 在新机器上启动好对应端口的 Redis 实例。
- 配置新端口为待迁移端口的从库。
- 待复制完成,与主库完成同步后,切换所有客户端配置到新的从库的端口。
- 配置从库为新的主库。
- 移除老的端口实例。
- 重复上述过程迁移好所有的端口到指定服务器上。
以上拆分流程是 Redis 作者提出的一个平滑迁移的过程,不过该拆分方法还是很依赖 Redis 本身的复制功能的,如果主库快照数据文件过大,这个复制的过程也会很久,同时会给主库带来压力。所以做这个拆分的过程最好选择为业务访问低峰时段进行。
六,一些细节
来自于 Tumblr 开发者的一些信息:
- Machine failures:每一个 Redis 实例都有自己的 slave,这样确保可以做 failover。
- Performance:Staircar 没有 redis 快。但它最主要的目的是,让 redis 基础设施对任何客户端都是透明的。
- Early Optimization:在一个庞大的基础架构中,你会面对很多局部性细节,很慢的客户端,机器宕机,其他运维问题等。我们感兴趣的是在 redis 实例池之上,构建一个高性能代理。
参考资源:
赠图一枚: 
本文链接