个性化搜索
- - CSDN博客云计算推荐文章 随着大数据日益成为IT领域的主流,如何利用大数据为业务提供支持以及来扩展市场成为当今众多公司追逐的目标. 目前,比较热门的领域有两块:recommendation(推荐系统)和personalization search(个性化搜索). 这两者有着很大的关联性和相似性,都是在大数据的环境得到了充分的发展,特别是recommendation,在Netflix公司举办的一个比赛---奖金一百万美元.
大家都记得塔吉特的案例:2012年,美国一名男子闯入他家附近的一家零售连锁超市塔吉特内抗议:你们竟然给我17岁的女儿发婴儿尿片和童车优惠券。店铺经理立刻向来者承认错误,但是该经理并不知道这一行为是总公司运行数据挖掘和个性化推荐的结果。一个月后,这位父亲前来道歉,因为这时他知道自己的女儿的确怀孕了。塔吉特比这位父亲知道自己女儿怀孕足足早了一个月。
塔吉特的案例是基于数据挖掘所做的用户行为分析的结果,经过分析之后,系统对用户进行了个性化推荐,以至于他们有把握给客户提供的商品是他们所喜欢和需要的。
个性化推荐的背后原理
要了解个性化推荐,先得理解互联网挖掘和协同过滤这两个概念。
准确地说, 互联网的挖掘( WEB 挖掘)指的是,利用数据挖掘技术从互联网上的文档中及互联网服务上自动发现并提取人们感兴趣的信息。
Web挖掘是对现代电子商务战略的一个重要支持,尤其是web挖掘中的用户访问模式挖掘主要用于对客户在网上行为的分析以及潜在的顾客信息的发现。Web挖掘的一个实现方法是对服务器日志、错误信息日志和本地终端数据日志等日志文件进行分析,挖掘出用户的访问行为、访问频率和浏览内容等信息,从而找出一定的模式和规则。
这就引出了协同过滤的概念。协同过滤是信息检索的一种技术,目标是为了帮用户在海量的互联网信息(商品)中找出感兴趣的内容。
在电子商务的应用中,我们通常使用协同过滤技术来找出关联商品推荐。这种商品推荐方法被称为推荐系统或个性化推荐系统。用通俗的话来说,协同过滤算法可以帮助找到和你喜好类似的那群人,看他们买了什么东西,然后推荐给你。
协同过滤的主要方法有以下三种:
基于用户的:收集用户的信息属性。对于每一个用户A,找到和他比较接近(或者相似)的几个用户。使用这些相似的用户对用户A的兴趣点进行预测,而把那些潜在的并没有被发掘出的兴趣点推荐给用户A。
基于项目的:收集项目的信息属性。对于一个用户,如果他对项目X有很高的兴趣,那么他很有可能也对与X相似的项目有潜在的兴趣。
基于内容的:除了用户和项目属性之外,基于内容的协同过滤还要进一步分析用户的评价内容和反馈。比如用户A对项目X感兴趣,但是他对X的兴趣是“痛恨”,这样就不能把他和“喜欢”项目X的用户归类在一起了。
找到相似点
当然,在电子商务领域,项目主要指的是商品。协同过滤推荐是基于这样的假设:如果一些用户对一些项的评分比较相似,则和这些用户相似的其他用户对这些项的评分也比较相似,而这些用户对于和这些项相似的其他项所做的评分也是相似的。
我们来举例说明:你在电子商城里买了电影碟片《指环王》和《星球大战》,协同过滤算法可以帮助你找到买了类似产品的其他人。如果算法发现他们还买了《哈利·波特》,就会把《哈利·波特》推荐给你。如果你买了余华的《兄弟》和《活着》、苏童的《大红灯笼》,系统找到了其他买这些书的人,发现这些人都买了莫言的《檀香刑》,于是就会把这本书推荐给你。
当我们找到和客户A“相似”的那些其他客户之后,就可以对商品列表进行排序了,越多和客户A相似的客户买了商品X,就说明商品X越可能吸引客户A。
简单地说,我们如果认为有1000个客户是和客户A“相似”的,那么可以把这些客户购买的历史数据调出来按照多寡排序。如果其中有100个客户都购买了商品X,有90个顾客购买了商品Y,那么我们会优先对客户A推荐商品X,然后再推荐商品Y。
大数据下的个性化推荐
推荐系统,或者称为个性化推荐系统,是建立在数据挖掘基础上的一套系统,以为顾客购物提供完全个性化的决策支持和信息服务为目的。几乎所有的海外大型电子商务网站,包括亚马逊和eBay,都不同程度地使用了各种形式的推荐系统。
我们来看一个基于协同过滤规则的推荐系统实施案例。
如左下表所示,Chris、Jenny、Mark和Peter等都是系统中的用户,而商品A、B、C等都是用户购买过的商品,打钩表示对应的用户购买了对应的商品。
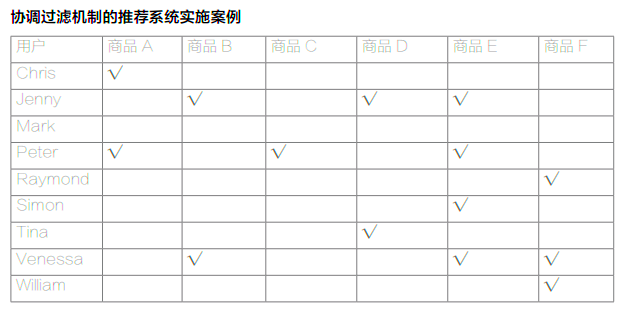
我们先来看基于用户的推荐。假设通过推荐系统,我们发现Chris和Peter两位用户的相似度是非常高的,其中Peter已经购买了商品A、C、E,而和他很“相似”的Chris只买了商品A,推荐系统就会把商品C和E推荐给Chris。
我们再来看基于项目的推荐。假设通过推荐系统,我们发现商品B和商品D是“相似”的。在系统的众多用户中,Jenny购买了商品B和D,Tina购买了商品D,而Venessa购买了商品B。我们的推荐系统根据商品B和D的相似规则,会把商品B推荐给Tina,并把商品D推荐给Venessa。
在协同过滤推荐系统中,一个需要考虑的因素是被推荐的商品X 和商品Y 本身的购买频率。如果在全部的用户中有10%的客户都购买了商品X,而只有1%的客户购买了商品Y,那么这时我们可能应该推荐的商品是Y而不是X。我们可以在排序的时候加上一个系数,而这个系数的数值是和该商品整体的热度成反比的。因为商品X在全部客户中被购买的比例是商品Y的10倍,而在和客户A“相似”的人群中被购买的比例只多了10%,那么我们在排序时需要把Y排在X的前面。
需要补充的是, 协同过滤推荐系统是依赖于大量数据的。如果数据量不够充分,推荐的结果可能会令人啼笑皆非。在新用户、新项目或者整个系统是全新开始的情况下,个性化推荐引擎是无法工作的。
本文链接《 个性化推荐背后的生成机制》
官方微信:woshipm,干货天天推荐,欢迎订阅
