linux 下如何抓取HTTP流量包
- - 运维生存时间基于某些原因你需要嗅探HTTP Web流量(即HTTP请求和响应). 例如,你可能会测试Web服务器的性能,或者x奥uy调试Web应用程序或RESTful服务 ,又或者试图解决PAC(代理自动配置)问题,或检查从网站上下载的任何恶意文件. 甭管是什么原因,对于系统管理员,开发人员,甚至是最终用户,嗅探HTTP流量是非常有帮助的.
$ sudo apt-get install gcc make git libpcap0.8-dev $ git clone https://github.com/jbittel/httpry.git $ cd httpry $ make $ sudo make installFedora、centos、RHEL系统需要安装EPEL源
$ sudo yum install httpry也可以源码编译
$ sudo yum install gcc make git libpcap-devel $ git clone https://github.com/jbittel/httpry.git $ cd httpry $ make $ sudo make install
$ sudo httpry -i <network-interface>httpry监听在指定的网卡下,实时捕获并显示HTTP请求与响应的包
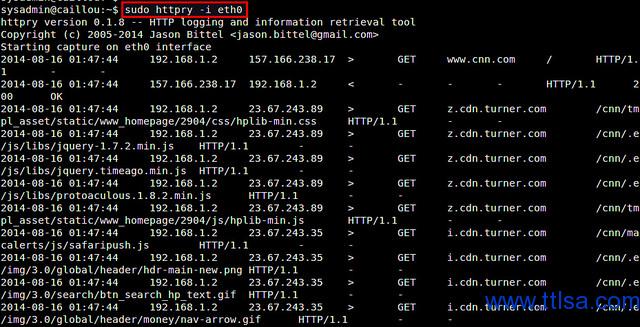 在大多数情况下,输出滚动非常快的,需要保存捕获的HTTP数据包进行离线分析。可以使用-b或-o选项。“-b”选项将原始的HTTP数据包保存到一个二进制文件,然后可以用httpry进行重播。 “-o”选项保存可读的输出到文本文件。
保存到二进制文件中:
在大多数情况下,输出滚动非常快的,需要保存捕获的HTTP数据包进行离线分析。可以使用-b或-o选项。“-b”选项将原始的HTTP数据包保存到一个二进制文件,然后可以用httpry进行重播。 “-o”选项保存可读的输出到文本文件。
保存到二进制文件中:
$ sudo httpry -i eth0 -b output.dump重放:
$ httpry -r output.dump保存到文本文件:
$ sudo httpry -i eth0 -o output.txt
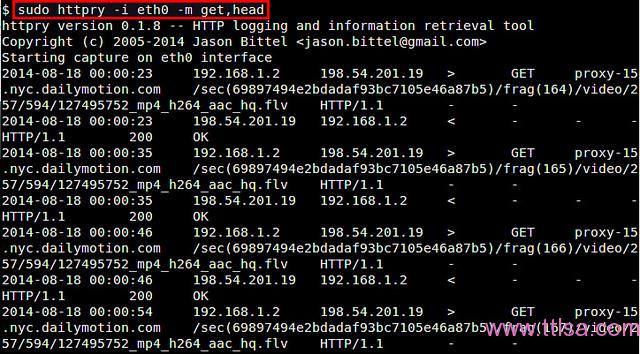
$ sudo httpry -i eth0 -m get,head
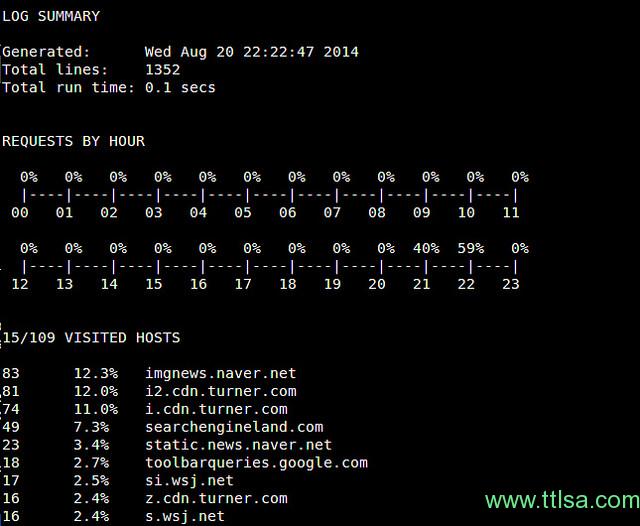
 如果你下载httpry源码,在源码目录下,有一个perl脚本来帮助我们分析httpry输出。该脚本在httpry/scripts/plugins目录下。 如果你想编写一个httpry输出的定制解析器,这些脚本是个很好的例子。功能有:
如果你下载httpry源码,在源码目录下,有一个perl脚本来帮助我们分析httpry输出。该脚本在httpry/scripts/plugins目录下。 如果你想编写一个httpry输出的定制解析器,这些脚本是个很好的例子。功能有:
$ cd httpry/scripts $ perl parse_log.pl -d ./plugins <httpry-output-file>parse_log.pl执行完后,会在httpry/scripts目录下生成一些分析结果文件(*.txt/xml)。例如,log_summary.txt看起来像下面这样: