[MySQL优化案例]系列 — 分页优化
- - 学习笔记通常,我们会采用ORDER BY LIMIT start, offset 的方式来进行分页查询. 或者像下面这个不带任何条件的分页SQL:. 一般而言,分页SQL的耗时随着 start 值的增加而急剧增加,我们来看下面这2个不同起始值的分页SQL执行耗时:. 可以看到,随着分页数量的增加,SQL查询耗时也有数十倍增加,显然不科学.
备注:插图来自网络搜索,如果觉得不当还请及时告知 :)
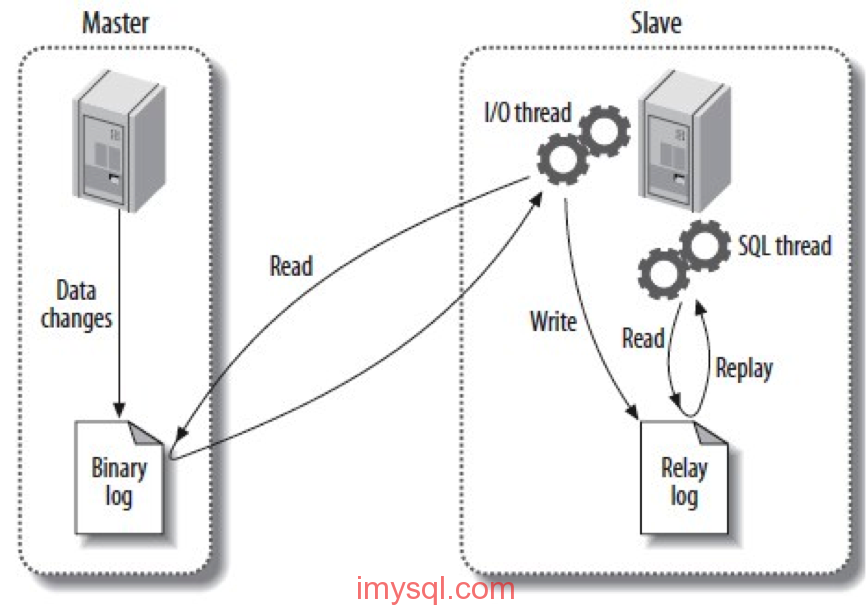
一般而言,slave相对master延迟较大,其根本原因就是slave上的复制线程没办法真正做到并发。简单说,在master上是并发模式(以InnoDB引擎为主)完成事务提交的,而在slave上,复制线程只有一个sql thread用于binlog的apply,所以难怪slave在高并发时会远落后master。
ORACLE MySQL 5.6版本开始支持多线程复制,配置选项 slave_parallel_workers 即可实现在slave上多线程并发复制。不过,它只能支持一个实例下多个 database 间的并发复制,并不能真正做到多表并发复制。因此在较大并发负载时,slave还是没有办法及时追上master,需要想办法进行优化。
另一个重要原因是,传统的MySQL复制是异步(asynchronous)的,也就是说在master提交完后,才在slave上再应用一遍,并不是真正意义上的同步。哪怕是后来的Semi-sync Repication(半同步复制),也不是真同步,因为它只保证事务传送到slave,但没要求等到确认事务提交成功。既然是异步,那肯定多少会有延迟。因此,严格意义上讲,MySQL复制不能叫做MySQL同步(处女座的面试官有可能会在面试时把说成MySQL同步的一律刷掉哦)。
另外,不少人的观念里,slave相对没那么重要,因此就不会提供和master相同配置级别的服务器。有的甚至不但使用更差的服务器,而且还在上面跑多实例。
综合这两个主要原因,slave想要尽可能及时跟上master的进度,可以尝试采用以下几种方法:
其他更多方法,欢迎大家帮忙补充 :)