基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
- - zzm网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项. 由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎,用来对网络爬虫抓取到的网络资源进行实时的索引和搜索. 搜 索引擎架构在ElasticSearch之上,是一个典型的分布式在线实时交互查询架构,无单点故障,高伸缩、高可用.
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项。由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎,用来对网络爬虫抓取到的网络资源进行实时的索引和搜索。
搜 索引擎架构在ElasticSearch之上,是一个典型的分布式在线实时交互查询架构,无单点故障,高伸缩、高可用。对大量信息的索引与搜索都可以在近 乎实时的情况下完成,能够快速实时搜索数十亿的文件以及PB级的数据,同时提供了全方面的选项,可以对该引擎的几乎每个方面进行定制。支持RESTful 的API,可以使用JSON通过HTTP调用它的各种功能,包括搜索、分析与监控。此外,还为Java、PHP、Perl、Python以及Ruby等各 种语言提供了原生的客户端类库。
网络爬虫通过将抓取到的数据进行结构化提取之后提交给搜索引擎进行索引,以供查询分析使用。由于搜索引擎的设计目标在于近乎实时的复杂的交互式查询,所以搜索引擎并不保存索引网页的原始内容,因此,需要一个近乎实时的分布式数据库来存储网页的原始内容。
分布式数据库架构在Hbase+Hadoop之上,是一个典型的分布式在线实时随机读写架构。极强的水平伸缩性,支持数十亿的行和数百万的列,能够对网络爬虫提交的数据进行实时写入,并能配合搜索引擎,根据搜索结果实时获取数据。
网 络爬虫、分布式数据库、搜索引擎均运行在普通商业硬件构成的集群上。集群采用分布式架构,能扩展到成千上万台机器,具有容错机制,部分机器节点发生故障不 会造成数据丢失也不会导致计算任务失败。不但高可用,当节点发生故障时能迅速进行故障转移,而且高伸缩,只需要简单地增加机器就能水平线性伸缩、提升数据 存储容量和计算速度。
网络爬虫、分布式数据库、搜索引擎之间的关系:
1、网络爬虫将抓取到的HTML页面解析完成之后,把解析出的数据加入缓冲区队列,由其他两个线程负责处理数据,一个线程负责将数据保存到分布式数据库,一个线程负责将数据提交到搜索引擎进行索引。
2、搜索引擎处理用户的搜索条件,并将搜索结果返回给用户,如果用户查看网页快照,则从分布式数据库中获取网页的原始内容。
整体架构如下图所示:
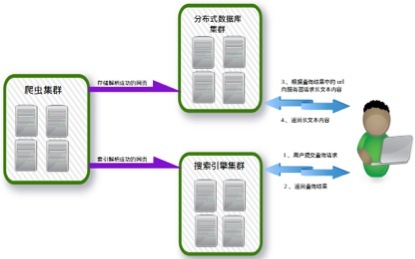
爬虫集群、分布式数据库集群、搜索引擎集群在物理部署上,可以部署到同一个硬件集群上,也可以分开部署,形成1-3个硬件集群。
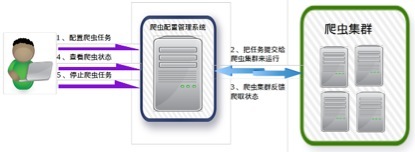
网络爬虫集群有一个专门的网络爬虫配置管理系统来负责爬虫的配置和管理,如下图所示:
搜 索引擎通过分片(shard)和副本(replica)实现了高性能、高伸缩和高可用。分片技术为大规模并行索引和搜索提供了支持,极大地提高了索引和搜 索的性能,极大地提高了水平扩展能力;副本技术为数据提供冗余,部分机器故障不影响系统的正常使用,保证了系统的持续高可用。
有2个分片和3份副本的索引结构如下所示:
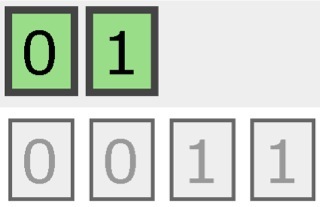
一个完整的索引被切分为0和1两个独立部分,每一部分都有2个副本,即下面的灰色部分。
在 生产环境中,随着数据规模的增大,只需简单地增加硬件机器节点即可,搜索引擎会自动地调整分片数以适应硬件的增加,当部分节点退役的时候,搜索引擎也会自 动调整分片数以适应硬件的减少,同时可以根据硬件的可靠性水平及存储容量的变化随时更改副本数,这一切都是动态的,不需要重启集群,这也是高可用的重要保 障。