Rsync同步使用
- - 开源软件 - ITeye博客rsync是类unix系统下的数据镜像备份工具——remote sync. /etc/rsyncd/rsyncd.conf 是你刚才编辑的rsyncd.conf的位置. 也可以在/etc/rc.d/rc.local里加入让系统自动启动等. rsync -参数 用户名@同步服务器的IP::rsyncd.conf中那个方括号里的内容 本地存放路径 如:.
犀牛云盘是美团点评内部一个基于美团云的文件协作平台,核心是文件的结构化云存储以及上传和下载的体验优化。文件同步是云盘功能的重要部分(包括文件内容的同步和文件增删的同步,应该有上传、下载、创建、删除等动作,但在本文的叙述中,主要关注文件内容的传输,即上传、下载),如何快速高效地进行文件同步,就成了云盘亟需解决的技术难题。本文阐述的方案就是在这种场景下提出来的,我们希望通过rsync增量传输算法,来提高文件同步速度。但原始rsync算法在高并发的服务上会存在性能问题,所以本方案也借鉴zsync的思路,做了优化。
rsync增量传输算法首度发表于1996年6月19日,原始作者为Andrew Tridgell与Paul Mackerras [1]。实现增量传输的主要过程,就是差异检测和差异数据组织及传输,前者是rsync增量传输算法的核心。
rsync增量传输算法是一种滑动块差异检测算法。以检测文件A和B的差异为例,首先对A按固定长度L划分为若干块,并对每一块生成弱摘要(Adler-32:速度快)和强摘要(MD5:鉴别度高),然后对B从第一个字节开始,以长度为L的滑动窗口,遍历整个文件,计算每个窗口块的弱、强摘要,并与A中的摘要值进行比较,弱、强摘要都相同者,即视为相同数据块,否即为差异块。如下图所示:
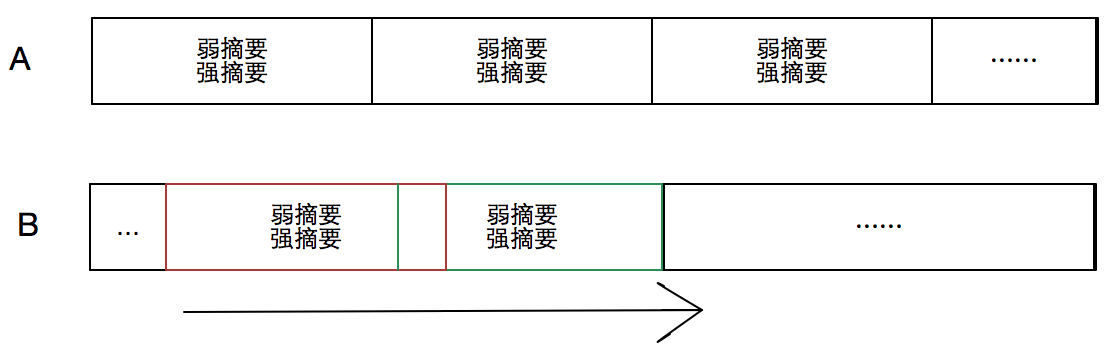
rsync增量传输算法主要有两个特点:
酷壳网有篇文章对rsync增量传输算法有比较详细的介绍[2]。
rsync性能优秀且简单容易理解,作者用了两年研究出来,而使用者只用两小时就可以理解了。
rsync增量传输算法使用最多的场景就是类UNIX系统上的rsync同步工具。该工具非常流行,被应用于大量的文件传输场景。比如现在美团点评发布系统就用rsync同步发布机器上编译后文件到生产机器上的。
rsync工具的工作机制,如下阐述。
目标:主机A、B,A要同步文件F-new给B,B上已有文件F-old,跟F-new相似度高。
步骤:
如果目标是B要同步文件给A,那就是步骤中把A、B换一下位置。
小结:同步的双方A、B基本是对等的,一方计算sign和合并文件,一方计算delta。 双方都有较大计算量,这在一个服务器多客户端场景下,服务端压力会过大。
zsync是Ubuntu上使用比较多的工具,主要用于分发Ubuntu的安装镜像ISO文件。zsync是rsync的一种变体,对rsync增量传输算法有所改造,并且基于HTTP协议,适合广域网应用[3]。
zsync适用的场景是:大文件、变动少、一个分发点(服务端)、大量下载(客户端)。
使用步骤为:
zsync算法,使发布方(服务端)只要一次签名文件的计算即可支撑大量客户端增量下载,缓解服务端压力。需要增加的签名文件存储空间,也是成本很低的。
基于上面介绍的rsync工具的传输步骤,并借鉴zsync增量下载的思路,制定云盘文件增量同步方案,如下图所示:
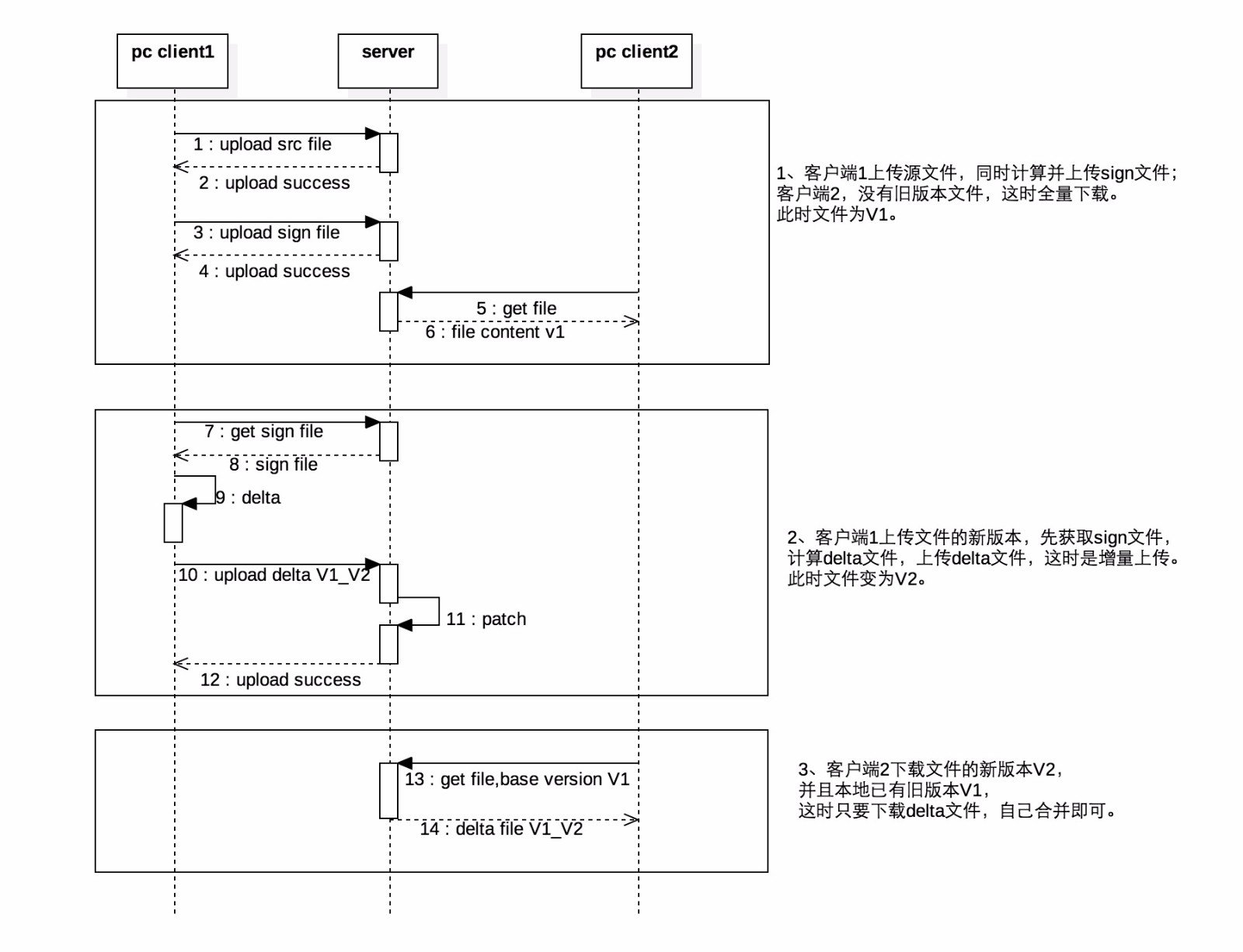
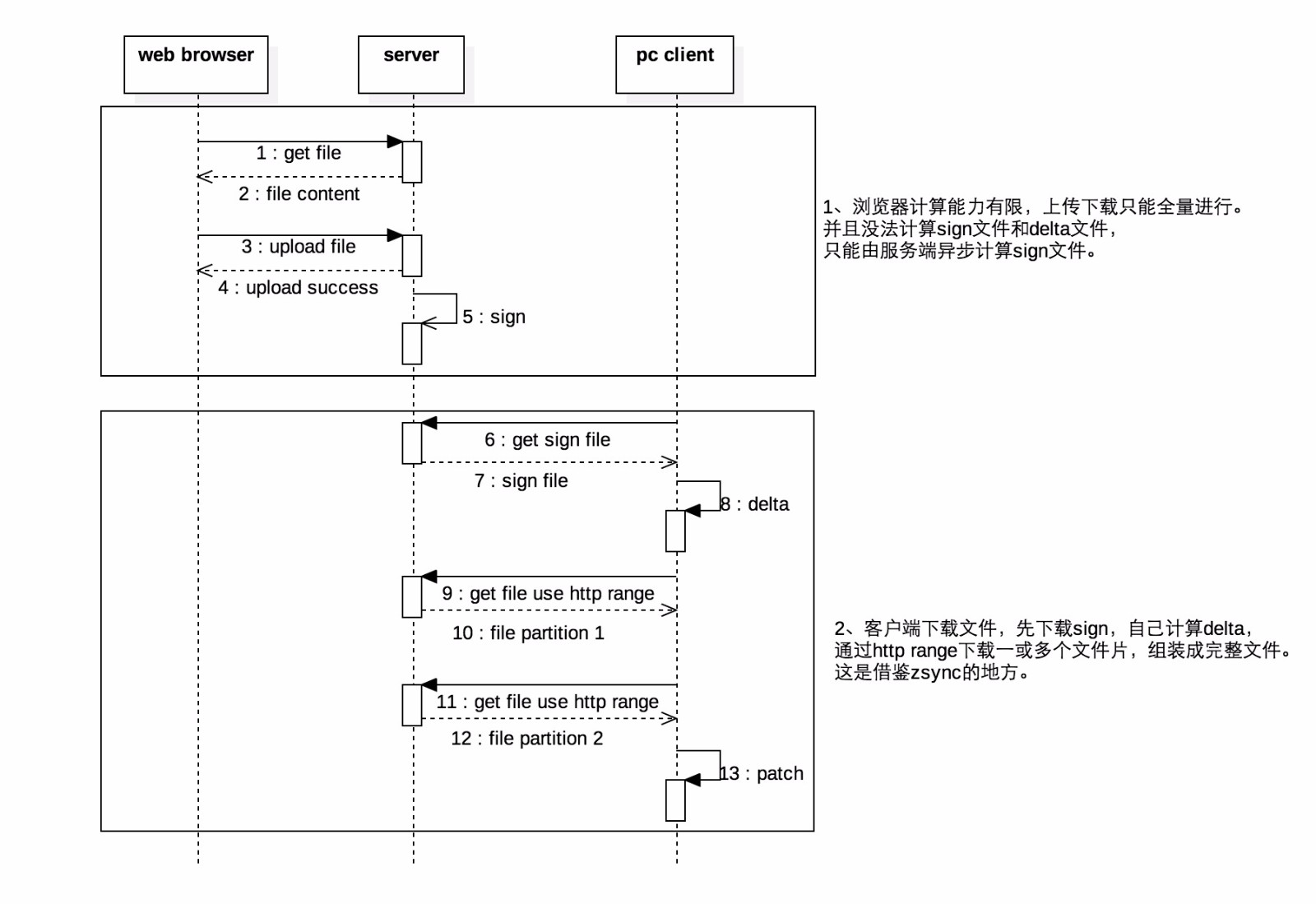
主要的方案设计要点是:
碎片块,这是rsync增量传输算法特点造成的,由于是滑动窗口检测,在两个相同块之间,有可能存在一个长度不定的差异块。如果相同块不连续,就会形成一系列碎片块。减少滑动块长度(也即是sign计算的固定块长度),可以提高命中率、减少碎片块,但计算量也随着加大,sign文件也变大,可能得不偿失。所以只能根据试验情况,取一个折衷的块长度。目前我们采取默认2KB的块长度,对每块生成4B弱摘要,16B强摘要,那么sign文件与源文件的长度比=20/2K=1/100(这里忽略sign文件头固定8B的小量影响)。
对JPEG、视频等类型的文件,局部改变可能性小,且文件一般比较大,差异检测计算量大但命中率低,不进行增量同步尝试。
基于以上设计方案,服务器端要做合并patch操作,但合并操作的时间和资源消耗还是挺大的,需要做:
该问题可从以下两方面做优化尝试:
第一,rsync工具及类库中为了做到极致的最小传输量,sign文件头没有保存源文件长度,delta文件块长度用不同数量的Byte来表示。建议修改。前者保存文件长度,方便做类似zsync的改造(zsync算法起作用需要整个文件长度)和下载时的长度校验;后者用固定数量Byte表示长度(每个长度值都要使用多个Byte),虽然多消耗一些传输量,但编码简单,处理效率高。
第二,对某些文件格式已知的文件,可以根据格式特点,做变长分块。比如MS Office的Open XML格式,其实是Zip组织方式,可以按Zip协议的分界标识来分块,提高命中率,但这需要对rsync增量传输算法进行修改。
第三,结合CDC(content-defined chunking)做变长分块检测,这方面属于研究的方向,但目前还没有比较通用可靠的解决方案。下面根据找到的资料做一下描述:
CDC算法是一种变长分块算法,它应用数据指纹(如Rabin指纹[5])将文件分割成长度大小不等的分块策略。与定长分块算法不同,它是基于文件内容进行数据块切分的,因此数据块大小是可变化的。算法执行过程中,CDC使用一个固定大小(如48字节)的滑动窗口对文件数据计算数据指纹。如果指纹满足某个条件,如当它的值模特定的整数等于预先设定的数时,则把窗口位置作为块的边界。
CDC算法可能会出现病态现象,即指纹条件不能满足、块边界不能确定,导致数据块过大。实现中可以对数据块的大小进行限定,通过设定上下限来解决这种问题。CDC算法对文件内容变化不敏感,插入或删除数据只会影响到较少的数据块,其余数据块不受影响。CDC算法也有缺陷,数据块大小的确定比较困难,粒度太细则开销太大,粒度过粗则检测效果不佳。如何两者之间权衡折衷,这是一个难点。
相比CDC,rsync是滑动块算法。滑动块算法对插入和删除问题处理非常高效,并且能够检测到比CDC更多的冗余数据,它的不足是容易产生数据碎片。如果能结合两者的优点,那就能更高效做差异检测,比如上面提到的Open XML格式按Zip标记分界的思路,其实是CDC思路的一个特例。