翻译《The rsync algorithm》
- AWard - CSDN博客推荐文章 最近在学习Rsync工具,在对Rsync算法大加赞赏之余,决定将《The rsync algorithm 》翻译,有不正之处 还请指正. 安德鲁Tridgell 保罗马克拉斯 部计算机科学 澳大利亚国立大学 堪培拉,ACT 0200,澳大利亚. 本报告介绍了将一台计算机上的文件内容同步到另一台机器上的文件的算法(同步后保证文件内容需要一致).
最近在学习Rsync工具,在对Rsync算法大加赞赏之余,决定将《The rsync algorithm 》翻译,有不正之处 还请指正。转载请注明出处。
rsync算法
安德鲁Tridgell 保罗马克拉斯 部计算机科学 澳大利亚国立大学 堪培拉,ACT 0200,澳大利亚
摘要:
本报告介绍了将一台计算机上的文件内容同步到另一台机器上的文件的算法(同步后保证文件内容需要一致)。我们认为这两台机器是通过低带宽,高延迟的双向通信链路设备连接的。该算法会先找出源文件和目标文件中相同的那些部分,并只将那些该算法认为不相同的数据同步过去。实际上,这个算法会计算两个文件差异之处,而且这两个文件不需要在同一台机器上。该算法的适用场景最好是同步的文件内容是相似的,不会有非常大的差异的,但是即便是那些同步前后差异非常大的文件,该算法也能很好的完成同步工作,而且同步效率相对而言也是比较好的。
本文大纲:
问题
想象一下,你有两个文件,A和B,你想将B的内容更新到和A一样。明显最简单的的方法是将A复制到B。
好,现在再想象一下,这两个文件之间通过一个缓慢的通信链路传输,例如,一个拨号的ip路由器 。如果A文件很大,那么将其复制到B的过程将是缓慢的。如果想使其速度更快,在发送文件之前,你可以先将文件压缩再发送,但是通常这样的处理方案只能提高2~4倍的效率。可见,传统的数据同步方案是不太适合大数据量,分布式,网络状况无法确定的场景。
换个思路,假设A 和 B文件的内容 是非常相似,也许他们来自于某个相同的原始文件。要真正加快同步的速度,就需要将文件的这种相似性的优势利用起来。常见的方法是发送A 和 B 之间的差异并记录列表,然后使用这个差异列表,重建B文件内容。
但是,按照普通的方法,要生成两个文件之间的差异,就必须要保证首先能够读取这两个文件。因此,这种情况下如果不能保证两个文件都同时在同一台计算机上,这些算法就不能使用起来(一旦你的文件复制过来,你就不需要的差异)。这是rsync的由来。
rsync算法能够有效地计算源文件和目标文件中匹配的内容(相同),这些相同的内容不需要在链路上发送,我们所需要同步的只是那些和目标文件内容不同的部分。这种方式是只有部分不匹配的源文件内容需要逐字发送,然后接收端可以使用现有目标文件的各个部分和源文件中需要同步的内容构造出最后的文件。
当然为了能够进一步的改善速度,发送端的数据可以先使用任何一个常见的压缩算法压缩厚再传输。
rsync算法
假设我们有两个通用计算机 和。电脑可以访问A文件,电脑可以访问B 文件,其中A 和 B文件内容“相似”,并且我们假设在和之间有一个缓慢的网络链接通路。
那么,rsync算法包括以下步骤:
1机器上rsync将文件 B分割成一系列不重叠的固定大小的块,假设块大小为S字节。该文件的最后一个块可能会小于S个字节。
2 对于每个块机器会计算两个校验和:一个弱“滚动”的32位校验(见下文)和一个强大的128位的MD4校验。
3 机器发送这些校验和给机器。
4 机器通过搜索所有block(从第一个偏移开始,遍历所有为S大小的block),找到所有和B文件有相同的薄弱/ 强大的校验和的block。这是可以通过下面描述的滚动校验的特殊属性非常快速做到的。
5机器给机器发送一个指令序列,用于构建B的一个副本。每个指令要么是B文件中某个block的引用要么是数据内容,这些数据内容都是前面匹配出来的那些A与B不同block的数据;此外还需要发送block的校验和以及索引信息
该算法也只需要一个链路的往返,最大限度地减少链路延迟的影响 。
该算法的最重要的细节是滚动校验和 以及关联的多备用搜索机制,它能保证偏移校验搜索过程非常迅速地进行。这些将在下文作更详细的讨论。
滚动校验
在rsync算法中使用的弱滚动校验和 算法需要具备这样的特性:根据X 1 ... X n的校验和和 X1到Xn的字节流值 可以很简单快速的计算X2 .. Xn+1 的校验和
我们在我们实现的弱校验和算法来自于Mark Adler的Adler - 32校验算法。校验算法公式如下:
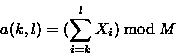
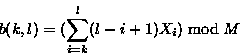
s(K , L ) =(K , L )+ 2 16 b ( K , 1 )
其中 s (K , L )就是字节的滚动校验和 。为了简单速度的计算出结果,我们一般设置 M = 2 16。
此校验算法的重要特性是非常有效地利用了递推关系,可以计算连续值
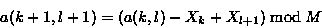
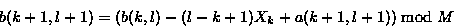
因此可以使用很少的计算就能达到从文件的任意一个位置开始 就能计算校验长度为S的 块的滚动校验和 。
尽管上述算法看起来看非常简单,但是这个校验值却已经足够用于两个文件块内容的第一级匹配。我们在实践中发现,块内容不同校验和相等的概率是相当低的。这是很重要的,因为那些弱校验和相同的不一定内容相同的块还需要经过非常耗费资源的强校验和算法计算用于识别文件内容是否真的一样。
校验和搜索
机器一旦收到B文件的块内容的校验和列表,它就开始从A文件中任何一个位置开始寻找那些校验和与B中块校验和相等的block。基本策略是从第一个字节开始,依次计算长度为S字节的块的32位滚动校验和,对于B的每个校验和,搜索A中匹配的列表 。要做到这一点我们的实现中使用一个简单的3级搜索计划。
第一级使用了32位滚动校验和16位的哈希和一个2 16项的哈希表。校验值的列表(即块的校验乙)是根据32位滚动校验的16位哈希值进行排序的 。哈希表中的每一项指向的是拥有相同hash值的校验和列表的第一个元素。
也就是说,从A文件的每一个偏移量开始,所有的32位滚动校验和和起对应的16位hash值都要计算一次。只要该哈希值的哈希表项是不是空值,第二个层次检查被调用。
第二个层次的检查扫描排序过的校验和列表条目。扫描过程会检查整个hash表中那些与当前block校验和相同的一项。如果这个搜索找到一个匹配,第三个层次检查被调用。
第三个层次检查需要计算从当前位置开始的block的强校验和,然后将起和前面的hash列表中的条目比较强校验和。如果这两个强校验和相匹配,我们就认为阿u,我们已经找到了A中一个匹配了B文件的块 。事实上块内容还是有可能不同,但这个概率是微观的,并在实践中这是一个合理的假设 。
当找到一个匹配, 会给 发送A文件中当前文件位置和上一次匹配位置之间的数据内容,这个内容还会前面加上B文件中block的索引信息 。该数据会立即发送,这使得我们可以保证计算与通信重叠进行。
如果某个位置开始没有找到匹配,就会前进一个位置继续搜索匹配的块。如果找到一个匹配,搜索匹配块的工作会从当前匹配块重新启动 。当这两个文件几乎是相同的,这种策略可以节省大量计算。
流水线
以上各节描述了在远程系统上构建一个文件的副本的过程。如果我们有几个文件复制,我们可以通过流水线的过程得到一个相当大的延迟优势。
这需要 启动两个独立的进程,其中一个进程生成和发送的校验和给 ,另外一个进程负责收取来自的差异信息 和重建文件工作。
如果通信链路是缓冲的,那么这两个过程可以独立进行,并保证了在大部分时间两个方向都能充分利用链接。
结果
为了测试算法,创建了一堆tar文件,放在了两个版本的Linux内核上测试,两个内核版本为1.99.10和2.0.0。这些tar文件大小约为24MB/
在1.99.10版本的2441文件,291文件的改变,在2.0.0版本19的文件已被删除,并已加入25个档案。
``差异:使用标准的GNU diff工具生产超过3200万线输出共计2.1 MB的文件。
下表显示了不同的块大小rsync的两 个文件之间的的结果 。
|
块大小 |
匹配 |
标签命中 |
假报警 |
数据 |
写入 |
读出 |
|
|
|
|
|
|
|
|
|
300 |
64247 |
3817434 |
948 |
5312200 |
5629158 |
1632284 |
|
500 |
46989 |
620013 |
64 |
1091900 |
1283906 |
979384 |
|
700 |
33255 |
571970 |
22 |
1307800 |
1444346 |
699564 |
|
900 |
25686 |
525058 |
24 |
1469500 |
1575438 |
544124 |
|
1100 |
20848 |
496844 |
21 |
1654500 |
1740838 |
445204 |
在表中的列如下:
块的大小
校验块的字节大小。
匹配
A中找到的那些与A相同的block个数
标签命中
A中滚动校验和的16位hash值匹配B中校验和hash值的个数
误报警
32位滚动校验和相匹配的次数,但没有强校验。
数据
文件中的传输数据量,以字节为单位。
写入
a写如的字节数,几乎是所有的文件内容
读出
通过读取的字节 总数,包括协议开销。这是几乎所有的校验和信息。
结果表明,超过300字节的块大小,只有一小部分(约5%)的文件被转移。转让的数量也大大超过少于diff文件的大小
校验和本身也占用了一定的空间,虽然比普通情况下传输的数据量少很多。每队校验和消耗20个字节:4个字节为滚动校验加上16字节128位的MD4校验。
假警报的数量小于1 / 1000,在筛选出虚假匹配的过程中32位滚动校验是相当不错,
标签命中数表示校验和搜索算法的第二个层次是调用大约每隔50个字符。这是相当高的,因为文件中的块的总数,标签哈希表的大小是一个很大比例。对于较小的文件,我们希望标签的命中率更接近匹配的数量。对于非常大的文件,我们也许应该增加哈希表的大小。
下表显示了类似的结果小得多的文件设置。在这种情况下,文件没有被打包成一个tar文件。相反,rsync的调用选项递归下降的目录树。从另一个称为Samba软件包的两个版本源文件中使用。总的源代码大小为1.7 MB,两个版本之间的差异是4155线长共120 KB。
|
块大小 |
匹配 |
标签命中 |
假报警 |
数据 |
写入 |
读出 |
|
|
|
|
|
|
|
|
|
300 |
3727 |
3899 |
0 |
129775 |
153999 |
83948 |
|
500 |
2158 |
2325 |
0 |
171574 |
189330 |
50908 |
|
700 |
1517 |
1649 |
0 |
195024 |
210144 |
36828 |
|
900 |
1156 |
1281 |
0 |
222847 |
236471 |
29048 |
|
1100 |
921 |
1049 |
0 |
250073 |
262725 |
23988 |
可用性
已写入一个rsync的实施提供了一个方便的界面,类似常用的UNIX命令RCP是从ftp://rsync.samba.org/pub/rsync下载。
关于这份文件... ...
rsync算法
这份文件是使用 LaTeX2HTML 发布版本98.1p1生成的(1998年3月2日 )
版权所有© 1993年,1994年,1995年,1996年,1997年, 尼科斯Drakos,基于计算机的学习单位,利兹大学。
命令行参数:latex2html tech_report.tex。
是由Andrew Tridgell 1998-11-09 发布