异常检测机制
- - 奇虎360-addops传统的异常检测系统通过设置一个固定的阈值来保证监控项处于正常水平,一旦超过设定的阈值,就会触发报警来提醒人们的注意. 静态阈值法适用于在一定范围内波动的监控项,比如磁盘使用率,CPU使用率等,但是如果遇到网络流量这种不具有明显上限,波动比较剧烈的情况,单纯利用静态阈值法如果设置的阈值比较小,会出现很多误报的情况,增加人工成本;而如果将阈值设置的比较大,又会出现漏报的情况.
传统的异常检测系统通过设置一个固定的阈值来保证监控项处于正常水平,一旦超过设定的阈值,就会触发报警来提醒人们的注意。
静态阈值法适用于在一定范围内波动的监控项,比如磁盘使用率,CPU使用率等,但是如果遇到网络流量这种不具有明显上限,波动比较剧烈的情况,单纯利用静态阈值法如果设置的阈值比较小,会出现很多误报的情况,增加人工成本;而如果将阈值设置的比较大,又会出现漏报的情况。
所以我们提出了一个应对复杂场景的异常检测算法,它不仅考虑同期数据的情况,也会将周期性纳入考虑范围,通过设置动态阈值的方法来对异常数据进行检测。
对于时间序列(是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列)来说,T时刻的数值对于T-1时刻有很强的依赖性。比如某个游乐园人数在8:00很多,在8:01时刻的人数很多的概率是很大的,但是如果07:01时刻人数对于8:01时刻影响不是很大。
针对最近时间窗口内的数据遵循某种趋势的现象,我们使用一条曲线对该趋势进行拟合,如果新的数据打破了这种趋势,使曲线变得不平滑,则该点就出现了异常。
曲线拟合的方法有很多,比如回归、moving average……。在这篇文章中,我们使用EWMA,即指数权重移动平均方法来拟合曲线。EWMA的递推公式是:
EWMA(1) = p(1) // 有时也会取前若干值的平均值。α越小时EWMA(1)的取值越重要。
EWMA(i) = α * p(i) + (1-α) * EWMA(i – 1) // α是一个0-1间的小数,称为smoothing factor.
可以从上面公式得出,下一点的平均值是由上一点的平均值,加上当前点的实际值修正而来。对于每一个EWMA值,每个数据的权重是不一样的,最近的数据将拥有越高的权重。
有了平均值之后,我们就可以使用3-sigma理论来判断新的input是否超过了容忍范围。比较实际的值是否超出了这个范围就可以知道是否可以告警了。超出了上界,可能是流量突然增加了;低于下界,可能是流量突然降低了,这两种情况都需要告警。
我们可以使用pandas库中的ewma函数来实现我们上面的计算过程,代码如下:
def EWMA(timeseries):
flag = ""
series = pandas.Series([x[1] for x in timeseries])
expAverage = pandas.stats.moments.ewma(series, com=50)
stdDev = pandas.stats.moments.ewmstd(series, com=50)
if abs(series.iget(-1) - expAverage.iget(-1)) > 3 * stdDev.iget(-1) and series.iget(-1) - expAverage.iget(-1) > 0:
flag = "突增"
if abs(series.iget(-1) - expAverage.iget(-1)) > 3 * stdDev.iget(-1) and series.iget(-1) - expAverage.iget(-1) > 0:
flag = "突减"
return flag
EWMA由于其时效性被广泛应用在时间序列的预测,它的优势在于:
而劣势则是
所以我们需要引入周期性的检测方法,来针对性处理具有周期性趋势的曲线。
很多监控项都具有一定的周期性,其中以一天为周期的情况比较常见,比如VIP流量在早上4点最低,而在晚上11点最高。为了将监控项的周期性考虑进去,我们选取了某个监控项过去14天的数据。对于某个时刻,将得到14个点可以作为参考值,我们记为xi,其中i=1,...,14。
我们先考虑静态阈值的方法来判断input是否异常(突增和突减)。如果input比过去14天同一时刻的最小值乘以一个阈值还小,就会认为该输入为异常点(突减);而如果input 比过去14天同一时刻的最大值乘以一个阈值还大,就会认为该输入为异常点(突增)。我们将上面的计算过程用代码来表示:
def simultaneous(data, min_threshold, max_threshold):
last_time = data.index[-1]
last_time = datetime.datetime.strptime(last_time, "%Y-%m-%d %H:%M:%S")
simultaneous_data =[]
for i in range(1, days_num+1):
before_time = last_time + datetime.timedelta(days=int("-%s" %i))
before_time_index = before_time.strftime("%Y-%m-%d %H:%M:%S")
if before_time_index in data.keys():
simultaneous_data.append(int(data[before_time_index]))
if int(data[-1]) < min(simultaneous_data) * min_threshold:
return "突降"
if int(data[-1]) > max(simultaneous_data) * max_threshold:
return "突增"
静态阈值的方法是根据历史经验得出的值,实际中如何给max_threshold和min_threshold是一个需要讨论的话题。根据目前动态阈值的经验规则来说,取平均值是一个比较好的思路。
上面我们把基于同期数据的检测方法进行了说明,下面我们讨论一下它的优缺点:
优点:
缺点:
检测方法二遇到下图的现象就不能检测出异常。比如今天是11.18日,过去14天的历史曲线必然会比今天的曲线低很多。那么今天出了一个小故障,曲线下跌了,相对于过去14天的曲线仍然是高很多的。这样的故障使用方法二就检测不出来,那么我们将如何改进我们的方法呢?一个直觉的说法是,两个曲线虽然不一样高,但是“长得差不多”。那么怎么利用这种“长得差不多”呢?那就是振幅了。
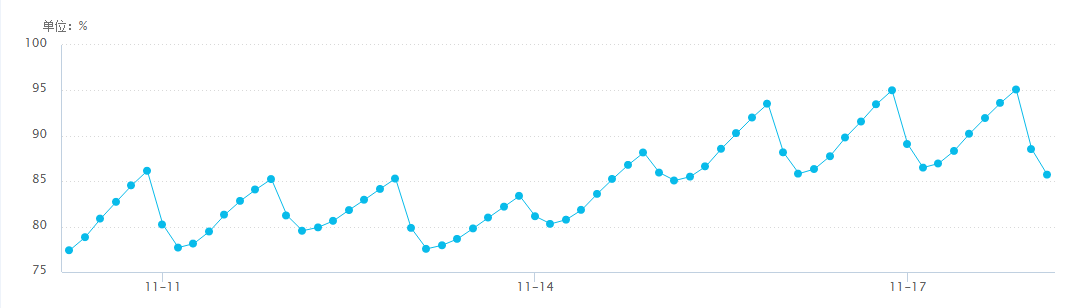
怎么计算t时刻的振幅呢? 我们使用x(t) – x(t-1) 再除以 x(t-1)来表示振幅。举个例子,例如t时刻的在线900人,t-1时刻的在线是1000人,那么可以计算出掉线人数是10%。如果参考过去14天的数据,我们会得到14个振幅值。使用14个振幅的绝对值作为标准,如果m时刻的振幅({m(t) – m(t-1)]/m(t-1))大于amplitude threshold并且m时刻的振幅大于0,则我们认为该时刻发生突增,而如果m时刻的振幅大于amplitudethreshold并且m时刻的振幅小于0,则认为该时刻发生突减。
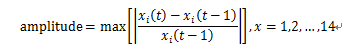
我们将上面的计算过程用一段代码表示:
def amplitude_max(data, threshold):
#最后一个值和倒数第二个值的振幅
last_amplitude = 0.0
last_time = data.index[-1]
last_time = datetime.datetime.strptime(last_time, "%Y-%m-%d %H:%M:%S")
last_amplitude_time = last_time + datetime.timedelta(minutes=int(-1))
last_amplitude_time_index = last_amplitude_time.strftime("%Y-%m-%d %H:%M:%S")
if last_amplitude_time_index in data.keys():
last_amplitude = float((float(data.values[-1])-float(data[last_amplitude_time_index]))/float(data.values[-1]))
last_time = last_time + datetime.timedelta(days=int(-1))
#同期的振幅
amplitude_data = []
for i in range(0, days_num):
now_time = last_time
prior_time = last_time + datetime.timedelta(minutes=int(-1))
prior_time_index = prior_time.strftime("%Y-%m-%d %H:%M:%S")
now_time_index = now_time.strftime("%Y-%m-%d %H:%M:%S")
if now_time_index in data.keys() and prior_time_index in data.keys():
tmp = float((float(data[now_time_index])-float(data[prior_time_index]))/float(data[now_time_index]))
amplitude_data.append(abs(round(tmp, 2)))
last_time = last_time + datetime.timedelta(days=int(-1))
if abs(last_amplitude) > max(amplitude_data) * threshold and last_amplitude > 0:
return "突增"
if abs(last_amplitude) > max(amplitude_data) * threshold and last_amplitude < 0:
return "突减"
同样,我们也讨论一下该方法的优缺点,先说优点:
缺点:
上面介绍了三种检测的方法,每个方法都有每个方法的优缺点,也有每个方法能检测和不能检测的范围。因此单纯依靠一种方法并不能达到我们预期的效果,而且具有很高的误报率。我们借鉴了投票制度中“少数服从多数”的原则,即三个方法中有两个或者两个以上符合,我们才认为符合。
如果你觉得上面的三种方法还不够精确,你甚至可以使用开源项目skyline来丰富你的算法库,进一步提高准确率。