抓取网页内容生成Kindle电子书
- - CodingLabs自从买了kindle后,总是想着如何最大效用发挥其效用. 虽然多看上有很多书可以购买,网上也有很多免费的电子书,但是仍然有很多感兴趣的内容是以网页的形式存在的. 例如 O’Reilly Atlas就提供了诸多电子书,但是只提供免费的在线阅读;另外还有很多资料或文档都只有网页形式. 于是就希望通过某种方法讲这些在线资料转为epub或mobi格式,以便在kindle上阅读.
自从买了kindle后,总是想着如何最大效用发挥其效用。虽然多看上有很多书可以购买,网上也有很多免费的电子书,但是仍然有很多感兴趣的内容是以网页的形式存在的。例如 O’Reilly Atlas就提供了诸多电子书,但是只提供免费的在线阅读;另外还有很多资料或文档都只有网页形式。于是就希望通过某种方法讲这些在线资料转为epub或mobi格式,以便在kindle上阅读。这篇文章介绍了如何借助calibre并编写少量代码来达到这个目的。
Calibre是一个免费的电子书管理工具,可以兼容Windows, OS X及Linux,令人欣喜的是,除了GUI外,calibre还提供了诸多命令行工具,其中的ebook-convert命令可以根据用户编写的recipes文件(实际是python代码)抓取指定页面内容并生成mobi等格式的电子书。通过编写recipes可以自定制抓取行为,以适应不同的网页结构。
Calibre的下载地址是 http://calibre-ebook.com/download,可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,还可以通过软件仓库安装:
Archlinux:
pacman -S calibre
Debian/Ubuntu:
apt-get install calibre
RedHat/Fedora/CentOS:
yum -y install calibre
注意,如果你使用OSX,需要单独安装 Command Line Tool。
下面以 Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
要抓取整本书,第一件事就是找到index页,这个页面一般是Table of Contents,也就是目录页,其中每个目录项链接到相应内容页。index页将会指导抓取哪些页面以及生成电子书时内容组织顺序。在这个例子中,index页面是 http://chimera.labs.oreilly.com/books/1230000000561/index.html。
Recipes是一个以recipe为扩展名的脚本,内容实际上是一段python代码,用来定义calibre抓取页面的范围和行为,下面是用于抓取Git Pocket Guide的recipes:
from calibre.web.feeds.recipes import BasicNewsRecipe
class Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }]
def get_title(self, link):
return link.contents[0].strip()
def parse_index(self):
soup = self.index_to_soup(self.url_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = []
for link in div.findAll('a'):
if '#' in link['href']:
continue
if not 'ch' in link['href']:
continue
til = self.get_title(link)
url = self.url_prefix + link['href']
a = { 'title': til, 'url': url }
articles.append(a)
ans = [('Git_Pocket_Guide', articles)]
return ans
下面分别解释代码中不同部分。
总体来看,一个recipes就是一个python class,只不过这个class必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
整个recipes的核心方法是parse_index,也是recipes唯一必须实现的方法。这个方法的目标是通过分析index页面的内容,返回一个稍显复杂的数据结构(稍后介绍),这个数据结构定义了整个电子书的内容及内容组织顺序。
在class的开始,定义了一些全局属性:
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }]
下面介绍parse_index需要通过分析index页面返回的数据结构。
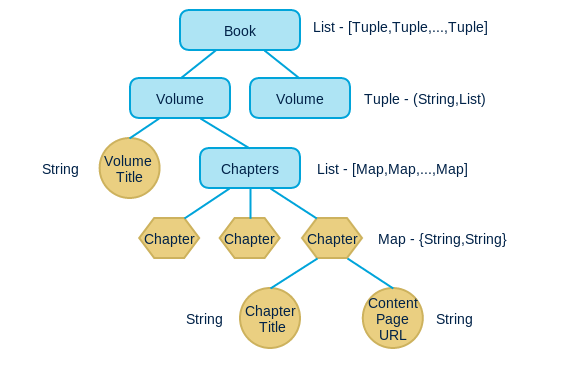
总体返回数据结构是一个list,其中每个元素是一个tuple,一个tuple表示一卷(volume)。在这个例子中只有一卷,所以list中只有一个tuple。
每个tuple有两个元素,第一个元素是卷名,第二个元素是一个list,list中每个元素是一个map,表示一章(chapter),map中有两个元素:title和url,title是章节标题,url是章节所在内容页的url。
Calibre会根据parse_index的返回结果抓取并组织整个书,并且会自行抓取并处理内容中外链的图片。
整个parse_index使用soup解析index页并生成上述数据结构。
上面是最基本的recipes,想了解更多的使用方法,可以参考 API文档。
编写好recipes后,在命令行下通过如下命令即可生成电子书:
ebook-convert Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi
即可生成mobi格式的电子书。ebook-convert会根据recipes代码自行抓取相关内容并组织结构。
下面是在kindle上看到的效果。
目录

内容一

内容二

含有图片的页
实际效果

我在github上建了一个 kindle-open-books,里面放了一些recipes,有我写的,也有其他同学贡献的。欢迎任何人贡献的recipes。