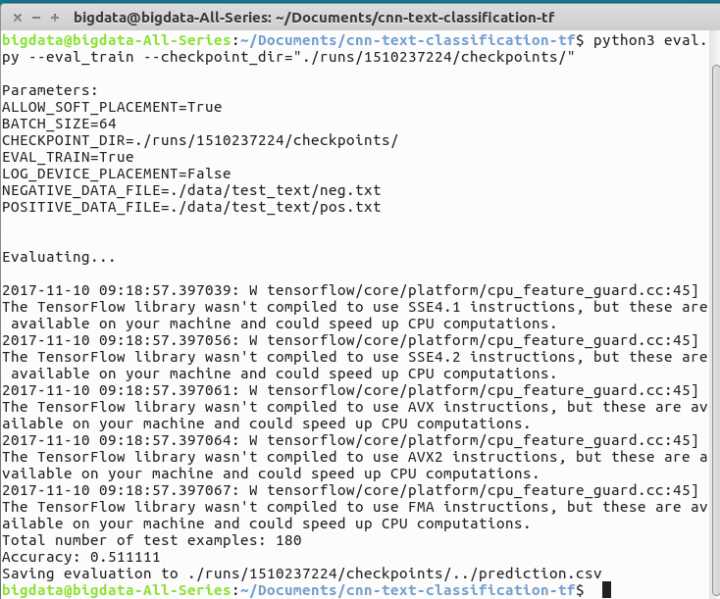
- - V2EX
从现在的结果来看,分词的版本( https://www.v2ex.com/t/404977#reply6 )准确率稍微高一点. 项目地址: https://github.com/fendouai/Chinese-Text-Classification. jieba 分词的版本在 master 分支,不分词的版本在 dev 分支.
- bin - One Piece of Programming
第一个版本实现了基于的MMSEG中文分词算法Python 实现. MMSEG实际上是一个正向最大匹配+多个规则的分词算法. 链接给出的几个网站写的很清楚了. 在开发过程中我增加了一个规则来处理原来的算法中有可能出现的冲突问题. 当所有的规则都无法唯一的确定一个chunk时,优先选择后面比较长的词. 开发过程中参照了MMSEG的Java实现和ruby实现.
- - 标点符
就是前面说的中文分词,这里需要介绍的是一个分词效果较好,使用起来像但方便的Python模块:结巴. 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG). 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合. 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法.
- Jimmy - 中文热文榜|最新
还有 bamboo, xiaoxie, Li, Ao, 推荐,查看全部 6 个推荐. 东方文化西方语发表于2010-08-08 08:04:45. 【我过去写过一篇博文说中国人说英语没有“口音”,因为各地中国人说英语五花八门没有规律,不像印度人或者其他国家的人说英语有特定的规律可循. 最近BBC播送了一个节目,专门谈中国人说英语的口音,转发供参考】.
- Interomeo - 60designwebpick
摄影师沈玮作品-Chinese Sentiment (中国情节). Chinese Sentiment (中国情节)is a personal journey for me to reconnect with the authentic Chinese life, both in the private and public space.
- -
EasyPR是一个开源的中文车牌识别系统,其目标是成为一个简单、高效、准确的非限制场景(unconstrained situation)下的车牌识别库. 相比于其他的车牌识别系统,EasyPR有如下特点:. 它基于openCV这个开源库. 这意味着你可以获取全部源代码,并且移植到opencv支持的所有平台.
- -
有关个人分析 / 仪表板,请参阅 . Content Management System 解决方案还具有存档和数字保存功能.. Access to Memory (AtoM) - 基于 Web 的开源应用程序,用于在多语言、多存储库环境中进行基于标准的档案描述和访问. Archivematica - 成熟的数字保存系统,旨在维护对数字对象集合的基于标准的长期访问.
- chuang - Initiative
dropbox定制优化CPython虚拟机,自己搞了个malloc调度算法. 那个 !!!111cos(0). 期待这次PyCon China 2011.
- - 企业架构 - ITeye博客
原文地址: http://blog.csdn.net/xuyuefei1988/article/details/19399137. 1、下面网上收罗的资料初学者应该够用了,但对比IBM的Python 代码调试技巧:. IBM:包括 pdb 模块、利用 PyDev 和 Eclipse 集成进行调试、PyCharm 以及 Debug 日志进行调试:.
- - 坚实的幻想
在构建 Web 应用时,通常会有 Web Server 和 Application Server 两种角色. 其中 Web Server 主要负责接受来自用户的请求,解析 HTTP 协议,并将请求转发给 Application Server,Application Server 主要负责处理用户的请求,并将处理的结果返回给 Web Server,最终 Web Server 将结果返回给用户.