分布式系统后台如何防止重复提交
- - ITeye博客分布式系统后台如何防止重复提交. 秒杀系统提交订单时,由于用户连续快速点击,并且前端没有针对性处理,导致连续发送两次请求,一次命中服务器A,另一次命中服务器B, 那么就生成了两个内容完全相同的订单,只是订单号不同而已.. 用户在界面看到两个一模一样的订单,不知道应该支付哪个;. 系统出现异常数据,影响正常的校验..
分布式系统后台如何防止重复提交
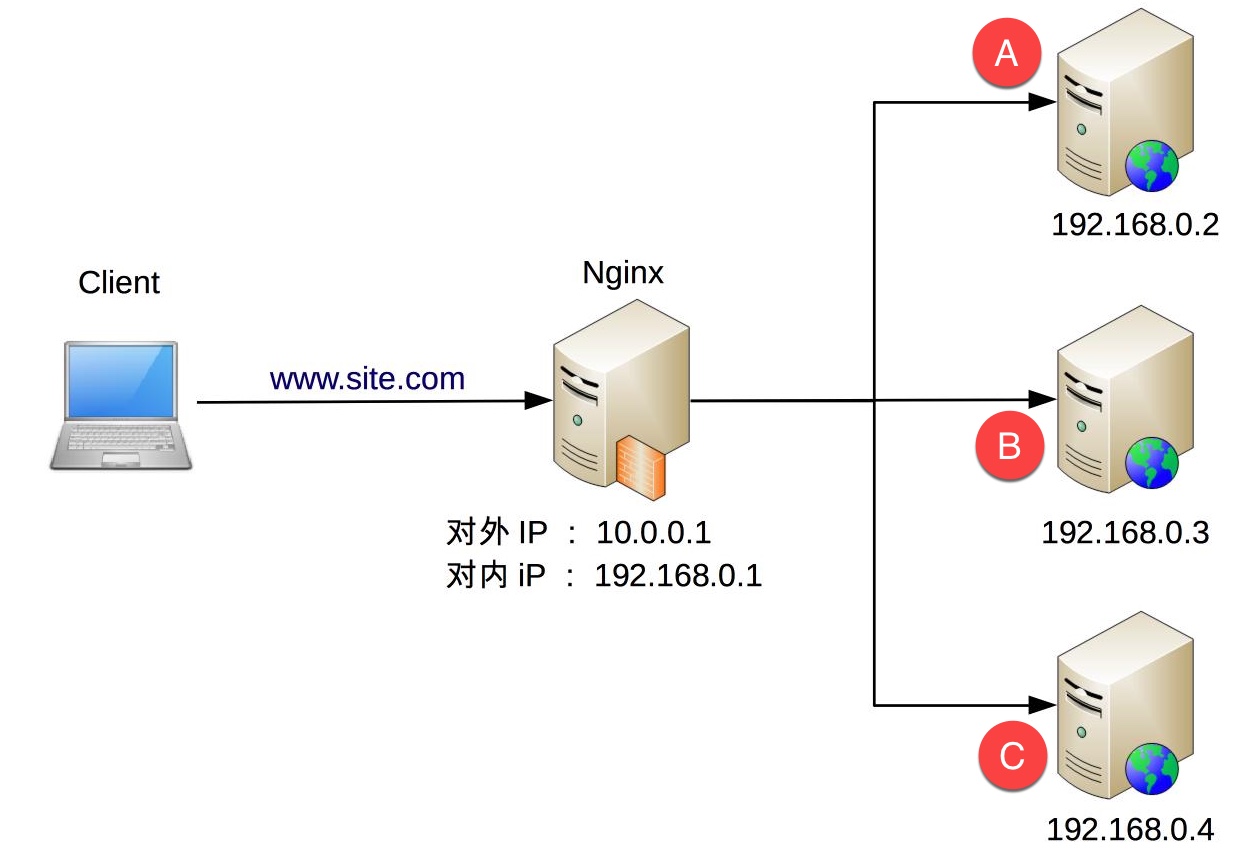
秒杀系统提交订单时,由于用户连续快速点击,并且前端没有针对性处理,导致连续发送两次请求,一次命中服务器A,另一次命中服务器B, 那么就生成了两个内容完全相同的订单,只是订单号不同而已.
解决思路:相同的请求在同一时间只能被处理一次.
如果是单体服务器,我们可以通过多线程并发的方式解决,但是目前大部分系统,采用了多机负载均衡.

实现思路: 对请求信息进行hash运算,得到一个hash值,
相同的请求信息得到相同的hash值(换成md5也可以) 步骤:
示例代码: 控制器中:
// 使用数据库约束条件,防止重复提交
try {
Integer userId = getCurrentId();
String hashSource = WebServletUtil.buildHashSource(request, userId);
reqOrderLock(hashSource, houseInfo.getId());
} catch (IOException e) {
e.printStackTrace();
}
Service中:
/***
* 利用数据库的唯一性约束<br />
* 防止重复提交
* @param queryString
*/
public void reqOrderLock(String queryString, Integer houseInfoId) {
long crc32Long = EncryptionUtil.getHash(queryString);
this.orderReqLockDao.addUnique(String.valueOf(crc32Long), houseInfoId, Constant2.Order_type_Label_VISIT_ORDER);
}
dao 中:
public OrderReqLock addUnique(String crc32, Integer houseInfoId, String orderTypeLabel) {
OrderReqLock orderReqLock = new OrderReqLock();
orderReqLock.setCrc32(crc32);
if (null != houseInfoId) {
orderReqLock.setHouseInfoId(houseInfoId);
}
orderReqLock.setOrderTypeLabel(orderTypeLabel);
CreateTimeDto createTimeDto = TimeHWUtil.getCreateTimeDao();
orderReqLock.setCreateTime(createTimeDto.getCreateTime());
orderReqLock.setUpdateTime(createTimeDto.getUpdateTime());
try {
add(orderReqLock);
} catch (org.hibernate.exception.ConstraintViolationException e) {
e.printStackTrace();
LogicExc.throwEx(Constant2.ERROR_CODE_Repeat_Operation, "您重复提交了订单,订单类型" );
}
return orderReqLock;
}
当然有个隐患: 在增加完锁,即执行addUnique 方法之后,程序挂了,不管是网络原因还是数据库崩溃, 当服务恢复之后,相同的请求无法提交了,因为数据库已经保存了请求的hash(但是实际上,后面的业务逻辑还没有来得及执行). 原因:锁操作addUnique 和业务逻辑肯定不在同一个数据库事务中
思路: 进入添加页面时,获取服务器端的token,
提交时把token提交过去,判断token是否存在,
若存在,则进行后续正常业务逻辑,
如不存在,则报错重复提交.
流程图
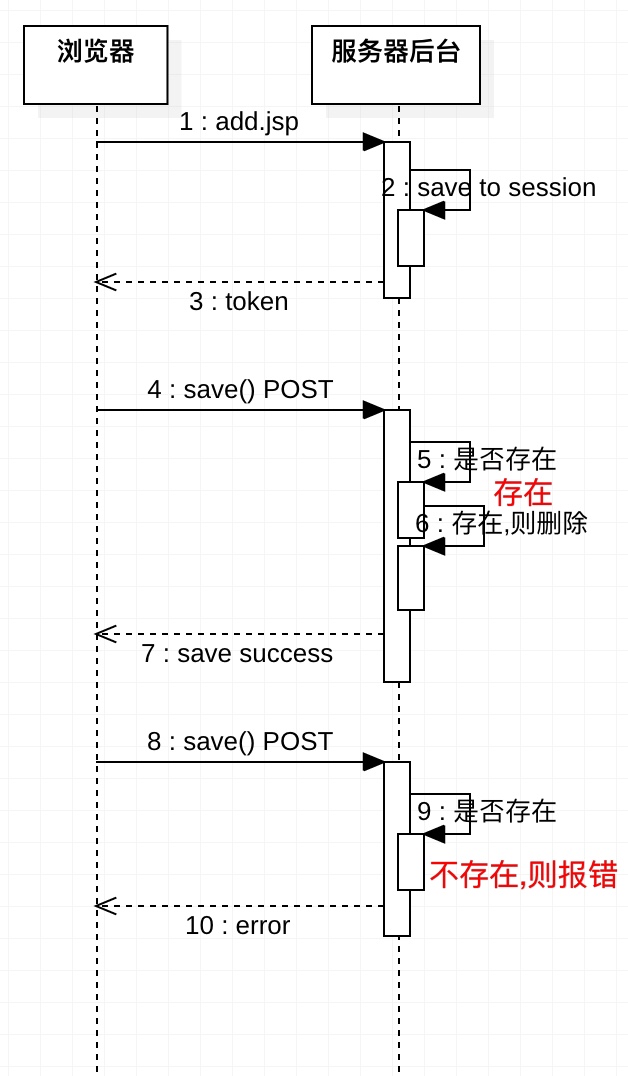
添加页面接口 使用注解:@RepeatToken(save = true) 提交接口 使用注解 :@RepeatToken(remove = true) token 拦截器代码
package com.girltest.web.controller.intercept;
import com.common.util.WebServletUtil;
import org.apache.log4j.Logger;
import org.springframework.web.method.HandlerMethod;
import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.lang.reflect.Method;
import java.util.UUID;
/**
* Created by 黄威 on 9/14/16.<br >
*/
public class TokenInterceptor extends HandlerInterceptorAdapter {
private static final Logger LOG = Logger.getLogger(TokenInterceptor.class);
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
if (handler instanceof HandlerMethod) {
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
RepeatToken annotation = method.getAnnotation(RepeatToken.class);
if (annotation != null) {
boolean needSaveSession = annotation.save();
if (needSaveSession) {
request.getSession(true).setAttribute("token", UUID.randomUUID().toString());
}
boolean needRemoveSession = annotation.remove();
if (needRemoveSession) {
if (isRepeatSubmit(request)) {
LOG.warn("please don't repeat submit,url:" + request.getServletPath());
//如果重复提交,则重定向到列表页面
response.sendRedirect(WebServletUtil.getBasePath(request) + "test/list");
return false;
}
request.getSession(true).removeAttribute("token");
}
}
return true;
} else {
return super.preHandle(request, response, handler);
}
}
/***
*
* @param request
* @return : true:报错需要重定向 <br />
* false: 处理后续的正常业务逻辑
*/
private boolean isRepeatSubmit(HttpServletRequest request) {
String serverToken = (String) request.getSession(true).getAttribute("token");
if (serverToken == null) {
return true;
}
String clinetToken = request.getParameter("token");
if (clinetToken == null) {
return true;
}
if (!serverToken.equals(clinetToken)) {
return true;
}
return false;
}
}
https://my.oschina.net/huangweiindex/blog/1837706
参考: http://www.importnew.com/27477.html
https://my.oschina.net/huangweiindex/blog/1843927