大数据: 知乎1.3万亿条数据毫秒级响应
- -Zhihu,在中文古典中文中意为“你知道吗. ”是中国的Quora:一个问答网站,其中各种问题由用户社区创建,回答,编辑和组织. 作为中国最大的知识共享平台,我们目前拥有2.2亿注册用户,3000万个问题,网站答案超过1.3亿. 随着用户群的增长,我们的应用程序的数据大小无法实现. 我们的Moneta应用程序中存储了大约1.3万亿行数据(存储用户已经阅读过的帖子).
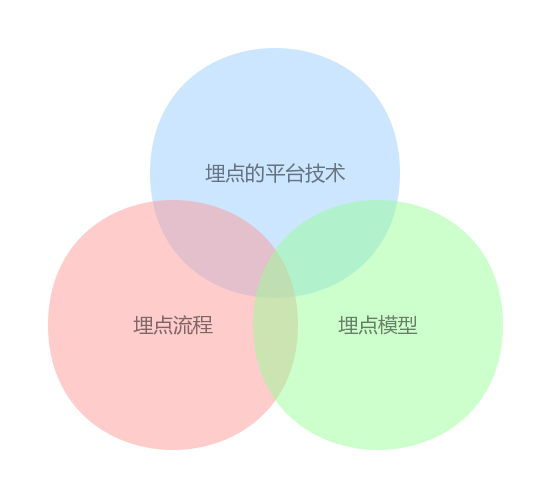
埋点作为商业智能(BI)和人工智能(AI)体系中重要的一环,是公司提升产品工程质量、实施 AB Testing、个性化推荐服务重要的数据来源。在传统的纯 Web 和 Native 开发的产品中,埋点从技术的角度来说未必多深奥,但从业务的角度来说要做到埋点设计规范、流程高效和保证质量却是很难。本文重点介绍一下知乎客户端的埋点模型、流程和平台技术。
Web 端的埋点可以随着新代码上线即时生效,对版本的发车概念相对较弱,即使埋点错漏,修复成本较低。
对客户端而言,如果使用 Native 技术开发的功能埋点有问题,则需要等下一个版本才能修复,并且还有版本覆盖度的问题。修复埋点的这个时间窗口一般都比较长,会对业务的产品快速迭代产生很负面的影响。从业务的角度来说,客户端在发布功能之前,对于要做的数据分析不见得想得全,无计划收集非常多的埋点,对于埋点设计人员、客户端开发、测试人员来说是很大的工作量。反过来说,真正要用数时才发现重要的埋点没有采集,则会 「点」 到用时方恨少。因此,如何综合规划一个版本要采集的埋点,也是颇有挑战的事情,颇有「养兵千日,用兵一时」的感觉。
从业务过程中采集埋点,是数据驱动型公司的必要条件。知乎的产品功能评审环节,不仅有 PRD (Product requirement document),还加入了对应的 DRD ( Data requirement document)。对于埋点而言,DRD 需要明确业务目标与埋点缺口之间的关系以及需求的优先级。埋点的需求大多来自于 DRD,整个过程会涉及多个角色,主要包括产品经理、业务数据负责人、开发工程师、测试工程师。
目前知乎的埋点流程如下图所示。
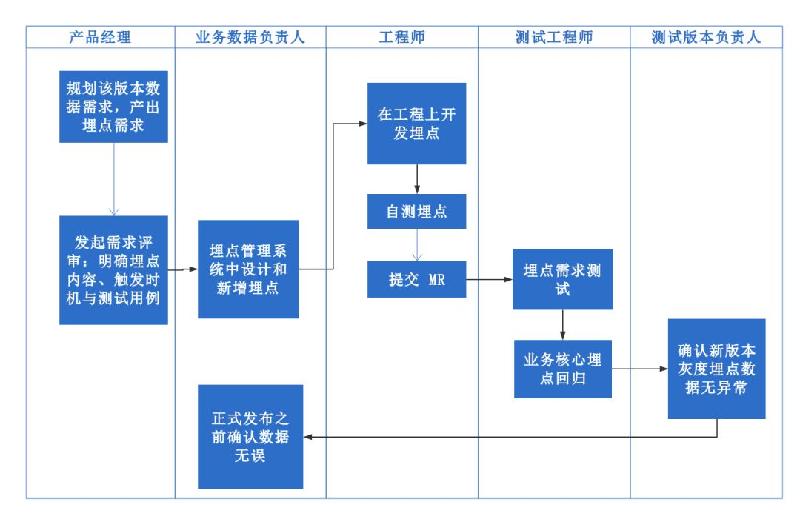
回顾知乎埋点流程的迭代史,整个流程落地三部曲可以总结为六个字:能力、意愿、工具。
这几年知乎的业务发展很快,埋点的流程也随着迭代了很多个版本。在数据平台组成立之初就研发了全端埋点 SDK 和日志的接收服务。在有了埋点 SDK 之后,数据平台组开始在公司推广埋点工作,在早期是埋点的推动方和设计者,使得公司基本具备了打点的能力。
为了快速推进业务的埋点,数据平台组招聘了埋点设计人员来设计全公司的打点。这个方法在短期内帮助公司的埋点工作顺利进行,但是很快随着业务持续的增长,即使是埋点设计的老手也无法快速响应业务的埋点需求,跨业务的任务排期也给业务带来较多的困扰。我们发现埋点的流程如果做到业务闭环,能让整个流程变得更为高效和顺利。业务中哪个角色更有意愿来设计埋点是流程是否高效的重要因素。以下是业务几个和数据有关角色的主要工作内容:
早期埋点测试只有一个能力有限的小工具,用户体验并不够好,直接将埋点测试作为客户端发版流程中的一部分只会整体降低测试工程师的效率。客户端发版往往会遇到新增的埋点打重、打错和打漏,老的埋点缺少回归测试等等问题,给业务带来了不少困扰。因此一个易用性高、自动化和智能化的埋点测试平台成了当时迫在眉睫的事情。在开发完一整套埋点管理和测试系统后,测试工程师将埋点加入了客户端发版流程,并对全公司埋点做了整体评审,推进业务完善了埋点的元信息,并对核心埋点创建了回归测试。在埋点测试平台有效使用起来之后,埋点的质量相比之前得到了大幅度的提升。
古语有云:「治大国若烹小鲜」。目前知乎的埋点数量约为三千个,如果缺少统一的模型来做标准化,每个人设计出来的埋点都不一样。数据平台为此提供公司级通用的埋点模型,既要有公司级别的规范,又要满足业务个性化的需求。在技术上,我们使用 Protocol Buffers 管理埋点 Schema,统一埋点字段和 enum 类型取值,统一 SDK 发版。
页面浏览的统计,对于 Web 端而言, 因为 URL 非常明确, 统计规则简单清新。通常来说,根据一些正则对 URL 进行分类,即可统计出某类页面的 PV。
对于客户端而言,统计的方式和 Web 端比较相似。由于客户端不像 Web 端天然具备 URL,因此需要为页面伪造 URL。只要能被定义 URL,那么 URL 变化了,即可算一次新的 PV。客户端页面浏览统计中,我们遇到的最难的问题是:页面是什么?如果说页面的跳转算一次新的曝光,问题在于页面的功能变化多少算一次页面的跳转?一个典型的场景是一个页面中某子模块进行了 Tab 间切换时,当前页面的 PV 该如何统计。目前对于这个问题,知乎目前没有做统一,由业务自己来定义。
对于行为事件,知乎选择了事件模型,完整描述 Who、When、Where、How 和 What 五大要素。
Who、When 和 How
Who:用户和设备的身份特征。
When:埋点触发的时间。
How:埋点发生时,用户当前的状态,例如网络是 4G 还是 Wifi,当前的 AB 实验命中情况等等。模型中 Who、When、How 由埋点 SDK 自动生成,埋点人员在绝大多数情况下不必关心这三个要素。
Where
准确定位一个事件发生的位置。主要包含以下几个字段提供埋点设计者来做用户事件的定位。

What
在事件发生位置上的内容信息,这里采集的内容由业务决定。 例如点击的卡片是一个回答还是一个 Live,当前内容的状态这类需求。
对于业务定制化的「What」,最初我们为个性化的需求,设计了通用的 ContentInfo,以及特定领域的数据结构。

对于 What,在客户端开发上,我们主要遇到以下问题:
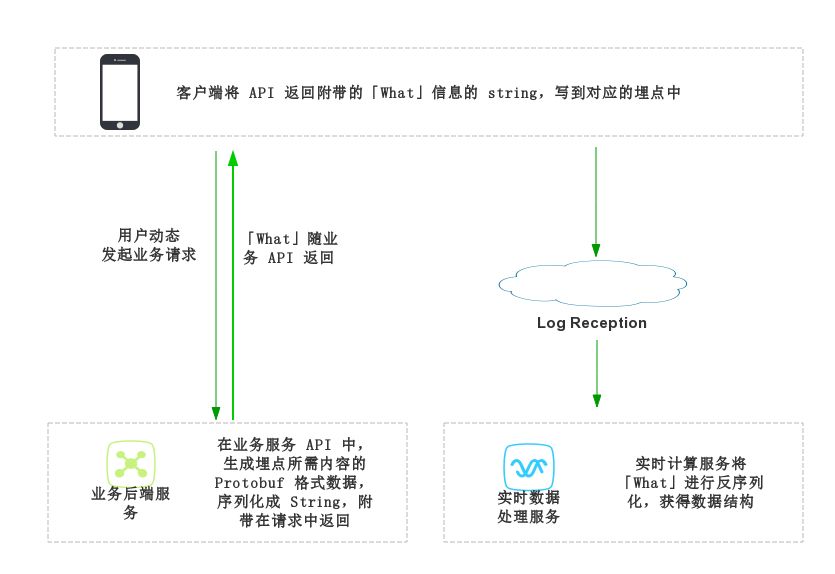
对于 What,在埋点设计上,目前主要遇到以下问题:
第一个问题我们正在对埋点字段进行治理,将平台通用字段和业务字段做系统级别的元信息完善。第二个问题,我们目前还在探索中。「他山之石,可以攻玉」,如果大家在这块有好的实践经验,欢迎给文章评论中分享知识。
当公司的规模生态还很小时,埋点使用 Excel 或者 Wiki 管理对埋点使用上影响不大。当公司业务快速发展,从一个产品变成多个产品,从几十个埋点变成几千个埋点,想要精准的用好埋点,就需要开发埋点的管理平台了。
埋点管理平台负责管理埋点的元信息,解决了埋点的录入和查找需求,同时简化了客户端埋点的内容, 是知乎埋点流程的重要组成部分。同时在工程上又为埋点测试平台,数据采集系统提供埋点的元信息接口。
查看埋点
支持按照多个标签来查找和过滤埋点。 在创建埋点时,需要花时间录入这些元信息,从长期来看,收益会非常大。
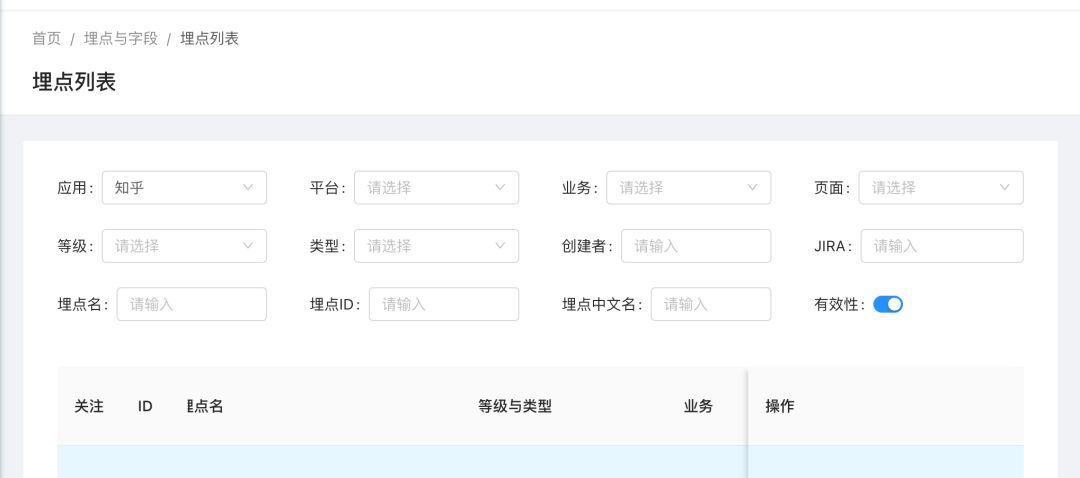
创建埋点
在创建埋点时,填写埋点对应的业务元信息和技术元信息,包括埋点对应的测试说明。埋点管理平台提供埋点的 key,如果需要新增 key 则可向平台申请。对于 enum 类型的 value,系统会自动补全。
生成埋点设计文档
埋点设计文档是工程师开发埋点的依据,是埋点流程中交流需要的重要「媒介」。埋点文档标准化了埋点的设计,包含埋点的以下信息:
提供埋点元信息 API
数据采集服务会对采集到的埋点写入到 Kafka 中,对于各个业务的实时数据消费需求,我们为每个业务提供了单独的 Kafka,流量分发模块会定期读取埋点管理平台提供的元信息,将流量实时分发的各业务 Kafka 中。
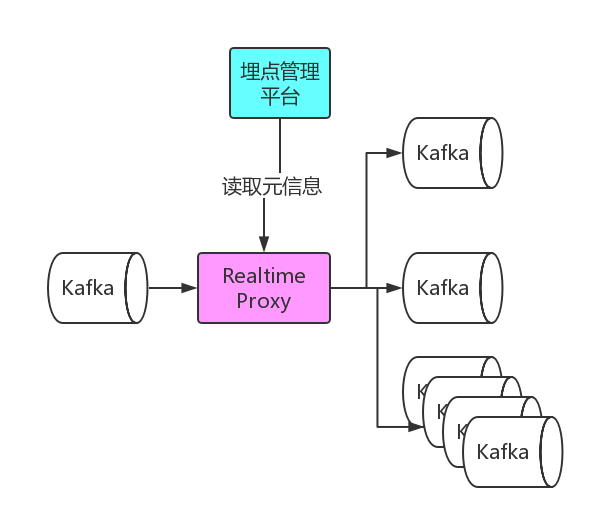
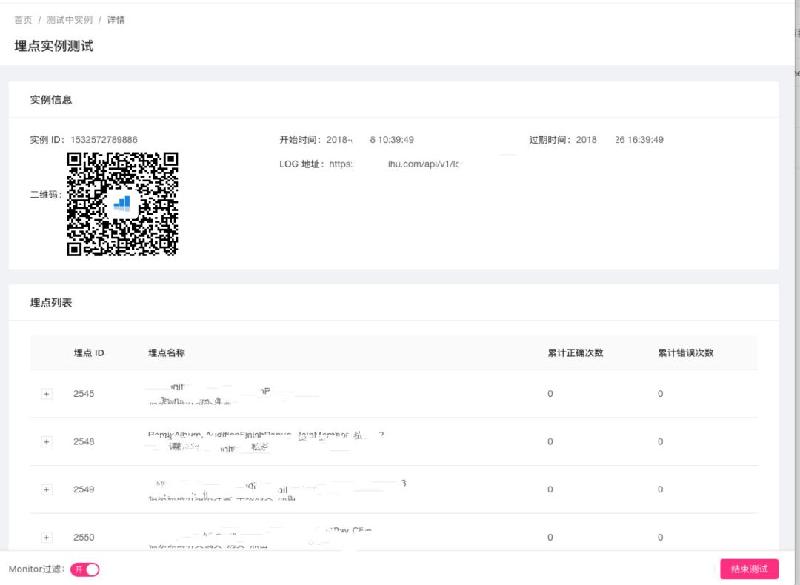
埋点的质量是数据的生命线,一旦出现问题,则会导致整条大数据链路的数据价值出现问题。埋点异常不但影响决策,修复数据同样会消耗大量的精力和时间,最直接的后果就是虽然数据量越来越大,数据本身却无法有效的使用。知乎的数据团队在 2016 年做了一个埋点的小工具,只要输入测试设备的 id,就可以查看对应的埋点信息。这个工具主要有以下几个痛点:
面对如上问题,我们重新设计了埋点测试平台,目标是让埋点测试更自动化和智能化,主要有以下功能:
客户端内的 H5 生成埋点使用的是 JavaScript SDK,如果直接发送到日志收集服务,会丢失客户端的重要属性。知乎的做法是将 H5 的日志发送给客户端,由客户端处理后发送给日志接收服务。在知乎我们对 H5 这类统称 Hybrid,我们自研了 Hybrid 框架,跨端通信和埋点传输由框架提供支持,自动化解决和 ZA (Zhihu Analytics Log Server)的通信问题。
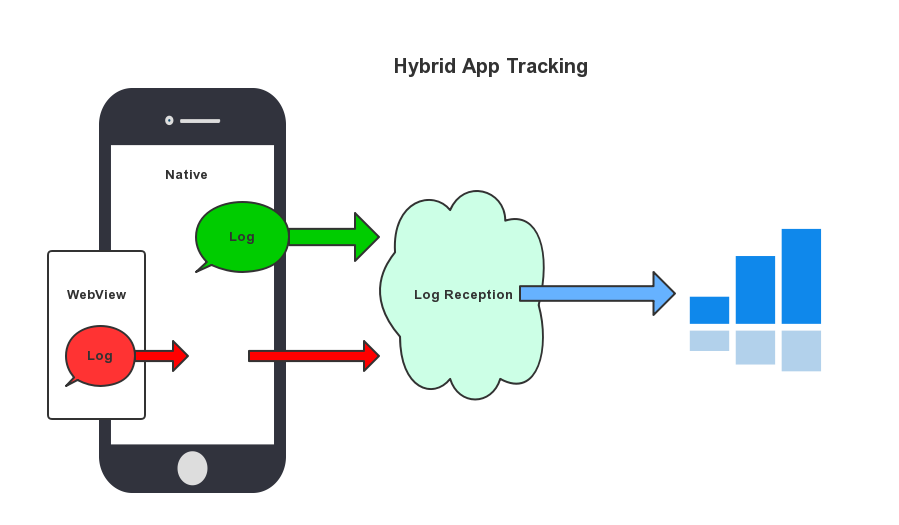
Hybrid 框架主要处理以下的问题:
今天的大数据发展趋势之快,对于很多公司来说都是挑战,埋点是数据整个数据链路中的起点,是数据的生命之源。随着知乎的快速发展,业务越来越多,知乎的埋点模型、流程和平台技术在不断迭代当中,在应用实践上还有很大的改进的空间。
知乎的大数据平台团队,属于知乎的技术中台,是具有数据驱动基因的公司发展到一定阶段必然会重点打造的团队。面对业务的多元化发展和精细化运营,数据的需求变得越来越多,大数据平台团队主要负责:
来自:http://www.infoq.com/cn/articles/event-tracking-in-zhihu