知乎落地的 Service Mesh Istio
- -在知乎,我们很早就进行了非常彻底的容器化部署. 全站在线运行的微服务数量高达两千多个. 这些微服务通过我们自己维护的 RPC 框架和 Kodor 体系来实现服务互联的能力. 在这其中,我们也存在一系列的问题:. 各种基础组件维护成本比较高,单点风险存在. 各语言客户端特性难以统一,熔断、重试等特性实现颇有不同,且不能做到动态线上进行调整.
一、背景
在知乎,我们很早就进行了非常彻底的容器化部署。全站在线运行的微服务数量高达两千多个。这些微服务通过我们自己维护的 RPC 框架和 Kodor 体系来实现服务互联的能力。
在这其中,我们也存在一系列的问题:
各种基础组件维护成本比较高,单点风险存在。
各语言客户端特性难以统一,熔断、重试等特性实现颇有不同,且不能做到动态线上进行调整。
客户端版本迭代难以推动。
微服务某些能力上跟其他大厂还有差距。
与社区、云原生距离较远,配合常见的开源项目紧密度较差。
Service Mesh 可以很好的解决上面的这些问题:
提升微服务治理能力,规范的引入精准的熔断、限流、流量管理等手段。
减少客户端维护、迭代的投入。
提升服务间通信速度。
具备故障注入能力。
具备动态服务路由调整的能力。
因此,我们选择拥抱社区、拥抱 Service Mesh、拥抱 Istio。
二、Kodor 体系介绍
我们先聊一聊知乎之前的微服务体系:Kodor。
在这个系统里,我们会为所有微服务都创建一组 HAProxy 容器。
而所有发向目标服务的流量都会经过这一组 HAProxy。
HAProxy 负责记录基本的指标和访问日志,并实现鉴权、限流、黑名单等功能。

在这一点上, Kodor 系统与服务网格可以算得上是异曲同工之妙,即都是借用代理来实现原本在微服务框架上实现的功能。
三、服务发现与注册
在 Kodor 体系中,Consul 是主要用来作为服务发现和注册的关键组件。
我们将服务的 HAProxy 节点作为服务节点注册到 Consul 。
同时,将服务自身的各节点信息,存储在 Consul 指定路径的 KV 。
这样客户端通过 Consul 发现的服务地址实际上是服务的 HAProxy 地址。
而 HAProxy 则通过 consul-template 的感知上游节点信息。
整体架构如下图所示:

四、Servive Mesh 迁移方案
1、目标
我们首先要确认迁移方案的一个基本要求。
即满足这几个保证:
保证业务无感知迁移,不变更代码;
保证可回滚;
保证高可用;
保证性能无明显下滑;
保证 Mesh 内的服务和 Kodor 的服务可以互相访问。
基于以上的目标要求,我们设计了如下的一个迁移方案。
2、流量互通方案
让我们先看看这两个通路的区别:
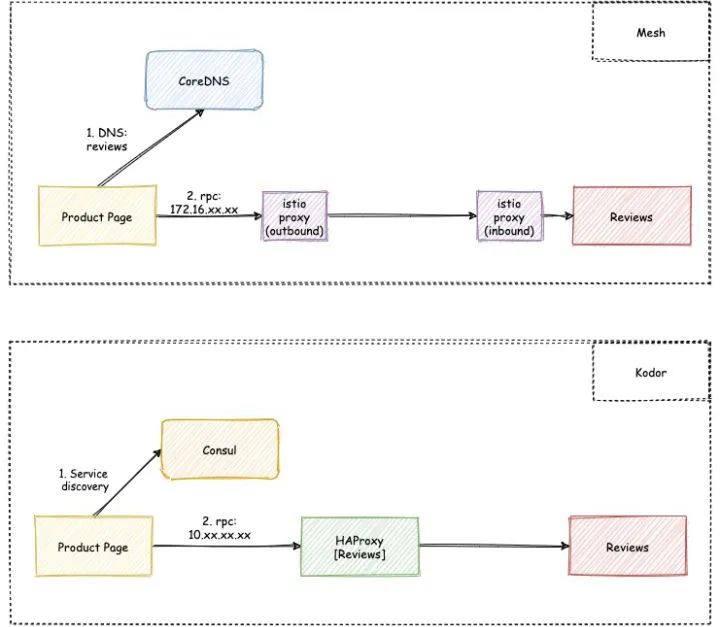
从整体上来看还是非常的类似的,都是先经过 Consul 的服务发现或是 DNS 查询,再进行 RPC 或 HTTP 的流量访问。
由于我们无法要求业务程序进行代码修改,因此无论如何服务发现的组件需要得到保留,原因是大量长尾项目难以推动,耗费大量人力资源可能得不偿失。
通过引入一个新的服务发现服务(Discovery),我们可以轻松的让 Mesh 和 Kodor 的服务实现互通。
这里存在两种 Case:
1)调用方服务在 Mesh 内
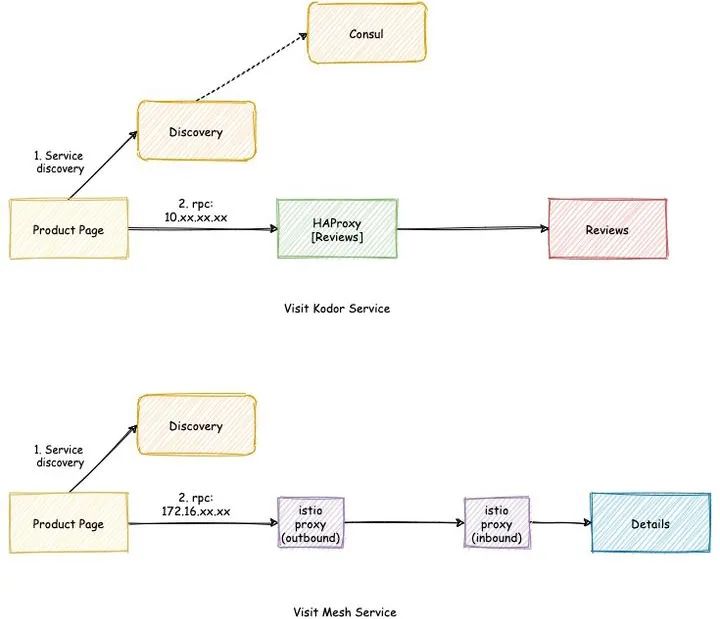
当目标服务不在 Mesh 内,Discovery 服务返回的地址是服务的 HAProxy 的地址(也就是将流量代理到 Consul)。
当目标服务在 Mesh 内,Discovery 服务将返回服务的 ServiceIP,此时应用将通过 Sidecar 触发 Service Mesh 的路由能力,将请求直接传递到对端 Sidecar。
2)调用方服务不在 Mesh 内
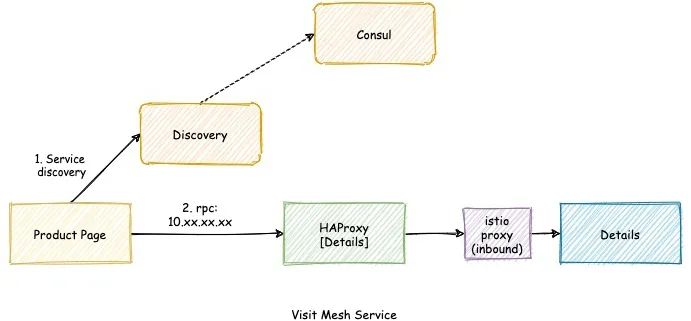
我们仍然保留服务的 HAProxy,因此调用方仍然可以通过 “Consul” 发现 HAProxy 端点,进行流量的投递。
3、流量管理
1)沙箱联调的支持
在知乎,我们有一种功能叫沙箱联调。
即创建一种沙箱,在沙箱内部署的服务在调用其他服务的时候,优先访问沙箱内部署的负载组。
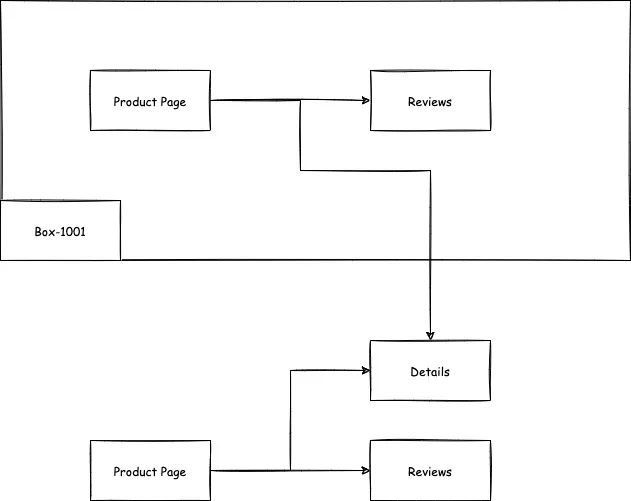
在 Mesh 中,我们也需要相对应功能的实现。首先,我们对所有沙箱内的负载组默认打上 branch=box-xxx 的 label。
然后我们在 VirtualService 中,添加通过 SourceLabel 匹配路由的规则。
下面是这样的一个例子:
apiVersion: networking.istio.io/v1beta1kind: VirtualServicemetadata:name: sm-verify-titlenamespace: sm-verifyspec:gateways:- mesh- istio-system/svc-ingresshosts:- sm-verify-title.sm-verify.svc.cluster.localhttp:- match:- sourceLabels:branch: box-10326name: box-10326--defaultroute:- destination:host: sm-verify-title--box-10326.sm-verify--box-10326.svc.cluster.localsubset: default- name: master--defaultroute:- destination:host: sm-verify-title--master.sm-verify.svc.cluster.localsubset: default
2)版本迭代中的 503 问题
官网关于这个问题的描述:https://reurl.cc/WkA6K7
简单来说就是需要:
在添加版本子集的时候,需要先修改 DR,等 DR 生效后再修改 VS。
在删除版本子集的时候, 需要先修改 VS,等 VS 生效后再修改 DR。
首先我们面临的问题是需要确定什么时候对象能生效。
这一点可以用 istioctl wait 来保证。
或者也可以直接等待一个经验时间,比如 30s。
其次,我们可能需要保障这个操作的事务性,不能出现同时多个对于 VS/DR 的操作,以导致操作的后果不可预期。
为了解决这个问题,我们引入一个新的自定义资源:Router,用于声明式变更版本和路由。
Router 同时也用于配置上述沙箱功能的配置和 Service 的创建,以简化应用的配置管理。
例子:
apiVersion: router.service-mesh.zhihu.com/v1kind: Routermetadata:name: sm-verify-web # 服务名namespace: sm-verifyspec:port: 9090protocol: httpsubsets:- branch: master # 生产默认路由versions: # 百分之十流量进行金丝雀验证v1.0.1: 90v1.0.2: 10- branch: box-0999 # 沙箱 ID
4、迁移
迁移到 Mesh,需要做如下几件事情:
Pod 添加注入 Sidecar 需要的 Label(istio-injection=enabled)。
为服务创建 Router 对象。
在第一步,我们修改了 Sidecar 的注入方式,以实现按照服务粒度的迁移。
我们简化了一下流程,为每个服务都默认创建了 Router 对象。
因此,迁移到 Mesh 就只需要给 workload 添加 label 然后重新部署。
5、回滚
1)系统性回滚
当 Istio 设施出现大面积系统性故障的时候,我们可以通过配置使 Discovery 完全降级到纯 Consul 代理,这样所有流量将恢复到旧有的 Kodor 系统中,实现了系统级别的回滚。
2)服务回滚
服务回滚只需要修改 Label,重新部署即可。
6、服务网格平台
为了使业务同学能够更方便的使用服务网格的能力,我们开发了一个平台,用于在线变更服务网格的配置。

这个平台的功能包括: 路由、限流、黑名单、授权、流量镜像、负载均衡策略、熔断、链接池、自动重试、服务发现管理等。
在这个平台的建设过程中,我们遇到这样的问题:
如果使用数据库存储用户配置,数据库的数据怎么和集群配置保持一致性?
能否很好的暴露接口和其他系统一起工作?
基于以上两点,我们设计了一个新的组件:IstioFilter。
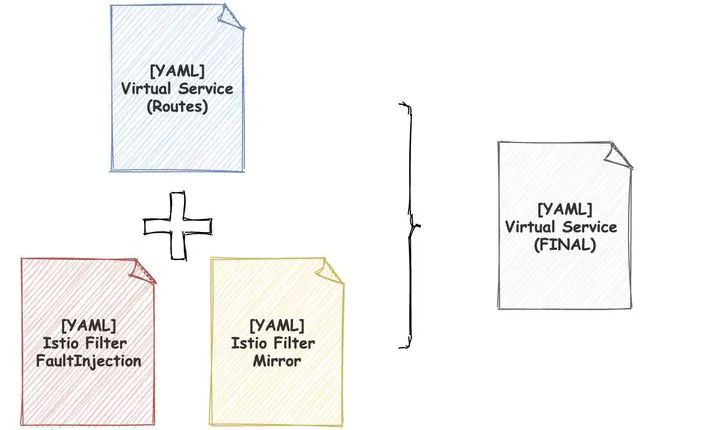
我们把服务的路由和子集看作基本的配置框架,通过 Patch 的方式把一个个具体功能 通过 istiofilter patch 到 VS/DR 之上。
这样,配置镜像流量是一个 istiofilter,配置故障注入也是一个 istiofilter。
平台上所有的配置几乎都对应一个独立的 istiofilter 的资源。
我们不需要将这些配置存储到数据库,也就不需要解决数据库和配置的一致性问题。
同时,其他系统比如混沌工程,也可以很轻易的通过 istiofilter 管理自己的故障注入能力。
istiofilter 是按照优先级顺序层层 Patch,因此整体的配置是可预测的,各个系统之间的配置并不会产生冲突。
倘使没有 istiofilter,那么各个系统对同一个 VS 对象的各种功能的新增、修改、删除而产生的冲突可就是个 bug 的无底洞了。
7、限流
由于 Istio 早在 1.5 版本中就几乎完全废弃了之前 Quota 的内容。
因此,我们需要自行解决在 Istio 上的限流问题。
限流配置:
首先限流从令牌桶上,我们分为全局限流和本地限流。
全局限流指的是所有特征流量在全局共享一个令牌桶。
本地限流指的是每个 Pod 有自己的令牌桶。
其次从限流作用的位置上,又分为服务端限流和客户端限流。
本地限流的实现非常简单,只需要配置一个 EnvoyFilter 即可。
例如,在我们的 sm-verify-page 服务上开启 [本地-服务端-1000rps] 限流。
apiVersion: networking.istio.io/v1alpha3kind: EnvoyFiltermetadata:name: locallimit-sm-verify-page-xxxxnamespace: sm-verifyspec:configPatches:- applyTo: HTTP_ROUTEmatch:context: SIDECAR_INBOUNDrouteConfiguration:vhost:route: {}patch:operation: MERGEvalue:typed_per_filter_config:envoy.filters.http.local_ratelimit:'@type': type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimitfilter_enabled:default_value:denominator: HUNDREDnumerator: 100runtime_key: local_rate_limit_enabledfilter_enforced:default_value:denominator: HUNDREDnumerator: 100runtime_key: local_rate_limit_enforcedstage: 0stat_prefix: inboundtoken_bucket:fill_interval: 1smax_tokens: 1000tokens_per_fill: 1000workloadSelector:labels:app: sm-verify-pagebranch: master
而全局限流的配置分为两部分,一部分是给服务添加 EnvoyFilter 配置,另一部分就是修改限流服务上对应的限流 Quota。
这个流程大概是:
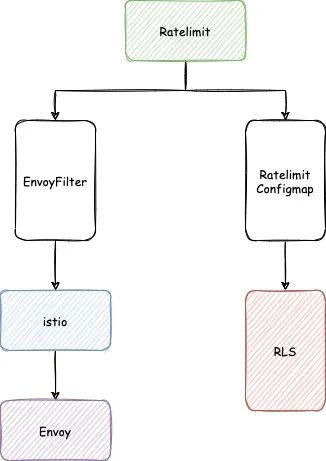
在我们内部使用了一个叫 Girls(Global Incredible Rate Limit System)的系统来简化操作配置。
apiVersion: quota.service-mesh.zhihu.com/v1kind: RateLimitmetadata:name: sm-verify-page-dbcecaanamespace: sm-verifyspec:hosts:- sm-verify-page.sm-verify.svc.cluster.local:80match:headers:- key: :pathmatchType: exactvalue: /Page.Showquota: 800stage: 1unit: SECOND
五、优化
接下来,我们谈一下:Istio 在知乎的集群落地所做的一些优化策略。
1、改善边车性能
默认情况下,集群中 Service 的数量达到一定规模时,服务的边车的内存、CPU 消耗将显著激增。
这是因为 Istio 下发到边车的代理配置是集群的全量信息。并且,集群中任何的变化都会触发一次全量的配置推送。
试想,倘若几个大型的服务同时持续部署,可能每秒钟会产生成百上千的事件,这必将酝酿灾难级的生产故障。
2、使用 Sidecar 配置
Istio 提供了一种方法可以改善这种情况。通过配置一种叫做 Sidecar 的CRD,你可以告知 Istio ,服务之间的依赖关系。从而让 Istio 仅下发所需要的代理配置。
如在示例应用 Bookinfo 中,Page 服务仅需要访问 Reviews 服务与 Details 服务。
因此,我们通过配置如下类似的配置,以避免 Istio 推送给 Page 的边车不相干服务的配置信息:
apiVersion: networking.istio.io/v1alpha3kind: Sidecarmetadata:name: pagespec:workloadSelector:labels:app: pageegress:- hosts:- "./reviews"- "./details"- "istio-system/*" # 确保系统服务的配置能下发到 Sidecar,以保留旧版遥测能力
在这个配置中, workloadSelector 指定作用在的工作负载组。这里使用 app: page 的标签选择器筛选出 Page 的容器。
hosts 则是负载组所需要依赖的服务的主机名列表。它的格式是 namespace/host,同命名空间下的 namespace 可以缩写为 . 来表示。host 支持 * 作为通配符来匹配多个主机名。
在这里,因为 Page 所依赖的服务都是同命名空间,因此写作 ./reviews 和 ./details。
当然这个如果暴露给业务去配置,那想必可能因为人的疏忽而导致服务异常的出现。
因此, 我们在服务发现 Discovery 上加了个功能:当收到服务发现请求时,自动去维护这个 Sidecar 的配置。
这样,我们几乎不需要业务同学去维护这个配置。
3、改善 istiod 性能
1)避免 XDS 不断被断开
通过给 istiod 配置 PILOT_XDS_SEND_TIMEOUT 环境变量,我们可以设定 istiod 推送的超时时间,默认为 5s,在大规模集群下,建议适度调高此配置。
2)减少推送量
我们将 istiod 的 PILOT_FILTER_GATEWAY_CLUSTER_CONFIG 环境变量配置为 “true”,这样 Istio 将仅推送 Gateway 所需的服务信息(参考VirtualService的gateway配置),这个配置将极大的减少每次推送的量。开启这个特性之后,笔者集群内的 istiod 每次向 Gateway 推送的服务信息从四万多降低到两千。
3)开启流控
我们将 istiod 的 PILOT_ENABLE_FLOW_CONTROL 环境变量配置为 “true”。这个时候 istiod 将会等待接收完成后,再进行下一次推送。
4)配置 Envoy 工作线程数
修改 Gateway 启动参数,加入 --concurrency=20,20 是期望 Gateway 运行的 worker 数量。
5)提高吞吐
默认情况下,单个 istiod 的推送并发数只有 100,这在较大的集群内,可能会导致配置生效的延迟。istiod 环境变量 PILOT_PUSH_THROTTLE 可以配置这个并发数。建议匹配集群规模进行配置。
6)避免频发推送
PILOT_DEBOUNCE_AFTER 与 PILOT_DEBOUNCE_MAX 是配置 istiod 去抖动的两个参数。
默认配置是 100ms 与 10s ,这也就意味着,当集群中有任何事件发生时,Istio 会等待 100ms。
若 100ms 内无任何事件进入,Istio 会立即触发推送。否则 Istio 将会等待另一个 100ms,重复这一操作,直到总共等待的时间达到 10s 时,会强制触发推送。
实践中可以适当调整这两个值以匹配集群规模和实际应用。
由于我们的集群内服务的 Pod 均配置了 preStop 为 sleep 35,因此,我们调高了 PILOT_DEBOUNCE_AFTER 到 500ms,以避免频繁推送对性能产生影响(主要是 Gateway )。
同时,我们调低了 PILOT_DEBOUNCE_MAX 为 3s,以避免极端情况下推送不及时导致的 503 问题。
六、我们遇到的各种坑
1、接入基础设施的坑
1)全链路追踪的接入问题
我们现有的全链路追踪使用的是 Jaeger。
Jaeger 推荐的架构是:应用先通过 UDP 协议投递到宿主机的 Jaeger Agent 上,Jaeger Agent 再投递到 Collector 组件。
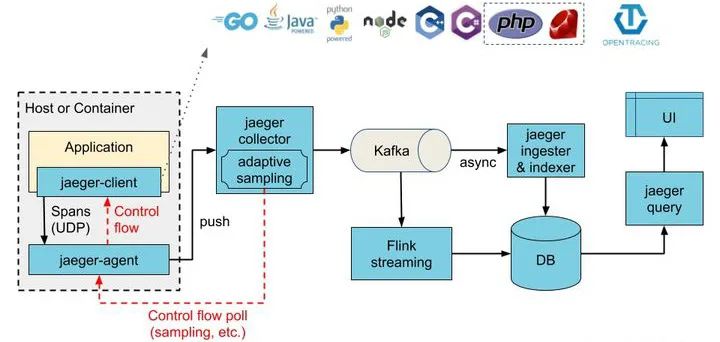
这样的设计很明显是合理的,然后 Envoy 却不能支持 Jaeger Agent 所支持的协议。
我们需要的是通过宿主机的 Agent 收集 tracing 数据,来最大程度的避免受到网络抖动、collector 稳定性等问题的影响。
通过查看 Envoy 文档,Envoy 是支持 OpenCensus 协议的,因此我们选用了支持 OpenCensus 协议的 OpenTelemetry 的 Agent 来替代 Jaeger Agent。
istio-operator 的配置如下:
tracing:openCensusAgent:address: ipv4:$(HOST_IP):55678 # 这里是支持使用环境变量的.context:- W3C_TRACE_CONTEXT- B3sampling: 1
2)日志的接入问题
目前我们开启了 Istio 的访问日志,但是引起了一些问题:
首先就是全站 Sidecar 的日志量太大了,对于日志系统产生了很大的压力。
绝大多数的日志,没有产生什么实际价值。
这就需要有能力在不关键的服务上默认关闭访问日志,在需要的时候能够动态开启来定位问题。
我们尝试过通过 Filebeat 的一些策略抛弃指定特征的 Sidecar 日志,可以规避这个问题。
不过这也太不优雅了,可能还是需要等之后新版本的、Istio 官方推出的 Telemetry API 来支持。
2、Kubernetes 遇到的挑战
1)IPVS 的问题
我们之前的 Kodor 系统并不需要依赖 Service,在开始迁移 Mesh 之后,我们发现全站的 latency 都显著的增长。
经过定位,这个问题来源于 IPVS 模块,当创建了过多的 Service 后,IPVS 的 ip_vs_estimation_timer 函数执行特别慢,而这个函数是在软中断中执行的,从而导致内核的网络包处理延迟。
这个在最新的内核中已经得到了解决。
如果用的是云厂商提供的内核,也大概率都已经打上了补丁。
2)DNS 的问题
我们原先的部署的容器,DNSPolicy 采用的是 Default 策略,DNS 查询会被本地的 unbound 缓存。
而迁移到 Service Mesh 的 Pod,需要使用 ClusterFirst 模式。
我们上线了一些应用后,发现很多调用流量的 latency 都上涨很严重,这些流量往往都是短链接。
这时我们才注意到,只靠 CoreDNS 是一定不行的,需要开启 Kubernetes 的 NodeLocalDNS 功能来做一层 Cache。
七、兼容性问题
1、HTTP1.0 兼容性问题
默认情况下,Istio 并不兼容 HTTP1.0 协议。
这会使某些流量出现异常,比如某些组件的健康检查。
配置 istiod 的 PILOT_HTTP10 环境变量,设置为 “true”,就可以修复这个问题。
2、服务启动异常问题
服务可能会遇到无法启动的情况,这是因为 istio-proxy 还没有准备好。需要开启 holdApplicationUntilProxyStarts: true,并配置 postStart 等待 istio-proxy 准备好之后再启动服务容器。
proxy:lifecycle:postStart:exec:command:- pilot-agent- wait
3、服务部署/重启过程中各种连接异常问题
在 Pod 退出时,需要至少比服务容器更长的 prestop 时间,以保证服务进程存活的周期内,Sidecar 持续可用。比如我们服务进程 preStop 的经验值是 30s,那么 istio-proxy 的 preStop 至少要比 30s 更长。
proxy:lifecycle:preStop:exec:command:- sleep- "35"
4、服务间透传 Host
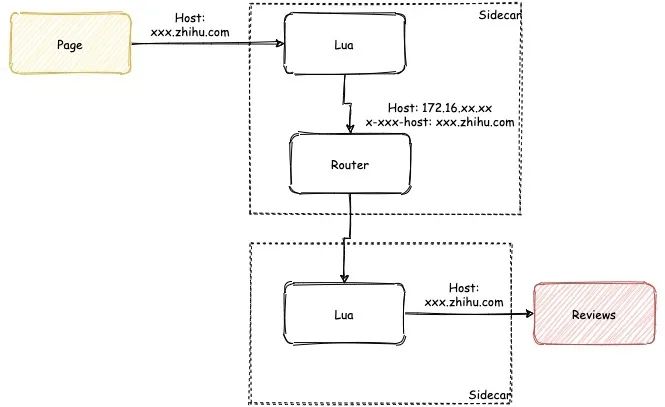
我们有一些服务需要将 Host 透传给下一个服务。

不幸的是 Istio 并不能支持这种情况,这个跟 Istio 使用的 Envoy 方式有关:
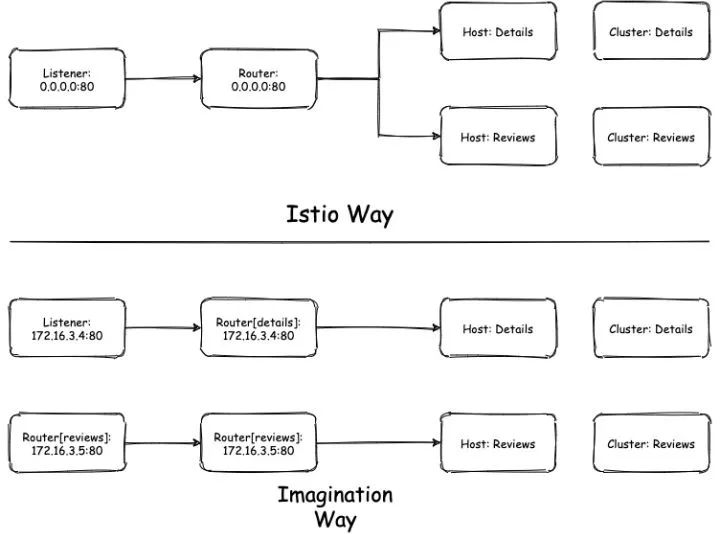
这张图下面的是我想象中的方式,使用 VIP 直接作为 Listener 的匹配规则。
上面的是 Istio 实际的使用方式,相同端口的服务会使用同一个 Listener 和 Router,然后用 Host 来匹配路由。
因此可想而知:
当 page 调用 reviews 时,如果用了个不认识的 Host,在 Router 上直接就匹配失败了。
这个问题我们使用了 Lua 插件来解决。
先把原先的 Host 存在另一个 Header 中,比如 x-my-host ,改写当前流量的 Host 为服务的 VIP。
服务的 Inbound 端再用这个 Header 覆盖掉传过来的 Host。
大致流程如图所示:
5、默认重试问题
Istio 默认给所有流量都加了默认重试策略。
retryPolicy:hostSelectionRetryMaxAttempts: "5"numRetries: 2retriableStatusCodes:- 503retryHostPredicate:- name: envoy.retry_host_predicates.previous_hostsretryOn: connect-failure,refused-stream,unavailable,cancelled,retriable-status-codes
这就带来了一些问题。
比如对于 gRPC 来说:
当响应码为 unavailable、cancelled 时重试可能会在业务故障的时候让流量翻三倍。
这让故障更难自愈,非常难受。
因此,我们给所有 gRPC 服务配置了我们自定义的重试策略,以避免出现类似的故障。
6、慢响应带来的问题
某些服务可能响应速度非常的慢,这就导致了有概率出现无法创建链接问题。
这是因为所有来源流量的 IP 端口在经过 Sidecar 后都被映射到 IP 固定为 127.0.0.6 的某个端口上。
如图所示:
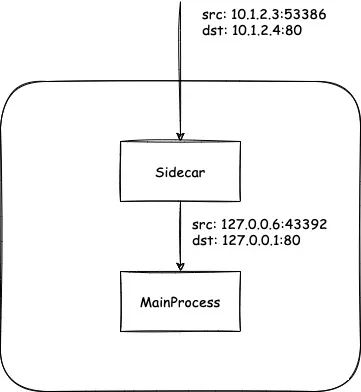
因为 TCP 的协议限制,因此有可能出现超过三万的连接数后,无法再为链接分配出端口的问题。
怎么解决呢?
我们认为 HTTP 1.1 可能是无解的,尽可能使用 HTTP 2 吧,比如 gRPC。
7、无 Service 关联容器的问题
1)区域感知失效
像 CronJob 这样类型的服务,很难为其创建 Service,但是它仍然有需求去访问其他服务。
在目前的 Istio 版本中,这样的 CronJob 服务就会丢失区域感知的能力。
这个问题也并不是无解的,只需要在 Pod 上添加一个叫 istio-locality 的 Label 即可。
Istio 会使用这个 Label 作为 Pod 的区域信息。
2)默认 Sidecar 配置失效
如果你的 namespace 中,没有任何 Service,那么你的容器也不能使用配置好的全局默认的 Sidecar 配置。
如果你的集群很大,那么在你注入边车的时候,你的 Pod 很可能会直接 OOM 掉。
解决这个问题,需要为所有 namespace 都配置默认 Sidecar。
八、Istio 的部署
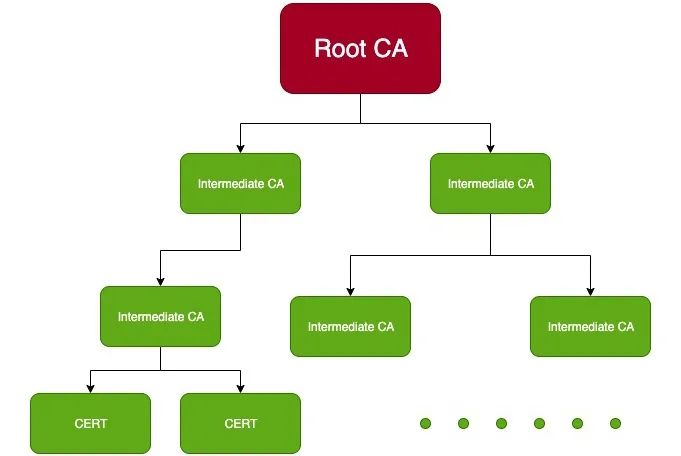
每个 Istio 集群都需要一个根证书,来给每个代理容器颁发证书。
无论你是否需要多集群,我都建议你生成符合多集群的证书结构,即一个“总根证书”,再用这个总根证书为你的集群签署一个集群内的根证书。
这样将来从单集群模式升级到多集群模式,根证书不需要经历切换的痛楚,这在线上环境是风险极高的。
这里还需要注意一个问题:如果你一开始的安装没有指定版本,你可能很难切换到使用金丝雀来验证新版本的 Istio 。
九、总结
Service Mesh 提供了非常优雅的微服务体系的统一的云原生解决方案。
Istio 作为行业公认的标准,已经被绝大多数云原生新基建所兼容。
而截止到目前为止,我们在知乎落地的 Service Mesh 的服务数量占全站服务总数的四分之一,许多关键 S 级别服务都已经接入并享受到最新的、来自云原生社区的红利。并且,这一过程仍在加速。
那么下一步呢?
服务网格关注在服务通信,是基础架构视图下的俯瞰。业务无感知接入使用,从顶层视图管理微服务。
而分布式运行时则更关注业务实现的视图,比如提供 Actor 框架,解耦基础设施资源(如解耦消息队列、解耦数据库等)。
介于两者之间呢?也有,比如 DB Mesh。
下一步也许是统一分布式运行时和服务网格。
我们将为业务:
提供缓存能力⽽不是 Redis、Memcached ……
提供异步通信⽽不是 Kafka、Pulsar ……
提供存储能⼒⽽不是 MySQL、TiDB ……
提供同步通信⽽不是 Dubbo、Spring Cloud、go-micro。
无关语言、无关平台、专注业务。