各大公司广泛使用的在线学习算法FTRL详解 - EE_NovRain - 博客园
- - 转载请注明本文链接:http://www.cnblogs.com/EE-NovRain/p/3810737.html . 现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression),而传统的批量(batch)算法无法有效地处理超大规模的数据集和在线数据流,google先后三年时间(2010年-2013年)从理论研究到实际工程化实现的.
转载请注明本文链接:http://www.cnblogs.com/EE-NovRain/p/3810737.html
现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression),而传统的批量(batch)算法无法有效地处理超大规模的数据集和在线数据流,google先后三年时间(2010年-2013年)从理论研究到实际工程化实现的 FTRL(Follow-the-regularized-Leader)算法,在处理诸如逻辑回归之类的带非光滑正则化项(例如1范数,做模型复杂度控制和稀疏化)的凸优化问题上性能非常出色,据闻国内各大互联网公司都第一时间应用到了实际产品中,我们的系统也使用了该算法。这里对FTRL相关发展背景和工程实现的一些指导点做一些介绍,凸优化的理论细节不做详细介绍,感兴趣可以去查阅相应paper,相关paper列表会在文后附上。机器学习并非本人在校时的专业方向,不过在校期间积累的基础不算太差,而且很多东西也是相通的,钻研一下基本意思都还能搞明白。当然,有不准确的地方欢迎大家讨论指正。
本文主要会分三个部分介绍,如果对理论产生背景不感兴趣的话,可以直接看第3部分的工程实现(这一部分google13年那篇工程化的paper介绍得很详细):
一、相关背景
【问题描述】
对于loss函数+正则化的结构风险最小化的优化问题(逻辑回归也是这种形式)有两种等价的描述形式,以1范数为例,分别是:
a、无约束优化形式的soft regularization formulation:
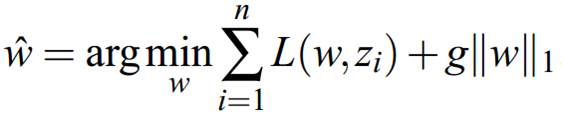
b、带约束项的凸优化问题convex constraint formulation:
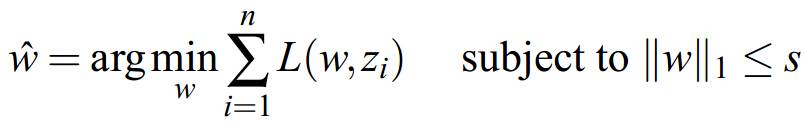
当合理地选择g时,二者是等价的。这里提这两种形式的问题描述,原因在于引出下面无约束优化和带约束优化问题的不同算法,对于不同的描述形式,会有一系列相关算法。
【批量(batch)算法】
批量算法中每次迭代对全体训练数据集进行计算(例如计算全局梯度),优点是精度和收敛还可以,缺点是无法有效处理大数据集(此时全局梯度计算代价太大),且没法应用于数据流做在线学习。这里分无约束优化形式和约束优化(与上面问题描述可以对应起来)两方面简单介绍一下一些传统批量算法。
a、无约束优化形式:1、全局梯度下降 ![]() ,很常用的算法,就不细说了,每一步求一个目标函数的全局梯度,用非增学习率进行迭代;2、牛顿法(切线近似)、LBFGS(割线拟牛顿,用之前迭代结果近似Hessian黑塞矩阵的逆矩阵,BFGS似乎是几个人名的首字母的简称)等方法。牛顿和拟牛顿等方法一般对于光滑的正则约束项(例如2范数)效果很好,据说是求解2范数约束的逻辑回归类问题最好的方法,应用也比较广,但是当目标函数带L1非光滑、带不可微点的约束项后,牛顿类方法比较无力,理论上需要做修改。感兴趣的可以去查查无约束优化的相关数值计算的书,我也没有更深入研究相关细节,这里不做重点关注。
,很常用的算法,就不细说了,每一步求一个目标函数的全局梯度,用非增学习率进行迭代;2、牛顿法(切线近似)、LBFGS(割线拟牛顿,用之前迭代结果近似Hessian黑塞矩阵的逆矩阵,BFGS似乎是几个人名的首字母的简称)等方法。牛顿和拟牛顿等方法一般对于光滑的正则约束项(例如2范数)效果很好,据说是求解2范数约束的逻辑回归类问题最好的方法,应用也比较广,但是当目标函数带L1非光滑、带不可微点的约束项后,牛顿类方法比较无力,理论上需要做修改。感兴趣的可以去查查无约束优化的相关数值计算的书,我也没有更深入研究相关细节,这里不做重点关注。
b、不等式约束凸优化形式:1、传统的不等式约束优化算法内点法等;2、投影梯度下降(约束优化表示下),gt是subgradient,直观含义是每步迭代后,迭代结果可能位于约束集合之外,然后取该迭代结果在约束凸集合上的投影作为新的迭代结果(第二个公式中那个符号标识向X的投影):
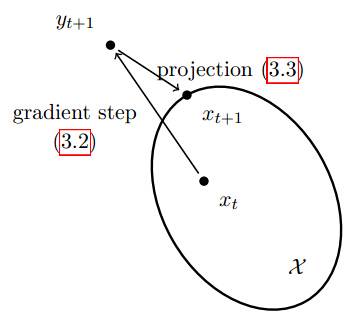
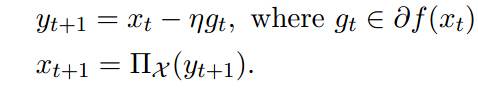
【在线算法】
如上所述,批量算法有自身的局限性,而在线学习算法的特点是:每来一个训练样本,就用该样本产生的loss和梯度对模型迭代一次,一个一个数据地进行训练,因此可以处理大数据量训练和在线训练。常用的有在线梯度下降(OGD)和随机梯度下降(SGD)等,本质思想是对上面【问题描述】中的 未加和的单个数据的loss函数 L(w,zi)做梯度下降,因为每一步的方向并不是全局最优的,所以整体呈现出来的会是一个看似随机的下降路线。典型迭代公式如下:
![]()
这里使用混合正则化项: ![]() ,例如可能是1范数与2范数强凸项的混合
,例如可能是1范数与2范数强凸项的混合 ![]() (后面会看到其实很多都是这种混合正则化的格式,而且是有一定直观含义的)。迭代公式中:gt是loss函数(单点的loss,未加和)的subgradient,与gt相加的那一项是混合正则化项中的第二项的梯度,投影集合C是约束空间(例如可能是1范数的约束空间),跟上面介绍的投影梯度下降类似的做法。
(后面会看到其实很多都是这种混合正则化的格式,而且是有一定直观含义的)。迭代公式中:gt是loss函数(单点的loss,未加和)的subgradient,与gt相加的那一项是混合正则化项中的第二项的梯度,投影集合C是约束空间(例如可能是1范数的约束空间),跟上面介绍的投影梯度下降类似的做法。
梯度下降类的方法的优点是精度确实不错,但是不足相关paper主要提到两点:
1、简单的在线梯度下降很难产生真正稀疏的解,稀疏性在机器学习中是很看重的事情,尤其我们做工程应用,稀疏的特征会大大减少predict时的内存和复杂度。这一点其实很容易理解,说白了,即便加入L1范数(L1范数能引入稀疏解的简单示例可以产看PRML那本书的第二章,我前面一篇blog的ppt里也大概提了),因为是浮点运算,训练出的w向量也很难出现绝对的零。到这里,大家可能会想说,那还不容易,当计算出的w对应维度的值很小时,我们就强制置为零不就稀疏了么。对的,其实不少人就是这么做的,后面的Truncated Gradient和FOBOS都是类似思想的应用;
2、对于不可微点的迭代会存在一些问题,具体有什么问题,有一篇paper是这么说的:the iterates of the subgradient method are very rarely at the points of non-differentiability。我前后看了半天也没看明白,有熟悉的同学可以指导一下。
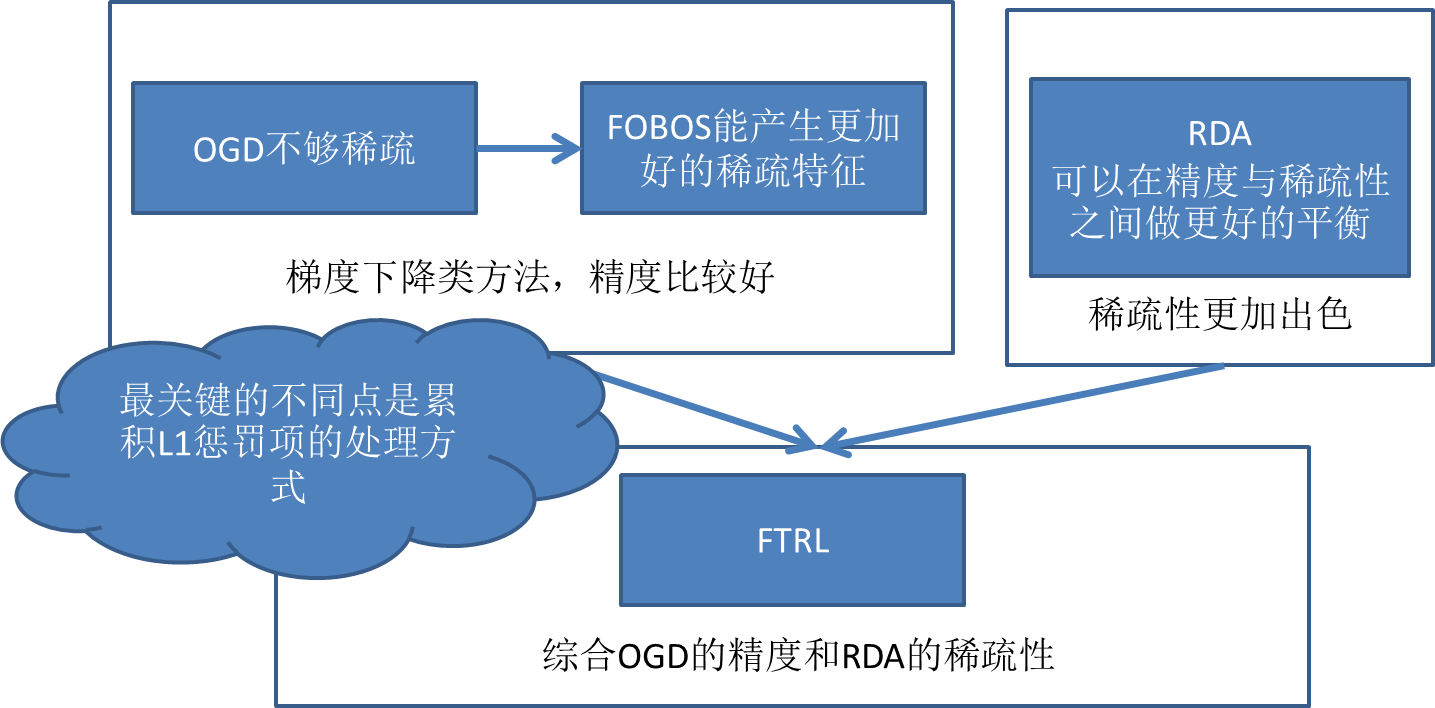
二、Truncated Gradient、FOBOS以及RDA(Regularized Dual Averaging)
上面提到了,稀疏性在机器学习中是很重要的一件事情,下面给出常见的三种做稀疏解的途径:
1)、简单加入L1范数
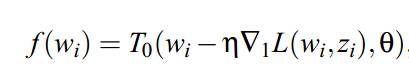
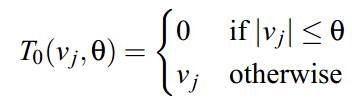
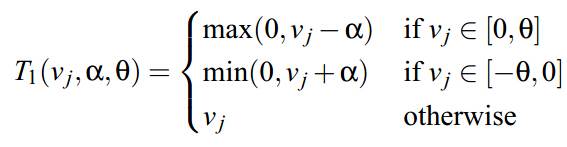
下面会提一下FOBOS(Forward-Backward Splitting method,其实应该叫FOBAS的,历史原因)以及RDA,因为后面的FTRL其实相当于综合了这两种算法的优点:
a、FOBOS,google和伯克利09年的工作:
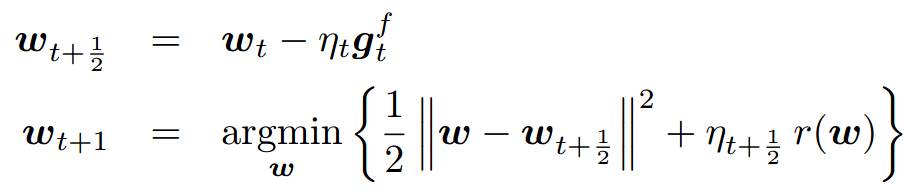
b、RDA(Regularized dual averaging),微软10年的工作,更加理论性一些,这里就直接略过去了,仅对其特点做一个简单介绍:
ok,背景和一些铺垫终于完成了,下面重点进入FTRL的部分。。。
三、FTRL (Follow-the-regularized-Leader)
【发展历程】
FTRL的理论推进和工程应用首先要感谢这个人:H. Brendan McMahan, google这哥们儿护了三年的坑,直到13年工程性paper出来。发展历程和基本说明如下:
–10年理论性paper,但未显式地支持正则化项迭代;11年证明regret bound以及引入通用的正则化项;11年另一篇的paper揭示OGD、FOBOS、RDA等算法与FTRL关系;13年的paper给出了工程性实现,并且附带了详细的伪代码,开始被大规模应用。
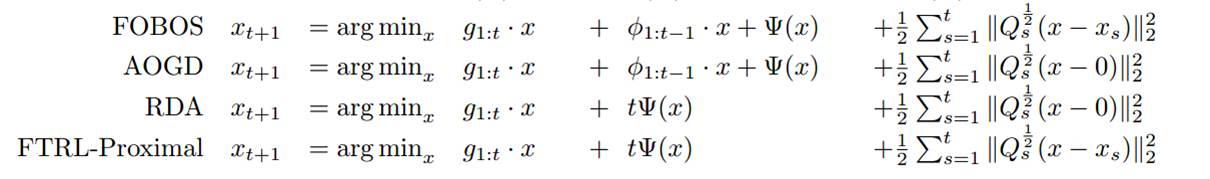

1)Poisson Inclusion:对某一维度特征所来的训练样本,以p的概率接受并更新模型;
2. 浮点数重新编码
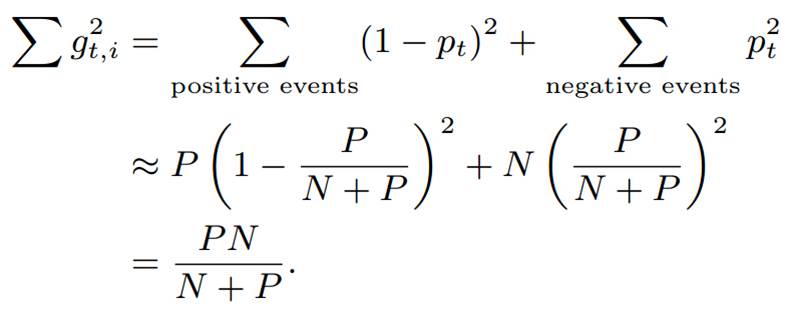

[1] J. Langford, L. Li, and T. Zhang. Sparse online learning via truncated gradient.JMLR, 10, 2009. (截断梯度的paper)
[2] H. B. McMahan. Follow-the-regularized-leader and mirror descent: Equivalence theorems and L1 regularization. In AISTATS, 2011 (FOBOS、RDA、FTRL等各种方法对比的paper)
[3] L. Xiao. Dual averaging method for regularized stochastic learning and online optimization. In NIPS, 2009 (RDA方法)
[4] J. Duchi and Y. Singer. Efficient learning using forward-backward splitting. In Advances in Neural Information Processing Systems 22, pages 495{503. 2009. (FOBOS方法)
[5] H. Brendan McMahan, Gary Holt, D. Sculley, Michael Young, Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, Eugene Davydov, Daniel Golovin, Sharat Chikkerur, Dan Liu, Martin Wattenberg, Arnar Mar Hrafnkelsson, Tom Boulos, Jeremy Kubica, Ad Click Prediction: a View from the Trenches, Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) (2013) (这篇是那篇工程性的paper)
[6] H. Brendan McMahan. A unied analysis of regular-ized dual averaging and composite mirror descent with implicit updates. Submitted, 2011 (FTRL理论发展,regret bound和加入通用正则化项)
[7] H. Brendan McMahan and Matthew Streeter. Adap-tive bound optimization for online convex optimiza-tion. InCOLT, 2010 (开始的那篇理论性paper)
后面附上我在组里分享时做的ppt,感兴趣的可以看看: http://pan.baidu.com/s/1eQvfo6e