基于mtcnn和facenet的实时人脸检测与识别系统开发 - 知乎
- -简介:本文主要介绍了实时人脸检测与识别系统的详细方法. 该系统基于python/opencv2/tensorflow环境,实现了从摄像头读取视频,检测人脸,识别人脸的功能. 本系统代码地址: real time face detection and recognition. 人脸识别是计算机视觉研究领域的一个热点.
1,前言
人脸识别是计算机视觉研究领域的一个热点。目前,在实验室环境下,许多人脸识别已经赶上(超过)人工识别精度(准确率:0.9427~0.9920),比如face++,DeepID3,FaceNet等(详情可以参考: 基于深度学习的人脸识别技术综述)。但是,由于光线,角度,表情,年龄等多种因素,导致人脸识别技术无法在现实生活中广泛应用。本文基于python/opencv/tensorflow环境,采用 FaceNet(LFW:0.9963 )为基础来构建实时人脸检测与识别系统,探索人脸识别系统在现实应用中的难点。下文主要内容如下 :
2,采用opencv2实现从摄像头读取视频帧;
3,对读取的视频帧采用mtcnn方法,检测人脸;
4,采用预训练的facenet对检测的人脸进行embedding,embedding成128维度的特征;
5,对人脸embedding特征采用knn进行分类,实现人脸识别;
6,结果与改进;
7,总结。
 图1-1 人脸检测与识别系统概况
图1-1 人脸检测与识别系统概况 2,opencv2从摄像头读取视频帧
采用opencv2,可以很方便的实现从摄像头读取视频帧。下文代码实现了从摄像头读取视频帧,并转化为灰度图像的功能,更多内容可以参考: Python-OpenCV 图像与视频处理。
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
# Our operations on the frame come here
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Display the resulting frame
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
3,人脸检测
人脸检测方法有许多,比如opencv自带的人脸Haar特征分类器和dlib人脸检测方法等。
对于opencv的人脸检测方法,有点是简单,快速;存在的问题是人脸检测效果不好。如图3-1所示,正面/垂直/光线较好的人脸,该方法可以检测出来,而侧面/歪斜/光线不好的人脸,无法检测。因此,该方法不适合现场应用。对于dlib人脸检测方法 ,效果好于opencv的方法,但是检测力度也难以达到现场应用标准。
本文中,我们采用了基于深度学习方法的mtcnn人脸检测系统( mtcnn: Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Neural Networks)。mtcnn人脸检测方法对自然环境中光线,角度和人脸表情变化更具有鲁棒性,人脸检测效果更好;同时,内存消耗不大,可以实现实时人脸检测。本文中采用mtcnn是基于python和tensorflow的实现(代码来自于 davidsandberg,caffe实现代码参见: kpzhang93)。mtcnn检测出人脸后,对人脸进行剪切并resize为(96,96,3)作为facenet输入,如图3-3所示。
如图3-2所示,mtcnn方法成功检测出所有人脸。
下文代码采用opencv2的haarcascade_frontalface_alt2实现人脸检测。
%%time
#图片人脸检测
import cv2
import sys
# Get user supplied values
imagePath = "./multi_faces.jpg"
# Create the haar cascade
faceCascade = cv2.CascadeClassifier("./haarcascade_frontalface_alt2.xml")
# Read the image
image = cv2.imread(imagePath)#2
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)#3
# Detect faces in the image
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.15,
minNeighbors=5,
minSize=(5,5),
flags = cv2.cv.CV_HAAR_SCALE_IMAGE
) #4
print "Found {0} faces!".format(len(faces))#5
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2) #6
cv2.imshow("Faces found", image)#7
cv2.waitKey(0) #8
 图3-1 opencv2人脸检测方法结果
图3-1 opencv2人脸检测方法结果 图3-2 mtcnn人脸检测方法结果
mtcnn人脸检测部分代码摘录:
#建立mtcnn人脸检测模型,加载参数
print('Creating networks and loading parameters')
gpu_memory_fraction=1.0
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = detect_face.create_mtcnn(sess, './davidsandberg_facenet-master/data/')
bounding_boxes, _ = detect_face.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
nrof_faces = bounding_boxes.shape[0]#人脸数目
print('找到人脸数目为:{}'.format(nrof_faces))
crop_faces=[]
for face_position in bounding_boxes:
face_position=face_position.astype(int)
print(face_position[0:4])
cv2.rectangle(img_color, (face_position[0], face_position[1]), (face_position[2], face_position[3]), (0, 255, 0), 2)
crop=img_color[face_position[1]:face_position[3],
face_position[0]:face_position[2],]
crop = cv2.resize(crop, (96, 96), interpolation=cv2.INTER_CUBIC )
print(crop.shape)
crop_faces.append(crop)
plt.imshow(crop)
plt.show()
plt.imshow(img_color)
plt.show()
 图3-3 剪切人脸区域
图3-3 剪切人脸区域 4,facenet embedding
Facenet是谷歌研发的人脸识别系统,该系统是基于百万级人脸数据训练的深度卷积神经网络,可以将人脸图像embedding(映射)成128维度的特征向量。以该向量为特征,采用knn或者svm等机器学习方法实现人脸识别。Facenet在LFW数据集上识别准确率为0.9963,详情可以参见: 谷歌人脸识别系统FaceNet解析。本文采用的是 davidsandberg基于FaceScrub and CASIA-WebFace数据集预训练的Facenet模型,LFW测试集准确率为0.98。下文代码实现了恢复预训练facenet模型和使用模型进行embedding,应用代码参考了 yobiface实现的代码。
#建立facenet embedding模型
print('建立facenet embedding模型')
tf.Graph().as_default()
sess = tf.Session()
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,
image_size,
image_size, 3), name='input')
phase_train_placeholder = tf.placeholder(tf.bool, name='phase_train')
embeddings = network.inference(images_placeholder, pool_type,
use_lrn,
1.0,
phase_train=phase_train_placeholder)
ema = tf.train.ExponentialMovingAverage(1.0)
saver = tf.train.Saver(ema.variables_to_restore())
#ckpt = tf.train.get_checkpoint_state(os.path.expanduser(model_dir))
#saver.restore(sess, ckpt.model_checkpoint_path)
model_checkpoint_path='./model-20160506.ckpt-500000'
#ckpt = tf.train.get_checkpoint_state(os.path.expanduser(model_dir))
#model_checkpoint_path='model-20160506.ckpt-500000'
#saver.restore(sess, ckpt.model_checkpoint_path)
saver.restore(sess, model_checkpoint_path)
print('facenet embedding模型建立完毕')
######省略部分代码
emb_data = sess.run([embeddings],
feed_dict={images_placeholder: face_data, phase_train_placeholder: False })[0]
5,人脸识别
对人脸进行embedding后,得到128维度的特征向量 。以该特征向量为基础,可以采用任何机器学习的方法进行分类和识别。本文中,选取了knn(k-NearestNeighbor)方法(你可以换其它任何分类方法,比如svm或者神经网络方法等)。本文中,采用了sklearn库实现knn模型的训练和预测。
首先,需要训练分类器。训练数据为:类别1:目标人脸1;类别2:目标人脸2...,类别n:其他人脸。本代码中,类别1:我的人脸数据(经过人脸检测和embedding,共98个样本);类别2:其它人脸(采用lfw数据集随机选取的人脸数据,共69个样本)。训练代码如下:
#训练KNN分类
from sklearn import metrics
from sklearn.externals import joblib
X_train, X_test, y_train, y_test = train_test_split(X, train_y, test_size=.3, random_state=42)
# KNN Classifier
def knn_classifier(train_x, train_y):
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(train_x, train_y)
return model
classifiers = knn_classifier
model = classifiers(X_train,y_train)
predict = model.predict(X_test)
accuracy = metrics.accuracy_score(y_test, predict)
print ('accuracy: %.2f%%' % (100 * accuracy) )
#保存模型
joblib.dump(model, 'knn.model')
训练后的分类器即可对人脸进行识别,代码如下:
model = joblib.load('knn.model')
predict = model.predict(X_test)
print ('识别结果为:{}'.format(predict))
6,结果与改进
6.1 运行结果
如图6-1所示,系统可以从摄像头获取视频,实时检测出人脸,并识别。系统不管对正面人脸,还是歪斜的人脸,以及不同表情的人脸均能有效的检测并识别,具有一定的鲁棒性。




6.2 改进
本系统虽然采用了高准确率的人脸检测(mtcnn)与识别方法(facenet),可以实现实时人脸检测与识别,具有一定的鲁棒性。但是,如果要在现实生活中应用本系统,还需要做许多改进。
6.2.1 人脸检测
mtcnn人脸检测方法精确度很高,但是依然存在一些问题。
一,该方法无法识别倾斜度大于45度的人脸和侧面的人脸。如图6-2所示,当倾斜度大于45度后,系统无法检测出人脸。该问题原因可能是mtcnn网络训练数据中没有大倾斜度的人脸照片。解决的方法可以有两种:(1)对训练照片进行旋转,在但前mtcnn网络的基础上进行finetune;(2)在视频帧读取后,旋转不同角度后,分别传入mtcnn进行人脸检测。前一种方法需要处理大量的人脸数据;后一种方法会影响实时检测的速度。

图6-2 难以检测出倾斜度过大的人脸
二,mtcnn人脸检测方法还存在另外的小问题:有时可能会被汪星人欺骗(好吧,汪星人的脸也是脸,该方法很强大,哦也!请忽略)。该问题不影响实际应用。
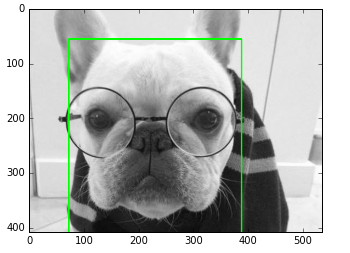 图6-3 检测出潜伏在人类星球的汪星人脸
图6-3 检测出潜伏在人类星球的汪星人脸 6.2.2 人脸识别
目前,基于深度神经网络方法的人脸识别系统在实验环境下准确率很高,已经达到或者超越人类的准确率,但是在现实环境中的准确率仅在60%-70%左右。现实环境中,光线/表情/角度/化妆等多种因素均会影响识别效果,有待研究新方法(参见: 基于深度学习的人脸识别技术综述)。
本系统采用的是 davidsandberg预训练的Facenet网络模型,如果需要更高准确率的facenet模型,可以考虑 openface。
同时,当前系统的识别分类器是基于仅仅167个正负样本训练的knn分类器,测试准确率仅为94%左右。进一步改进可以考虑:(1)采集更多的类别与数量的训练样本训练分类器,实现多个类别的人脸识别; (2)选择其它分类方法(svm/神经网络等)。(3)将分类器训练部分集成,实现实时训练与识别。
6.2.3 其它改进
本系统的核心方法是基于mtcnn和facenet,均是基于深度学习的方法。虽然神经网络模型不算大,但是相对于opencv内置的人脸检测和识别方法来讲内存消耗还是比较大的。本文运行环境为Ubuntu 16.04.1,8G内存,仅能设置为每5帧进行一次检测和识别(不影响实际效果)。可以考虑在不影响深度神经网络方法精确度的情况下,减少内存消耗,实现在移动设备(手机/平板等)运行。
同时,本系统代码采用的是ipython notebook(为了代码结构更加清晰,易读),运行一段时间后会导致内存满,kernel die的问题。
7,总结
本文主要介绍了实时人脸检测与识别系统的详细方法,该系统基于python/opencv2/tensorflow环境,实现了从摄像头读取视频,检测人脸,识别人脸的功能。实现类似功能的代码有 openface,但是,openface核心是基于torch和lua。本人更喜欢python和tensorflow,因此,才有本文的产生。
本系统相对于opencv自带的人脸检测和识别的准确率更高,鲁棒性更好;但距离实际应用,还需要许多改进。同时,实时人脸检测与识别技术还需要许多改进和研究,期待和大家一起探索,谢谢。