三步学会爬动态网站
- - FreeBuf互联网安全新媒体平台*本文原创作者:qingxp9,本文属于FreeBuf原创奖励计划,未经许可禁止转载. 本篇文章仅用于技术讨论,严禁用于任何非法用途. 此外,请尽量通过公开数据进行练习,减缓爬取速度和数量. 在我们写爬虫程序时,难免会碰到一些动态加载的网页,为获取数据制造了困难. 本篇文章我将尝试用非常简短的篇幅来教大家:如何应对动态加载的网页.
*本文原创作者:qingxp9,本文属于FreeBuf原创奖励计划,未经许可禁止转载
本篇文章仅用于技术讨论,严禁用于任何非法用途。此外,请尽量通过公开数据进行练习,减缓爬取速度和数量。
在我们写爬虫程序时,难免会碰到一些动态加载的网页,为获取数据制造了困难。本篇文章我将尝试用非常简短的篇幅来教大家:如何应对动态加载的网页。
以Ruby语言为例,可以在Linux、Mac、Windows等平台上进行实验。
目标:收集目标网站上公开的所有产品型号
所有的产品通过类型进行分类,如下所示:

当点击某个分类后,出现具体的产品信息:

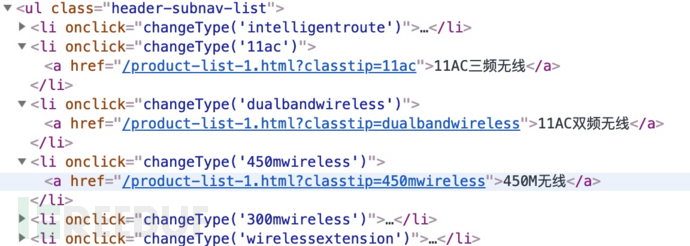
需要注意的是,这部分产品信息是通过解析参数后动态加载的,这是本篇要解决的主要问题:
Nokogiri是一个用于解析HTML, XML, SAX等内容的开源Ruby库,可以通过XPath和CSS选择器语法来操作内容。
安装:
```
apt install ruby
gem install nokogiri
```
通过简单分析,各分类的url位于以下结构中:
```
<ul class="header-subnav-list">
<li>
<a></a>
<</li>
</ul>
```

由于这些内容在网站中是静态的,我们直接使用open-uri打开目标网页,配合Nokogiri来获取各分类的url:
```
#irb是Ruby的交互式shell,
root@bad:~# irb
require 'nokogiri'
require 'open-uri'
#获取目标网站HTML代码
doc=Nokogiri::HTML(open(" http://www.xxxx.com"))
#通过xpath选择器获取目标内容
ar=doc.xpath("//ul[@class='header-subnav-list']//li//a")
href = []
ar.each {|a| href << a["href"]}
```
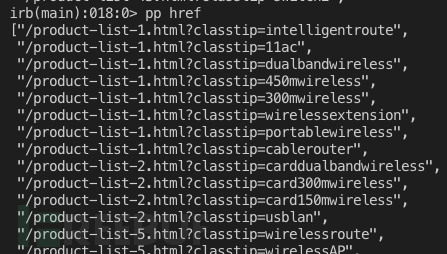
查看一下获取的列表:
前面提到,分类里边的产品列表由Javascript动态加载,这时候我们可以使用Watir来获取动态内容。
Waitr是一个用于自动化测试的开源Ruby库。Watir将使用跟真人一样的浏览器交互方式来点击链接,填写表单和验证文本。可以配合Chrome、Firefox、IE、Safari、Edge等。
以Chrome为例,除了安装Waitr外,还需要安装chromedriver:
```
gem install watir
apt install chromium-driver
#其他平台可参考 https://github.com/SeleniumHQ/selenium/wiki/ChromeDriver
```
当我们使用Watir访问目标网站时,会出现一个受代码控制的Chrome窗口。(不要用鼠标去操作或者关掉它!!)
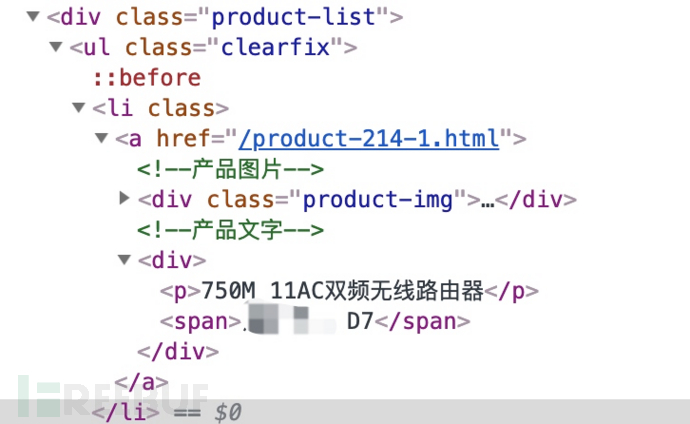
由于浏览器加载内容需要一些时间,所以我们适当增加一些休眠时间确保内容加载完成。通过Watir获取了每个页面的内容后,再次通过nokogiri进行获取即可。
```
#接着上面的代码
require 'watir'
browser = Watir::Browser.new
browser.goto " http://www.xxxx.com#{href[2]}"
sleep(1)
doc=Nokogiri::HTML(browser.html)
ar=doc.xpath("//div[@class='product-list']//ul//li//a//div//span")
ar.each {|a| p a.content if a.content != '' }
```
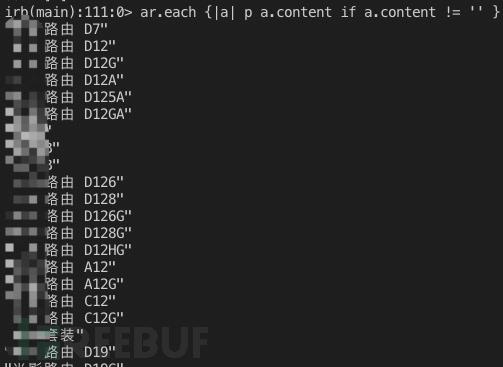
可以适当输出一些中间内容,方便在出错时调试。
(完)
*本文原创作者:qingxp9,本文属于FreeBuf原创奖励计划,未经许可禁止转载