谢 @henryWang 邀。(不知道为啥我又 at 不上人。被知乎针对了?)
刚看完文章。效果就不比了,屠榜了没什么好说的。
1、监督信号的提取
BERT 有两个目标,Masked Language Model 和 Next Sentence Prediction,前者用于提取单词之间的关系,后者用来提取句子之间的关系。前者带来的问题在于, 训练时引入 [MASK] token 使得 train/test 不一致,于是又用了很多乱七八糟的方法来补救(以一定概率保留原词,一定概率换成别的单词等等)。
新的目标 Permutation Language Model 就没这个问题。PLM 的大意是把输入的句子链式分解一下,然后用最大似然来训练。只不过这里的分解不是通常语言模型的 left-to-right factorization,而是以任意顺序排列进行 factorization,最后求期望。当然,具体实现的时候用采样代替期望,随机选取一个具体排列进行计算,例如将 1 -> 2 -> 3 -> 4 调整为 2 -> 4 -> 3 -> 1,然后优化样本似然  。shuffle 过后(代码实现中调整 attention mask 即可,不必 shuffle 输入)预测单词 3 时可以观测到单词 2 和 4 的信息,实现双向的信息提取。另外,Grover 训练时也会 shuffle metadata,有一定的相似之处,可能是大势所趋吧。这种乱序的输入很适合完形填空的场景(单讲完形填空的话其实 BERT 更适合,但对于完整的输入文本 BERT 就有些货不对板了)。
。shuffle 过后(代码实现中调整 attention mask 即可,不必 shuffle 输入)预测单词 3 时可以观测到单词 2 和 4 的信息,实现双向的信息提取。另外,Grover 训练时也会 shuffle metadata,有一定的相似之处,可能是大势所趋吧。这种乱序的输入很适合完形填空的场景(单讲完形填空的话其实 BERT 更适合,但对于完整的输入文本 BERT 就有些货不对板了)。
BERT 的另一个训练目标 NSP 对于提取句间关系的任务很有帮助,甚至有后续研究说即便是单句的任务也可以构建出一个辅助句进而获益(如 "BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence");而 XLNet 的实验发现 PLM 和 NSP 不兼容,加入 NSP 对大多数任务都是有害的。两个模型的优点不能融合,着实有些遗憾。
题外话, Bert时代的创新:Bert在NLP各领域的应用进展文末对 BERT 的适用场景有很好的总结,推荐一读。
GPT 等普通语言模型的训练目标是 Causal Language Model,BERT 的训练目标是 MLM,在此基础上通过改进 mask 又有了 Whole Word Masking/N-gram Masking/ERNIE 等目标。把 Transformer 的 encoder 和 decoder 都用上可以得到 MASS,双语平行语料预训练可以用 TLM。如今又多了一个 PLM 的目标,很高兴看到这样的进步,期待以后能有更多的手段从语料里无监督地提取到更多的知识。但不管怎么说,这都是土豪的游戏了,一般人玩不起。
PLM 可能带来的另一个潜在收益是, XLNet 应该具有一定的文本生成能力,从这一点上讲它和 UNILM 更像。理解和生成相统一,可能也是未来的趋势之一。
XLNet 在 GLUE benchmark 的几乎所有任务上都比先前最优水平得到了提升,但是 CoLA 这一项的表现似乎不尽如人意。 CoLA 是判断一个句子是否在语法上合理的,是不是说明这个任务较为依赖单词顺序?
XLNet 的提升来源主要有两部分,一是来源于 Transformer-XL 对更长的上文信息的提取,二是来源于 PLM 训练目标与下游任务的一致性(没有 train-test skewness)。Table 6 中的 ablation study 发现,第一点带来的提升相当明显(对比 row 2 和 row 1),使得 DAE + Transformer-XL 在 RACE 和 SQUAD 上明显超过了 BERT-Base(MNLI 和 SST-2 上没有明显变化,是因为这两个任务没有长程依赖)。由此可见 BERT 处理长文本其实还是有些力不从心,而 Transformer-XL 则把 stateful RNN 的思想在 Transformer 上复活了。第二点的提升效果也很明显,并且所有任务都能从中受益。
XLNet 计算量和激活值比 BERT 更大,有可能接近 BERT 的 2 倍(因为 XLNet 要给每个位置维护两套隐状态,一套是包含当前 token 信息的 content stream h,另一套是不包含当前 token 信息的 query stream g。此外还有前一个 segment 的缓存)。细节详见论文 2.3 节 Two-Stream Self-Attention 的相关描述,大意如下图:
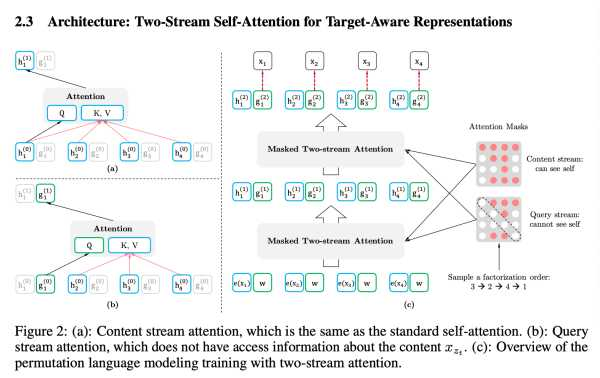
于是, 即便是对于 left-to-right 这种特殊情形的分解,XLNet 可能也比 GPT 更强:假设要预测单词 4,GPT 的输入和输出是错位一个时间步的,即读入 1,2,3,然后在 3 的位置预测 4;而 XLNet 的输入和输出时间步数是相同的(这一点类似于 BERT),输入 1,2,3,4 并在 4 的位置预测 4。当然,XLNet 不会读取第 4 个时间步的单词(否则有信息泄露),仅仅利用位置 4 的 position embedding,告诉模型现在想要预测第 4 个位置。XLNet 在第 4 步的输入向量是一个 query vector(在最底层是一个可学习的参数w,在中间层是 query stream g)来对 1,2,3 各个时间步进行 attend,和 GPT 相比多一个时间步的输入,多一轮 query & attend 的过程,因此有可能更强。
文章中还说, XLNet-Large 依然是欠拟合训练数据的,但是再训练对于 downstream task 已经没有用了。这一点有些奇怪,可以进一步探究的是,存在于这些数据中、但是对下游任务没有帮助的到底是什么信息?也许是跟语言生成(而非判别)有关的?也许我们应该寻找新的、能够从这些信息中获益的下游任务——也许是比 GLUE benchmark 更难,但又比长篇文本生成更简单的任务,例如 DecaNLP?今天 GLUE 已经接近解决,这些任务也许可以作为更好的 NLP 领域风向标。
2、数据规模
XLNet-Base 和 Bert-Base 数据集是一样的,效果也有比较明显的提高,说明 XLNet-Base 确实更好。
但是 XLNet-Large 除了放大模型之外还用了更多的数据,在 BERT 所用的 BooksCorpus & English Wikipedia 的基础上还增加了 Giga5, ClueWeb 2012-B, and Common Crawl,扩大到了原先的 10 倍。不知道 BERT-Large 在这样的数据上表现如何?预期应该会变好(@霍华德 在 这个回答里也说了腾讯 AI Lab 用 200G 语料训出的 BERT-Large 又变强了一大截),但应该不会超过 XLNet。
3、优化方法
XLNet-Large 用 512 TPU v3 chips 训了 2.5 天,而 BERT-Large 用 64 TPU chips 训了 4 天。也就是说,训练 XLNet 所需的浮点运算次数大约是 Bert 5 倍。再考虑到 XLNet 计算量和激活值大约是 BERT 的 2 倍(我真的很好奇他们是怎么把这个模型塞进 TPU 的。TPU v3 每个 core 也只有 16G HBM 啊,TPU 上的 XLA 优化这么强的吗?),语料规模是 BERT-Large 的 10 倍,如果不考虑代码实现的效率差异的话,可以近似认为 XLNet 的训练效率是 BERT 的 4 倍。
训练效率的提高可能有两个来源:
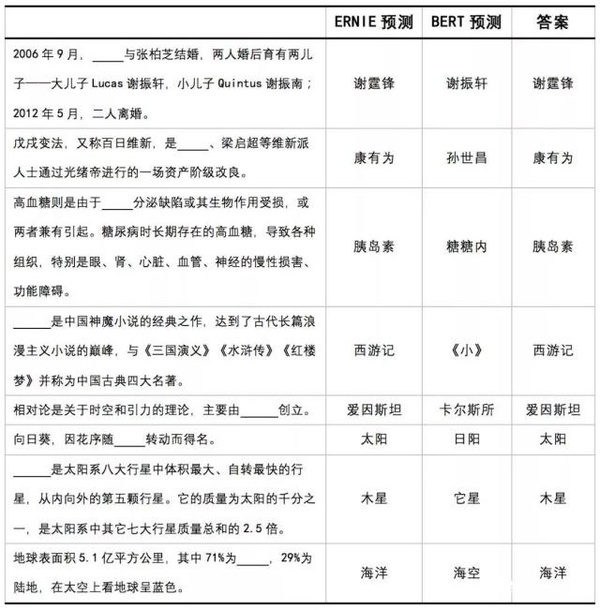
- 其一是对多个预测目标之间的关系的建模。文中有一个例子,假如输入是 New York is a city,想要预测的目标是 New York,那么 BERT 在预测 New 和 York 时是互相独立的,即优化 P(New|is a city)P(York|is a city);而 XLNet 则是优化 P(New|is a city)P(York|New, is a city)。这种单词间依赖的建模使得 XLNet 的预训练更有效率。BERT 不建模多个预测之间的相互依赖可能导致重复预测等问题(可以参考百度 ERNIE 给出的一些 bad case,如下图中的“糖糖内”和“日阳”),于是前段时间谷歌给 BERT 发布了一个叫 Whole Word Masking 的补丁。不过从原理上讲 wwm-MLM 依然不如 PLM,因为 wwm-MLM 还是没有真正建模多个目标词之间的依赖,只是让模型在这种情况下多训练来缓解。
- 其二是 XLNet 理论上可以训练输入序列所有的 token,而 BERT 只能训练 15% 被掩掉的 token。虽然实际操作中 XLNet 只训练了 permutation 最后 1/K(K=6 或 7)的 token,因为这些 token 的上下文最长,更有利于模型提取上下文信息。不过我觉得可以在训练初期使用大部分 token,仅当训练接近结束时切换成只训练上下文最长的 1/K,以便进一步提高样本利用率和训练效率。GPT 可以训练全部 token,MASS 可以训练 50% token,XLNet 理论上也能训练较大比例的 token(虽然实际只训了 1/K,但如果精心设计 permutation 的形式和训练过程,把 K 从 6 降到 2 或 3 不算离谱),BERT 这个废柴怎么就只能训 15% 的 token 呢?
4、彩蛋:
GPT-2 是如何看待 XLNet 的:

5、吃瓜群众可以干什么
其实更大规模的模型出现对大家来说可能反而是一件好事,因为:
- 模型越大,越多人跑不起,这样大家审稿时也就不会太苛责 sota,转而关注研究本身的价值而非实验结果。这个道理就好比,假如一项研究只有 10% 的人能做得起,他们可能会借着手里的资源优势抓紧灌水;但是如果门槛抬高到了只有 0.1% 的人能做得起的程度,新的 9.9% 被资源门槛筛下来的人就会跟一开始被筛的 90% 的人回到同一阵营中,开始互相理解。
- 这些工作也带来了新的机会。对于硬件厂商,怎么做专用芯片?TPU 现在还是一家独大,GPU 没个 V100 好像也要脱离时代了。对于后端框架,如何做内存优化?如果这些巨无霸模型大多数人都跑不起来(暂且认为大多数人拥有的单卡显存 <=16G),必然不利于整个行业的发展。对于业界,如何进行模型压缩?很多文章都指出 BERT 有很多冗余参数(例如 Are Sixteen Heads Really Better than One? 指出很多层只保留一个 attention head 就够了),怎么把这类模型的体积和延迟都减小到适合部署的程度?
来源:知乎 www.zhihu.com
作者:
知乎用户(登录查看详情)
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。
点击下载
此问题还有
28 个回答,查看全部。
延伸阅读:
如何评价 MIT Deep Learning 这本书?
为何DL在NLP效果并不是特别好但是Stanford却开设cs224d这门课?