一、废话:先讲述一个k8s重要概念,我觉得这个概念是整个k8s集群实现微服务的最核心的概念
概念:Service
Service定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了一个统一的服务访问入口以及服务代理和发现机制,用户不需要了解后台Pod是如何运行。只需要将一组跑同一服务的pod池化成一个service,k8s集群会自动给这个service分配整个集群唯一ip和端口号(这个端口号自己在yaml文件中定义),一个service定义了访问pod的方式,就像单个固定的IP地址和与其相对应的DNS名之间的关系。
Service其实就是我们经常提起的微服务架构中的一个"微服务",每个微服务后端负载均衡多个业务pod,由版本控制(deployment)控制pod数量,保证服务的高可靠性与冗余性。最终我们的系统由多个提供不同业务能力而又彼此独立的微服务单元所组成,服务之间通过TCP/IP(k8s集群分配的整个集群唯一的)进行通信,从而形成了我们强大而又灵活的弹性网络,拥有了强大的分布式能力、弹性扩展能力、容错能力;
理解service这个概念之后,我们跑去service后端看看具体是怎么实现的?
需求:有一个问题就是现在我的业务分配在多个Pod上,那么如果我某个Pod死掉岂不是业务完蛋了,当然也会有人说Pod死掉没问题啊,K8S自身机制Deployment和Controller会动态的创建和销毁Pod来保证应用的整体稳定性,那这时候还会有问题,那就是每个Pod产生的IP都是动态的,那所以说重新启动了我对外访问的IP岂不是要变了,别急,下面我们来解决下这个问题。
可以通过Service来解决如上所遇到的问题
二、Service是kubernetes最核心的概念,通过创建Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求进行负载分发到后端的各个容器应用上。至于如何负载分发,我们不用去担心,k8s自己搞定。
简单来说Service就是一个把所有Pod统一成一个组,然后对外提供固定一个IP,具体是哪些Pod,可以通过之前介绍到的Label标签来进行设置,假设一个pod死掉,副本控制器在生成一个pod,这是pod ip肯定会变,但是我们不去关心你pod ip是多少,我们只知道service ip 没变就好了,因为新的pod 早就加入到我的service中了,各个服务之间通信是通过service 唯一ip来通信的。
上述所有操作,为什么实现了所谓的“”微服务”,举个大家都懂的例子;
一套简单的架构,nginx做反向代理,后端web为8个tomcat实例,在k8s集群中怎么实现呢,我只需要跑8个pod,每个pod运行tomcat容器,service池化这8个pod,而且副本控制会自动动态控制pod数量,少于8个他会创建到8个,多余8个会自动删除到8个。而且我们访问service ip,k8s中的kube-proxy会自动负载均衡后端的8个pod,这一套服务集群内部访问,只需要一个service ip 和端口号就可以;同理,redis集群,同样可以这样实现,每个service相当于微服务,各个服务之间灵活通信。
废话不多说,咱们直接实操演示
三、 创建副本控制资源名为nginx-deployment,运行两个pod,每个pod运行一个nginx容器,容器端口开放80.
[root@master yaml]# cat nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx 就是说哪些Pod被Service池化是根据Label标签来的,此行nginx字样,后面我们创建Service会用到
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
kubectl create -f nginx.yaml
deployment.apps/nginx-deployment created

创建Service 池化刚才的两个nginx pod
[root@master yaml]# cat nginx-svc.yml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
type: NodePort
selector:
app: nginx
ports:
- protocol: TCP
port: 8080 这个资源(svc)开放的端口
targetPort: 80
selector选择之前Label标签为nginx的Pod作为Service池化的对象,
最后说的是把Service的8080端口映射到Pod的80端口。
kubectl apply -f nginx-svc.yml
service/nginx-svc created

创建完成之后nginx-svc会分配到一个cluster-ip,可以通过该ip访问后端nginx业务。
那它是怎么实现的呢?答案是通过iptables实现的地址转换和端口转换,自己可以去研究

那这时候有人说了,还是不能外网访问啊,别急下面我们来进行外网地址访问设置。在实际生产环境中,对Service的访问可能会有两种来源:Kubernetes集群内部的程序(Pod)和Kubernetes集群外部,为了满足上述的场景,Kubernetes service有以下三种类型:
1.ClusterIP:提供一个集群内部的虚拟IP(与Pod不在同一网段),以供集群内部的pod之间通信使用。
2.NodePort:在每个Node上打开一个随机端口并且每个Node的端口都是一样的,通过:NodePort的方式Kubernetes集群外部的程序可以访问Service。
3.LoadBalancer:利用Cloud Provider特有的Load Balancer对外提供服务,Cloud Provider负责将Load Balancer的流量导向Service
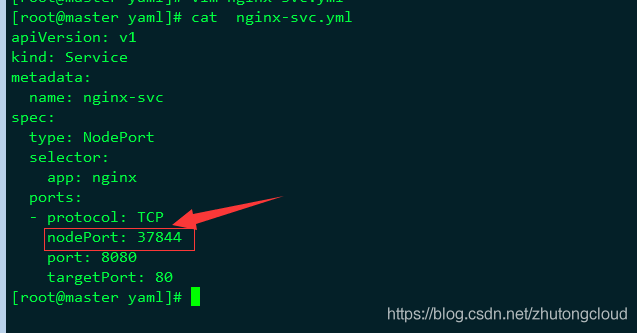
本篇文章我着重讲下第二种方式,也就是NodePort方式,修改nginx-svc.yml文件,也就是刚才前面创建的Service文件,相信细心的同学会发现在之前截图的时候已经做好了NodePort,因为我的环境已经配置好了所以这样就不在截图了,配置很简单,可以网上看下截图,就是添加一个type:NodePort,然后重新创建下nginx-svc,命令的话和创建的命令一样,我们来看看创建完事的结果。

如果刚开始你没有设置NodePort这个type的时候在端口那只会显示一个8080端口,而设置了之后会看到多了一个端口也就是37884,那8080就是是cluster-ip监听的端口,那37844就是在node节点上新起的一个端口(K8s会从30000~32767中分配一个可用的端口),只用于端口转发,转发到service的端口。
用户访问服务,每个节点都会监听这个端口,并转发给Service,service负载均衡调度后端pod,也就是防止说一个节点挂了影响访问>。
说的再通俗一点,集群内部可以直接通过service的ip+端口访问,而nodeport就是为了外网访问服务,给node开了一个端口,转发到service的ip+端口。
可能有人会问了,说这里的Service可不可以固定?当时可以了,可以在Service nginx-svc.yml文件里面添加一个nodeport。
当然,这个访问依然是负载均衡的!