Python3连接MySQL数据库之mysql-client - Ethan_zhang - 博客园
- -要想使 python 可以操作 mysql 就需要 MySQLdb 驱动,它是 python 操作 mysql 必不可少的模块. 在此站点下载mysqlclient安装包:https://www.lfd.uci.edu/~gohlke/pythonlibs/# 进行本地安装. 以下是从这个网站上面检索到的mysqlclient的所有版本.
MySQL作为一种关系型数据库,已被广泛应用到互联网中的诸多项目中。今天我们来讨论下事务的提交过程。
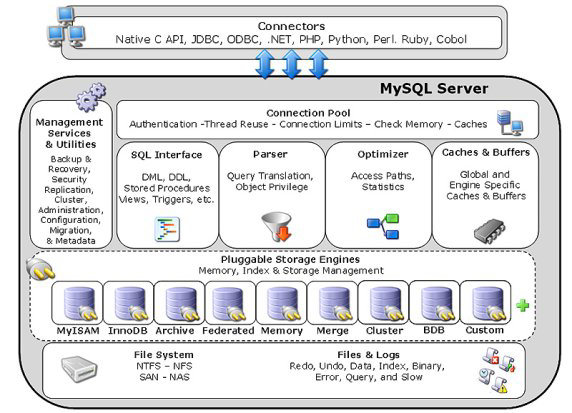
MySQL体系结构
由于mysql插件式存储架构,导致开启binlog后,事务提交实质是二阶段提交,通过两阶段提交,来保证存储引擎和二进制日志的一致。
本文仅讨论binlog未打卡状态下的提交流程,后续会讨论打开binlog选项后的提交逻辑。
测试环境
OS:WIN7
ENGINE:
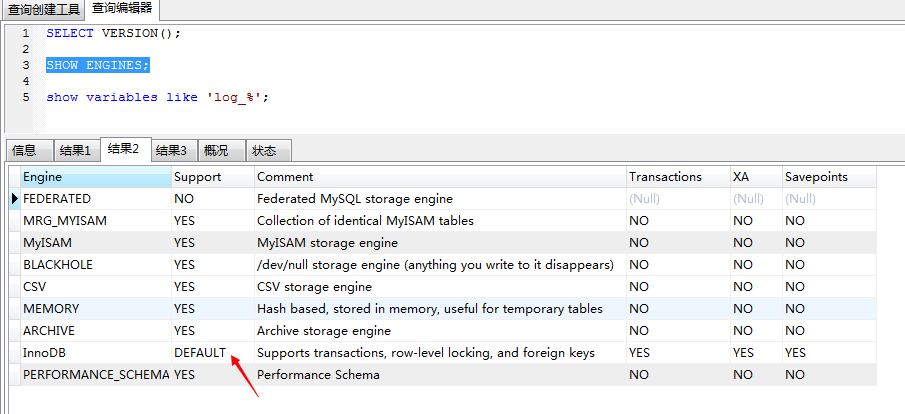
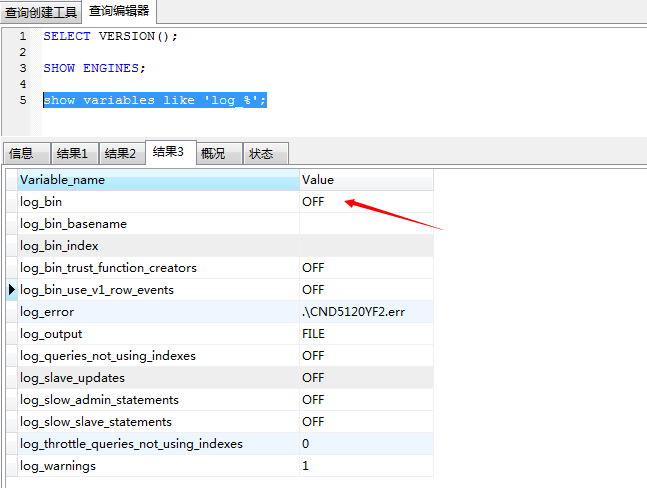
bin-log:off
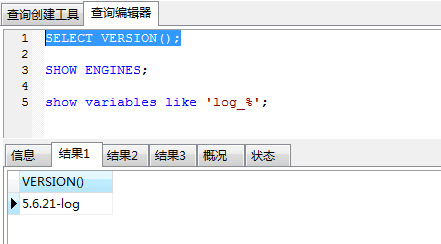
DB:
测试条件
set autocommit=0;
-- ---------------------------- -- Table structurefor`user`-- ----------------------------DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `id`int(20) NOT NULL, `account` varchar(20) NOT NULL, `name` varchar(20) NOT NULL, PRIMARY KEY (`id`), KEY `id` (`id`) USING BTREE, KEY `name` (`name`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
测试语句
insert into user values(1, 'sanzhang', '张三');
commit;
一般常用的DML:Data Manipulation Language 数据操纵语言,对表的数据进行操作,(insert、update、delete )语句 和 DCL:Data Control Language 数据库控制语言
(创建用户、删除用户、授权、取消授权)语句 和 DDL:Data Definition Language 数据库定义语言,对数据库内部的对象进行创建、删除、修改的操语句
,均是使用MySQL提供的公共接口mysql_execute_command,来执行相应的SQL语句。我们来分析下mysql_execute_command接口执行的流程:
mysql_execute_command
{switch(command)
{caseSQLCOM_INSERT:
mysql_insert();break;caseSQLCOM_UPDATE:
mysql_update();break;caseSQLCOM_DELETE:
mysql_delete();break;
......
}ifthd->is_error()//语句执行错误trans_rollback_stmt(thd);elsetrans_commit_stmt(thd);
}
从上述流程中,可以看到执行任何语句,最后都会执行trans_rollback_stmt或者trans_commit_stmt,这两个分别是语句回滚和语句提交。
语句提交,对于非自动模式下,主要有两个作用:
1、释放autoinc锁,这个锁主要用来处理多个事务互斥的获取自增序列。因此,无论最后执行的是语句提交还是语句回滚,该资源都是需要立马释放掉的。
2、标识语句在事务中的位置,方便语句级回滚。执行commit后,可以进入commit流程。
现在看下具体的事务提交流程:
mysql_execute_command
trans_commit_stmt
ha_commit_trans(thd, FALSE);
{
TC_LOG_DUMMY:ha_commit_low
ha_commit_low()
innobase_commit
{//获取innodb层对应的事务结构trx=check_trx_exists(thd);if(单个语句,且非自动提交)
{//释放自增列占用的autoinc锁资源lock_unlock_table_autoinc(trx);//标识sql语句在事务中的位置,方便语句级回滚trx_mark_sql_stat_end(trx);
}else事务提交
{
innobase_commit_low()
{
trx_commit_for_mysql();<span style="color: #ff0000;">trx_commit</span>(trx);
}//确定事务对应的redo日志是否落盘【根据flush_log_at_trx_commit参数,确定redo日志落盘方式】trx_commit_complete_for_mysql(trx);
trx_flush_log_if_needed_low(trx->commit_lsn);
log_write_up_to(lsn);
}
}
}trx_commit
trx_commit_low
{
trx_write_serialisation_history
{
trx_undo_update_cleanup//供purge线程处理,清理回滚页}
trx_commit_in_memory
{
lock_trx_release_locks//释放锁资源trx_flush_log_if_needed(lsn)//刷日志trx_roll_savepoints_free//释放savepoints}
}
MySQL是通过WAL方式,来保证数据库事务的一致性和持久性,即ACID特性中的C(consistent)和D(durability)。
WAL(Write-Ahead Logging)是一种实现事务日志的标准方法,具体而言就是:
1、修改记录前,一定要先写日志;
2、事务提交过程中,一定要保证日志先落盘,才能算事务提交完成。
通过WAL方式,在保证事务特性的情况下,可以提高数据库的性能。
从上述流程可以看出,提交过程中,主要做了4件事情,
1、清理undo段信息,对于innodb存储引擎的更新操作来说,undo段需要purge,这里的purge主要职能是,真正删除物理记录。在执行delete或update操作时,实际旧记录没有真正删除,只是在记录上打了一个标记,而是在事务提交后,purge线程真正删除,释放物理页空间。因此,提交过程中会将undo信息加入purge列表,供purge线程处理。
2、释放锁资源,mysql通过锁互斥机制保证不同事务不同时操作一条记录,事务执行后才会真正释放所有锁资源,并唤醒等待其锁资源的其他事务;
3、刷redo日志,前面我们说到,mysql实现事务一致性和持久性的机制。通过redo日志落盘操作,保证了即使修改的数据页没有即使更新到磁盘,只要日志是完成了,就能保证数据库的完整性和一致性;
4、清理保存点列表,每个语句实际都会有一个savepoint(保存点),保存点作用是为了可以回滚到事务的任何一个语句执行前的状态,由于事务都已经提交了,所以保存点列表可以被清理了。
关于mysql的锁机制,purge原理,redo日志,undo段等内容,其实都是数据库的核心内容。
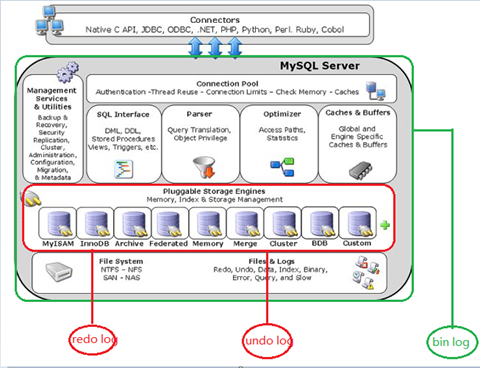
MySQL 本身不提供事务支持,而是开放了存储引擎接口,由具体的存储引擎来实现,具体来说支持 MySQL 事务的存储引擎就是 InnoDB。
存储引擎实现事务的通用方式是基于 redo log 和 undo log。
简单来说,redo log 记录事务修改后的数据, undo log 记录事务前的原始数据。
所以当一个事务执行时实际发生过程简化描述如下:
在 MySQL 执行事务过程中如果因故障中断,可以通过 redo log 来重做事务或通过 undo log 来回滚,确保了数据的一致性。
这些都是由事务性存储引擎来完成的,但 binlog 不在事务存储引擎范围内,而是由 MySQL Server 来记录的。
那么就必须保证 binlog 数据和 redo log 之间的一致性,所以开启了 binlog 后实际的事务执行就多了一步,如下:
这样的话,只要 binlog 没写成功,整个事务是需要回滚的,而 binlog 写成功后即使 MySQL Crash 了都可以恢复事务并完成提交。
要做到这点,就需要把 binlog 和事务关联起来,而只有保证了 binlog 和事务数据的一致性,才能保证主从数据的一致性。
所以 binlog 的写入过程不得不嵌入到纯粹的事务存储引擎执行过程中,并以内部分布式事务(xa 事务)的方式完成两阶段提交。
参考
1、《高性能MySQL》