Python3连接MySQL数据库之mysql-client - Ethan_zhang - 博客园
- -要想使 python 可以操作 mysql 就需要 MySQLdb 驱动,它是 python 操作 mysql 必不可少的模块. 在此站点下载mysqlclient安装包:https://www.lfd.uci.edu/~gohlke/pythonlibs/# 进行本地安装. 以下是从这个网站上面检索到的mysqlclient的所有版本.
上一篇文章我们介绍了在关闭binlog的情况下,事务提交的大概流程。之所以关闭binlog,是因为开启binlog后事务提交流程会变成两阶段提交,这里的两阶段提交并不涉及分布式事务,当然mysql把它称之为内部xa事务(Distributed Transactions),与之对应的还有一个外部xa事务。
这里所谓的两阶段提交分别是prepare阶段和commit阶段。
内部xa事务主要是mysql内部为了保证binlog与redo log之间数据的一致性而存在的,这也是由其架构决定的(binlog在mysql层,而redo log 在存储引擎层);
外部xa事务则是指支持多实例分布式事务,这个才算是真正的分布式事务。
既然是xa事务,必然涉及到两阶段提交,对于内部xa而言,同样存在着提交的两个阶段。
下文会结合源码详细解读内部xa的两阶段提交过程,以及各种情况下,mysqld crash后,mysql如何恢复来保证事务的一致性。
测试环境
OS:WIN7
ENGINE:
DB:
配置文件参数:
log-bin=D:\mysql\log\5-6-21\mysql-bin binlog_format=ROW set autocommit=0; innodb_support_xa=1sync_binlog=1; innodb_flush_log_at_trx_commit=1;
【innodb_flush_log_at_trx_commit=1,sync_binlog=1
不同的模式区别在于,写文件调用write和落盘fsync调用的频率不同,所导致的后果是mysqld 或 os crash后,不严格的设置可能会丢失事务的更新。
双一模式是最严格的模式,这种设置情况下,单机在任何情况下不会丢失事务更新。】
测试条件
set autocommit=0;
-- ---------------------------- -- Table structurefor`user`-- ----------------------------DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `id`int(20) NOT NULL, `account` varchar(20) NOT NULL, `name` varchar(20) NOT NULL, PRIMARY KEY (`id`), KEY `id` (`id`) USING BTREE, KEY `name` (`name`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
测试语句
insert into user values(1, 'sanzhang', '张三');
commit;
prepare阶段:
1.设置undo state=TRX_UNDO_PREPARED;//trx_undo_set_state_at_prepare调用
2.刷事务更新产生的redo日志;【步骤1产生的redo日志也会刷入】
MYSQL_BIN_LOG::prepare
ha_prepare_low
{
engine:
binlog_prepare
innobase_xa_prepare
mysql:
trx_prepare_for_mysql
{1.trx_undo_set_state_at_prepare//设置undo段的标记为TRX_UNDO_PREPARED2.设置事务状态为TRX_STATE_PREPARED3.trx_flush_log_if_needed//将产生的redolog刷入磁盘}
}
commit阶段:
1.将事务产生的binlog写入文件,刷入磁盘;
2.设置undo页的状态,置为TRX_UNDO_TO_FREE或TRX_UNDO_TO_PURGE; // trx_undo_set_state_at_finish调用
3.记录事务对应的binlog偏移,写入系统表空间; //trx_sys_update_mysql_binlog_offset调用
MYSQL_BIN_LOG::commit
ordered_commit
{1.FLUSH_STAGE
flush_cache_to_file//刷binlog2.SYNC_STAGE
sync_binlog_file//Call fsync() to sync the file to disk.3.COMMIT_STAGE
ha_commit_low
{
binlog_commit
innobase_commit
trx_commit(trx)
{
trx_write_serialisation_history(trx, mtr);//更新binlog位点,设置undo状态trx_commit_in_memory(trx, lsn);//释放锁资源,清理保存点列表,清理回滚段}
}
}
在任何情况下(机器掉电)mysqld crash或者os crash,MySQL仍然能保证数据库的一致性。数据的一致性是如何做到的哪?正是二阶段提交。
我们结合几种场景来分析下二阶段提交是如何做到的:
1.prepare阶段,redo log落盘前,mysqld crash
2.prepare阶段,redo log落盘后,binlog落盘前,mysqld crash
3.commit阶段,binlog落盘后,mysqld crash
对于第一种情况,由于redo没有落盘,毫无疑问,事务的更新肯定没有写入磁盘,数据库的一致性受影响;
对于第二种情况,这时候redo log写入完成,但binlog还未写入,事务处于TRX_STATE_PREPARED状态,这是提交还是回滚呢?
对于第三种情况,此时,redo log和binlog都已经落盘,只是undo状态没有更新,虽然redo log和binlog已经一致了,事务是否应该提交?
我们结合mysqld异常重启后的执行逻辑以及关键的源代码。
对于第三种情况,我们可以搜集到未提交事务的binlog event,所以需要提交;
对于第二种情况,由于binlog未写入,需要通过执行回滚操作来保证数据库的一致性。
异常重启后,如何判断事务该提交还是回滚
1.读binlog日志,获取崩溃时没有提交的event; //info->commit_list中含有该元素
2.若存在,则对应的事务要提交;否则需要回滚。
判断事务提交或回滚源码如下:
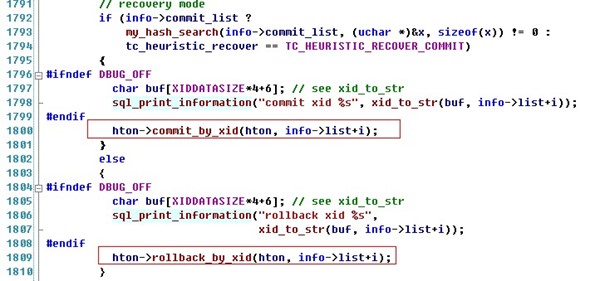
上面讨论了两阶段提交的基本流程,以及服务器异常crash后,mysql如何重启恢复保证binlog和数据的一致性。
简而言之,对于异常的xa事务,若binlog已落盘,则事务应该提交;binlog未落盘,则事务就应该回滚。
//异常重启后,回滚流程
innobase_rollback_by_xid
rollback_by_xid
trx_rollback_resurrected
trx_rollback_active
row_undo
{//从回滚页获取undo记录//分析undo记录类型if(insert)
row_undo_inselserow_undo_mod
}
//异常重启后,提交流程
commit_by_xid trx_commit_for_mysql
//写binlog接口
handler.cc:binlog_log_row sql/binlog.cc:commit mysys/my_sync:my_sync sql/binlog.cc:sync_binlog_file handler/ha_innodb.cc:innobase_xa_prepare
binlog日志文件是为了解决MySQL主从复制功能而引入的一份新日志文件,它包含了引发数据变更的事件日志集合。
从库请求主库发送 binlog 并通过日志事件还原数据写入从库,所以从库的数据来源为 binlog。
这样 MySQL 主库只需做到 binlog 与本地数据一致就可以保证主从库数据一致(暂且忽略网络传输引发的主从不一致)。
参考
1、《高性能MySQL》
2、 mysql 事务提交过程