Kafka日志及Topic数据清理 - moonandstar08 - 博客园
- - 由于项目原因,最近经常碰到Kafka消息队列拥堵的情况. 碰到这种情况为了不影响在线系统的正常使用,需要大家手动的清理Kafka Log. 但是清理Kafka Log又不能单纯的去删除中间环节产生的日志,中间关联的很多东西需要手动同时去清理,否则可能会导致删除后客户端无法消费的情况. 在介绍手动删除操作之前,先简单的介绍一下Kafka消费Offset原理.
由于项目原因,最近经常碰到Kafka消息队列拥堵的情况。碰到这种情况为了不影响在线系统的正常使用,需要大家手动的清理Kafka Log。但是清理Kafka Log又不能单纯的去删除中间环节产生的日志,中间关联的很多东西需要手动同时去清理,否则可能会导致删除后客户端无法消费的情况。
在介绍手动删除操作之前,先简单的介绍一下Kafka消费Offset原理。
一、Kafka消费Offset
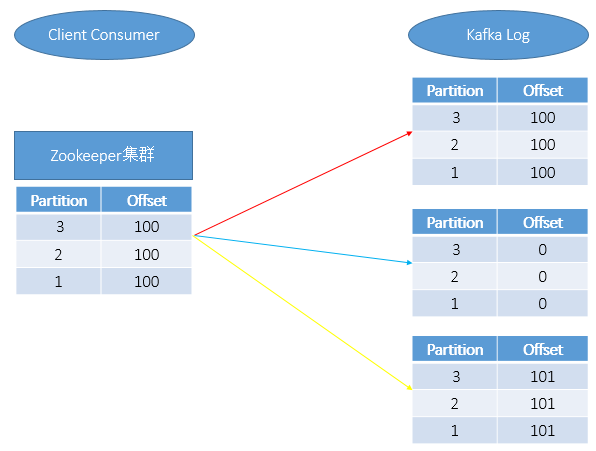
在通过Client端消费Kafka中的消息时,消费的消息会同时在Zookeeper和Kafka Log中保存,如上图红线所示。
当手动删除Kafka某一分片上的消息日志时,如上图蓝线所示,此是只是将Kafka Log中的信息清0了,但是Zookeeper中的Partition和Offset数据依然会记录。当重新启动Kafka后,我们会发现如下二种情况:
A、客户端无法正常用消费;
B、在使用Kafka Consumer Offset Monitor工具进行Kafka监控时会发现Lag(还有多少消息数未读取(Lag=logSize-Offset))为负数;其中此种情况的删除操作需要我们重点关注,后面我们也会详细介绍其对应的操作步骤。
一般正常情况,如果想让Kafka客户端正常消费,那么需要Zookeeper和Kafka Log中的记录保持如上图黄色所示。
Kafka具体消费原理可以参见: http://blog.xiaoxiaomo.com/2016/05/14/Kafka-Consumer%E6%B6%88%E8%B4%B9%E8%80%85/
二、Kafka消息日志清除
操作步骤主要包括:
1、停止Kafka运行;
2、删除Kafka消息日志;
3、修改ZK的偏移量;
4、重启Kafka;
上述步骤重点介绍其中的关键步骤。
在进行第2步:删除Kafka消息日志时,进入Kafka消息日志路径下,使用du -sh * 检查磁盘占用比较大的目录,然后删除此目录;
在进行第3步:修改ZK的偏移量时,进入ZK的安装目录下,运行./zkCli.sh -server (中间以,分割),如果不带server默认修改的为本机。
示例如下:
A.运行./zkCli.sh -server AAA:2181,BBB:2181,CCC:2181
B.在ZK上运行ls /consumers/对应的分组/offset/对应的topic,就可以看到此topic下的所有分区了;
通过get /consumers/对应的分组/offset/对应的topic/对应的分区号,可以查询到该分区上记录的offset;
通过set /consumers/对应的分组/offset/对应的topic/对应的分区号 修改后的值(一般为0),即可完成对offset的修改;
三 、重建Topic
操作步骤主要包括如下:
1、删除Topic;
2、删除log日志;
3、删除ZK中的Topic记录
第一步:删除Topic
运行./kafka-topics.sh -delete -zookeeper [zookeeper server] -topic [topic name];如果kafka启动时加载的配置文件server.properties没有配置delete.topic.enable = true,那么此时的删除并不是真正的删除。而只是把topic标记为:marked for deletion,此时就需要执行第3步的操作;
第三步:删除ZK中的Topic记录
示例如下:
A.运行./zkCli.sh -server AAA:2181,BBB:2181,CCC:2181
B.进入/admin/delete_topics目录下,找到删除的topic,删除对应的信息。
四、常用命令
A.查看Kafka中的消息
./kafka-run-class.sh kafka.tools.DumpLogSegments -print-data-log -files /data01/middle/kafka-logs/00000002154.log >>aa.txt find /dataa01 -mtime 0 -name *.log |xargs /kafka-run-class.sh kafka.tools.DumpLogSegments -print-data-log -files /data01/middle/kafka-logs/00000002154.log >>aa.txt
0代表当天;-1代表昨天