kubernetes NodePort网络踩坑 - 三木燕 - 博客园
- -系统:centos7.6 . IP地址:192.168.1.1. 因为需要跑一个nginx的应用叫做http-proxy做流量转发,公网入口是阿里云的SLB然转发到http-proxy的NodePor 端口上,也就是192.168.1.1:30285. 刚配好一切正常,过了几分钟SLB开始报健康检查错误,手动检查了一下发现3、4请求之后必然会有一次timeout.
系统:centos7.6
内核:3.10
IP地址:192.168.1.1
因为需要跑一个nginx的应用叫做http-proxy做流量转发,公网入口是阿里云的SLB然转发到http-proxy的NodePor 端口上,也就是192.168.1.1:30285
spec:
clusterIP: 172.30.253.123
externalTrafficPolicy: Cluster
ports:
- name: http
nodePort: 30285
port: 8080
protocol: TCP
targetPort: 8080刚配好一切正常,过了几分钟SLB开始报健康检查错误,手动检查了一下发现3、4请求之后必然会有一次timeout
$ curl proxy.public.com
几次请求中必然会有一次timeout
$ curl localhost:8080
正常
$ curl192.168.1.1:30285
正常,这就很诡异了
# tcpdump port30285
11:08:36.186722 IP 100.122.64.147.30042 > 192.168.1.1:30285: Flags [S], seq 868295361, win 28480, options [mss 1424,sackOK,TS val 1875975334 ecr 0,nop,wscale 9], length 0
11:08:37.236652 IP 100.122.64.147.30042 > 192.168.1.1:.30285: Flags [S], seq 868295361, win 28480, options [mss 1424,sackOK,TS val 1875976384 ecr 0,nop,wscale 9], length 0
11:08:39.284640 IP 100.122.64.147.30042 > 192.168.1.1:.30285: Flags [S], seq 868295361, win 28480, options [mss 1424,sackOK,TS val 1875978432 ecr 0,nop,wscale 9], length
可以看到有收到来自SLB发来第一握手syn包,但是服务端没有回应ack
$ netstat -s |grepLISTEN
280 SYNs to LISTEN sockets dropped
果然有而且在一直增加,查阅了相关资料后发现有可能是启用了tcp_tw_recycle参数,前一段时间因time_wait确实优化过这个参数。。。果断关掉
# sysctl -wnet.ipv4.tcp_tw_recycle=0
然后一切正常了
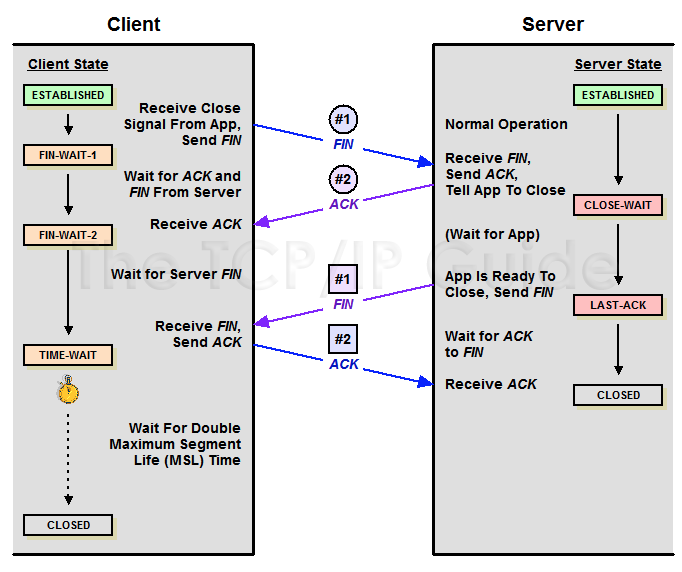
第一次挥手:主动关闭方发送一个FIN+ACK报文,此时主动方进入FIN_WAIT1状态,主动方停止发送数据但仍然能接收数据
第二次挥手:被动方收到FIN+ACK,发送一个ACK给对方,此时被动方进入CLOSE-WAIT状态,被动方仍然可以给主动方发送数据
第三次挥手:主动方收到ACK后,此时主动方进入FIN_WAIT2状态,被动方确定没有数据要发后就会发送FIN+ACK报文
第四次挥手:主动方收到FIN+ACK,此时主动方进入TIME-WAIT状态,发送一个ACK给被动方,方被动方进入CLOSED状态
| 参数 | 默认状态 | 作用 | 条件 | 影响 | 风险 | 建议 |
| net.ipv4.tcp_timestamps | 开启 | 记录TCP报文的发送时间 | 双方都要开启 | 影响客户端服务端 | 开启 | |
| net.ipv4.tcp_tw_recycle | 关闭 4.1内核已删除 | 把TIME-WAIT状态超时时间设置为成rto,以实现快速回收 | 要启用net.ipv4.tcp_timestamps | 影响客户端服务端 | tcp_tw_recycle和tcp_timestamps同时开启的条件下,60s内同一源ip主机的socket connect请求中的timestamp必须是递增的,否则数据会被linux的syn处理模块丢弃 | 内网环境切没有NAT的时候看情况打开,没什么必要就不要打开了 |
| net.ipv4.tcp_tw_reuse | 关闭 | TIME-WAIT状态1秒之后可以重用端口 | 要启用net.ipv4.tcp_timestamps | 影响客户端 | 比如负载均衡连接后端服务器时,可以在负载均衡服务器上开启 |
结论:对于服务端来说,客户端通过SNAT上网时的timestamp递增性无可保证,所以当服务端tcp_tw_recycle生效时会出现连接异常
service网络的实体是kube-proxy维护iptables规则,先看一下流程
# iptables -t nat -nL PREROUTING
# iptables -t nat -nL KUBE-SERVICES
KUBE-NODEPORTS all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
# iptables -t nat -nL KUBE-NODEPORTS
KUBE-MARK-MASQ tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/http-proxy:http1 */ tcp dpt:30285
KUBE-SVC-NKX6PXTXGL4F5LBG tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/http-proxy:http1 */ tcp dpt:30285
# iptables -t nat -nL KUBE-MARK-MASQ
MARK all -- 0.0.0.0/0 0.0.0.0/0 MARK or 0x1
# iptables -t nat -nL POSTROUTING
KUBE-POSTROUTING all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes postrouting rules */
# iptables -t nat -nL KUBE-POSTROUTING
MASQUERADE all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */ mark match 0x1/0x1
# iptables -t nat -nL KUBE-SVC-NKX6PXTXGL4F5LBG
KUBE-SEP-4DYOPOZ4UKLHEHIS all -- 0.0.0.0/0 0.0.0.0/0 /* default/http-proxy:http1 */
# iptables -t nat -nL KUBE-SEP-4DYOPOZ4UKLHEHIS
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/http-proxy:http1 */ tcp to:10.128.0.74:8081
结论:可以看到第五步kube-proxy会做SNAT的操作,这也就不难解释从SLB过来的流量为什么会不正常了。至于为什么要做SNAT主要是防止路由来回路径不一致会导致tcp通信失败,这里就不展开了