
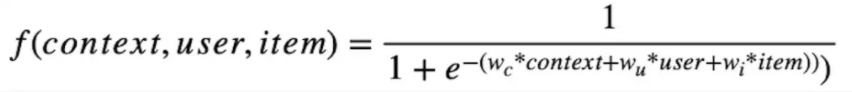


得物技术聊聊推荐系统是如何做排序的
- - SegmentFault 最新的文章信息时代到来以后,我们被各种各样海量的信息所淹没,从新闻、广告、电商、直播、短视频等各种涉及这些场景的APP中,大量个性化的信息被推送到我们眼前. 例如在使用得物APP购物的过程中,我们也常常会听到这样的问题, 为什么会给我推这双鞋/这件衣服. 为什么浏览收藏过的商品反复出现在推荐流中. 推荐的排序逻辑是怎样的,都考虑了哪些因素.
信息时代到来以后,我们被各种各样海量的信息所淹没,从新闻、广告、电商、直播、短视频等各种涉及这些场景的APP中,大量个性化的信息被推送到我们眼前。例如在使用得物APP购物的过程中,我们也常常会听到这样的问题, 为什么会给我推这双鞋/这件衣服?为什么浏览收藏过的商品反复出现在推荐流中?推荐流是怎么猜测我的喜好的?推荐的排序逻辑是怎样的,都考虑了哪些因素?能不能主动增加某些类目的曝光量?这些种种的问题,都和我们的排序模型、排序逻辑有关,下面就让我们来聊聊推荐系统中是如何对商品做排序的。
图1. 得物APP首页推荐瀑布流
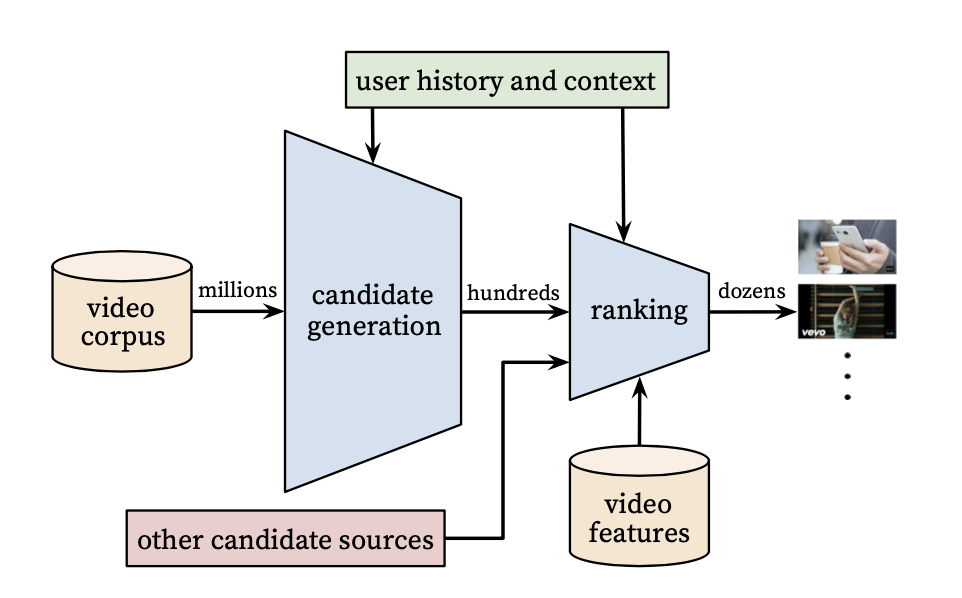
首先来简单说一下推荐系统的基本架构,借用youtube论文中的一张图片来说明。推荐系统的核心目标是从我们的总商品库中,为用户挑选出他最感兴趣的一部分商品,从而节省用户时间,也提高平台的转化效率,为交易的顺利进行提供助力。除开一些工程实现部分的细节,整个过程可以大致分为两个阶段,即召回(candidate generation)和排序(ranking),其中召回的任务是从海量商品中选取部分用户“大概率”感兴趣的商品集,而排序则负责将召回选出来的这部分商品仔细分析,按照用户可能感兴趣的程度(probability),从高到低进行排序,展示给用户观看,整个过程在毫秒级的时间内完成。
图2. 引用自论文:Deep Neural Networks for YouTube Recommendations
召回层面的策略和逻辑有很多,也演化了很长一段时间,不过这不是我们今天聊的重点,我们来详细聊聊,当我们拿到了召回结果,大概在一万件以内的规模下,模型是怎样确定他们的先后顺序的,机器怎样自动化地计算出分数来评估用户对他们的感兴趣程度的。
排序模型的发展也有很长一段时间了,从互联网逐渐兴起开始,为用户快速筛选出有价值的信息一直是一件非常核心的事。我们不妨来看看,为了完成这项任务,都经历了哪些演变过程。
先看一个简单例子,一位女性用户来到我们平台,我们可以拿到的信息有她的性别、访问时间、行为历史记录等,假设她之前逛了逛衣服,收藏了一双鞋,最近又在浏览吹风机,而我们的召回候选集中又恰好有衣服、鞋和吹风机,我们应该怎样来定义排序的逻辑呢?
解决问题的第一阶段,往往是依赖于直觉的,直觉告诉我们,每一个和用户或者是商品有关的信息,都会影响到用户的决策,这之中又必然存在着一定的数量关系,排序便有了最初的思路:人工规则。顾名思义,就是根据平台运营人员对业务的熟悉程度,来直接定义物品的先后顺序,例如平台最近某件衣服是爆款,卖的很好,所以要排在前面,尽可能让顾客看到,考虑到个性化因素,这位又是女性用户,那么就把最近所有女性用户购买的商品做一个统计,按照销量从高到低排序,或者更近一步,某个地区的女性用户,最近收藏过鞋子的某地区的女性用户….只要划分用户特定维度后的数据流足够多,规则足够明确,最终所有商品对一个具体用户都会有一个排序结果,一个粗糙的推荐排序策略也就成型了。
那么以上策略是否就是我们的排序方案呢?显然并不是的。以上方案有两个不太合理的地方:
有没有一个方案能整合利用所有能拿到的信息,并且在上线前对结果有一个合理预期,甚至不需要上线实验,离线就能评估策略的好坏呢?这个时候,机器学习方法出现在了我们眼前。
解决问题的第二阶段,就是在直觉的基础上引入可量化的模型。模型是一个比较抽象的词,在这里它指的是对一种映射的抽象描述,即 f(context,user,item)—> score,任何能用具体公式提供这个分数计算逻辑的方案,都可以叫做模型。 衡量一个模型好坏的标准,就是这个假设出来的映射关系与现实中真实的内在关系的距离。比如个子越高,体重就越大,就是一个根据身高信息去映射体重信息的线型模型,这个模型显然是不严谨的,但在很多时候也是成立的。说回我们的排序模型,我们需要设计一个方案,从用户、商品和上下文信息(事件发生的时间、场景等客观信息)中,提炼出用户对商品的偏好程度。
一个能同时整合所有信息,在形式上足够简单,在工业界的大数据和高并发下又拥有足够稳定性的模型,早就已经被数学所给出,那就是著名的逻辑回归模型,形式如下:
图3. 逻辑回归函数图像
这个模型的形式虽然简单,但思想足够深刻,里面整合了数学界在参数估计、信息论和凸优化等方向的研究成果,将变量用线性的方式结合起来,把定义在(-∞,+∞)的自变量映射到(0,1)的值域上,这里的(0,1)之间的分数可以理解为用户感兴趣的概率,整个过程便成了一个点击率预估问题。当我们用线上实时收集到的用户行为数据作为基础,把用户的点击行为转化为0或1的训练目标,便可以用很成熟的数学方案快速地求出公式中的所有最优化参数w,从而确定下最终的计算过程。虽然逻辑回归模型在学术界已经是基础中的基础,但由于其稳定性和极高的计算效率,工业界也依然有很多业务场景中使用这套模型作为线上服务的主要担当或者降级备用方案。
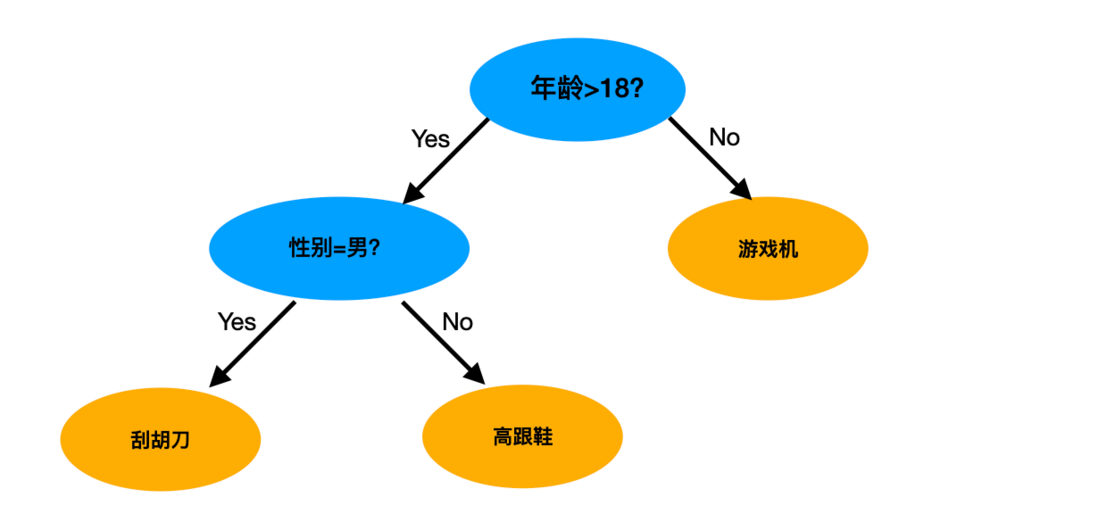
除了逻辑回归以外,还有许多机器学习的模型被应用在排序环节中如NB, SVM和GBDT等,其中比较成功的模型是GBDT,这里面又以陈天奇博士提出的XGBoost模型最为著名,在工业界也有广泛的应用。GBDT模型是以决策树模型为基础提出的组合模型,树模型的特点是更加符合我们人对事物的判断方式,大概的思想类似下图:
图4. 树模型决策思路简述
刚才提到的GBDT模型就是将以上这种决策行为给定量化,并且使用多棵决策树进行组合决策的结果,相比于逻辑回归模型,它提出了一个更符合人类直觉的视角,将排序问题拆解为对若干特征的而二分类组合,将各种用户和商品特征在决策过程中进行了交叉,实践中效果往往是更优的,这也符合我们提到的“模型是对真实决策关系的模拟”这一观点。但是树模型也有它的不足,比如它优化性能较低,对大数据量的计算性能较差,对增量训练的支持度较差等等。
总的来说,无论是逻辑回归还是GBDT模型,都是机器学习在推荐领域很好的实践和探索,他们各自都还存在一些明显的不足,业界针对这些不足的地方也都有各种补充和优化的方案,经过几年的迭代,伴随着理论和硬件条件双重发展的基础上,推荐系统迎来了它的深度学习时代。
解决问题的第三阶段,是在成熟的工业界方案基础上,加入自己对具体业务场景的理解。逻辑回归公式简洁,性能可靠,GBDT思路清晰,效果出色,但他们是否就是问题的最终解决方案呢?显然还是不够的,如上面提到的,他们各自都还有不少的问题需要解决:
从解决这两个问题出发,我们的思路又细分到了两个方向上,分别是拓宽模型的复杂度和多目标下的后排序干预。
第一个问题是拓宽模型的复杂度,在具体操作中可以分为两个方面的工作,第一个方面,是在特征组合上尽可能提供复杂的特征,比如我们例子中,本身模型输入的信息是性别、地区、用户行为、商品属性,但是我们可以人工定义一些其他的复杂特征,比如用户是否购买过同类商品,用户对同品牌商品的点击次数等,通过增加特征的复杂度,来增加模型输入的信息量,把一些非线性的关系转化到线性模型上来解决,这样做的好处是有效节省了计算资源,也减轻了线上推断所带来的压力,对效果提升也很有帮助;不过弊端也是明显的,那就是整体思路又回到了我们一开始人工规则的老路上,依赖于人的经验来做优化,不过这里的人由平台运营换成了算法工程师。所以能不能把拓宽非线性关系的工作也交给机器来完成呢?这便是第二个方面,引入深度学习的模型。
图5. Google提出的模型的Wide&Deep模型架构
深度学习在如今的工业界早已是大名鼎鼎,从2016年起,在谷歌的W&D模型的影响下,工业界的推荐系统开始纷纷效仿,大踏步地迈进了深度学习所统治的时代,如今各大厂的主流推荐模型,都是在深度学习的基础上做的开发,关于深度学习的理论知识,相关讲解有很多,这里就不详细展开。对于推荐系统来说,深度学习所解决的核心问题,就是特征间非线性关系的自动化挖掘。这里面的逻辑,可以说是一个“用魔法来打败魔法”的过程。我对这个问题的理解是这样的,特征间正确的组合方式是存在的,只是组合成几何级增长,遍历尝试的操作代价难以承受,这便是第一重“魔法”;而深度学习从理论上证明,只要给定入参和目标,它可以拟合任意复杂的函数,但是最终你也不会知道拟合出来的函数具体形式是怎样的(可解释性目前为止也是学术界的一个很重要的方向),这便是第二重“魔法”;一边是你无法遍历的组合结果,另一边是你无法解释的组合结果,但最终产出了符合你预期的业务效果,所以我称之为一个用魔法去打败魔法的过程,这也是业内深度学习算法工程师又被戏称为“炼丹工程师”的原因,很多时候工程师对于模型的具体作用原理也是难以解释的,唯一知道的,就是它是否“有效”。
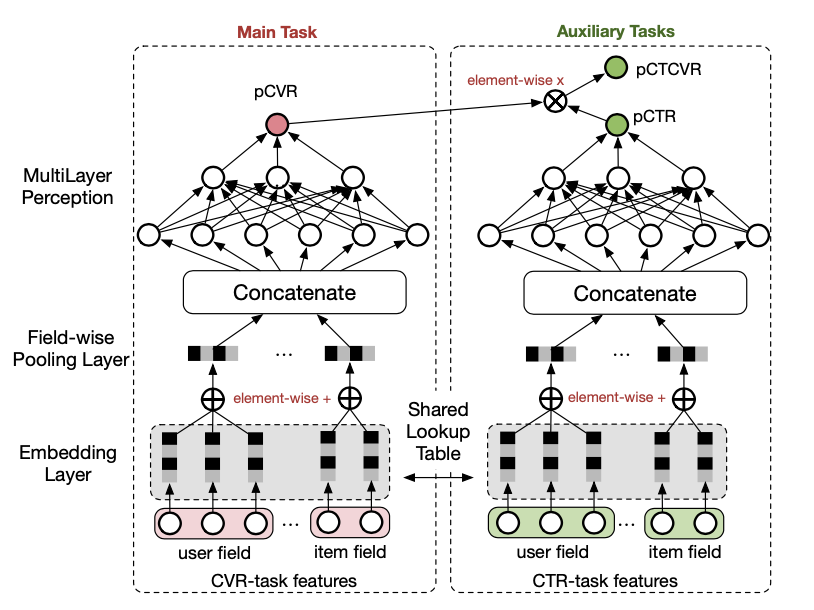
图6.阿里巴巴提出的ESMM多目标网络
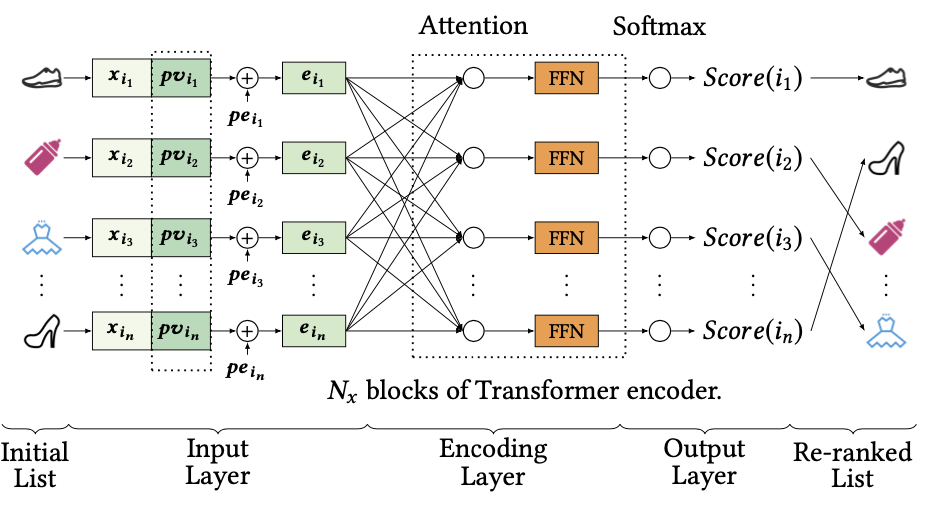
图7.阿里巴巴提出的重排序网络
关于逻辑回归的第二个问题,多目标和多样性,就不能简单通过拓宽模型复杂度来解决了。多目标优化和后排序干预也是现在推荐排序侧很重要的逻辑,由于深度学习这个魔法特别好用,所以业界也产出了很多相关的理论模型,比如阿里的ESMM和Re-ranking模型。不过由于后排序这块是直接影响到用户最终体验的,不可解释的魔法结果在目前的实用性和可控性上还是比不上能够灵活调整的规则,因此在模型排序的结果环节,又加入了一些人工规则,比如类目打散、品牌打散和曝光过滤等,来满足一些主观需求。最终的排序流程,还是一个计算机模型和人工规则互相扶助来实现的。
以上便是推荐系统的大体排序逻辑,以后的模型还会越来越多,也未必都会局限在深度学习的领域,整个业界也还在探寻什么样的模型能以最小的代价刻画出人与物的协同关系,这个问题很可能没有一个标准答案,需要算法工程师根据具体的业务场景和业务特点去构造和处理排序的问题。最终的排序结果是在训练数据、特征选择、模型结构和后排序逻辑的共同干预作用下决定的,数据会是排序逻辑的核心,而不是人工主观意识在驾驭和操纵的。虽然小的细节还在不断地调整和改变,但是大的方向一定是以更复杂的特征、更合理的模型结构、更高效的迭代方式,更灵活的规则调整来实现更好的业务指标。
[1] Covington, Paul, Jay Adams, and Emre Sargin. "Deep neural networks for youtube recommendations." Proceedings of the 10th ACM conference on recommender systems. 2016.
[2] Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st workshop on deep learning for recommender systems. 2016.
[3] Ma, Xiao, et al. "Entire space multi-task model: An effective approach for estimating post-click conversion rate." The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.
[4] Pei, Changhua, et al. "Personalized re-ranking for recommendation." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
[5] Chen, Tianqi, and Carlos Guestrin. "Xgboost: A scalable tree boosting system." Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016.
文|John
关注得物技术,携手走向技术的云端