作者丨gongyouliu 编辑丨zandy 这是作者的第20 篇文章, 约2.4 万字,阅读需18 0 分钟
2016年DeepMind开发的AlphaGo在围棋对决中战胜了韩国九段选手李世石,一时成为轰动全球的重大新闻,被全球多家媒体大肆报道。AlphaGo之所以取得这么大的成功,这其中最重要的技术之一是深度学习技术。经过这几年的发展,深度学习技术已经在图像分类、语音识别、自然语言处理等领域取得突破性进展,甚至在某些方面(如图像分类等)超越了人类专家的水平。深度学习技术驱动了第三次人工智能浪潮的到来。
鉴于深度学习技术的巨大威力,它被学术界、产业界尝试应用于各类业务及应用场景,包括计算机视觉、语音识别、自然语言处理、搜索、推荐、广告等等。2016年YouTube发表论文将深度学习应用于视频推荐取得了非常好的效果,自此之后,深度学习技术在推荐系统上的应用遍地开花,各种论文、学术交流、产业应用层出不穷。国际著名的推荐系统会议RecSys从2016开始专门组织关于深度学习的会议,深度学习在推荐圈中越来越受到重视。
本文试图对深度学习在推荐系统中的应用进行全面介绍,不光介绍具体的算法原理,还会重点讲解作者对深度学习技术的思考及深度学习应用于推荐系统的当前生态和状况,我会更多地聚焦深度学习在工业界的应用。具体来说,本文会从深度学习介绍、利用深度学习做推荐的一般方法和思路、工业界经典深度学习推荐算法介绍、开源深度学习框架&推荐算法介绍、深度学习推荐系统的优缺点、深度学习推荐系统工程实施建议、深度学习推荐系统的未来发展等7个部分分别介绍。
本文的目的是通过全面的介绍让读者更好地了解深度学习在推荐上的应用,并更多地冷静思考,思考当前是否值得将深度学习引入到推荐业务中,以及怎么引入、需要具备的条件、付出的成本等等,而不是追热点跟风去做。深度学习是一把双刃剑,我们只有很好地理解深度学习、了解它当前的应用状况,最终才能更好地用好深度学习这个强有力的武器,服务好推荐业务。希望本文可以为读者提供一个了解深度学习在推荐系统中的应用的较全面的视角,成为你的一份学习深度学习推荐系统的参考指南。
一深度学习介绍
深度学习其实就是神经网络模型,一般来说,隐含层数量大于等于2层就认为是深度学习(神经网络)模型。神经网络不是什么新鲜概念,在好几十年前就被提出来了,最早可追溯到1943年McCulloch与Pitts合作的一篇论文(参考文献1),神经网络是模拟人的大脑中神经元与突触之间进行信息处理与交互的过程而提出的。神经网络的一般结构如下图,一般分为输入层、隐含层和输出层三层,其中隐含层可以有多层,各层中的圆形是对应的节点(模拟神经元的对应物),节点之间通过有向边(模拟神经元之间的突触)连接,所以神经网络也是一种有向图模型。
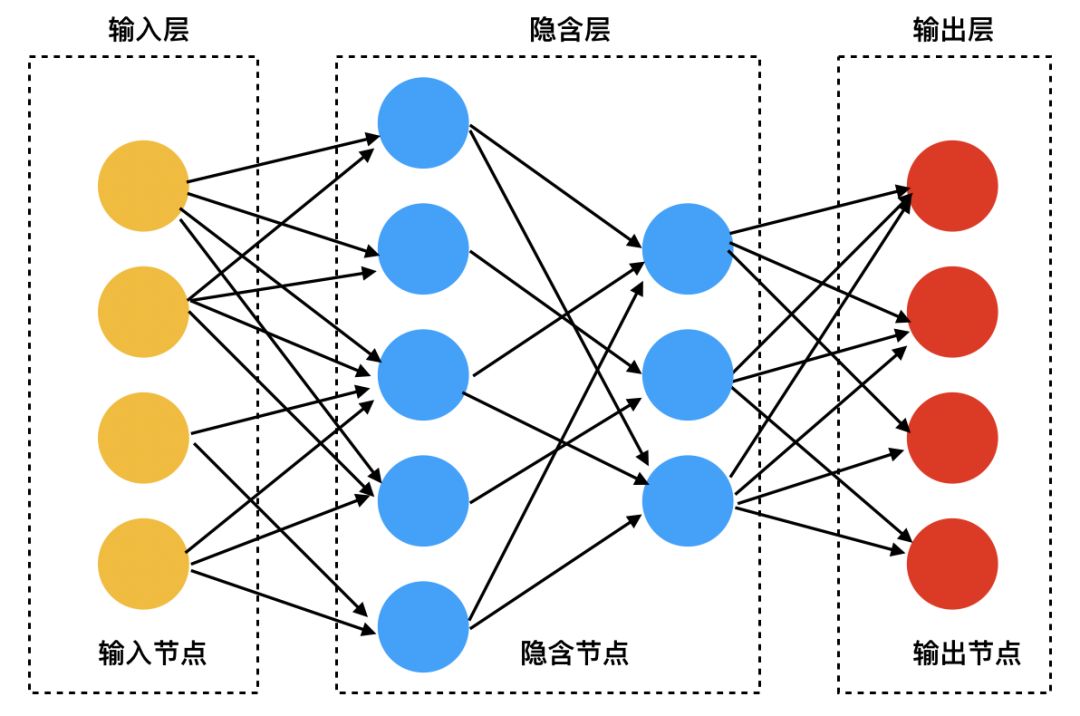
图1:深度学习网络(前馈神经网络)结构示意图
假设前馈神经网络一共有k个隐含层,那么我们可以用如下一组公式来说明数据沿着箭头传递的计算过程,其中

是输入,
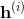
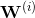
是第i个隐含层各个节点对应的数值,
是从第i-1层到第i层的权重矩阵,
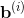
是偏移量,
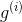
是激活函数,
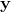
是最终的输出,这里
、
是需要学习的参数。
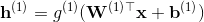
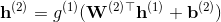
......
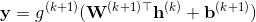
对于更加复杂的深度学习网络模型,公式会更加复杂,这里不细说。深度学习一般应用于回归、分类等监督学习问题,通过输出层的损失函数,构建对应的最优化问题,深度学习借助于
反向传播(参考文献3)技术来进行迭代优化,将预测误差从输出层向输入层(即反向)传递,依次更新各层的网络参数,通过结合某种参数更新的最优化算法(一般是各种梯度下降算法),实现参数的调整和更新,最终通过多伦迭代让损失函数收敛到(局部)最小值,从而求出模型参数。梯度下降算法的推导公式依赖于数学中求导的链式规则,这里具体不做介绍,读者可以参考相关文章及书本学习了解。
虽然神经网络很早被提出来了,但当时只是停留在学术研究领域,一直没有得到大规模的产业应用。最早的神经网络叫做感知机(Perceptron),是单层的人工神经网络,只用于模拟简单的线性可分函数,连最简单的XOR异或都无能为力,这种致命的缺陷导致了神经网络发展的第一次低谷,科研院校纷纷减少对神经网络研究的经费支持。单层感知机无法解决线性不可分的分类问题,后面人们提出了有名的多层感知机(
MLP),但是限于当时没有好的方法来训练MLP,直到80年代左右,反向传递算法被发现,被用于手写字符识别并取得了成功,但是训练速度非常慢,更复杂的问题根本无法解决。90年代中期,由Vapnik等人发明的支持向量机(SVM)在各类问题上取得了非常好的效果,基本秒杀神经网络模型,这时神经网络技术陷入了第二次低谷,只有Hinton等很少学者一直坚持研究神经网络。事情的转机出现在2006年,Hinton提出了深度置信网络,通过预训练及微调的技术让深度神经网络的训练时间及效果得到了极大提升。到了2012年,Hinton及他的学生提出的AlexNet网络(一种深度卷积神经网络)在ImageNet竞赛(2010年开始,斯坦福的李飞飞教授组织的ImageNet项目,是一个用于视觉对象识别软件研究的大型可视化数据库,该竞赛直接促进了以深度学习驱动的第三次AI浪潮的发展)中取得了第一名,成绩比第二名高出许多,这之后深度学习技术获得了空前的巨大成功。
经过近十来年的发展,有更多的神经网络模型被陆续发现,除了最古老的多层感知机(
MLP)外,卷积神经网络(
CNN)在图像识别取得极大的胜利,循环神经网络(
RNN)在语音识别、自然语音处理中如鱼得水,CNN和RNN是当前最成功的两类神经网络模型,它们有非常多的变种。另外,像自编码器(
Autoencoder)、对抗网络(Adversarial Network,简称
AN)等新的模型及神经网络架构不断被提出。
对深度学习发展历史感兴趣的读者可以阅读参考文献2,该文对深度学习发展历史做了非常好的总结与整理。
二利用深度学习做推荐的一般方法和思路
在上一节我们对深度学习的基本概念、原理、发展历史做了简单的介绍,同时也提到了MLP、CNN、RNN、Autoencoder、AN几类比较出名并且常见的神经网络模型,这几类模型都可以应用于推荐系统中。
本节我们来简单讲解一下可以从哪些角度将深度学习技术应用于推荐系统中。根据推荐系统的分类及深度学习模型的归类,我们大致可以从如下三个角度来思考怎么在推荐系统中整合深度学习技术。这些思考问题的角度可以帮助我们结合深度学习相关技术、推荐系统本身的特性以及公司具备的数据及业务特点选择合适自身业务和技能的深度学习技术,将深度学习技术更好地落地到推荐业务中。
1从推荐算法中用到的深度学习技术角度来思考
常用的深度学习模型有MLP(多层感知机)、CNN(卷积神经网络)、RNN(循环神经网络)、Autoencoder(自编码器)、AN(Adversarial Network,对抗网络)、RBM(受限玻尔兹曼机)、NADE(Neural Autoregressive Distribution Estimation)、AM(Attentional Model,注意力模型)、DRL(深度强化学习)等,这些模型都可以跟推荐系统结合起来,并且学术界和产业界都有相关的论文发表。读者可以参见参考文献5,该文章是一篇非常全面实用的深度学习推荐系统综述文章,在这篇文章中作者就是按照不同深度学习模型来整理当前深度学习应用于推荐系统的有代表性的文章和方法的。希望对深度学习推荐系统有全面了解和学习的读者可以好好阅读这篇文章,一定会有较大的收获。
目前采用MLP网络来构建深度学习推荐算法是最常见的一种范式(参考文献7、8、13、19等),如果需要整合附加信息(图像、文本、语音、视频等)会采用CNN、RNN模型来提取相关信息。
2从推荐系统的预测目标来思考
从推荐系统作为机器学习任务的目标来看,推荐系统是为用户推荐用户可能感兴趣的标的物,一般可以分为预测评分、排序学习、分类等三类问题,下面分别介绍。
(1) 推荐作为评分预测问题
我们可以通过构建机器学习模型来预测用户对未知标的物的评分,高的评分代表用户对标的物更有兴趣,最终根据评分高低来为用户推荐标的物。这时推荐算法就是一个回归问题,经典的协同过滤算法(如矩阵分解)、logistic回归推荐算法都是这类模型,以及基于经典协同过滤思路发展的深度学习算法(见参考文献19)也是这类模型。
由于在真实产品中用户对标的物评分数据非常有限,因此隐式反馈是比用户评分更容易获得的数据类型,所以采用评分预测问题来构建深度学习推荐系统的案例及文章会比较少。深度学习需要大量的数据来训练好的模型,因此也期望数据量足够大,所以利用隐式反馈数据是更合适的。
(2) 推荐作为排序学习问题
可以将推荐问题看成排序学习(Learning to Ranking)问题,采用信息抽提领域经典的一些排序学习算法(point-wise、pair-wise、list-wise等)来进行建模,关于这方面利用深度学习做推荐的文章也有一些,比如参考文献46是京东的一篇基于深度强化学习做list-wise排序推荐的文章。作者未来会单独写一篇关于排序学习相关的文章,这里不细讲解。
(3) 推荐作为分类问题
将推荐预测看成是分类问题是比较常见的一种形式,既可以看成二分类问题,也可以看成多分类问题。
对于隐式反馈,我们用0和1表示标的物是否被用户操作过,那么预测用户对新标的物的偏好就可以看成一个二分类问题,通过输出层的logistic激活函数来预测用户对标的物的点击概率。这种将推荐作为二分类问题,通过预测点击概率的方式是最常用的一种推荐系统建模方式。下面会讲到的wide & deep模型就是采用这样的建模方式。
我们也可以将推荐预测问题看成一个多分类问题,每一个标的物就是一个类别,有多少个标的物就有多少类,一般标的物的数量是巨大的,所以这种思路就是一个海量标签(label)分类问题。我们可以通过输出层的softmax激活函数来预测用户对每个类别的“分量概率”,预测用户下一个要点击的标的物就是分量概率最大的一个标的物。下面要讲到的YouTube深度学习中的召回阶段采用的就是这种建模方式。
3根据推荐算法的来归类来思考
从推荐算法最传统的分类方式来看,推荐算法分为基于内容的推荐、协同过滤推荐、混合推荐等三大类。
(1) 基于内容的推荐
基于内容的推荐,会用到用户或者标的物的metadata信息,基于该metadata信息来为用户做推荐,这些metadata信息主要有文本、图片、视频、音频等,一般会用CNN或者RNN从metadata中提取信息,并基于该信息做推荐。参考文献9就是这类推荐。
(2) 协同过滤推荐
协同过滤只依赖用户的行为数据,不依赖metadata数据,因此可以在更多更广泛的场景中使用,它也是最主流的推荐技术。绝大多数深度学习推荐系统都是基于协同过滤思路来推荐的,或者至少包含部分协同过滤的模块在其中,参考文献19就是这类模型中的一个代表。
(3) 混合推荐
混合推荐就是混合使用多种模型进行推荐,可以混合使用基于内容的推荐和协同过滤推荐,或者混合多种内容推荐、混合多种协同过滤推荐等。参考文献10就是一种混合的深度学习推荐算法。下面要讲到的wide & deep模型中wide部分可以整合metadata信息,deep部分类似协同的思路,因此也可以认为是一种混合模型。
三几种用于推荐系统的嵌入方法的算法原理介绍
深度学习在推荐系统中的应用最早可以追溯到2007年Hinton跟他的学生们发表的一篇将受限玻尔兹曼机应用于推荐系统的文章(参考文献6),随着深度学习在计算机视觉、语音识别与自然语音处理的成功,越来越多的研究者及工业界人士开始将深度学习应用于推荐业务中,最有代表性的是2016年Google发表的wide & deep模型和YouTube深度学习推荐模型(这两个模型我们下面会重点讲解),这之后深度学习在推荐上的应用如雨后春笋,使用各种深度学习算法应用于各类产品形态上。本节我们选择几个有代表性的工业级深度学习推荐系统,讲解它们的算法原理和核心亮点,让大家更好地了解深度学习在推荐的应用方法,希望给大家提供一些可借鉴的的思路和方法。具体来说我们会重点讲解如下4个主流深度学习推荐模型,在最后也会对其他重要的模型进行简单介绍。
1YouTube深度学习推荐系统
该模型发表于2016年(参考文献7),应用于YouTube上的视频推荐。该篇文章按照工业级推荐系统的架构将整个推荐流程分为两个阶段:候选集生成(召回)和候选集排序(排序)(见下面图2)。构建YouTube视频推荐系统会面临三大问题:规模大(YouTube有海量的用户和视频),视频更新频繁(每秒钟都有数小时时长的视频上传到YouTube平台,噪音(视频metadata不全、不规范,也无法很好度量用户对视频的兴趣),通过将推荐流程分解为这两步,并且这两部都采用深度学习模型来建模,很好地解决了这三大问题,最终获得非常好的线上效果。
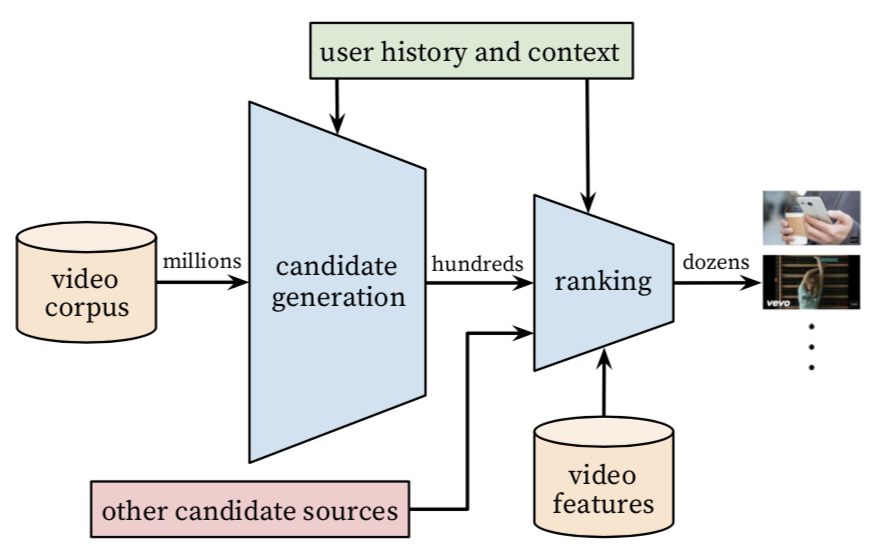
图2:YouTube深度学习推荐系统架构
候选集生成阶段根据用户在YouTube上的行为为用户生成几百个候选视频,候选集视频期望尽量匹配用户可能的兴趣偏好。排序阶段从更多的(特征)维度为候选视频打分,根据打分高低排序,将用户最有可能点击的几十个作为最终的推荐结果。划分为两阶段的好处是可以更好地从海量视频库中为用户找到几十个用户可能感兴趣的视频(通过两阶段逐步缩小查找范围),同时可以很好地融合多种召回策略召回视频。下面我们分别来讲解这两个步骤的算法。
1. 候选集生成
通过将推荐问题看成一个多分类问题(类别的数量等于视频个数),基于用户过去观看记录预测用户下一个要观看的视频的类别。利用深度学习(MLP)来进行建模,将用户和视频嵌入同一个低维空间,通过softmax激活函数来预测用户在时间点t观看视频i的的概率。具体预测概率公式如下:
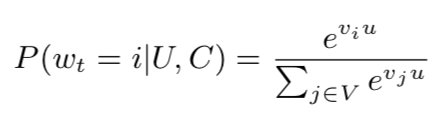
其中u、v分别是用户和视频的嵌入向量。U是用户集,C是上下文。该方法通过一个(深度学习)模型来一次性学习出用户和视频的嵌入向量。
由于用户在YouTube的显示反馈较少,该模型采用隐式反馈数据,这样可以用于模型训练数据量会大很多,这刚好适合深度学习这种强依赖数据量的算法系统。
为了更快地训练深度学习多分类问题,该模型采用了负采样机制(重要性加权的候选视频集抽样)提升训练速度。最终通过最小化交叉熵损失函数(
cross-entropy loss)求得模型参数。通过负采样可以将整个模型训练加速上百倍。
候选集生成阶段的深度学习模型结构如下图。首先将用户的行为记录按照word2vec的思路嵌入到低维空间中(参考作者《嵌入方法在推荐系统中的应用》第四节2中的item2vec方法),将用户的所有点击过的视频的嵌入向量求平均(如element-wise average),获得用户播放行为的综合嵌入表示(即下图的watch vector)。同样的道理,可以将用户的搜索词做嵌入,获得用户综合的搜素行为嵌入向量(即下图的search vector)。同时跟用户的其他非视频播放特征(地理位置、性别等)拼接为最终灌入深度学习模型的输入向量,再通过三层全连接的ReLU层,最终通过输出层(输出层的维度就是视频个数)的softmax激活函数获得输出,利用交叉熵损失函数来训练模型最终求解最优的深度学习模型。
图3:候选集生成阶段深度学习模型结构
下面我们来讲解一下候选集生成阶段怎么来筛选出候选集的,这一块在论文中没有讲的很清楚(有可能论文作者觉得这个太简单没必要讲,但是我还是花了很长时间才搞清楚的)。最上一层ReLU层是512维的,这一层可以认为是一个嵌入表示,表示的是用户的嵌入向量。那么怎么获得视频的嵌入向量呢?是通过用户嵌入向量经过softmax变换获得512维的视频嵌入向量,这样用户和视频嵌入都确定了。最终可以通过用户嵌入在所有视频嵌入向量空间中,按照内积度量找最相似的topN作为候选集。通过这里的描述,我们可以将候选集生成阶段看成是一个嵌入方法,是矩阵分解算法的非线性(MLP神经网络)推广。
候选集生成阶段的亮点除了创造性地构建深度学习多分类问题、通过用户、视频的嵌入获取嵌入表示,通过KNN获得候选集外,还有很多工程实践上的哲学,这里简单列举几个:
(1) 每个用户生成固定数量的训练样本,“公平”对待每一个用户,而不是根据用户观看视频频度的多少按照比例获取训练样本(即观看多的活跃用户取更多的训练样本),这样可以提升模型泛化能力,从而获得更好的在线评估指标。
(2) 选择输入样本和label时,是需要label观看时间上在输入样本之后的,这是因为用户观看视频是有一定序关系的,比如一个系列视频,用户看了第一季后,很可能看第二季。因此,模型预测用户下一个要看的视频比预测随机一个更好,能够更好地提升在线评估指标,这就是要选择label的时间在输入样本之后的原因。
(3) 模型将“
example age”(等于
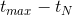
,这里
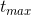
是训练集中用户观看视频的最大时间,
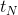
是某个样本的label观看时间)整合到深度学习模型的输入特征中,这个特征可以很好地反应视频在上传到YouTube之后播放流量的真实分布(一般是刚上线后流量有一个峰值,后面就迅速减少了),通过整合该特征后预测视频的分布跟真实播放分布保持一致。
2. 候选集排序
候选集排序阶段(参见下面图4)通过整合用户更多维度的特征,通过特征拼接获得最终的模型输入向量,灌入三层的全连接MLP神经网络,通过一个加权的logistic回归输出层获得对用户点击概率(即是我们前面介绍的当做二分类问题)的预测,同样采用交叉熵作为损失函数。
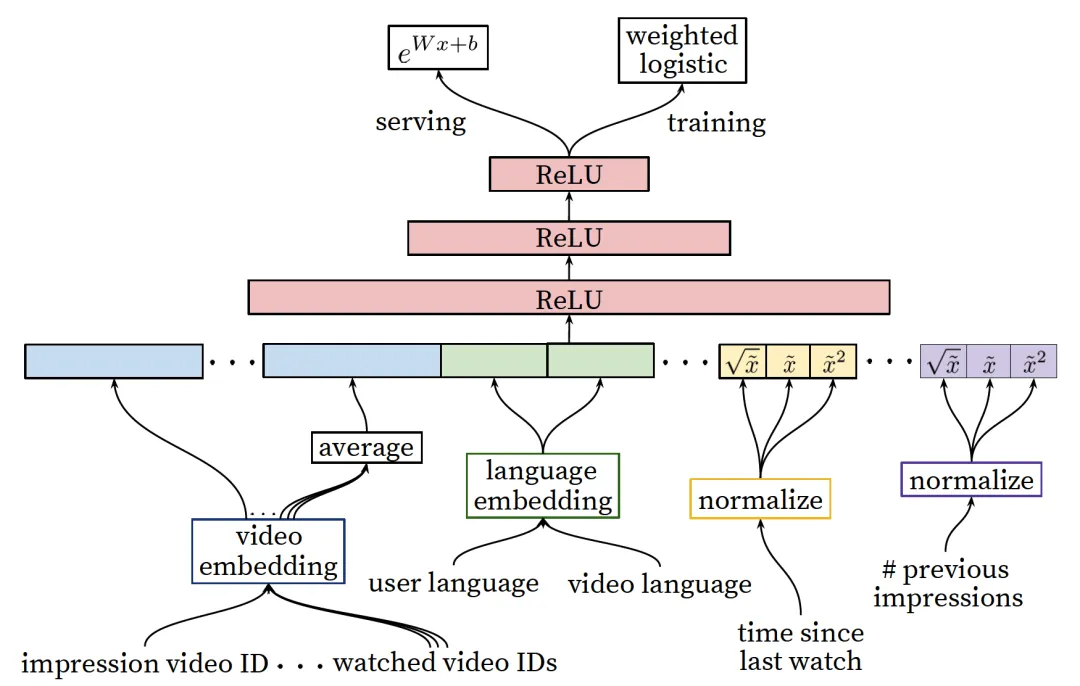
图4:候选集排序阶段深度学习模型结构
YouTube希望优化的不是点击率而是用户的播放时长,这样可以更好地满足用户需求,提升了时长也会获得更好的广告投放回报(时长增加了,投放广告的可能性也相对增加),因此在候选集排序阶段希望预测用户下一个视频的播放时长。所以才采用图4的这种输出层的加权logistic回归激活函数和预测的指数函数(
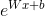
),下面我们来说明为什么这样的形式刚好是优化了用户的播放时长。
模型用加权logistic回归来作为输出层的激活函数,对于正样本,权重是视频的观看时间,对于负样本权重为1。下面我们简单说明一下为什么用加权logistic回归以及serving阶段为什么要用
来预测。
logistic函数公式如下,
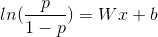
通过变换,我们得到
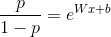
左边即是logistic回归的odds(几率),下面我们说明一下上述加权的logistic回归为什么预测的也是odds。对于正样本i,由于用了
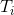
加权,odds可以计算为
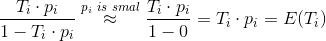
上式中约等于号成立,是因为YouTube视频总量非常大,而正样本是很少的,因此点击率
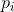
很小,相对于1可以忽略不计。上式计算的结果正好是视频的期望播放时长。因此,通过加权logistic回归来训练模型,并通过
来预测,刚好预测的正是视频的期望观看时长,预测的目标跟建模的期望保持一致,这是该模型非常巧妙的地方。
候选集排序阶段为了让排序更加精准,利用了非常多的特征灌入模型(由于只需对候选集中的几百个而不是全部视频排序,这时可以选用更多的特征、相对复杂的模型),包括类别特征和连续特征,文章中讲解了很多特征处理的思想和策略,这里不细介绍,读者可以看论文深入了解。
YouTube的这篇推荐论文是非常经典的工业级深度学习推荐论文(我个人觉得是我看到的所有深度学习推荐系统论文中最好的一篇,没有之一),里面有很多工程上的权衡和处理技巧,值得我们深入学习。这篇论文理解起来还是比较困难的,需要有很多工程上的经验积累才能够领悟其中的奥妙。因此,据我所知国内很少有团队将这篇文章的方法应用于自己团队的业务中的,而下一篇我们要讲的wide & deep模型却非常多,主要原因可能是对这篇文章的核心亮点把握还不够,或者里面用到的很多巧妙的工程设计哲学不适合自己公司的业务情况。我们团队在17年尝试将该模型的候选集生成阶段直接应用于推荐(没有排序阶段,我们也是视频行业,但是是长视频,因此视频量没有YouTube那么多,因此没有采用两阶段的策略),并且取得了比矩阵效果转化率提升近20%以上的效果。
2Google的wide&deep深度学习推荐模型参考文献8是Google在2016年提出的一个深度学习模型,应用于Google Play应用商店上的APP推荐,该模型经过在线AB测试获得了比较好的效果。这篇文章也是比较早将深度学习应用于工业界的文章,也是一篇非常有价值的文章,对整个深度学习推荐系统有比较大的积极促进作用。基于该模型衍生出了很多其他模型(如参考文献27中的DeepFM),并且很多都在工业界取得了很大的成功,在这一部分我们对该模型的思想进行简单介绍,并介绍2个由该模型衍生出的比较有价值、有代表性的模型。
wide & deep模型分为wide和deep两部分。wide部分是一个线性模型,学习特征间的简单交互,能够“
记忆”用户的行为,为用户推荐感兴趣的内容,但是需要大量耗时费力的人工特征工作。deep部分是一个前馈深度神经网络模型,通过稀疏特征的低维嵌入,可以学习到训练样本中不可见的特征之间的复杂交叉组合,因此可以提升模型的泛化能力,并且也可以有效避免复杂的人工特征工程。通过将这两部分结合,联合训练,最终获得记忆和泛化两个优点。该模型的网络结构图如下面图5中间(左边是对应的wide部分,右边是deep部分)。
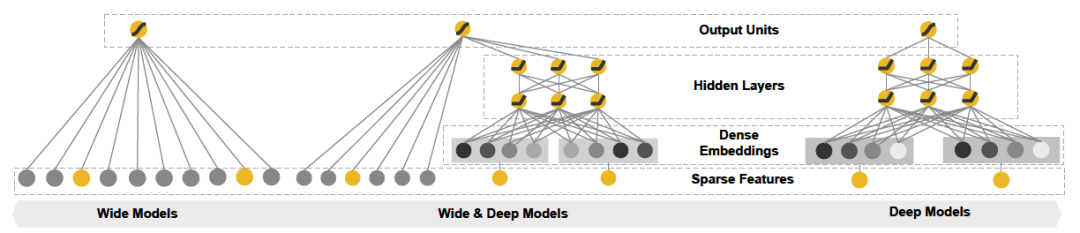
图5:wide & deep 模型网络结构
wide部分是一般线性模型 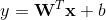 ,y是最终的预测值,这里
,y是最终的预测值,这里 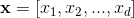 是d个特征,
是d个特征, 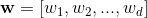 是模型参数,b是bias。这里的特征 包含两类特征:
是模型参数,b是bias。这里的特征 包含两类特征:
(1) 原始输入特征;
(2) 通过变换后(交叉积)的特征;
这里的用的主要变换是交叉积(cross-product),它定义如下:
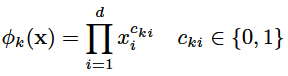
上式中 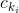 是布尔型变量,如果第i个特征
是布尔型变量,如果第i个特征 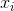 是第k个变换
是第k个变换 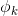 的一部分,那么 =1,否则为0。对于交叉积 And(gender=female, language=en),只有当它的成分特征都为1时,
的一部分,那么 =1,否则为0。对于交叉积 And(gender=female, language=en),只有当它的成分特征都为1时, 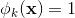 ,否则
,否则 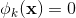 。
。
deep部分是一个前馈神经网络模型,高维类别特征通过先嵌入到低维空间(几十上百维)转化为稠密向量, 再灌入深度学习模型中。神经网络中每层通过计算公式
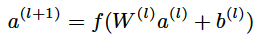
与上层进行数据交互。上式中 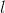 是层数,f是激活函数(该模型采用了ReLU),
是层数,f是激活函数(该模型采用了ReLU), 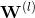 、
、 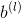 是模型需要学习的参数。
是模型需要学习的参数。
最终wide和deep部分需要结合起来,通过将他们的的对数几率加权平均,再喂给logistic损失函数进行联合训练。最终我们通过如下方式来预测用户的兴趣偏好(这里也是将预测看成是二分类问题,预测用户的点击概率)。
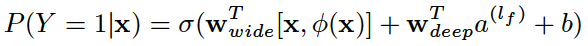
这里,
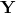
是最终的二元分类变量,
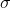
是sigmoid函数,
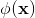
是前面提到的交叉积特征,
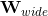
和
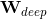
分别是wide模型的权重和deep模型中对应于最后激活
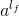
的权重。 下图是最终的wide & deep模型的整体结构,类别特征是嵌入到32维空间的稠密向量,数值特征归一化到0-1之间(本文中归一化采用了该变量的累积分布函数,再通过将累积分布函数分成若干个分位点,用
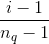
来作为该变量的归一化值,这里
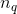
是分位点的个数),数值特征和类别特征拼接起来形成大约1200维的向量再灌入deep模型,而wide模型是APP安装和APP评分(impression)两类特征通过交叉积变换形成模型需要的特征。最后通过反向传播算法来训练该模型(wide模型采用FTRL优化器,deep模型采用AdaGrad优化器),并上线到APP推荐业务中做AB测试。
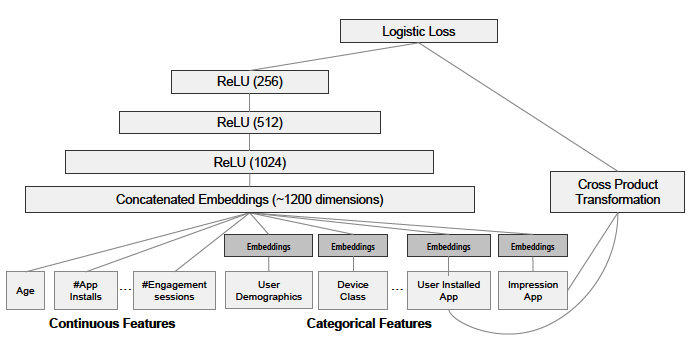
图6:wide & deep 模型的数据源于具体网络结构
上面简单介绍完了wide & deep 模型,详细的介绍请读者阅读参考文献8进行了解。
借助wide & deep模型这种将简单模型跟深度学习模型联合训练,最终获得浅层模型的记忆特性及深度模型的泛化特性两大优点,有很多研究者进行了很多不同维度的尝试和探索。其中deepFM(参考文献27)就是将分解机与深度学习进行结合,部分解决了wide & deep模型中wide部分还是需要做很多人工特征工程的问题,并取得了非常好的效果,被国内很多公司应用于推荐系统排序及广告点击预估中。
参考文献13中,阿里提出了一种BST(Behavior Sequence Transformer)模型(见下图),通过引入Transformer技术(参见参考文献44、45),将用户的行为序列关系整合到模型中,能够捕获用户访问的顺序信号,该模型跟wide & deep最大的不同是将用户行为序列嵌入低维空间并通过一个Transformer层捕获用户行为序列特征后再跟其他特征(包括用户维度的、物品维度的、上下文的、交叉的4类特征)拼接灌入MLP网络训练。该模型在淘宝真实推荐排序业务场景中得到了比wide & deep模型更好的效果,感兴趣的读者可以阅读原文。
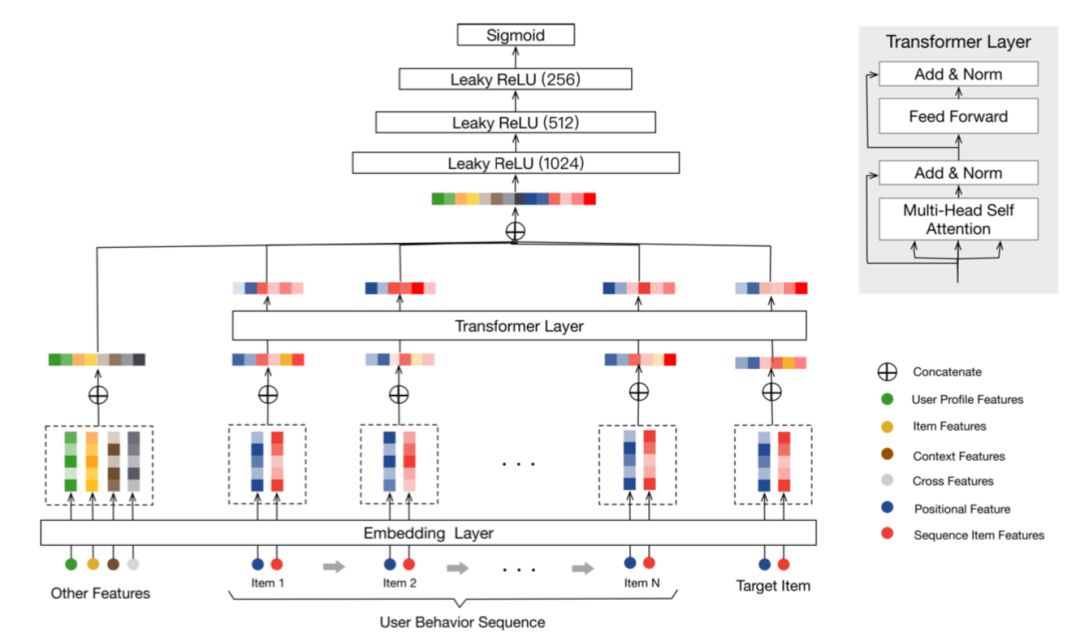
图7:BST推荐模型网络结构
3阿里基于兴趣树(TDM)的深度学习推荐算法
参考文献16中阿里的算法工程师们提出了一类基于兴趣树(Tree-based Deep Model)的深度学习推荐模型,通过利用从粗到精的方式从上到下检索兴趣树的节点为用户生成推荐候选集,该方法可以从海量商品中快速(检索时间正比于商品数量的对数,因此是一类高效的算法)检索出topN用户最感兴趣的商品,因此该算法非常适合淘宝推荐中从海量商品中进行召回。下面我们对该算法的基本原理做简单介绍,算法一共分为如下3个主要步骤。
(1) 构建兴趣树
构建树模型分为两种情况,首先是初始化树模型,有了树模型会经过下面的步骤(2)的深度学习模型学习树中叶子节点的嵌入表示,有了嵌入表示后再重新优化新的树模型,下面我们分别讲解初始化树模型和获得了叶子节点的嵌入表示后重新构建新的树模型。
初始化树模型的思路是希望将相似的物品放到树中相近的地方(参见下面图8)。由于开始没有足够多的信息,这时可以利用物品的类别信息,同一类别中的物品一般会比不同类别的物品更相似。假设一共有k个类别,我们将这k个类别随机排序,排序后为C_1、C_2、...... 、C_k,每一类中的物品随机排序,如果一个物品属于多个类别,那么将它分配到所属的任何类别中,确保每个商品分配的唯一性。那么通过这样处理,就变为下图中的最上面一层这样的排列。这时可以找到这一个物品队列的中点(下图最最上一层的红竖线),从中间将队列均匀地分为两个队列(见下图第二层的节点),这两个队列再分别从中间分为两个队列,递归进行下去,直到每个队列只包含一个物品为止,这样就构建出了一棵(平衡)二叉树,得到了初始化的兴趣树模型。
 图8:初始化树模型
图8:初始化树模型
如果有了兴趣树叶子节点的嵌入向量表示,我们可以基于该向量表示利用聚类算法构建一棵新的兴趣树,具体流程如下:利用kmeans将所有商品的嵌入向量聚类为2类,并对这两类做适当调整使得最终构建的兴趣树更加平衡(这两类中的商品差不多一样多),并对每一类再采用kmeans聚类并适当调整保持分的两类包含的商品差不多一样多,这个过程一直进行下去,直到每类只包含一个商品,这个分类过程就构建出了一棵平衡的二叉树。由于是采用嵌入向量进行的kmeans聚类,被分在同一类的嵌入向量相似(欧几里得距离小),因此,构建的兴趣树满足相似的节点放在相近的地方。
(2) 学习兴趣树叶子节点的嵌入表示
在讲兴趣树模型训练之前,先说下该兴趣树的需要满足的特性。该篇文章中的兴趣树是一种类似最大堆(为了方便最终求出topN推荐候选集)的树。对于树中第j层的每个非叶子节点,满足如下公式:
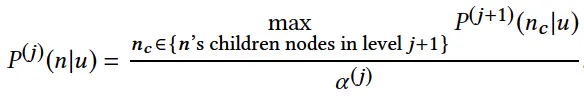
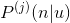
是用户u对商品n感兴趣的概率,
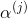
是层j的归一化项,保证该层所有节点的概率加起来等于1。上式的意思是某个非叶子节点的兴趣概率等于它的子节点中兴趣概率的最大值除以归一化项。
为了训练树模型,我们需要确定树中每个节点是否是正样本节点和负样本节点,下面说明怎么确定它们。如果用户喜欢某个叶子节点(即喜欢该叶子节点对应的商品,即用户对该商品有隐式反馈),那么该叶子节点从下到上沿着树结构的所有父节点都是正样本节点。因此,该用户所有喜欢的叶子节点及对应的父节点都是正样本节点。对于某一层除去所有的正样本节点,从剩下的节点中随机选取节点作为负样本节点,这个过程即是负采样。读者可以参考下面图6中右下角中的正样本节点和负样本节点,更好地理解刚刚的文字介绍。
记
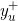
、
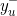
分别为用户u的正、负样本集。该模型的似然函数为
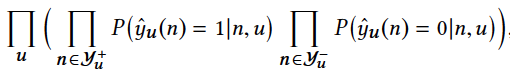
这里
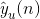
是用户u对物品n的喜好label(=0或者=1),
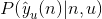
是
=1或
=0对应的概率。对所有用户u和商品n,我们可以获得对应的模型损失函数,具体如下
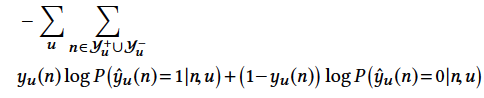
有了上面的背景解释,兴趣树中叶子节点(即所有商品集)的嵌入表示可以通过下面图9的深度学习模型来学习(损失函数就是上面的损失函数)。用户的历史行为按照时间顺序被划分为不同的时间窗口,每个窗口中的商品嵌入最终通过加权平均(权重从Activation Unit获得,见下图右上角的Activation Unit模型)获得该窗口的最终嵌入表示。所有窗口的嵌入向量外加候选节点(即正样本和负采样的样本)的嵌入向量通过拼接,作为最上层神经网络模型的输入。最上层的神经网络是3层全连接的带PReLU激活函数的网络结构,输出层是2分类的softmax激活函数,输出值代表的是用户对候选节点的喜好概率。每个叶子节点拥有一样的嵌入向量,所有嵌入向量是随机初始化的。
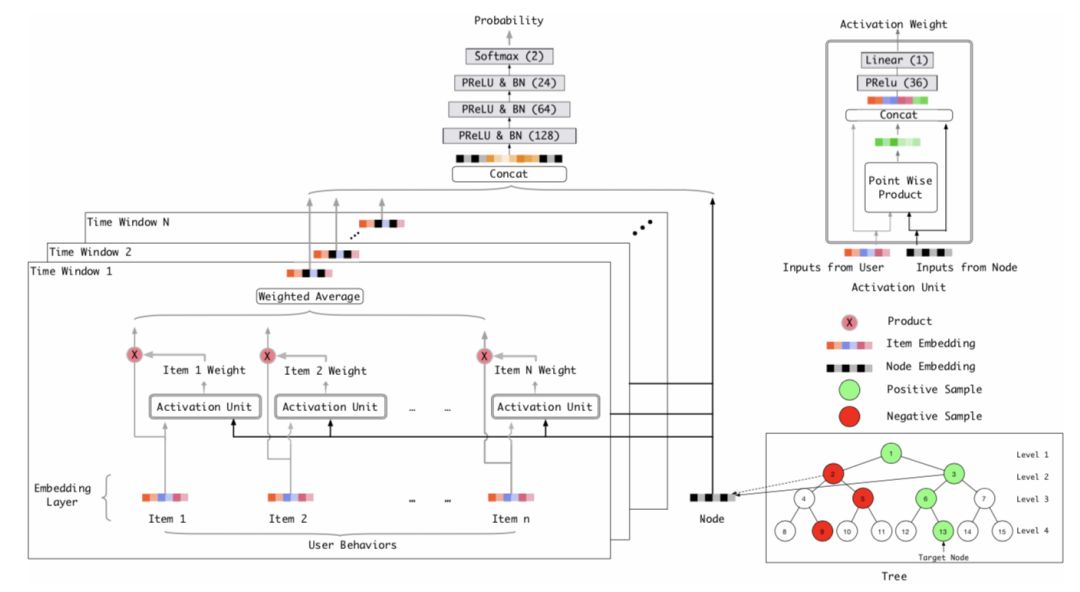
图9:TDM算法深度学习模型
这里说一下,上述兴趣树结构和这里的深度学习模型是可以交替联合训练的。先构造初始化树,再训练深度学习模型直到收敛,从而获得所有节点(即商品)的嵌入表示,基于该嵌入表示又可以获得新的兴趣树,这时又可以开始训练新的深度神经网络模型了,这个过程可以一直进行下去获得更佳的效果。
(3) 从树中检索出topN最喜欢的商品
通过上面介绍的(1)、(2)两步求得最终的兴趣树后,我们可以非常容易的检索出topN用户最喜欢的商品作为推荐候选集,具体流程如下:
采用自顶向下的方式检索(这里我们拿下面的图10来说明,并且假设我们取top2候选集,对于更多候选集过程是一样的)。从根节点1出发,从level2中取两个兴趣度最大的节点(从(2)中介绍可以知道,每个节点是有一个概率值来代表用户对它的喜好度的),这里是2、4两个节点(用红色标记了,下面也是一样)。再分别对2、4两个节点找他们兴趣度最大的两个子节点,2的子节点是6、7,而4的子节点是11、12,从6、7、11、12这4个level3层的节点中选择两个兴趣度最大的,这里是6,11。再选择6、11的两个兴趣度最大的子节点,分别是14、15和20、21,最后从14、15、20、21这四个level4层的节点中选择2个兴趣度最大的节点(假设是14、21)作为给用户的最终候选推荐,所以最终top2的候选集是14、21。
在实际生成候选集推荐之前,可以事先对每个节点关联一个N个元素的最大堆(即该节点兴趣度最大的N个节点),将所有非叶子节点的最大堆采用Key-Value的数据结构存起来。在实际检索时,每个非叶子节点直接从关联的最大堆中获取兴趣度最大的N个子节点。因此,整个搜索过程是非常高效的。
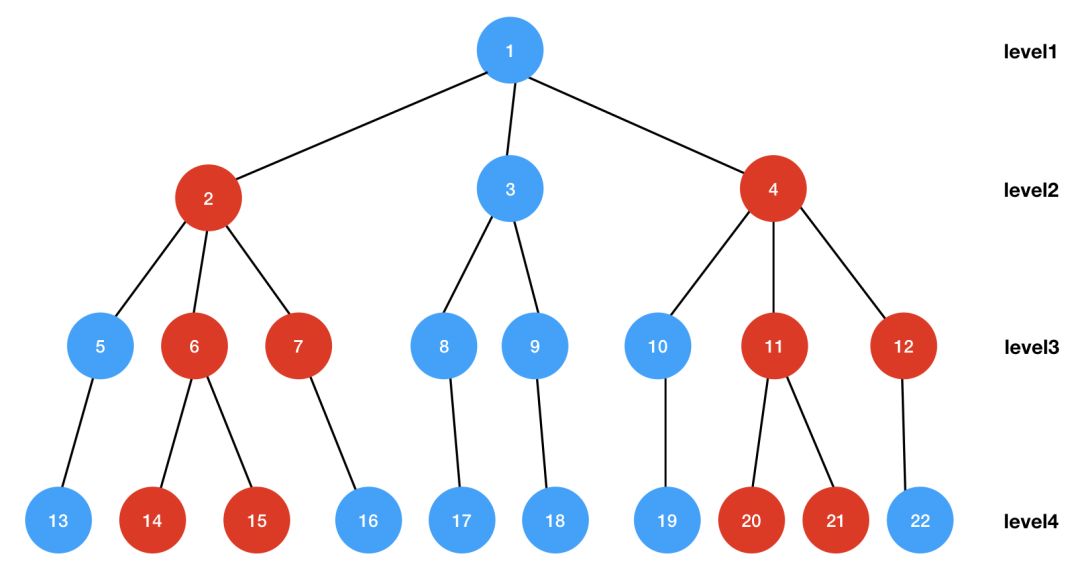
图10:从兴趣树中检索出topN用户最喜欢的商品
阿里这篇文章的思路还是非常值得学习的,通过树模型检索,可以大大减少检索时间,避免了从海量商品库中全量检索的低效率情况,因此,该模型非常适合有海量标的物的产品的推荐候选集生成过程。感兴趣的读者可以好好阅读该论文。
4Google的NFC(神经网络协同过滤)深度学习推荐算法
参考文献19中提出了一种神经网络协同过滤模型(见下面图11),通过将用户行为矩阵中用户和标的物向量做嵌入,灌入多层的MLP神经网络模型中,输出层通过恒等激活函数输出预测结果来预测用户真实的评分,采用平方损失函数来训练模型,因此这种方法就是第二节2中的预测评分问题。如果是隐式反馈,输出层激活函数改为logistic函数,采用交叉熵损失函数,这时就是二分类问题。
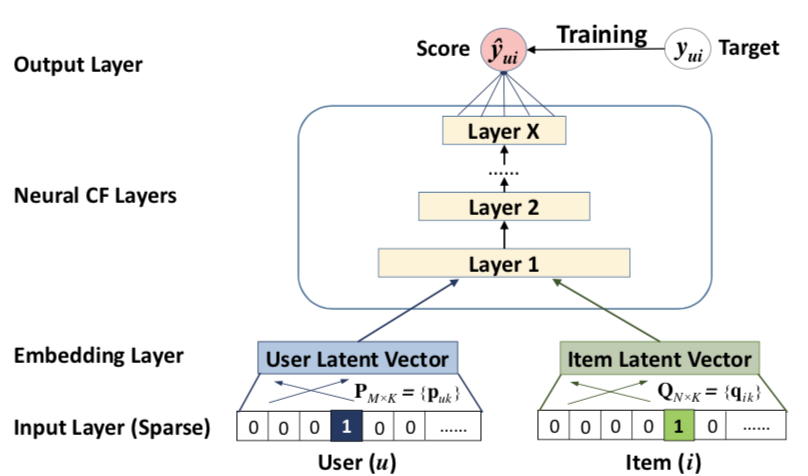
图11:NCF(Neural collaborative filtering)框架
矩阵分解算法可以看成上面模型的特例,矩阵分解可以用公式
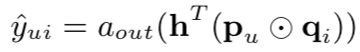
来表示,这里
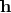
是所有分量为1的向量
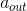
是恒等函数,

代表的是向量对应位置的元素相乘(element-wise product),该公式可以将
看成权重,
看成激活函数,那么矩阵分解算法就可以看成只有输入和输出层(没有隐含层)的神经网络模型,即是上面图11中NCF模型的特例。
另外通过将矩阵分解和MLP的输出向量拼接作为上面提到的NCF模型的输入,可以得到下面表现力更强的神经矩阵分解模型。这里不详细讲解,读者可以阅读原文了解更多细节。
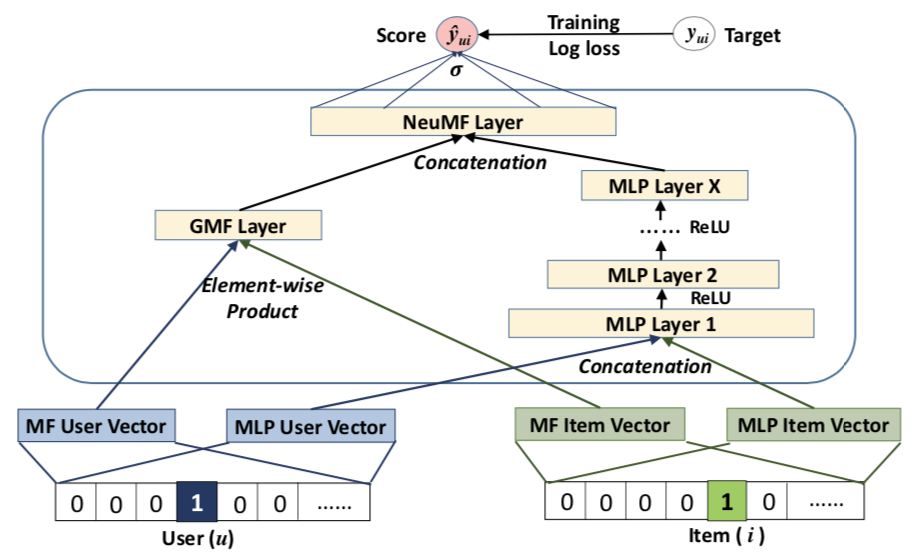
图12:神经矩阵分解模型(Neural matrix factorization model)
前面我们介绍了4篇利用深度学习进行推荐的工业级推荐系统解决方案,希望通过这几个案例大家可以更好地了解深度学习在推荐系统中的应用方法与技巧。深度学习在工业界的应用最近几年非常活跃,有很多这方面的论文发表,值得大家了解、学习和借鉴。由于时间及篇幅关系,还有很多好的文章和方法来不及整理,这里简单提一下,希望有兴趣的读者可以线下自行学习。
参考文献18中,Facebook提供了一种DLRM的深度学习推荐模型,通过将嵌入技术、矩阵分解、分解机、MLP等技术整合起来,取各模型之长,能够对稀疏特征、稠密特征进行建模,学习特征之间的非线性关系,获得更好的推荐预测效果。
参考文献20是腾讯的微信团队提出了一个基于注意力机制的look-alike深度学习模型RALM,是对广告行业中传统的look-alik模型的深度学习改造,通过用户表示学习和look-alike学习捕获种子用户的局部和全局信息,同时学习用户群和目标用户的相似度表示,更好地挖掘长尾内容的受众,并应用到了微信“看一看”中的精选推荐中。通过线上AB测试,点击率、推荐结果多样性等方面都有较大提升。
在参考文献48中,Pinterest公司提出了一种图卷积神经网络(Graph Convolutional Network)模型PinSage,结合高效的随机游走和图卷积生成图中节点的嵌入表示,该算法有效地整合了图结构和节点的特征信息。算法部署到Pinterest网站上,通过AB测试获得了非常好的推荐效果。该应用场景是深度图嵌入技术在工业界规模最大的一个应用案例。
参考文献17中网易考拉团队提出了一个基于RNN的session-based实时推荐系统,参考文献15中阿里提出了一个利用多个向量来表示一个用户多重兴趣的深度学习模型。另外,参考文献11、12、14中阿里提出的DIN、SIEN、DSIN等用于CTR预估的深度学习模型也非常值得大家学习了解。
四开源深度学习框架&推荐算法介绍
深度学习技术要想很好地应用于推荐系统,需要我们开发出合适的深度学习推荐模型,并能够很好地进行训练、推断,因此需要一个好的构建深度学习模型的计算平台。幸好,目前有很多开源的平台及工具可供大家选择,让深度学习的落地相对容易,不再只是大公司才使用得上的高端技术。本节我们就对业界比较主流的几类深度学习平台进行介绍,给大家提供一些选择的参考。同时,也会介绍该平台中已经实现的相关深度学习推荐算法,这些算法可以直接拿来用,或者作为我们学习深度学习推荐系统的材料。
1.Tensorflow(Keras)
Tensorflow是Google开源的深度学习平台,也是业界最流行的深度学习计算平台,有最为完善的开发者社区及周边组件,被大量公司采用,并且几乎所有的云计算公司都支持Tensorflow云端训练。Tensorflow整合了Keras,而Keras是一个高级的神经网络API,用python编写,能够运行在Tensorflow、CNTK或Theano之上,它的初衷是是实现快速实验,能够以最快的速度从想法到落地,因此可以快速实现神经网络原型,它的交互方式友好、模块化封装得很好,很适合初学人员。目前在Tensorflow上可以直接基于Keras API构建深度学习模型,这让原本编程接口较低级的Tensorflow(相对没有那么好用)更加易用。Tensorflow实现了NCF (Neural Collaborative Filtering)深度学习推荐算法,读者可以参考https://github.com/tensorflow/models/tree/master/official/recommendation了解具体介绍及实现细节。
另外,Tensorflow在1.x中也有wide and deep推荐模型的实现,不过未包含在2.0版本中,读者可以参考https://github.com/tensorflow/models/tree/master/official/r1/wide_deep。
tensorrec也是一个基于Tensorflow的推荐库,读者可以参考https://github.com/jfkirk/tensorrec了解,另外https://github.com/tensorflow/ranking/是基于Tensorflow的一个排序学习库(见参考文献47),可以基于该库构建推荐候选集排序模型。
2.PyTorch(Caffe)
PyTorch是Facebook开源的深度学习计算平台,目前是成长最快的深度学习平台之一,增长迅速,业界口碑很好,在学术界广为使用,大有赶超Tensorflow的势头。它最大的优势是对基于GPU的训练加速支持得很好,有一套完善的自动求梯度的高效算法,支持动态图计算,有良好的编程API接口,非常容易实现快速的原型迭代。PyTorch整合了业界大名鼎鼎的计算机视觉深度学习库Caffe,可以方便地复用基于Caffe的CV相关模型及资源。最近PyTorch发布了1.3版本,支持在移动端部署训练好的深度神经网络模型。
利用PyTorch良好的编程接口及高效的网络搭建,可以非常容易构建各类深度学习推荐算法。spotlight就是一个基于PyTorch的开源推荐算法库,提供基于分解模型和序列模型的推荐算法实现,开源工程参见https://github.com/maciejkula/spotlight。
另外,参考文献18中,Facebook提供了一种DLRM的深度学习推荐模型,通过将嵌入技术、矩阵分解、分解机、MLP等技术整合起来,能够对类别特征、数值特征进行建模,学习特征之间的隐含关系。该算法已经开源,读者可以参考https://github.com/facebookresearch/dlrm,该算法分别利用PyTorch和Caffe2来实现了,这也算是Facebook官方提供的一个基于PyTorch平台的深度学习推荐算法。
3.MxNet
MxNet也是一个非常流行的深度学习框架,是亚马逊AWS上官方支持的深度学习框架。它是一个轻量级的、灵活便捷的分布式深度学习框架。支持Python、 R、Julia、Scala、 Go、 Javascript等各类编程语言接口。它允许你混合符号和命令式编程,以最大限度地提高效率和生产力。MxNet的核心是一个动态依赖调度程序,它可以动态地自动并行符号和命令操作,而构建在动态依赖调度程序之上的一个图形优化层使符号执行速度更快,内存使用效率更高。MxNet具有便携性和轻量级的优点,可以有效地扩展到多个gpu和多台机器。
MxNet也提供了推荐系统相关的代码实现,主要有矩阵分解推荐算法和DSSM(Deep Structured Semantic Model)深度学习推荐算法两类推荐算法。读者可以参考https://github.com/apache/incubator-mxnet/tree/master/example/recommenders了解更多细节。
4.DeepLearning4j
DeepLearning4j(简称
dl4j)是基于Java生态系统的深度学习框架,构建在Spark等大数据平台之上,可以无缝跟Spark等平台对接。基于Spark平台构建的技术体系可以非常容易跟dl4j应用整合。dl4j对深度学习模型进行了很好的封装,可以方便地通过类似搭积木的方式轻松构建深度学习模型,构建的深度学习模型直接可以在Spark平台上运行。
不过官方没有提供推荐系统相关的参考实现案例,目前dl4j处在1.0版本预发布阶段。如果你的机器学习平台基于Hadoop/Spark生态体系,dl4j是一个不错的尝试方案,作者曾经使用过dl4j构建深度学习模型,确实是非常高效的,但是训练过程可能会占用很多系统资源(当时是直接跑在CPU之上),有可能会影响现在的其他机器学习任务,最好的方式是采用更好的资源隔离策略或者使用独立的集群供dl4j使用,并使用GPU进行计算。
5.百度的PaddlePaddle
PaddlePaddle(飞桨)是百度开源的深度学习框架,也是国内做的最好的深度学习框架,整个框架体系做的比较完善。官方介绍飞桨同时支持动态图和静态图,兼顾灵活性和高性能,源于实际业务淬炼,提供应用效果领先的官方模型,源于产业实践,输出业界领先的超大规模并行深度学习平台能力。提供包括AutoDL、深度强化学习、语音、NLP、CV等各个方面的能力和模型库。
在深度学习推荐算法方面,飞桨提供了超过5类深度学习推荐算法模型,包括Feed流推荐、DeepFM、sesssion-based推荐、RNN相关推荐、卷积神经网络推荐等,是很好的深度学习推荐系统学习材料,想详细了解的读者可以参考https://github.com/PaddlePaddle/models/tree/develop/PaddleRec。
6.腾讯的Angel
Angel是腾讯跟北京大学联合开发的基于参数服务器模型的分布式机器学习平台,可以跟Spark无缝对接,主要聚焦于图模型及推荐模型。最近(今年8月份)Angel发布了3.0版本,提供了更多新的特性,包括自动特征工程、Spark on Angel中集成了特征工程,可以无缝对接自动调参、整合了PyTorch(PyTorch on Angel),增强了Angel在深度学习方面的能力、自动超参调节、Angel Serving、支持Kubernetes运行等很多非常有实际工业使用价值的功能点。
在深度学习推荐系统方面,Angel支持包括DeepFM、Wide & Deep、DNN、NFM、PNN、DCN、AFM等多种深度学习推荐算法。读者可以参考https://github.com/Angel-ML/angel了解。
由于Angel可以跟Spark无缝对接,是比较适合基于Spark平台构建的技术栈的,我们公司目前也在尝试使用Angel进行部分推荐算法的研究与业务落地。不过,Angel中很多深度学习模型(比如wide & deep)还是实现的很粗陋,使用范围有一定限制,没有怎么经过大规模实际数据的验证,文档也非常不完整,使用过程中可能会有很多坑。
7.微软开源的推荐算法库recommenders
微软云计算团队和人工智能开发团队在今年2月份开源了一个推荐算法库,基于微软的大型企业级客户项目经验及最新的学术研究成果,将搭建工业级推荐系统的业务流程和适用操作技巧总结提炼开源出来,对构建工业级推荐系统的5大流程:数据准备、模型构建、模型离线评估、模型选择与调优、模型上线,进行整理与提炼,方便学习者熟悉关键点与技巧,帮我我们更好地学习推荐系统。并提供多种有价值的适合工业级应用的推荐算法,包括xDeepFM、DKN、NCF、RBM、Wide and Deep等深度学习推荐算法。因此,是一份难得的学习推荐系统工程实践及工业级推荐算法的学习材料,这些算法基于Python开发,不依赖其他深度学习平台,直接可以在服务器上运行(部分算法依赖GPU、部分算法依赖PySpark),细节读者可以参考https://github.com/microsoft/recommenders。
前面介绍了7个深度学习相关的平台及该平台包含的推荐算法,可供读者参考。另外,CNTK(微软开源的)、Theano、gensim(我们公司在用,还不错)等也是比较有名的深度学习平台,阿里也开源了x-deeplearning深度学习平台。如果读者是从零开始学习深度学习推荐算法,建议可以从Tensorflow或者PyTorch开始入手,他们是生态最完善、最出名的深度学习平台。如果读者公司基于Hadoop/Spark平台来开发推荐算法,可以研究一下Angel及DeepLearning4j,不过请慎重用于真实业务场景,毕竟它们生态不完善,文档相对较少,由于用的人少,出了问题,搜索相关问题解决方案也比较困难。
五深度学习技术应用于推荐系统的优缺点及挑战
前面几节对深度学习推荐系统相关知识进行了全面介绍,大家知道了深度学习应用于推荐系统的巨大价值,本节我们来梳理总结一下深度学习应用于推荐系统的优缺点及挑战,让大家对深度学习推荐系统的价值有一个更加全面、客观、公正的了解。
-
优点
深度学习技术最近几年的大火,在计算机视觉和语音识别中的巨大成功,真正体现出了深度学习的巨大价值。深度学习应用于推荐系统的优势主要体现在如下几个方面。
(1) 更加精准的推荐
深度学习模型具备非常强的表达能力,已经证明MLP深度学习网络可以拟合任意复杂的函数到任意精度(见参考文献4)。因此,利用深度学习技术来构建推荐算法模型,可以学习特征之间深层的交互关系,可以达到比传统矩阵分解、分解机等模型更精准的推荐效果。第三节中的部分工业级深度学习推荐系统案例已经很好验证了这一点。
(2) 可以减少人工特征工程的投入
传统机器学习模型(比如logistic回归等),需要花费大量的人力工作用于构建特征、筛选特征,最终才能构建一个效果较好的推荐模型。而深度学习模型只需要将原始数据通过简单的向量化灌入模型,通过模型自动学习特征,最终获得具备良好表达能力的神经网络,因此,通过深度学习构建推荐算法可以大大节省人工特征工程的投入成本。
(3) 可以方便整合附加信息(side information)
深度学习模型的可拓展性很强,可以非常方便地在模型中整合附加信息(利用附加信息的嵌入,或者利用CNN、RNN等网络结构从附加信息中提取特征),这在第三节中部分模型中已经有详细介绍。有更多的数据整合进深度学习模型,可以让模型获得更多的信息,最终预测结果会更加精确。
2. 缺点与挑战
深度学习应用于推荐系统,除了上面的优势外,还存在一些问题,这些问题限制了深度学习在推荐系统中的大规模应用。具体表现在如下几个方面:
(1) 需要大量的样本数据来训练可用的深度学习模型
深度学习是一类需要大量样本数据的机器学习算法。模型的层数多,表达能力强,决定了需要学习的参数多,因此需要大量的数据才可以训练出一个能真正解决问题、精度达到一定要求的算法。所以,对于用户规模小的产品或者刚刚开发不久还没有很多用户的产品,深度学习算法是不合适的。
(2) 需要大量的硬件资源进行训练
深度学习算法需要依赖大量数据进行训练,因此也是一类计算敏感型技术,要想训练一个深度学习模型,需要足够的硬件资源(一般是GPU服务器)来计算,否则资源不足会导致训练时间过长,无法真正应用,甚至无法进行训练。一般GPU是比较贵的,所以对企业的资金提出了更高的要求。
(3) 对技术要求相对较高,人才比较紧缺
由于深度学习是最近几年才流行起来的技术,深度学习相关技术相比传统机器学习算法,会更加复杂,对相关算法人员要求更高。目前这方面的人才明显非常紧缺。因此,团队在落地深度学习算法应用于推荐中,是否有相应的人才可以实践、解决深度学习相关问题也是面临的重要挑战。
(4) 跟团队现有的软件架构适配,工程实现有一定难度
经过前面介绍,考虑应用深度学习技术的公司或者团队,一定会负责着有足够用户规模的产品线,并且有足够硬件、人力资源来应付,这样的团队一般是较成熟的团队。经过几年发展,团队中肯定有各类算法组件,特别是大数据相关技术与平台。在引进深度学习过程中,怎么将深度学习相关技术组件跟团队现有的架构和组件有机整合起来(深度学习平台可能需要大数据平台提供用于建模的数据分析处理、特征工程等),也是团队面临的重要问题。一般需要团队开发相关工具或者组件,打通现有的技术架构和深度学习技术架构之间的壁垒,让两者高效地融合起来,一起更好地服务于推荐业务。
(5) 深度学习模型可解释性不强
深度学习模型基本是一个黑盒模型,通过数据灌入,学习输入与输出之间的内在联系,具体输入是怎么决定输出的,我们一无所知,导致我们很难解释清楚深度学习推荐系统为什么给用户推荐这个。给用户提供有价值的推荐解释,往往是很重要的,能够加深用户对产品的理解和信赖,提升用户体验。现在部分基于注意力机制的深度学习模型,具备一定的可解释性,这块也是未来一个值得研究和探索的方向。
(6) 调参过程冗长复杂
深度学习模型包含大量的参数及超参,训练深度学习是一个复杂的过程,需要选择随机梯度下降算法,并且在训练过程中需要跟进观察参数的变化情况,对模型的训练过程进行跟踪,并实时调整。调参是需要大量的实践经验积累的。
幸好,目前像Tensorflow等提供了可视化的工具(TensorBoard)方便模型训练人员进行跟踪。更好的消息是,有很多学术和工程研究在尝试怎么让调参的过程尽量自动化,目前很多学者及大公司也在大力发展自动超参调节(AutoML)相关技术,让参数调节更加简单容易。
参考文献41中,Google的研究者们提出了NIS技术(Neural Input Search),可以自动学习大规模深度推荐模型中每个类别特征最优化的词典大小以及嵌入向量维度大小。目的就是为了在节省性能的同时尽可能地最大化深度模型的效果。并且,他们发现传统的Single-size Embedding方式(所有特征值共享同样的嵌入向量维度)其实并不能够让模型充分学习训练数据。因此与之对应地,提出了Multi-size Embedding方式让不同的特征值可以拥有不同的嵌入向量维度。在实际训练中,他们使用强化学习来寻找每个特征值最优化的词典大小和嵌入向量维度。通过在两大大规模推荐问题(检索、排序)上的实验验证,NIS技术能够自动学习到更优化的特征词典大小和嵌入维度并且带来在Recall@1以及AUC等指标上的显著提升。
六深度学习推荐系统工程实施建议
前面对深度学习应用于推荐系统的相关算法、优缺点等进行了比较全面的介绍。从第三节的案例介绍,我们知道深度学习使用得好是可以为推荐业务带来巨大价值的,那么是否一定需要在我们自己的推荐业务中引入深度学习算法呢?如果考虑引入,该怎么更好地跟现有的平台及业务对接呢? 需要注意哪些点呢?这些问题是我们在本节需要重点探讨的问题。
-
深度学习的效果真的有那么好吗?
从第二节的案例介绍,确实给了我们很大的信心,相信引入深度学习技术一定会大大提升推荐业务的点击率,从而提升用户体验,为公司创造业务价值。但是深度学习要做好,还是非常有难度的,甚至可以说,设计好的深度学习算法是一门艺术而不仅仅是技术。参考文献43对当前深度学习的效果进行了质疑,很多深度学习效果可能还不如常规算法来得好(其中第三节4中的NCF模型也被该作者diss了)。因此,我们在是否选择深度学习技术时一定要慎重,要有效果可能不一定如意的心里准备和预期。
-
团队是否合适引入深度学习推荐技术
我们除了要顾虑深度学习带来的推荐效果外,我们还需要关注自己团队是否合适引入深度学习技术。总体来说,我们必须要考虑如下几个问题:
(1) 产品所在阶段及产品定位
如果是新开发的产品或者产品定位只服务于非常有限的用户群体,这样的产品或者阶段肯定是不适合深度学习技术的,因为深度学习需要大量的训练数据来保证模型可训练及模型的精度。
(2) 是否有相关技术人员
深度学习是一类新的发展中的技术,技术要求比一般机器学习应用要高,这方面的人才相对稀缺,团队目前是否有相关人才,是否有学习能力强、短期可以试用深度学习技术的人才,以及是否可以招聘到(给到足够高的工资)这方面的人才都是需要考虑的不稳定因素。
(3) 深度学习相关硬件资源
深度学习对硬件要求较高,团队是否有现成的硬件支撑深度学习平台搭建,是否可以有足够的资金支持购买深度学习相关硬件,能否承受购买代来的短期成本投入,都是团队面临的问题。
(4) 其他的沉默成本
深度学习推荐系统的模型训练周期长,需要调整很多超参数,因此选择合适的模型周期长,需要跟现有的技术架构打通,需要对可能出现的任何问题排查等等。这些可能都是沉默成本,我们必须要有心理预期。
-
怎么打通深度技术相关技术栈与团队现有技术栈之间的脉络
如果通过2的思考,你觉得有必要在你们团队引入深度学习推荐技术,那怎么将深度学习相关技术栈跟团队现有技术栈打通呢?
想必大部分团队会技术Hadoop/Spark技术构建大数据与算法平台,那么怎么将深度学习技术跟Hadoop生态打通就是摆在你面前急需解决的问题。
如果你尝试选择Angel、DeepLearning4j,就不存在这些问题,因为他们天生就是支持在Spark平台上运行的,只不过这两个项目还不够成熟,稳定性有待提高,在团队中尝试使用肯定会遇到很多坑,出了问题也没有很好的资源进行排查解决,主要得靠自己。
如果你选择Tensorflow、PyTorch等主流深度学习平台,因为它们都是基于Python体系的,将Hadoop生态与它们打通就是非常有必要的。一般会用Spark做数据处理、特征构建、推断等工作,利用Tensorflow、PyTorch训练深度学习模型。那么将两者打通的可行方案有如下两个:
(1) 将Tensorflow、PyTorch训练好的模型上传到Spark平台,开发基于Java的模型解析工具,让Spark可以解析Tensorflow、PyTorch构建的深度学习模型,并最终进行预测;
(2) Tensorflow、PyTorch训练好深度学习模型后,直接用Tensorflow Servering(PyTorch没有官方提供的Servering,但是可以利用Flask等python web框架自己搭建)部署好深度学习模型,在Spark侧做推断时,通过调用Servering的接口来为每个用户做推荐。
-
从经典成熟的模型、从跟公司业务接近的模型开始尝试
如果我们考虑引入深度学习模型,我们可以考虑前面提到的一些经典的、在大公司海量数据场景下经过AB测试验证过有巨大商业价值的模型开始尝试,最好选择跟本公司业务类似的模型,比如你们公司是做视频的,那么选择YouTube的深度学习模型可能是一个好的选择。通过引入这些成熟模型并结合本公司的业务场景及数据情况进行裁剪调优,会更容易产生商业价值,可能付出的代价会更小,整个引入过程也会更加可控。
前面讲完了引入深度学习需要考虑的工程问题,希望可以帮助读者更好地做决策。深度学习不是银弹,所以在考虑深度学习技术时,一定要慎重,不要被业界利好的消息所蒙蔽,我相信即使像Google这类有技术、有人才、有资源的公司,在将深度学习引入并产生商业价值的过程中,肯定是掉了很多坑的,他们论文发出来肯定是介绍美好的一面,走了多少弯路,付出了多少代价我们就不得而知了。
对于小团队,作者强烈建议可以先用简单的推荐模型(如矩阵分解、基于内容的推荐等)将推荐业务跑起来,将产品中需要用到推荐的所有业务场景都做完,将整个推荐流程做得更加易用、模块化,让推荐迭代更加方便容易,同时对AB测试、推荐指标体系、推荐监控等体系要先做好。如果这些都做的比较完善了,并且有剩余的人力资源,是可以投入一定的人力去研究、实践深度学习技术的。否则,还是建议不要尝试了。
七深度学习推荐系统的未来发展
从2016年AlphaGo战胜李世石开始,深度学习驱动了第三次人工智能浪潮的到来。几年时间内,深度学习风靡全球,几乎所有的科技公司都希望将深度学习引入到真实业务场景中,期望借助深度学习产生巨大的商业价值。深度学习的引入确实让计算机视觉、语音识别、自然语言处理等领域有非常大的突破,在很多方面甚至超越了人类专家的水平,在推荐系统中的价值也逐渐凸显出来。
我相信深度学习相关技术未来会给推荐系统带来巨大的改变和革新,现在只是前奏。在本节作者就基于自己最近几年的所知、所学、所思,对深度学习在推荐系统中的未来发展做一些预测,希望可以给读者提供一些新的视角,更好地预见深度学习未来巨大价值的爆发,提前做好准备。具体来说,我会从如下5个维度来讲解。
1. 算法模型维度
目前的深度学习应用于推荐还只是包含2-3层隐含层的较浅层的深度学习模型,跟CNN等动辄上百层的模型还不在一个量级,目前应用于推荐的深度学习模型为什么没有朝深层发展,还需要有更多这方面的研究与实践。
另外,目前应用于推荐的深度学习模型五花八门,基本是参考照搬在其他领域非常成功的模型,还没有一个为推荐系统量身定制的非常适合推荐业务的网络结构出现(比如计算机视觉中的CNN网络结构,语音识别中的RNN网络结构),我相信在这一方向上不久的将来一定会有突破,应该会出现一个适合推荐系统的独有网络架构,给推荐系统带来深远影响。
未来的产品形态一定是朝着实时化方向发展,通过信息流推荐的方式更好地满足用户的需求变化。这要求我们可以非常方便地将用户的实时兴趣整合到模型中,如果我们能够对已有的深度学习推荐模型进行增量优化调整,反应用户兴趣变化,就可以更好更快地服务于用户。可以进行增量学习的深度学习模型应该是未来一个有商业价值的研究课题。同时,随身携带的智能产品(手机、智能手表、智能眼镜等)会越来越多,如果我们要在这些跟随身体运动的智能产品上做推荐的话,一定需要结合当前的场景实时感知用户的位置、状态等的变化做到实时调整、动态变化。而强化学习是解决这类跟外界环境实时交互的一种有效机器学习范式,或许结合深度强化学习技术,这方面可以提供用户体验非常好的推荐解决方案,这也是未来一个非常火的领域,目前也有少量这方面的应用案例。
任何一种模型都不是万能的,因此深度学习模型怎么跟传统的机器学习模型更好地融合来提供更好的推荐服务,也是非常值得研究的一个方向。
2. 工程维度
当前深度学习做分布式训练还比较困难,也没有很好地跟大数据平台打通,基本都是大公司花很多工程人员自己提供深度学习分布式解决方案及跟已有大数据平台对接。虽有很多将深度学习跟大数据结合的开源项目(比如雅虎的CaffeOnSpark,intel的bigDL、以及前面讲的DeepLearning4j、Angel等),但是还不够成熟,社区不够壮大,遇到问题也可能会比较麻烦,不易解决。 。
要想让深度学习在工业界产生巨大价值,深度学习技术需要做到高效、便捷、可拓展,怎么跟现有的大数据平台更好地打通,做到无缝对接,对深度学习在推荐上更好地应用非常重要。亦或是深度学习平台通过自身发展具备处理大数据的能力。不管是哪种方式,做到跟大数据处理能力打通是必要的。
大数据和AI是无法割裂开来的,因此未来一定会有成熟的开源方案出现,可以方便整合大数据与深度学习相关的能力点,让数据的处理、分析、建模更加流畅便捷。
3. 应用场景维度
目前深度学习的应用场景还比较单一,基本是对同一类场景的标的物的推荐(比如视频、电商商品),未来的产品(APP)一定会提供整体的大而全的解决方案(比如现在的微信、美团就是综合服务平台),那么怎么在这些差异非常大的多场景中为用户统一推荐各类产品与服务就是一个非常大的挑战,深度学习是否可以在这类场景中发挥巨大价值,还需要更多的研究与实践。在跨场景下结合知识图谱与迁移学习,或许可以帮助深度学习算法取得更大的成功。
随着5G及物联网的发展,不久的将来,像家庭、车载等新场景会变得越来越重要,这类场景用户的交互方式会产生变化,我们可能更多地是从语音获取用户的反馈信息,在这类场景中,将语音等信息整合到深度学习模型中,做基于语音交互的推荐解决方案一定是一个比较有前景的方向。另外,VR/AR的发展,也可能促进视觉交互(如手势交互)的成熟,通过神经网络处理视觉信息,从而构建有效的推荐模型也是未来的一个重要方向。深度学习已经在计算机视觉、语音识别、自然语言处理中获得了极大的成功,我相信在这些以语音、语言、视觉交互为主的新型产品中,深度学习必有用武之地。
4. 数据维度
目前的深度学习推荐模型还主要是使用单一的数据源(用户行为数据、用户标的物metadata数据)来构建深度学习模型。未来随着5G技术的发展、各类传感器的普及,我们会更容易收集到多源的数据,怎么充分有效地利用这些异构信息网络(
Heterogeneous
Information
Network,简写为
HIN)的数据,构建一个融合多类别数据的深度学习推荐模型,是一个必须面对的有意思的并且极有挑战的研究方向。在前面讲的在新的未开发的应用场景中一定也会产生非常多种类的新数据类型(比如嗅觉的数据)需要深度学习来处理。
随着安全意识的崛起及相关法律的规范化,未来对数据的收集形式及数量也可能会有变化和限制,深度学习这种强烈依赖数据的算法是否能够适应这种未来数据更加谨慎规范化的时代的发展,也是面临的问题。怎么在有限数据下、在保证用户隐私情况下,应用深度学习技术也是值得研究的课题。
当前深度学习技术一般适合回归、预测等监督学习任务,需要依赖大量的标注数据进行训练,这限制了深度学习的应用场景,怎么改造、进化深度学习模型,让它可以处理少量标注数据,也是一个有前景、有需求的方向。强化学习、半监督学习在处理无监督学习上有天然优势,或许深度学习跟这些技术的结合是一个好的方向。
5. 产品呈现与交互维度
目前的深度学习模型基本是一个黑盒模型,我们只有通过部署到线上经过AB测试观察指标变化,进而评价模型的效果好坏,无法给出为什么这样推荐的原因。而给用户一个明显的、用户可以理解和接受的推荐原因是大大有益于用户信任建立的。好的推荐解释可以提升用户的产品体验,这方面肯定是未来的一个研究热点。
好的推荐产品除了推荐精准的物品外,给用户的视觉呈现方式、视觉效果、交互方式等都对用户是否愿意使用、是否认同推荐都非常重要。未来的深度学习推荐技术可能会结合用户的点击率、用户对标的物的视觉感受度(可以通过视觉传感器获取)、甚至心情(可以通过视觉或者声音识别出)、用户的使用流畅度(可以通过用户的操作,如触屏点击获得)等多维度的目标进行建模,更好地提升推荐产品的用户体验。
总结
本文对深度学习技术、深度学习应用于推荐系统的一般方法和思路、几个重要的工业级深度学习推荐系统、开源深度学习平台及推荐算法、深度学习推荐算法的优缺点与挑战、深度学习推荐系统工程落地建议以及深度学习推荐系统的未来发展等几个方面进行了比较全面的介绍。
本文更多地是从工业实践的角度来讲解深度学习推荐系统,特别是第三节中讲解的几个核心深度学习推荐算法、第五节的优缺点与挑战和第六节的工程实施建议,值得大家好好学习,希望可以给大家提供深度学习在推荐业务落地上的参考与借鉴。
深度学习在推荐系统中的应用是最近几年的事情,虽然成功案例颇多,但是还不算完善,远没有达到成熟的地步。也没有形成完善的理论体系,更多地是借鉴深度学习在图像、语音识别等领域的成功经验,将模型稍作修改迁移过来,目前并未找到一种专为推荐系统量身定制的深度学习模型,这方面未来还有很大的发展空间。推荐系统作为机器学习中一个相对完善的子领域,它在实际业务中有重大商业价值,越来越个性化也是用户发展的需要和社会发展趋势。我相信,对极致用户体验的追求,对商业价值的挖掘,这两个原因一定会推动学术界、产业界的专家在深度学习推荐系统上进行更多的的探索与实践,未来深度学习相关技术一定会在推荐系统中产生更大的价值!让我们拭目以待!
参考文献
-
[1943] A Logical Calculus of Ideas Immanent in Nervous Activity
-
[2017] On the Origin of Deep Learning
-
[1986] Learning Representations by Back-Propagating
-
[1989] Multilayer feedforward networks are universal approximators
-
[深度学习-综述文章 2019] Deep Learning based Recommender System- A Survey and New Perspectives
-
[2007] Restricted Boltzmann Machines for Collaborative Filtering
-
[YouTube 2016] Deep Neural Networks for YouTube Recommendations
-
[Google 2016] Wide & Deep Learning for Recommender Systems
-
Deep content-based musicrecommendation
-
Improving Content-based and Hybrid Music Recommendation using Deep Learning
-
[2017 阿里] Deep Interest Network for Click-Through Rate Prediction
-
[2018 阿里] Deep Interest Evolution Network for Click-Through Rate Prediction
-
[2019 阿里] Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
-
[2019 阿里] Deep Session Interest Network for Click-Through Rate Prediction
-
[2019 阿里] Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
-
[2018 阿里] Learning Tree-based Deep Model for Recommender Systems
-
[网易] Personal Recommendation Using Deep Recurrent Neural Networks in NetEase
-
[2019 facebook] Deep Learning Recommendation Model for Personalization and Recommendation Systems
-
[2017 Google] Neural Collaborative Filtering
-
[2019 腾讯] Real-time Attention Based Look-alike Model for Recommender System
-
[2018 Airbnb] Applying Deep Learning To Airbnb Search
-
A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
-
[2015] Collaborative Deep Learning for Recommender Systems
-
[2015] Deep Collaborative Filtering via Marginalized Denoising Auto-encoder
-
[2016] A Neural Autoregressive Approach to Collaborative Filtering
-
[2016] Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction
-
[2017 华为诺亚实验室] DeepFM- A Factorization-Machine based Neural Network for CTR Prediction
-
[2017 携程] A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems
-
[2018] DKN- Deep Knowledge-Aware Network for News Recommendation
-
DeepPlaylist- Using Recurrent Neural Networks to Predict Song Similarity
-
The application of Deep Learning in Collaborative Filtering
-
[2016] Improved Recurrent Neural Networks for Session-based Recommendations
-
[2016] Session-based Recommendations with Recurrent Neural Networks
-
[2017] Contextual Sequence Modeling for Recommendation with Recurrent Neural Networks
-
[2017] Improving Session Recommendation with Recurrent Neural Networks by Exploiting Dwell Time
-
[2017] Inter-Session Modeling for Session-Based Recommendation
-
[2017] Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks
-
[2017] Recurrent Latent Variable Networks for Session-BasedRecommendation
-
[2017] Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
-
Collaborative Memory Network for Recommendation Systems
-
[2019 Google] Neural Input Search for Large Scale Recommendation Models
-
[2018 Google] Efficient Neural Architecture Search via Parameters Sharing
-
[2019] Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
-
[2017] Attention is all you need
-
[2018] Bert: Pre-training of deep bidirectional transformers for language understanding
-
[2018 京东] Deep Reinforcement Learning for List-wise Recommendations
-
[2019] TF-Ranking- Scalable TensorFlow Library for Learning-to-Rank
-
[2018 Pinterest] Graph Convolutional Neural Networks for Web-Scale Recommender Systems